 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
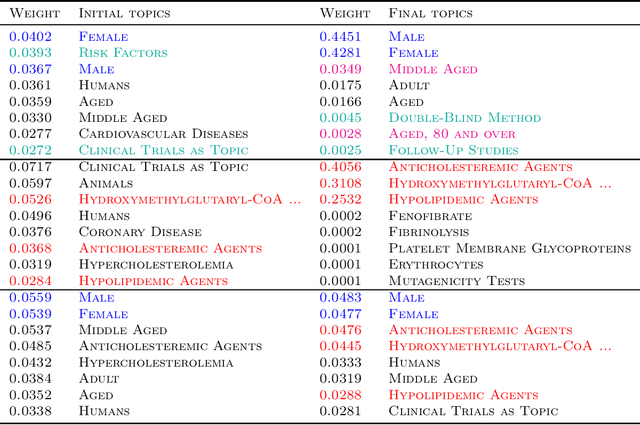
Add to EdgePrediction Focused Topic Models via Vocab Selection
Oct 12, 2019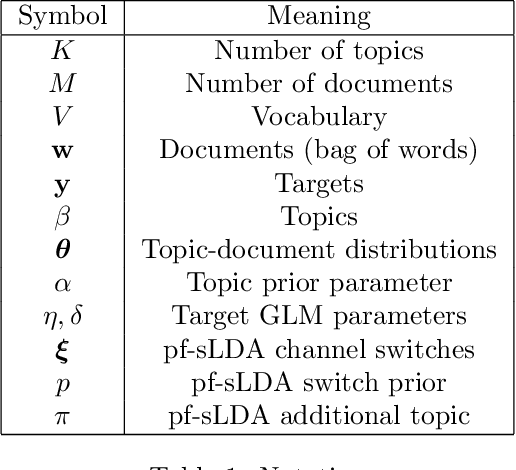

