 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Predictive and Interpretable Timeseries Summaries from ICU Data
Sep 22, 2021
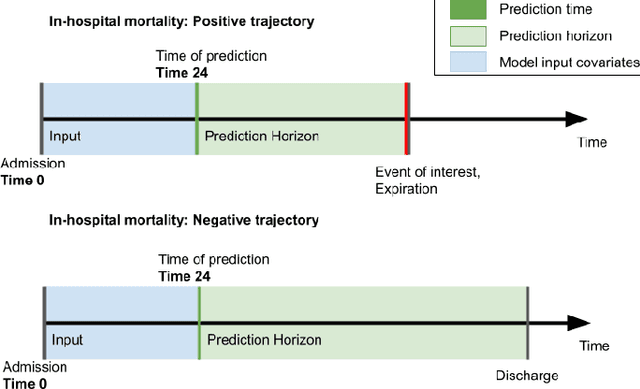
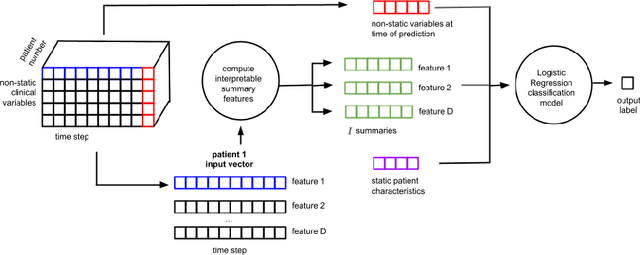
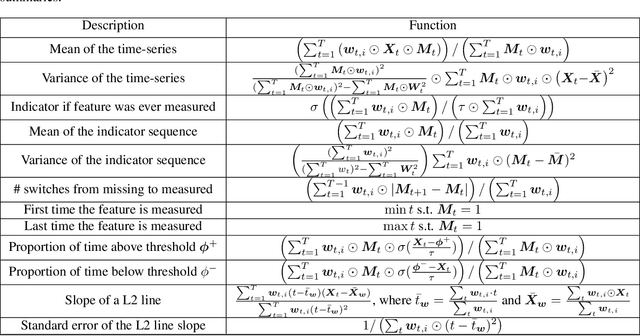
Machine learning models that utilize patient data across time (rather than just the most recent measurements) have increased performance for many risk stratification tasks in the intensive care unit. However, many of these models and their learned representations are complex and therefore difficult for clinicians to interpret, creating challenges for validation. Our work proposes a new procedure to learn summaries of clinical time-series that are both predictive and easily understood by humans. Specifically, our summaries consist of simple and intuitive functions of clinical data (e.g. falling mean arterial pressure). Our learned summaries outperform traditional interpretable model classes and achieve performance comparable to state-of-the-art deep learning models on an in-hospital mortality classification task.
Comparison and Unification of Three Regularization Methods in Batch Reinforcement Learning
Sep 16, 2021
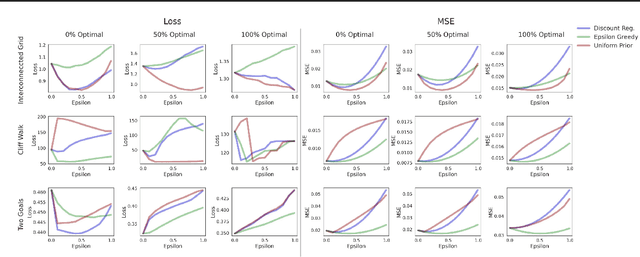
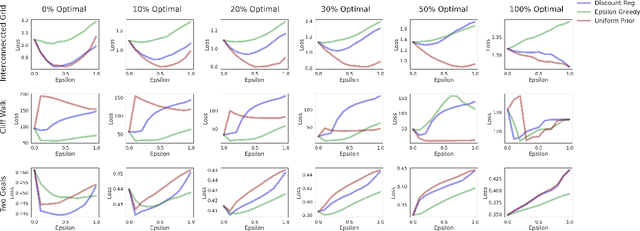
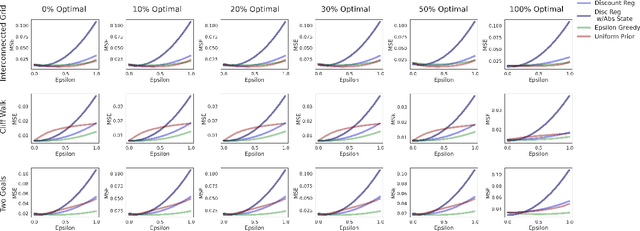
In batch reinforcement learning, there can be poorly explored state-action pairs resulting in poorly learned, inaccurate models and poorly performing associated policies. Various regularization methods can mitigate the problem of learning overly-complex models in Markov decision processes (MDPs), however they operate in technically and intuitively distinct ways and lack a common form in which to compare them. This paper unifies three regularization methods in a common framework -- a weighted average transition matrix. Considering regularization methods in this common form illuminates how the MDP structure and the state-action pair distribution of the batch data set influence the relative performance of regularization methods. We confirm intuitions generated from the common framework by empirical evaluation across a range of MDPs and data collection policies.
