 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpreting CLIP with Sparse Linear Concept Embeddings (SpLiCE)
Feb 16, 2024



CLIP embeddings have demonstrated remarkable performance across a wide range of computer vision tasks. However, these high-dimensional, dense vector representations are not easily interpretable, restricting their usefulness in downstream applications that require transparency. In this work, we empirically show that CLIP's latent space is highly structured, and consequently that CLIP representations can be decomposed into their underlying semantic components. We leverage this understanding to propose a novel method, Sparse Linear Concept Embeddings (SpLiCE), for transforming CLIP representations into sparse linear combinations of human-interpretable concepts. Distinct from previous work, SpLiCE does not require concept labels and can be applied post hoc. Through extensive experimentation with multiple real-world datasets, we validate that the representations output by SpLiCE can explain and even replace traditional dense CLIP representations, maintaining equivalent downstream performance while significantly improving their interpretability. We also demonstrate several use cases of SpLiCE representations including detecting spurious correlations, model editing, and quantifying semantic shifts in datasets.
Multi-Group Fairness Evaluation via Conditional Value-at-Risk Testing
Dec 06, 2023Machine learning (ML) models used in prediction and classification tasks may display performance disparities across population groups determined by sensitive attributes (e.g., race, sex, age). We consider the problem of evaluating the performance of a fixed ML model across population groups defined by multiple sensitive attributes (e.g., race and sex and age). Here, the sample complexity for estimating the worst-case performance gap across groups (e.g., the largest difference in error rates) increases exponentially with the number of group-denoting sensitive attributes. To address this issue, we propose an approach to test for performance disparities based on Conditional Value-at-Risk (CVaR). By allowing a small probabilistic slack on the groups over which a model has approximately equal performance, we show that the sample complexity required for discovering performance violations is reduced exponentially to be at most upper bounded by the square root of the number of groups. As a byproduct of our analysis, when the groups are weighted by a specific prior distribution, we show that R\'enyi entropy of order $2/3$ of the prior distribution captures the sample complexity of the proposed CVaR test algorithm. Finally, we also show that there exists a non-i.i.d. data collection strategy that results in a sample complexity independent of the number of groups.
Differentially Private Secure Multiplication: Hiding Information in the Rubble of Noise
Sep 28, 2023We consider the problem of private distributed multi-party multiplication. It is well-established that Shamir secret-sharing coding strategies can enable perfect information-theoretic privacy in distributed computation via the celebrated algorithm of Ben Or, Goldwasser and Wigderson (the "BGW algorithm"). However, perfect privacy and accuracy require an honest majority, that is, $N \geq 2t+1$ compute nodes are required to ensure privacy against any $t$ colluding adversarial nodes. By allowing for some controlled amount of information leakage and approximate multiplication instead of exact multiplication, we study coding schemes for the setting where the number of honest nodes can be a minority, that is $N< 2t+1.$ We develop a tight characterization privacy-accuracy trade-off for cases where $N < 2t+1$ by measuring information leakage using {differential} privacy instead of perfect privacy, and using the mean squared error metric for accuracy. A novel technical aspect is an intricately layered noise distribution that merges ideas from differential privacy and Shamir secret-sharing at different layers.
Fair Machine Unlearning: Data Removal while Mitigating Disparities
Jul 27, 2023



As public consciousness regarding the collection and use of personal information by corporations grows, it is of increasing importance that consumers be active participants in the curation of corporate datasets. In light of this, data governance frameworks such as the General Data Protection Regulation (GDPR) have outlined the right to be forgotten as a key principle allowing individuals to request that their personal data be deleted from the databases and models used by organizations. To achieve forgetting in practice, several machine unlearning methods have been proposed to address the computational inefficiencies of retraining a model from scratch with each unlearning request. While efficient online alternatives to retraining, it is unclear how these methods impact other properties critical to real-world applications, such as fairness. In this work, we propose the first fair machine unlearning method that can provably and efficiently unlearn data instances while preserving group fairness. We derive theoretical results which demonstrate that our method can provably unlearn data instances while maintaining fairness objectives. Extensive experimentation with real-world datasets highlight the efficacy of our method at unlearning data instances while preserving fairness.
Arbitrariness Lies Beyond the Fairness-Accuracy Frontier
Jun 15, 2023