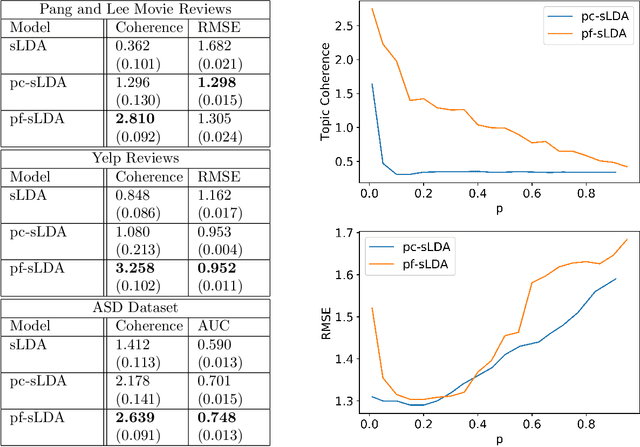
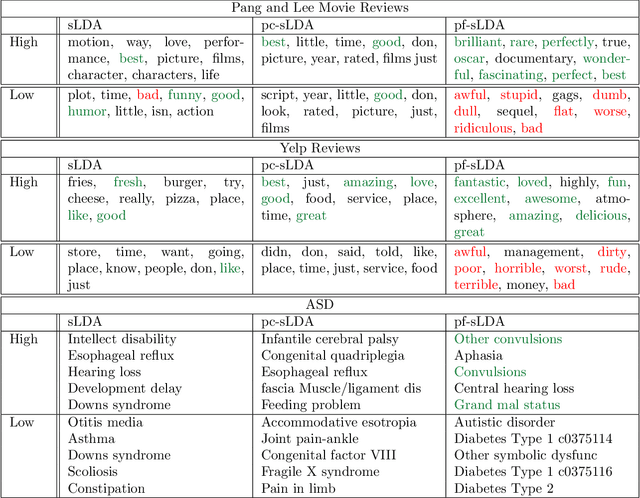
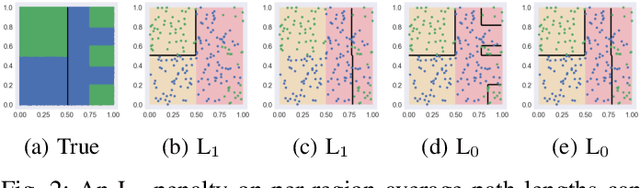
Supervised topic models are often sought to balance prediction quality and interpretability. However, when models are (inevitably) misspecified, standard approaches rarely deliver on both. We introduce a novel approach, the prediction-focused topic model, that uses the supervisory signal to retain only vocabulary terms that improve, or do not hinder, prediction performance. By removing terms with irrelevant signal, the topic model is able to learn task-relevant, interpretable topics. We demonstrate on several data sets that compared to existing approaches, prediction-focused topic models are able to learn much more coherent topics while maintaining competitive predictions.
Optimizing for Interpretability in Deep Neural Networks with Tree Regularization
Aug 14, 2019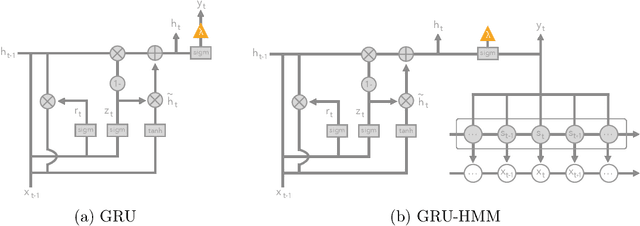
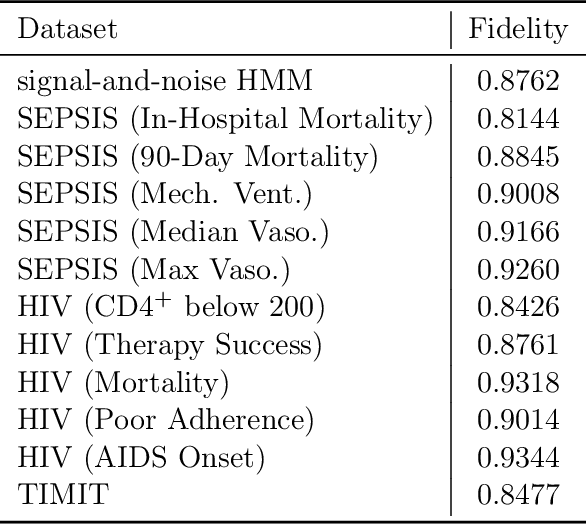
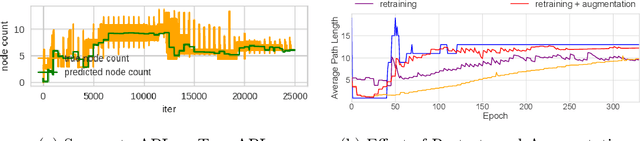
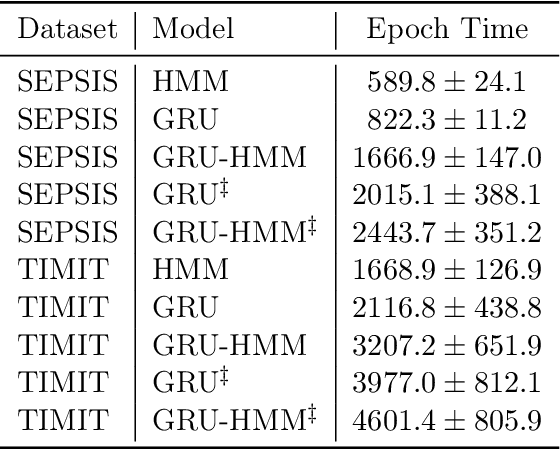
Deep models have advanced prediction in many domains, but their lack of interpretability remains a key barrier to the adoption in many real world applications. There exists a large body of work aiming to help humans understand these black box functions to varying levels of granularity -- for example, through distillation, gradients, or adversarial examples. These methods however, all tackle interpretability as a separate process after training. In this work, we take a different approach and explicitly regularize deep models so that they are well-approximated by processes that humans can step-through in little time. Specifically, we train several families of deep neural networks to resemble compact, axis-aligned decision trees without significant compromises in accuracy. The resulting axis-aligned decision functions uniquely make tree regularized models easy for humans to interpret. Moreover, for situations in which a single, global tree is a poor estimator, we introduce a regional tree regularizer that encourages the deep model to resemble a compact, axis-aligned decision tree in predefined, human-interpretable contexts. Using intuitive toy examples as well as medical tasks for patients in critical care and with HIV, we demonstrate that this new family of tree regularizers yield models that are easier for humans to simulate than simpler L1 or L2 penalties without sacrificing predictive power.
Regional Tree Regularization for Interpretability in Black Box Models
Aug 13, 2019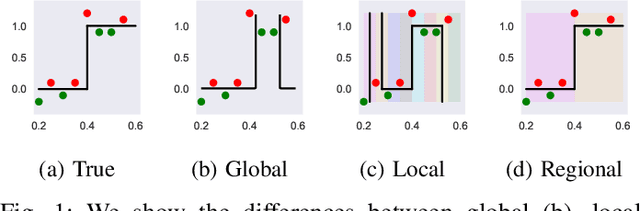