Pre-emptive learning-to-defer for sequential medical decision-making under uncertainty
Sep 13, 2021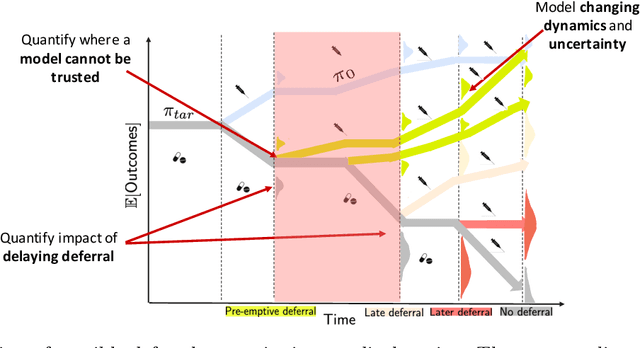
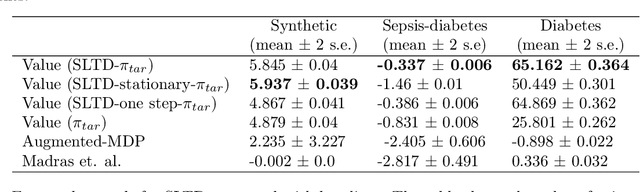
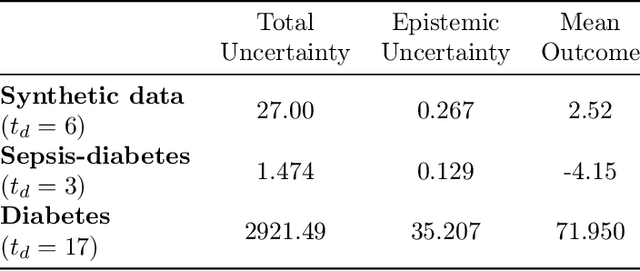
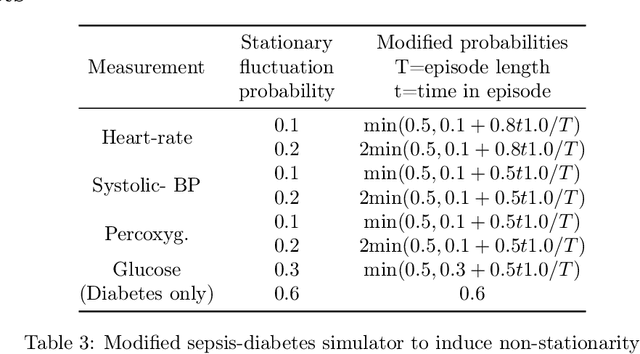
We propose SLTD (`Sequential Learning-to-Defer') a framework for learning-to-defer pre-emptively to an expert in sequential decision-making settings. SLTD measures the likelihood of improving value of deferring now versus later based on the underlying uncertainty in dynamics. In particular, we focus on the non-stationarity in the dynamics to accurately learn the deferral policy. We demonstrate our pre-emptive deferral can identify regions where the current policy has a low probability of improving outcomes. SLTD outperforms existing non-sequential learning-to-defer baselines, whilst reducing overall uncertainty on multiple synthetic and real-world simulators with non-stationary dynamics. We further derive and decompose the propagated (long-term) uncertainty for interpretation by the domain expert to provide an indication of when the model's performance is reliable.
