 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Reward Hacking in Large Language Models
Jun 24, 2025


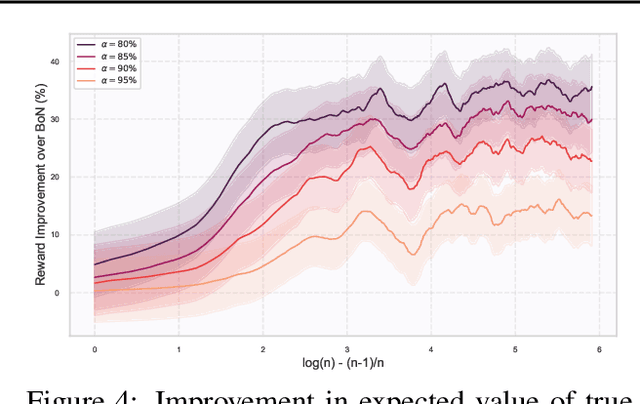
A common paradigm to improve the performance of large language models is optimizing for a reward model. Reward models assign a numerical score to LLM outputs indicating, for example, which response would likely be preferred by a user or is most aligned with safety goals. However, reward models are never perfect. They inevitably function as proxies for complex desiderata such as correctness, helpfulness, and safety. By overoptimizing for a misspecified reward, we can subvert intended alignment goals and reduce overall performance -- a phenomenon commonly referred to as reward hacking. In this work, we characterize reward hacking in inference-time alignment and demonstrate when and how we can mitigate it by hedging on the proxy reward. We study this phenomenon under Best-of-$n$ (BoN) and Soft-Best-of-$n$ (SBoN), and we introduce Best-of-Poisson (BoP) that provides an efficient, near-exact approximation of the optimal reward-KL divergence policy at inference time. We show that the characteristic pattern of hacking as observed in practice (where the true reward first increases before declining) is an inevitable property of a broad class of inference-time mechanisms, including BoN and BoP. To counter this effect, hedging offers a tactical choice to avoid placing undue confidence in high but potentially misleading proxy reward signals. We introduce HedgeTune, an efficient algorithm to find the optimal inference-time parameter and avoid reward hacking. We demonstrate through experiments that hedging mitigates reward hacking and achieves superior distortion-reward tradeoffs with minimal computational overhead.
Multi-Group Proportional Representation for Text-to-Image Models
May 29, 2025



Text-to-image (T2I) generative models can create vivid, realistic images from textual descriptions. As these models proliferate, they expose new concerns about their ability to represent diverse demographic groups, propagate stereotypes, and efface minority populations. Despite growing attention to the "safe" and "responsible" design of artificial intelligence (AI), there is no established methodology to systematically measure and control representational harms in image generation. This paper introduces a novel framework to measure the representation of intersectional groups in images generated by T2I models by applying the Multi-Group Proportional Representation (MPR) metric. MPR evaluates the worst-case deviation of representation statistics across given population groups in images produced by a generative model, allowing for flexible and context-specific measurements based on user requirements. We also develop an algorithm to optimize T2I models for this metric. Through experiments, we demonstrate that MPR can effectively measure representation statistics across multiple intersectional groups and, when used as a training objective, can guide models toward a more balanced generation across demographic groups while maintaining generation quality.
Soft Best-of-n Sampling for Model Alignment
May 06, 2025
Best-of-$n$ (BoN) sampling is a practical approach for aligning language model outputs with human preferences without expensive fine-tuning. BoN sampling is performed by generating $n$ responses to a prompt and then selecting the sample that maximizes a reward function. BoN yields high reward values in practice at a distortion cost, as measured by the KL-divergence between the sampled and original distribution. This distortion is coarsely controlled by varying the number of samples: larger $n$ yields a higher reward at a higher distortion cost. We introduce Soft Best-of-$n$ sampling, a generalization of BoN that allows for smooth interpolation between the original distribution and reward-maximizing distribution through a temperature parameter $\lambda$. We establish theoretical guarantees showing that Soft Best-of-$n$ sampling converges sharply to the optimal tilted distribution at a rate of $O(1/n)$ in KL and the expected (relative) reward. For sequences of discrete outputs, we analyze an additive reward model that reveals the fundamental limitations of blockwise sampling.
All Roads Lead to Rome? Exploring Representational Similarities Between Latent Spaces of Generative Image Models
Jul 18, 2024