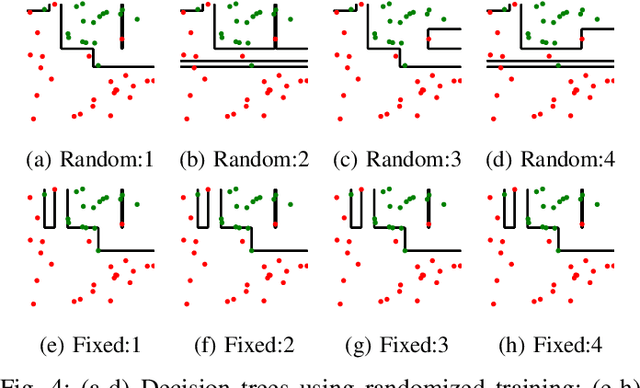
The lack of interpretability remains a barrier to the adoption of deep neural networks. Recently, tree regularization has been proposed to encourage deep neural networks to resemble compact, axis-aligned decision trees without significant compromises in accuracy. However, it may be unreasonable to expect that a single tree can predict well across all possible inputs. In this work, we propose regional tree regularization, which encourages a deep model to be well-approximated by several separate decision trees specific to predefined regions of the input space. Practitioners can define regions based on domain knowledge of contexts where different decision-making logic is needed. Across many datasets, our approach delivers more accurate predictions than simply training separate decision trees for each region, while producing simpler explanations than other neural net regularization schemes without sacrificing predictive power. Two healthcare case studies in critical care and HIV demonstrate how experts can improve understanding of deep models via our approach.
Quality of Uncertainty Quantification for Bayesian Neural Network Inference
Jun 24, 2019

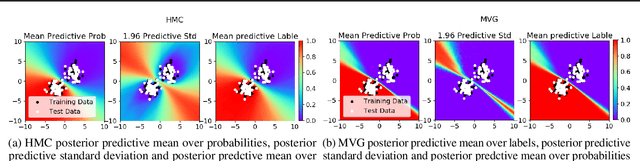

Bayesian Neural Networks (BNNs) place priors over the parameters in a neural network. Inference in BNNs, however, is difficult; all inference methods for BNNs are approximate. In this work, we empirically compare the quality of predictive uncertainty estimates for 10 common inference methods on both regression and classification tasks. Our experiments demonstrate that commonly used metrics (e.g. test log-likelihood) can be misleading. Our experiments also indicate that inference innovations designed to capture structure in the posterior do not necessarily produce high quality posterior approximations.
Diversity-Inducing Policy Gradient: Using Maximum Mean Discrepancy to Find a Set of Diverse Policies
May 31, 2019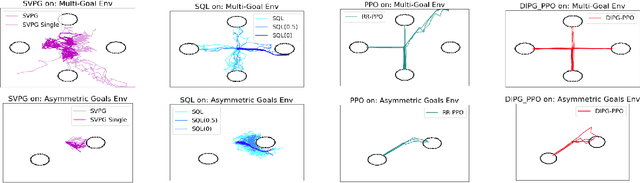