State Relevance for Off-Policy Evaluation
Sep 13, 2021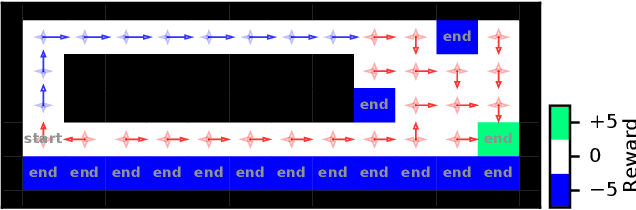
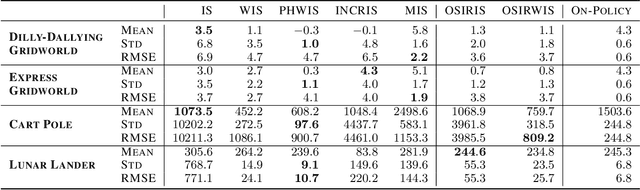
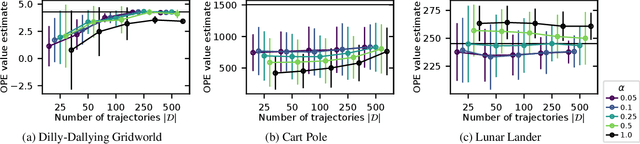
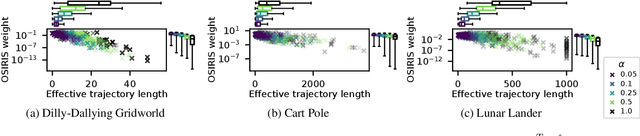
Importance sampling-based estimators for off-policy evaluation (OPE) are valued for their simplicity, unbiasedness, and reliance on relatively few assumptions. However, the variance of these estimators is often high, especially when trajectories are of different lengths. In this work, we introduce Omitting-States-Irrelevant-to-Return Importance Sampling (OSIRIS), an estimator which reduces variance by strategically omitting likelihood ratios associated with certain states. We formalize the conditions under which OSIRIS is unbiased and has lower variance than ordinary importance sampling, and we demonstrate these properties empirically.
* ICML 2021
Online structural kernel selection for mobile health
Jul 21, 2021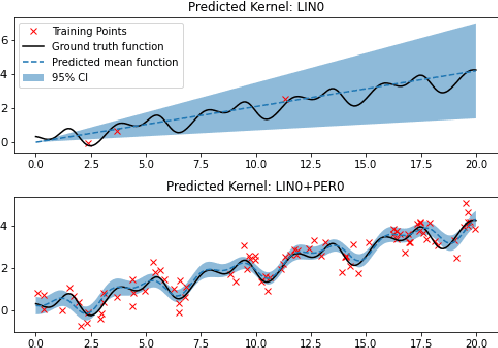
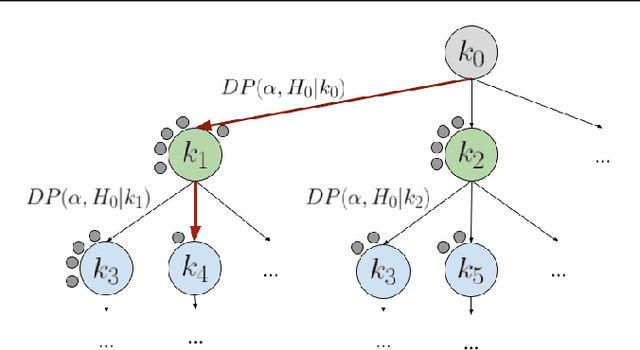
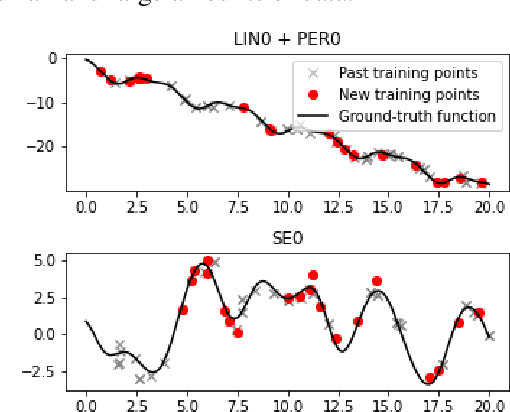
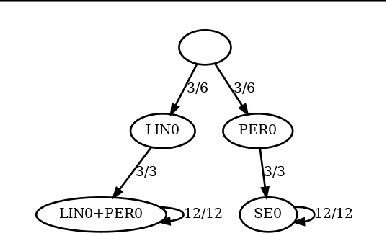
Motivated by the need for efficient and personalized learning in mobile health, we investigate the problem of online kernel selection for Gaussian Process regression in the multi-task setting. We propose a novel generative process on the kernel composition for this purpose. Our method demonstrates that trajectories of kernel evolutions can be transferred between users to improve learning and that the kernels themselves are meaningful for an mHealth prediction goal.