Do different generative image models secretly learn similar underlying representations? We investigate this by measuring the latent space similarity of four different models: VAEs, GANs, Normalizing Flows (NFs), and Diffusion Models (DMs). Our methodology involves training linear maps between frozen latent spaces to "stitch" arbitrary pairs of encoders and decoders and measuring output-based and probe-based metrics on the resulting "stitched'' models. Our main findings are that linear maps between latent spaces of performant models preserve most visual information even when latent sizes differ; for CelebA models, gender is the most similarly represented probe-able attribute. Finally we show on an NF that latent space representations converge early in training.
Multi-Group Proportional Representation
Jul 11, 2024Image search and retrieval tasks can perpetuate harmful stereotypes, erase cultural identities, and amplify social disparities. Current approaches to mitigate these representational harms balance the number of retrieved items across population groups defined by a small number of (often binary) attributes. However, most existing methods overlook intersectional groups determined by combinations of group attributes, such as gender, race, and ethnicity. We introduce Multi-Group Proportional Representation (MPR), a novel metric that measures representation across intersectional groups. We develop practical methods for estimating MPR, provide theoretical guarantees, and propose optimization algorithms to ensure MPR in retrieval. We demonstrate that existing methods optimizing for equal and proportional representation metrics may fail to promote MPR. Crucially, our work shows that optimizing MPR yields more proportional representation across multiple intersectional groups specified by a rich function class, often with minimal compromise in retrieval accuracy.
Operationalizing the Blueprint for an AI Bill of Rights: Recommendations for Practitioners, Researchers, and Policy Makers
Jul 11, 2024As Artificial Intelligence (AI) tools are increasingly employed in diverse real-world applications, there has been significant interest in regulating these tools. To this end, several regulatory frameworks have been introduced by different countries worldwide. For example, the European Union recently passed the AI Act, the White House issued an Executive Order on safe, secure, and trustworthy AI, and the White House Office of Science and Technology Policy issued the Blueprint for an AI Bill of Rights (AI BoR). Many of these frameworks emphasize the need for auditing and improving the trustworthiness of AI tools, underscoring the importance of safety, privacy, explainability, fairness, and human fallback options. Although these regulatory frameworks highlight the necessity of enforcement, practitioners often lack detailed guidance on implementing them. Furthermore, the extensive research on operationalizing each of these aspects is frequently buried in technical papers that are difficult for practitioners to parse. In this write-up, we address this shortcoming by providing an accessible overview of existing literature related to operationalizing regulatory principles. We provide easy-to-understand summaries of state-of-the-art literature and highlight various gaps that exist between regulatory guidelines and existing AI research, including the trade-offs that emerge during operationalization. We hope that this work not only serves as a starting point for practitioners interested in learning more about operationalizing the regulatory guidelines outlined in the Blueprint for an AI BoR but also provides researchers with a list of critical open problems and gaps between regulations and state-of-the-art AI research. Finally, we note that this is a working paper and we invite feedback in line with the purpose of this document as described in the introduction.
Interpreting CLIP with Sparse Linear Concept Embeddings (SpLiCE)
Feb 16, 2024



CLIP embeddings have demonstrated remarkable performance across a wide range of computer vision tasks. However, these high-dimensional, dense vector representations are not easily interpretable, restricting their usefulness in downstream applications that require transparency. In this work, we empirically show that CLIP's latent space is highly structured, and consequently that CLIP representations can be decomposed into their underlying semantic components. We leverage this understanding to propose a novel method, Sparse Linear Concept Embeddings (SpLiCE), for transforming CLIP representations into sparse linear combinations of human-interpretable concepts. Distinct from previous work, SpLiCE does not require concept labels and can be applied post hoc. Through extensive experimentation with multiple real-world datasets, we validate that the representations output by SpLiCE can explain and even replace traditional dense CLIP representations, maintaining equivalent downstream performance while significantly improving their interpretability. We also demonstrate several use cases of SpLiCE representations including detecting spurious correlations, model editing, and quantifying semantic shifts in datasets.
Fair Machine Unlearning: Data Removal while Mitigating Disparities
Jul 27, 2023



As public consciousness regarding the collection and use of personal information by corporations grows, it is of increasing importance that consumers be active participants in the curation of corporate datasets. In light of this, data governance frameworks such as the General Data Protection Regulation (GDPR) have outlined the right to be forgotten as a key principle allowing individuals to request that their personal data be deleted from the databases and models used by organizations. To achieve forgetting in practice, several machine unlearning methods have been proposed to address the computational inefficiencies of retraining a model from scratch with each unlearning request. While efficient online alternatives to retraining, it is unclear how these methods impact other properties critical to real-world applications, such as fairness. In this work, we propose the first fair machine unlearning method that can provably and efficiently unlearn data instances while preserving group fairness. We derive theoretical results which demonstrate that our method can provably unlearn data instances while maintaining fairness objectives. Extensive experimentation with real-world datasets highlight the efficacy of our method at unlearning data instances while preserving fairness.
Distributionally Robust Group Backwards Compatibility
Dec 20, 2021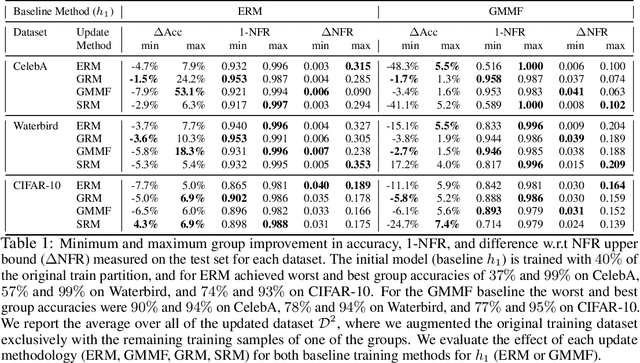
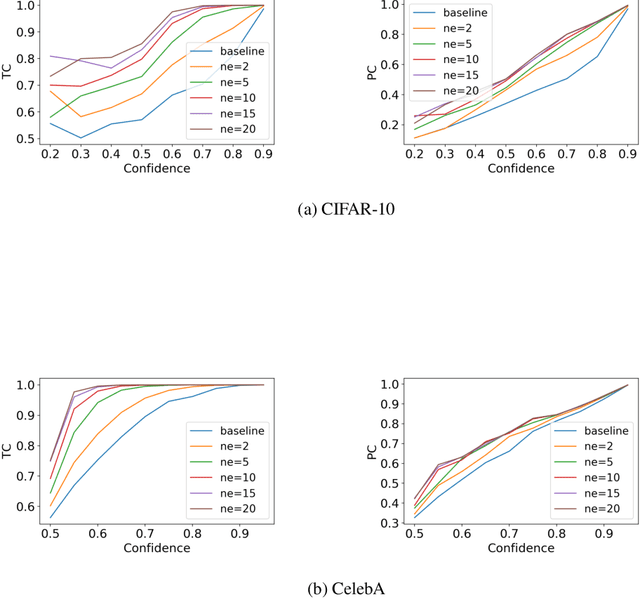
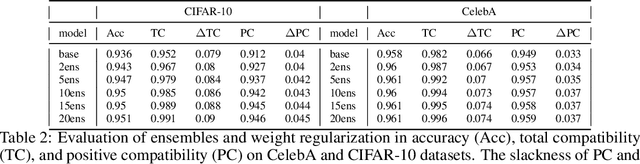