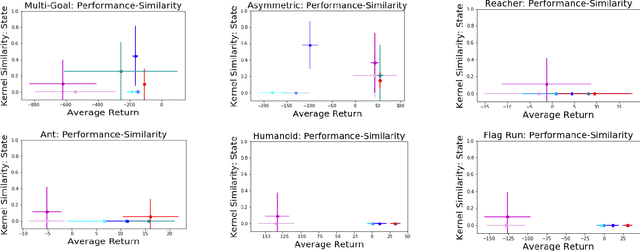
Standard reinforcement learning methods aim to master one way of solving a task whereas there may exist multiple near-optimal policies. Being able to identify this collection of near-optimal policies can allow a domain expert to efficiently explore the space of reasonable solutions. Unfortunately, existing approaches that quantify uncertainty over policies are not ultimately relevant to finding policies with qualitatively distinct behaviors. In this work, we formalize the difference between policies as a difference between the distribution of trajectories induced by each policy, which encourages diversity with respect to both state visitation and action choices. We derive a gradient-based optimization technique that can be combined with existing policy gradient methods to now identify diverse collections of well-performing policies. We demonstrate our approach on benchmarks and a healthcare task.
Exploring Computational User Models for Agent Policy Summarization
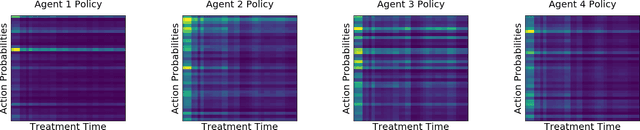
May 30, 2019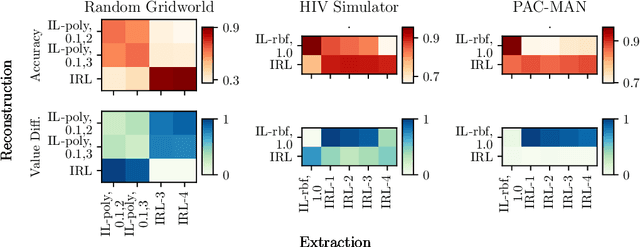

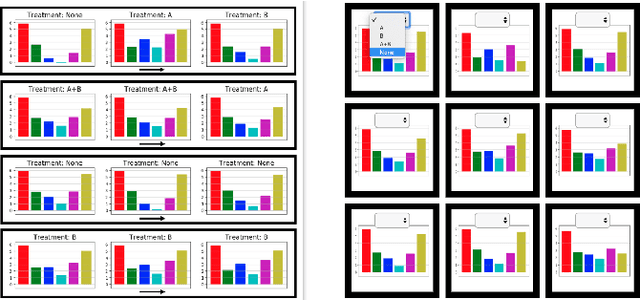

AI agents are being developed to support high stakes decision-making processes from driving cars to prescribing drugs, making it increasingly important for human users to understand their behavior. Policy summarization methods aim to convey strengths and weaknesses of such agents by demonstrating their behavior in a subset of informative states. Some policy summarization methods extract a summary that optimizes the ability to reconstruct the agent's policy under the assumption that users will deploy inverse reinforcement learning. In this paper, we explore the use of different models for extracting summaries. We introduce an imitation learning-based approach to policy summarization; we demonstrate through computational simulations that a mismatch between the model used to extract a summary and the model used to reconstruct the policy results in worse reconstruction quality; and we demonstrate through a human-subject study that people use different models to reconstruct policies in different contexts, and that matching the summary extraction model to these can improve performance. Together, our results suggest that it is important to carefully consider user models in policy summarization.
Defining Admissible Rewards for High Confidence Policy Evaluation
May 30, 2019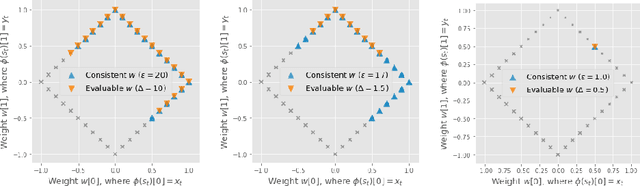