Promises and Pitfalls of Black-Box Concept Learning Models
Jun 24, 2021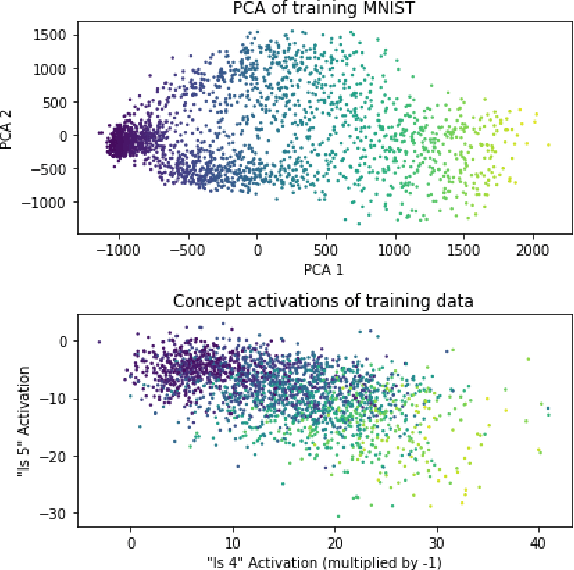
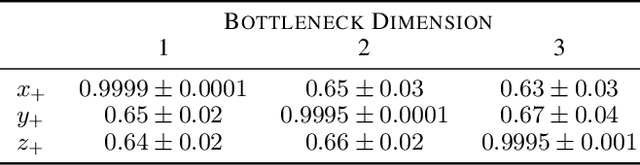
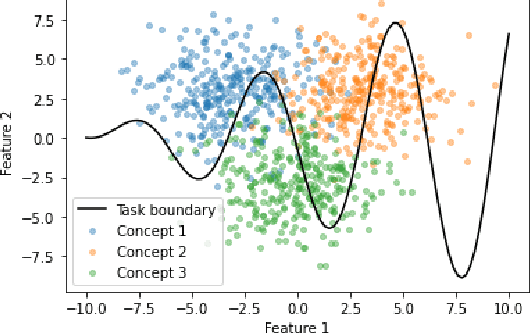

Machine learning models that incorporate concept learning as an intermediate step in their decision making process can match the performance of black-box predictive models while retaining the ability to explain outcomes in human understandable terms. However, we demonstrate that the concept representations learned by these models encode information beyond the pre-defined concepts, and that natural mitigation strategies do not fully work, rendering the interpretation of the downstream prediction misleading. We describe the mechanism underlying the information leakage and suggest recourse for mitigating its effects.