Machine learning tasks may admit multiple competing models that achieve similar performance yet produce conflicting outputs for individual samples -- a phenomenon known as predictive multiplicity. We demonstrate that fairness interventions in machine learning optimized solely for group fairness and accuracy can exacerbate predictive multiplicity. Consequently, state-of-the-art fairness interventions can mask high predictive multiplicity behind favorable group fairness and accuracy metrics. We argue that a third axis of ``arbitrariness'' should be considered when deploying models to aid decision-making in applications of individual-level impact. To address this challenge, we propose an ensemble algorithm applicable to any fairness intervention that provably ensures more consistent predictions.
Adapting Fairness Interventions to Missing Values
May 30, 2023Missing values in real-world data pose a significant and unique challenge to algorithmic fairness. Different demographic groups may be unequally affected by missing data, and the standard procedure for handling missing values where first data is imputed, then the imputed data is used for classification -- a procedure referred to as "impute-then-classify" -- can exacerbate discrimination. In this paper, we analyze how missing values affect algorithmic fairness. We first prove that training a classifier from imputed data can significantly worsen the achievable values of group fairness and average accuracy. This is because imputing data results in the loss of the missing pattern of the data, which often conveys information about the predictive label. We present scalable and adaptive algorithms for fair classification with missing values. These algorithms can be combined with any preexisting fairness-intervention algorithm to handle all possible missing patterns while preserving information encoded within the missing patterns. Numerical experiments with state-of-the-art fairness interventions demonstrate that our adaptive algorithms consistently achieve higher fairness and accuracy than impute-then-classify across different datasets.
Gaussian Max-Value Entropy Search for Multi-Agent Bayesian Optimization
Mar 10, 2023



We study the multi-agent Bayesian optimization (BO) problem, where multiple agents maximize a black-box function via iterative queries. We focus on Entropy Search (ES), a sample-efficient BO algorithm that selects queries to maximize the mutual information about the maximum of the black-box function. One of the main challenges of ES is that calculating the mutual information requires computationally-costly approximation techniques. For multi-agent BO problems, the computational cost of ES is exponential in the number of agents. To address this challenge, we propose the Gaussian Max-value Entropy Search, a multi-agent BO algorithm with favorable sample and computational efficiency. The key to our idea is to use a normal distribution to approximate the function maximum and calculate its mutual information accordingly. The resulting approximation allows queries to be cast as the solution of a closed-form optimization problem which, in turn, can be solved via a modified gradient ascent algorithm and scaled to a large number of agents. We demonstrate the effectiveness of Gaussian max-value Entropy Search through numerical experiments on standard test functions and real-robot experiments on the source-seeking problem. Results show that the proposed algorithm outperforms the multi-agent BO baselines in the numerical experiments and can stably seek the source with a limited number of noisy observations on real robots.
Arbitrary Decisions are a Hidden Cost of Differentially-Private Training
Feb 28, 2023



