 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDSCnet: Replicating Lidar Point Clouds with Deep Sensor Cloning
Nov 27, 2018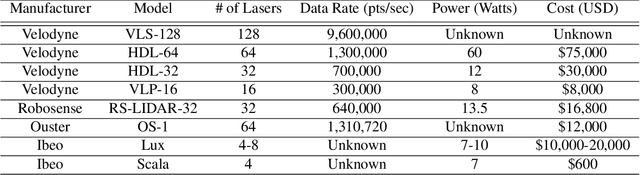
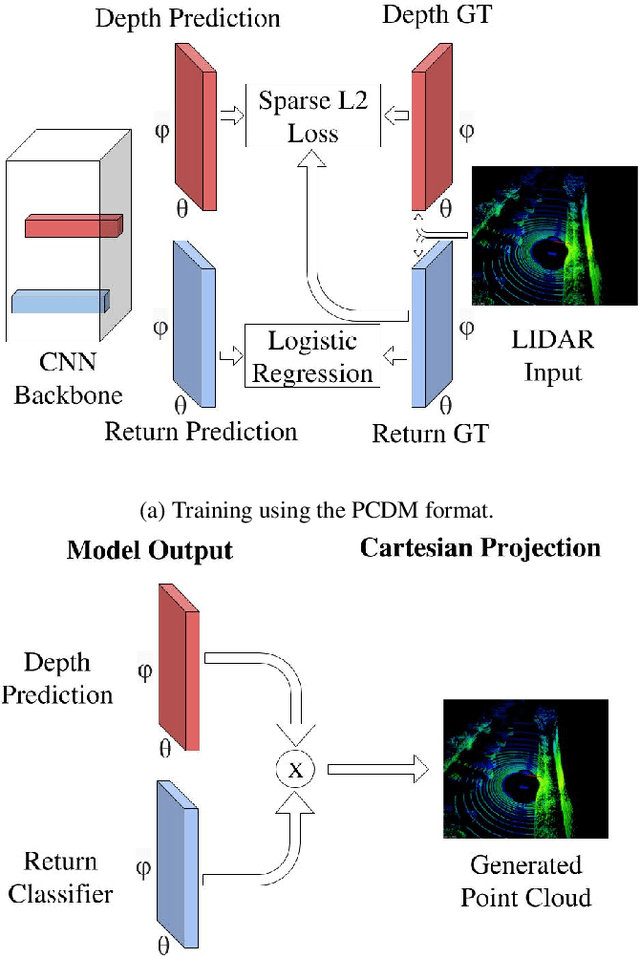


Convolutional neural networks (CNNs) have become increasingly popular for solving a variety of computer vision tasks, ranging from image classification to image segmentation. Recently, autonomous vehicles have created a demand for depth information, which is often obtained using hardware sensors such as Light detection and ranging (LIDAR). Although it can provide precise distance measurements, most LIDARs are still far too expensive to sell in mass-produced consumer vehicles, which has motivated methods to generate depth information from commodity automotive sensors like cameras. In this paper, we propose an approach called Deep Sensor Cloning (DSC). The idea is to use Convolutional Neural Networks in conjunction with inexpensive sensors to replicate the 3D point-clouds that are created by expensive LIDARs. To accomplish this, we develop a new dataset (DSDepth) and a new family of CNN architectures (DSCnets). While previous tasks such as KITTI depth prediction use an interpolated RGB-D images as ground-truth for training, we instead use DSCnets to directly predict LIDAR point-clouds. When we compare the output of our models to a $75,000 LIDAR, we find that our most accurate DSCnet achieves a relative error of 5.77% using a single camera and 4.69% using stereo cameras.