Learning MDPs from Features: Predict-Then-Optimize for Sequential Decision Problems by Reinforcement Learning
Jun 14, 2021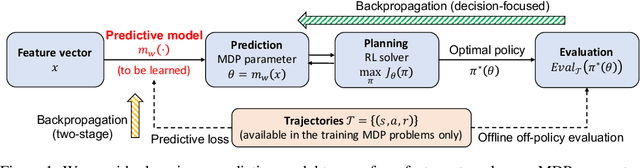
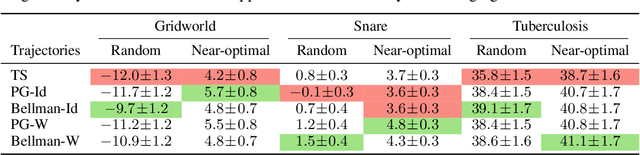
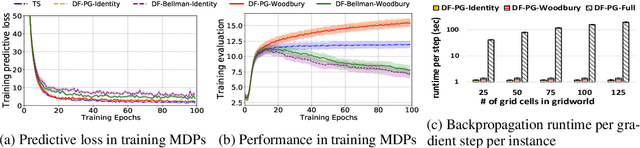
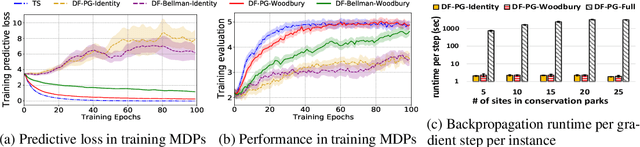
In the predict-then-optimize framework, the objective is to train a predictive model, mapping from environment features to parameters of an optimization problem, which maximizes decision quality when the optimization is subsequently solved. Recent work on decision-focused learning shows that embedding the optimization problem in the training pipeline can improve decision quality and help generalize better to unseen tasks compared to relying on an intermediate loss function for evaluating prediction quality. We study the predict-then-optimize framework in the context of sequential decision problems (formulated as MDPs) that are solved via reinforcement learning. In particular, we are given environment features and a set of trajectories from training MDPs, which we use to train a predictive model that generalizes to unseen test MDPs without trajectories. Two significant computational challenges arise in applying decision-focused learning to MDPs: (i) large state and action spaces make it infeasible for existing techniques to differentiate through MDP problems, and (ii) the high-dimensional policy space, as parameterized by a neural