Machine learning models are updated as new data is acquired or new architectures are developed. These updates usually increase model performance, but may introduce backward compatibility errors, where individual users or groups of users see their performance on the updated model adversely affected. This problem can also be present when training datasets do not accurately reflect overall population demographics, with some groups having overall lower participation in the data collection process, posing a significant fairness concern. We analyze how ideas from distributional robustness and minimax fairness can aid backward compatibility in this scenario, and propose two methods to directly address this issue. Our theoretical analysis is backed by experimental results on CIFAR-10, CelebA, and Waterbirds, three standard image classification datasets. Code available at github.com/natalialmg/GroupBC
Multitask Learning for Citation Purpose Classification
Jun 24, 2021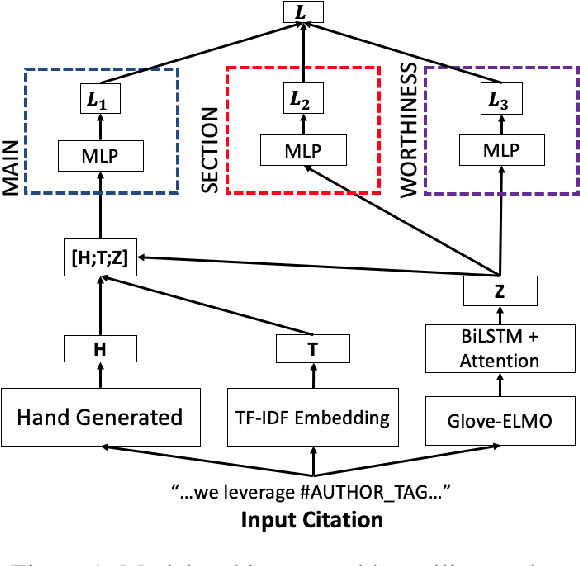
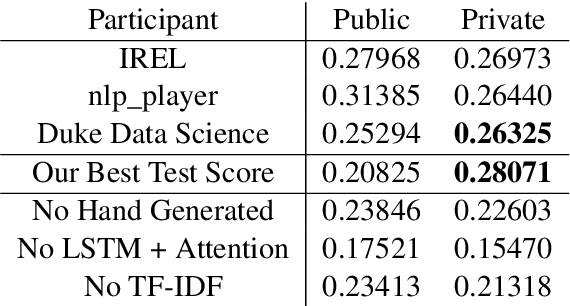
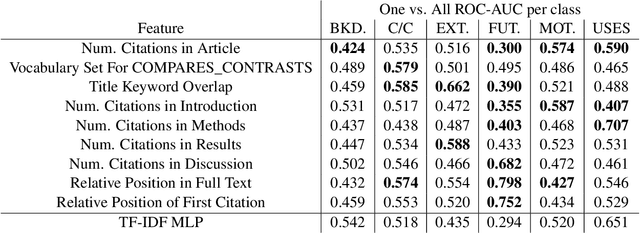
We present our entry into the 2021 3C Shared Task Citation Context Classification based on Purpose competition. The goal of the competition is to classify a citation in a scientific article based on its purpose. This task is important because it could potentially lead to more comprehensive ways of summarizing the purpose and uses of scientific articles, but it is also difficult, mainly due to the limited amount of available training data in which the purposes of each citation have been hand-labeled, along with the subjectivity of these labels. Our entry in the competition is a multi-task model that combines multiple modules designed to handle the problem from different perspectives, including hand-generated linguistic features, TF-IDF features, and an LSTM-with-attention model. We also provide an ablation study and feature analysis whose insights could lead to future work.