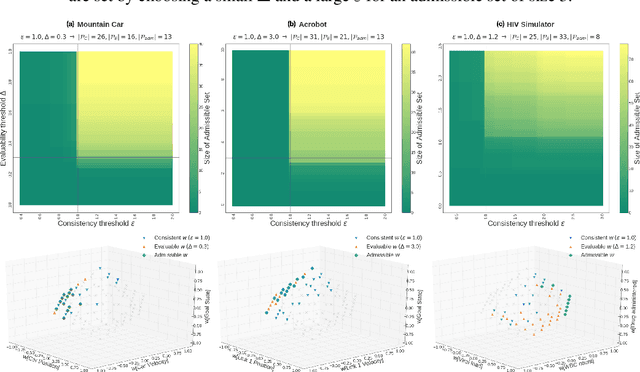

A key impediment to reinforcement learning (RL) in real applications with limited, batch data is defining a reward function that reflects what we implicitly know about reasonable behaviour for a task and allows for robust off-policy evaluation. In this work, we develop a method to identify an admissible set of reward functions for policies that (a) do not diverge too far from past behaviour, and (b) can be evaluated with high confidence, given only a collection of past trajectories. Together, these ensure that we propose policies that we trust to be implemented in high-risk settings. We demonstrate our approach to reward design on synthetic domains as well as in a critical care context, for a reward that consolidates clinical objectives to learn a policy for weaning patients from mechanical ventilation.
A general method for regularizing tensor decomposition methods via pseudo-data
May 24, 2019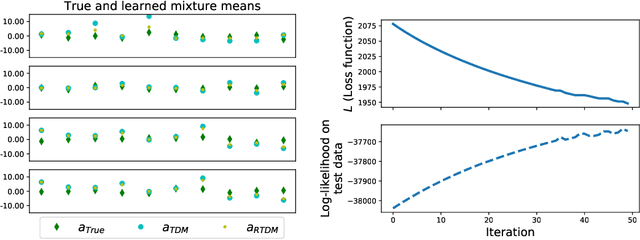
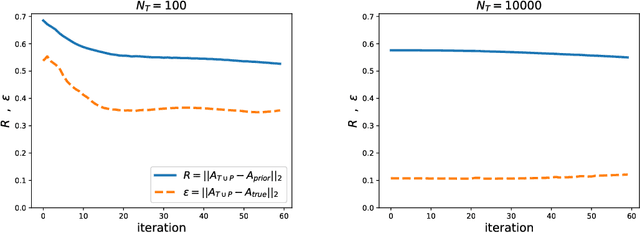
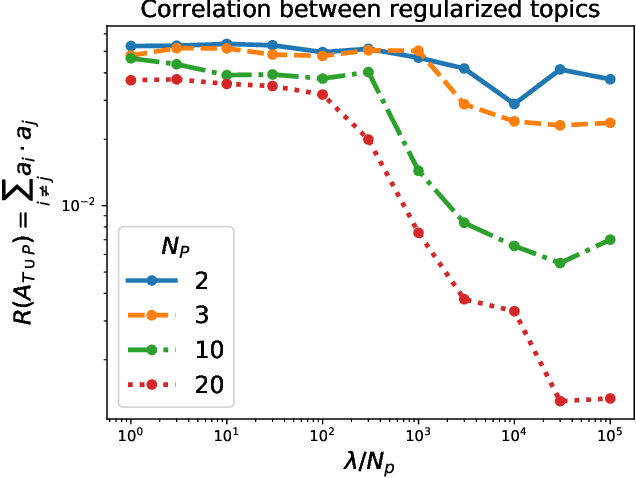
Tensor decomposition methods allow us to learn the parameters of latent variable models through decomposition of low-order moments of data. A significant limitation of these algorithms is that there exists no general method to regularize them, and in the past regularization has mostly been performed using bespoke modifications to the algorithms, tailored for the particular form of the desired regularizer. We present a general method of regularizing tensor decomposition methods which can be used for any likelihood model that is learnable using tensor decomposition methods and any differentiable regularization function by supplementing the training data with pseudo-data. The pseudo-data is optimized to balance two terms: being as close as possible to the true data and enforcing the desired regularization. On synthetic, semi-synthetic and real data, we demonstrate that our method can improve inference accuracy and regularize for a broad range of goals including transfer learning, sparsity, interpretability, and orthogonality of the learned parameters.
Combining Parametric and Nonparametric Models for Off-Policy Evaluation
May 16, 2019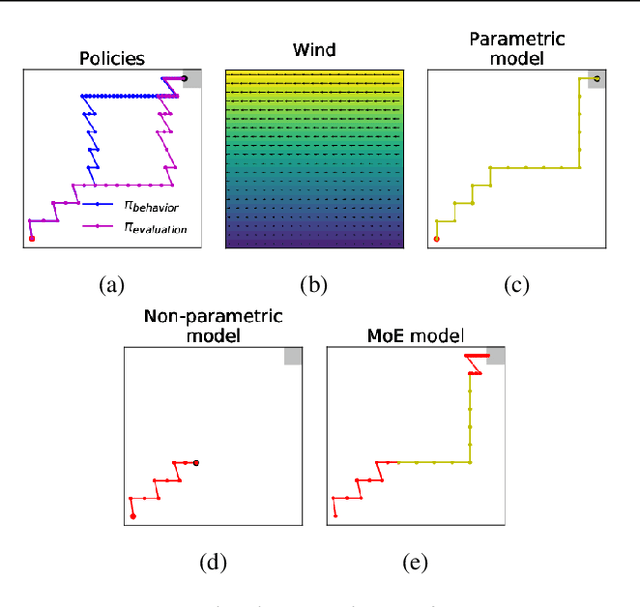