A Metaprogramming and Autotuning Framework for Deploying Deep Learning Applications
Nov 21, 2016
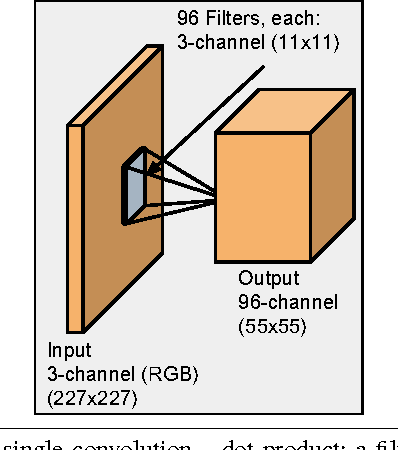
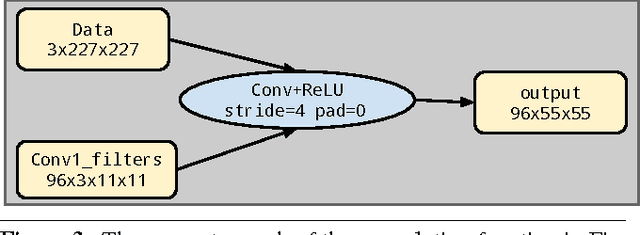
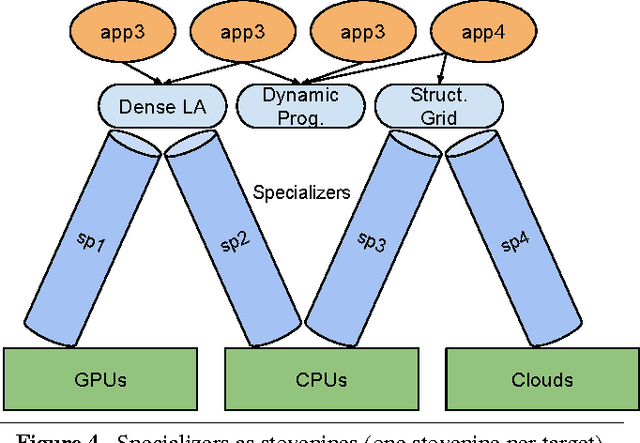
In recent years, deep neural networks (DNNs), have yielded strong results on a wide range of applications. Graphics Processing Units (GPUs) have been one key enabling factor leading to the current popularity of DNNs. However, despite increasing hardware flexibility and software programming toolchain maturity, high efficiency GPU programming remains difficult: it suffers from high complexity, low productivity, and low portability. GPU vendors such as NVIDIA have spent enormous effort to write special-purpose DNN libraries. However, on other hardware targets, especially mobile GPUs, such vendor libraries are not generally available. Thus, the development of portable, open, high-performance, energy-efficient GPU code for DNN operations would enable broader deployment of DNN-based algorithms. Toward this end, this work presents a framework to enable productive, high-efficiency GPU programming for DNN computations across hardware platforms and programming models. In particular, the framework provides specific support for metaprogramming, autotuning, and DNN-tailored data types. Using our framework, we explore implementing DNN operations on three different hardware targets: NVIDIA, AMD, and Qualcomm GPUs. On NVIDIA GPUs, we show both portability between OpenCL and CUDA as well competitive performance compared to the vendor library. On Qualcomm GPUs, we show that our framework enables productive development of target-specific optimizations, and achieves reasonable absolute performance. Finally, On AMD GPUs, we show initial results that indicate our framework can yield reasonable performance on a new platform with minimal effort.
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size
Nov 04, 2016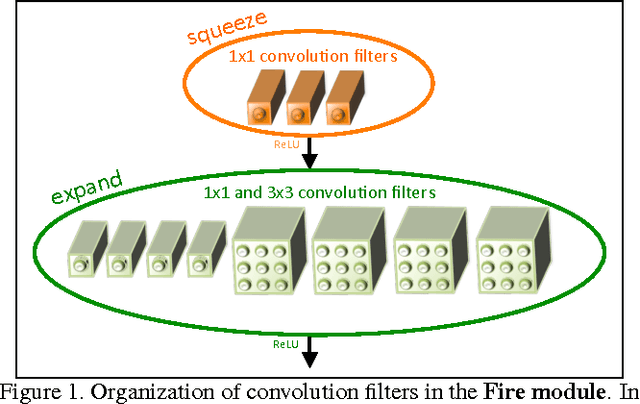
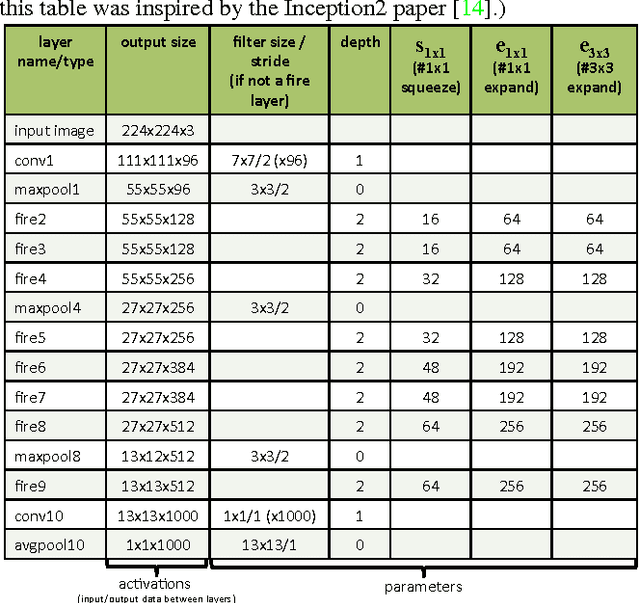
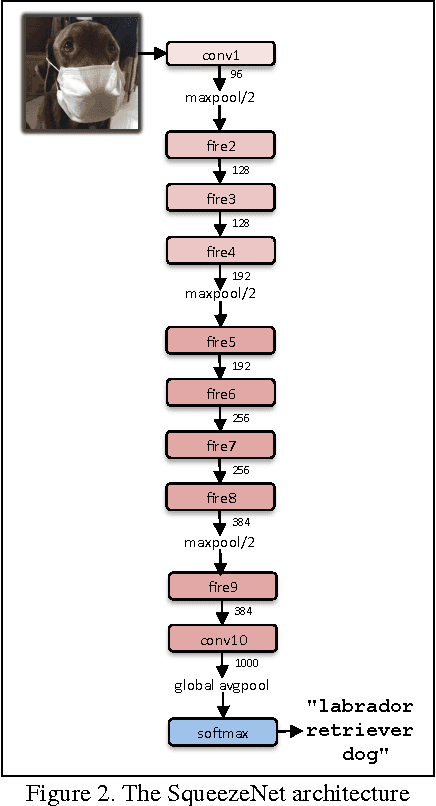
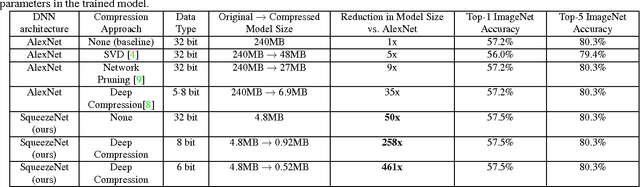