Mechanisms used in privacy-preserving machine learning often aim to guarantee differential privacy (DP) during model training. Practical DP-ensuring training methods use randomization when fitting model parameters to privacy-sensitive data (e.g., adding Gaussian noise to clipped gradients). We demonstrate that such randomization incurs predictive multiplicity: for a given input example, the output predicted by equally-private models depends on the randomness used in training. Thus, for a given input, the predicted output can vary drastically if a model is re-trained, even if the same training dataset is used. The predictive-multiplicity cost of DP training has not been studied, and is currently neither audited for nor communicated to model designers and stakeholders. We derive a bound on the number of re-trainings required to estimate predictive multiplicity reliably. We analyze -- both theoretically and through extensive experiments -- the predictive-multiplicity cost of three DP-ensuring algorithms: output perturbation, objective perturbation, and DP-SGD. We demonstrate that the degree of predictive multiplicity rises as the level of privacy increases, and is unevenly distributed across individuals and demographic groups in the data. Because randomness used to ensure DP during training explains predictions for some examples, our results highlight a fundamental challenge to the justifiability of decisions supported by differentially-private models in high-stakes settings. We conclude that practitioners should audit the predictive multiplicity of their DP-ensuring algorithms before deploying them in applications of individual-level consequence.
Aleatoric and Epistemic Discrimination in Classification
Jan 27, 2023



Machine learning (ML) models can underperform on certain population groups due to choices made during model development and bias inherent in the data. We categorize sources of discrimination in the ML pipeline into two classes: aleatoric discrimination, which is inherent in the data distribution, and epistemic discrimination, which is due to decisions during model development. We quantify aleatoric discrimination by determining the performance limits of a model under fairness constraints, assuming perfect knowledge of the data distribution. We demonstrate how to characterize aleatoric discrimination by applying Blackwell's results on comparing statistical experiments. We then quantify epistemic discrimination as the gap between a model's accuracy given fairness constraints and the limit posed by aleatoric discrimination. We apply this approach to benchmark existing interventions and investigate fairness risks in data with missing values. Our results indicate that state-of-the-art fairness interventions are effective at removing epistemic discrimination. However, when data has missing values, there is still significant room for improvement in handling aleatoric discrimination.
Automated Segmentation and Recurrence Risk Prediction of Surgically Resected Lung Tumors with Adaptive Convolutional Neural Networks
Sep 17, 2022

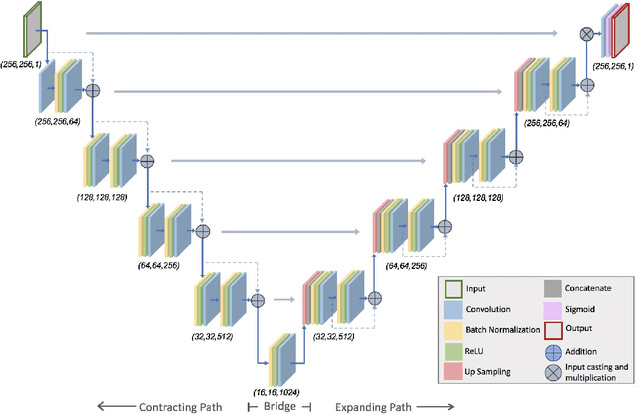

Lung cancer is the leading cause of cancer related mortality by a significant margin. While new technologies, such as image segmentation, have been paramount to improved detection and earlier diagnoses, there are still significant challenges in treating the disease. In particular, despite an increased number of curative resections, many postoperative patients still develop recurrent lesions. Consequently, there is a significant need for prognostic tools that can more accurately predict a patient's risk for recurrence. In this paper, we explore the use of convolutional neural networks (CNNs) for the segmentation and recurrence risk prediction of lung tumors that are present in preoperative computed tomography (CT) images. First, expanding upon recent progress in medical image segmentation, a residual U-Net is used to localize and characterize each nodule. Then, the identified tumors are passed to a second CNN for recurrence risk prediction. The system's final results are produced with a random forest classifier that synthesizes the predictions of the second network with clinical attributes. The segmentation stage uses the LIDC-IDRI dataset and achieves a dice score of 70.3%. The recurrence risk stage uses the NLST dataset from the National Cancer institute and achieves an AUC of 73.0%. Our proposed framework demonstrates that first, automated nodule segmentation methods can generalize to enable pipelines for a wide range of multitask systems and second, that deep learning and image processing have the potential to improve current prognostic tools. To the best of our knowledge, it is the first fully automated segmentation and recurrence risk prediction system.