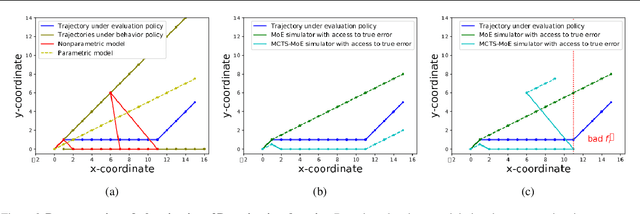

We consider a model-based approach to perform batch off-policy evaluation in reinforcement learning. Our method takes a mixture-of-experts approach to combine parametric and non-parametric models of the environment such that the final value estimate has the least expected error. We do so by first estimating the local accuracy of each model and then using a planner to select which model to use at every time step as to minimize the return error estimate along entire trajectories. Across a variety of domains, our mixture-based approach outperforms the individual models alone as well as state-of-the-art importance sampling-based estimators.
Output-Constrained Bayesian Neural Networks
May 15, 2019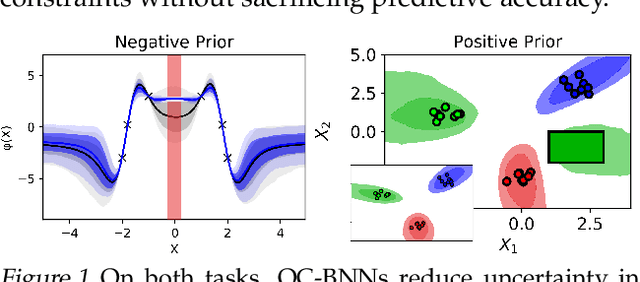
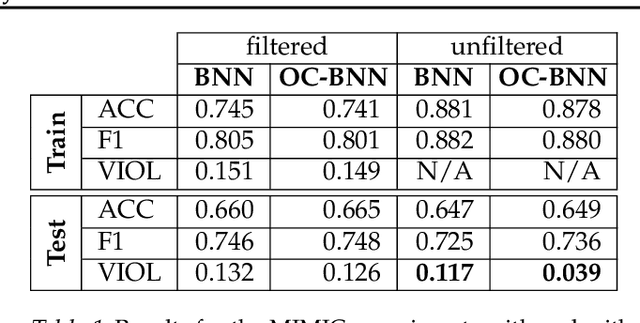
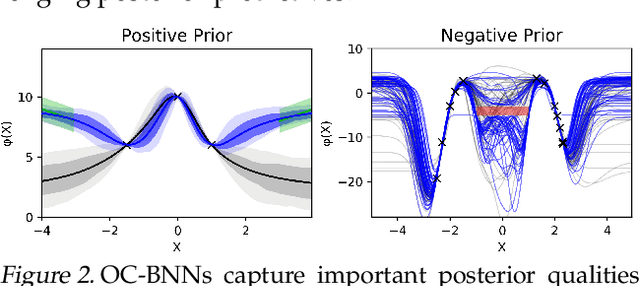
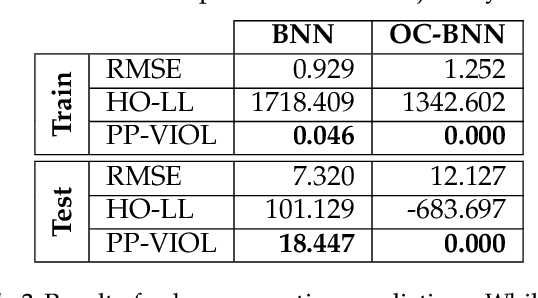
Bayesian neural network (BNN) priors are defined in parameter space, making it hard to encode prior knowledge expressed in function space. We formulate a prior that incorporates functional constraints about what the output can or cannot be in regions of the input space. Output-Constrained BNNs (OC-BNN) represent an interpretable approach of enforcing a range of constraints, fully consistent with the Bayesian framework and amenable to black-box inference. We demonstrate how OC-BNNs improve model robustness and prevent the prediction of infeasible outputs in two real-world applications of healthcare and robotics.