network, makes differentiating through a policy expensive. We resolve the first challenge by sampling provably unbiased derivatives to approximate and differentiate through optimality conditions, and the second challenge by using a low-rank approximation to the high-dimensional sample-based derivatives. We implement both Bellman--based and policy gradient--based decision-focused learning on three different MDP problems with missing parameters, and show that decision-focused learning performs better in generalization to unseen tasks.
Wide Mean-Field Variational Bayesian Neural Networks Ignore the Data
Jun 13, 2021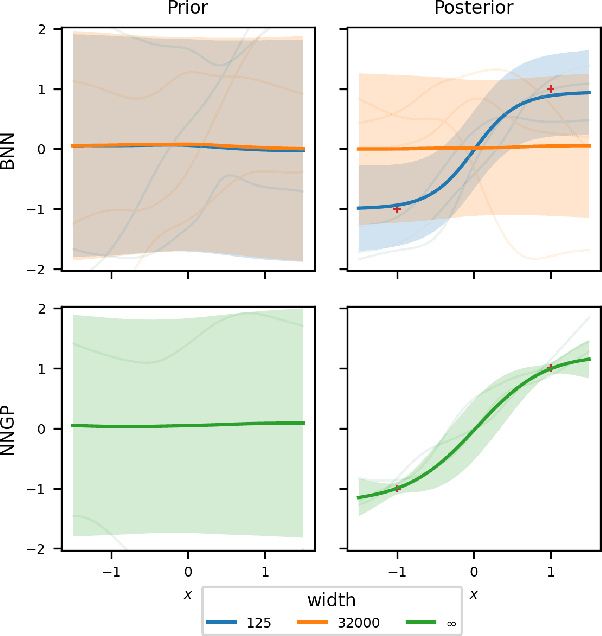
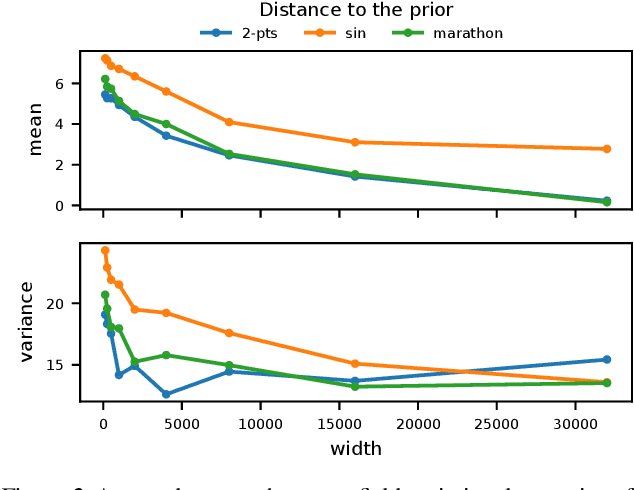
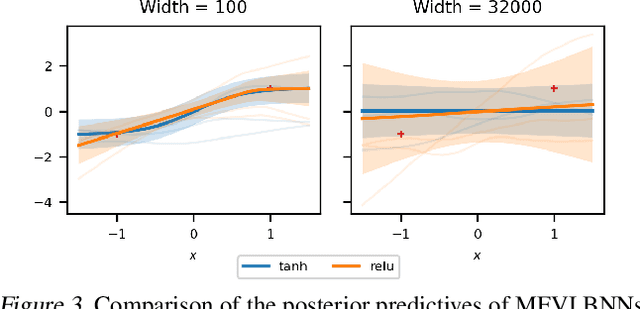
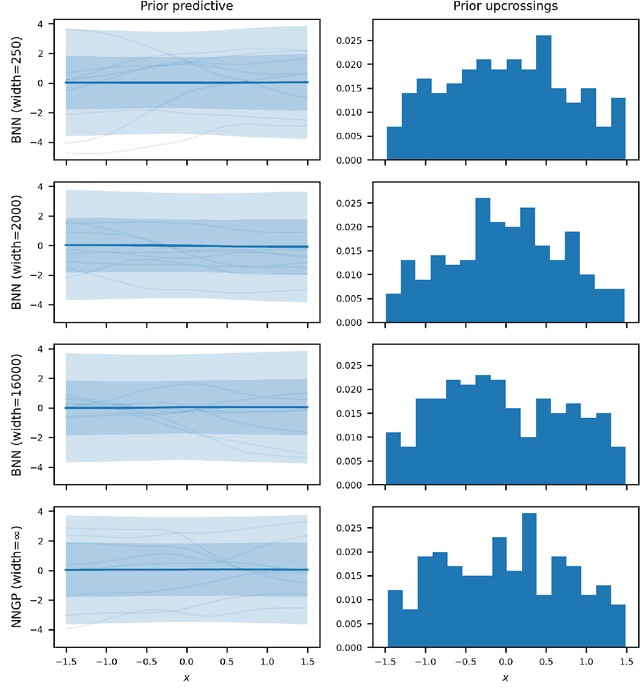
Variational inference enables approximate posterior inference of the highly over-parameterized neural networks that are popular in modern machine learning. Unfortunately, such posteriors are known to exhibit various pathological behaviors. We prove that as the number of hidden units in a single-layer Bayesian neural network tends to infinity, the function-space posterior mean under mean-field variational inference actually converges to zero, completely ignoring the data. This is in contrast to the true posterior, which converges to a Gaussian process. Our work provides insight into the over-regularization of the KL divergence in variational inference.