Recent research on deep neural networks has focused primarily on improving accuracy. For a given accuracy level, it is typically possible to identify multiple DNN architectures that achieve that accuracy level. With equivalent accuracy, smaller DNN architectures offer at least three advantages: (1) Smaller DNNs require less communication across servers during distributed training. (2) Smaller DNNs require less bandwidth to export a new model from the cloud to an autonomous car. (3) Smaller DNNs are more feasible to deploy on FPGAs and other hardware with limited memory. To provide all of these advantages, we propose a small DNN architecture called SqueezeNet. SqueezeNet achieves AlexNet-level accuracy on ImageNet with 50x fewer parameters. Additionally, with model compression techniques we are able to compress SqueezeNet to less than 0.5MB (510x smaller than AlexNet). The SqueezeNet architecture is available for download here: https://github.com/DeepScale/SqueezeNet
FireCaffe: near-linear acceleration of deep neural network training on compute clusters
Jan 08, 2016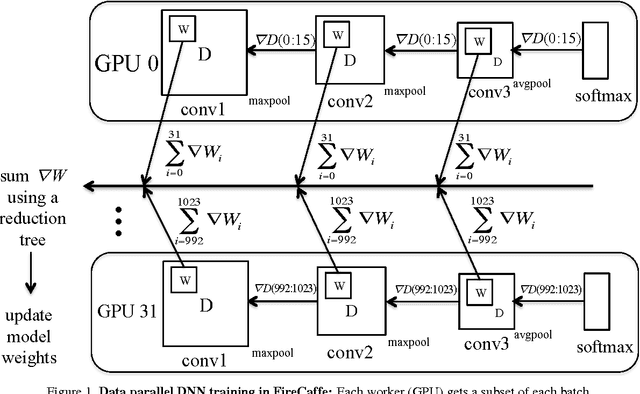

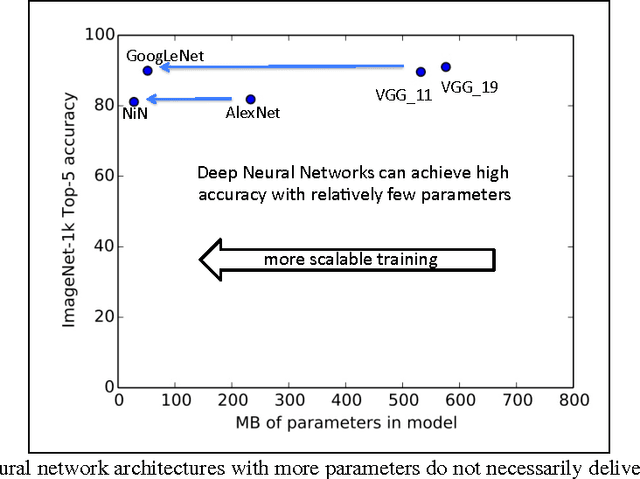
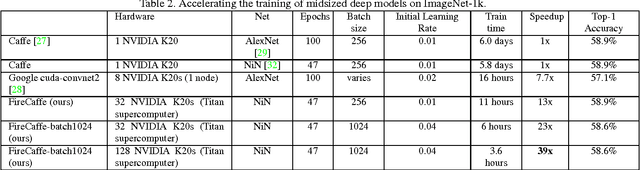
Long training times for high-accuracy deep neural networks (DNNs) impede research into new DNN architectures and slow the development of high-accuracy DNNs. In this paper we present FireCaffe, which successfully scales deep neural network training across a cluster of GPUs. We also present a number of best practices to aid in comparing advancements in methods for scaling and accelerating the training of deep neural networks. The speed and scalability of distributed algorithms is almost always limited by the overhead of communicating between servers; DNN training is not an exception to this rule. Therefore, the key consideration here is to reduce communication overhead wherever possible, while not degrading the accuracy of the DNN models that we train. Our approach has three key pillars. First, we select network hardware that achieves high bandwidth between GPU servers -- Infiniband or Cray interconnects are ideal for this. Second, we consider a number of communication algorithms, and we find that reduction trees are more efficient and scalable than the traditional parameter server approach. Third, we optionally increase the batch size to reduce the total quantity of communication during DNN training, and we identify hyperparameters that allow us to reproduce the small-batch accuracy while training with large batch sizes. When training GoogLeNet and Network-in-Network on ImageNet, we achieve a 47x and 39x speedup, respectively, when training on a cluster of 128 GPUs.