Learning Under Adversarial and Interventional Shifts
Mar 29, 2021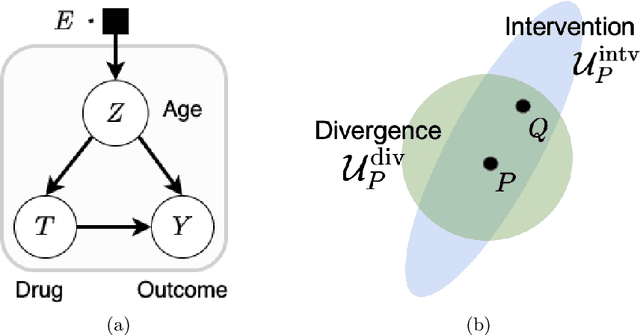
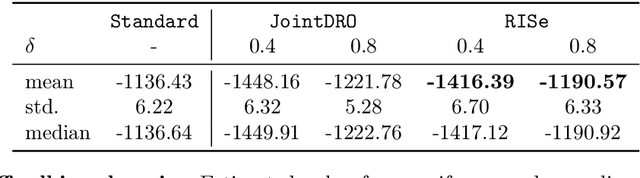
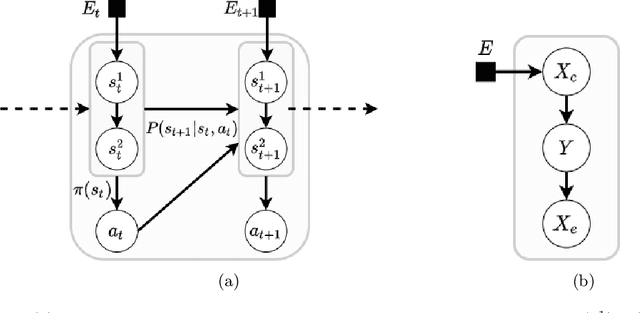
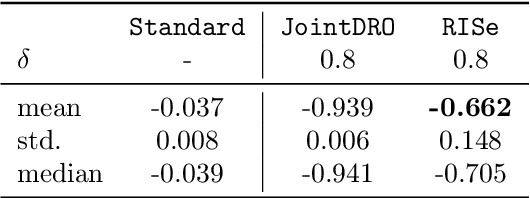
Machine learning models are often trained on data from one distribution and deployed on others. So it becomes important to design models that are robust to distribution shifts. Most of the existing work focuses on optimizing for either adversarial shifts or interventional shifts. Adversarial methods lack expressivity in representing plausible shifts as they consider shifts to joint distributions in the data. Interventional methods allow more expressivity but provide robustness to unbounded shifts, resulting in overly conservative models. In this work, we combine the complementary strengths of the two approaches and propose a new formulation, RISe, for designing robust models against a set of distribution shifts that are at the intersection of adversarial and interventional shifts. We employ the distributionally robust optimization framework to optimize the resulting objective in both supervised and reinforcement learning settings. Extensive experimentation with synthetic and real world datasets from healthcare demonstrate the efficacy of the proposed approach.
Benchmarks, Algorithms, and Metrics for Hierarchical Disentanglement
Feb 09, 2021

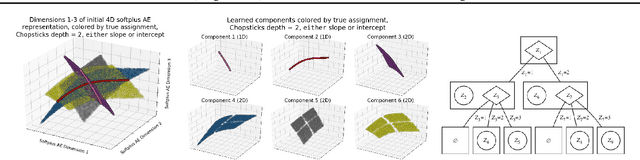
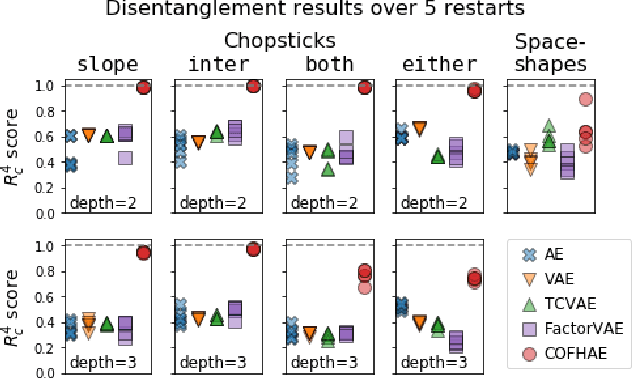
In representation learning, there has been recent interest in developing algorithms to disentangle the ground-truth generative factors behind data, and metrics to quantify how fully this occurs. However, these algorithms and metrics often assume that both representations and ground-truth factors are flat, continuous, and factorized, whereas many real-world generative processes involve rich hierarchical structure, mixtures of discrete and continuous variables with dependence between them, and even varying intrinsic dimensionality. In this work, we develop benchmarks, algorithms, and metrics for learning such hierarchical representations.