 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Bayesian Approach to Learning Bandit Structure in Markov Decision Processes
Jul 30, 2022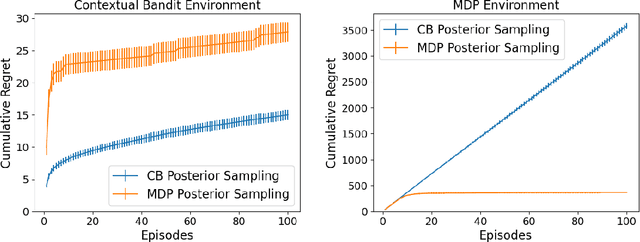
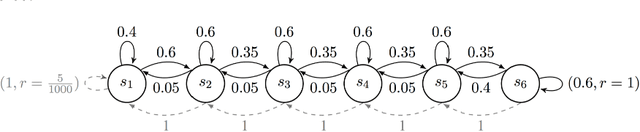
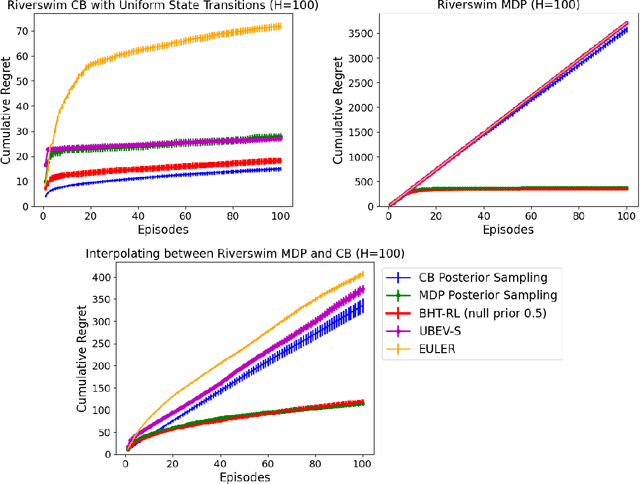
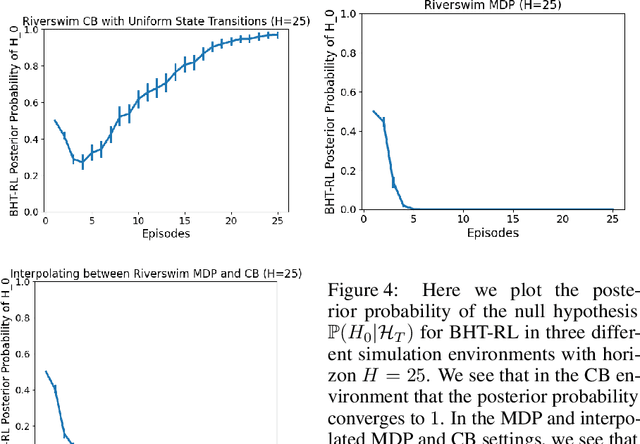
In the reinforcement learning literature, there are many algorithms developed for either Contextual Bandit (CB) or Markov Decision Processes (MDP) environments. However, when deploying reinforcement learning algorithms in the real world, even with domain expertise, it is often difficult to know whether it is appropriate to treat a sequential decision making problem as a CB or an MDP. In other words, do actions affect future states, or only the immediate rewards? Making the wrong assumption regarding the nature of the environment can lead to inefficient learning, or even prevent the algorithm from ever learning an optimal policy, even with infinite data. In this work we develop an online algorithm that uses a Bayesian hypothesis testing approach to learn the nature of the environment. Our algorithm allows practitioners to incorporate prior knowledge about whether the environment is that of a CB or an MDP, and effectively interpolate between classical CB and MDP-based algorithms to mitigate against the effects of misspecifying the environment. We perform simulations and demonstrate that in CB settings our algorithm achieves lower regret than MDP-based algorithms, while in non-bandit MDP settings our algorithm is able to learn the optimal policy, often achieving comparable regret to MDP-based algorithms.
Policy Optimization with Sparse Global Contrastive Explanations
Jul 13, 2022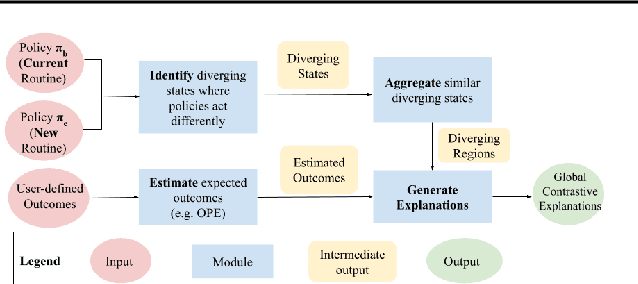

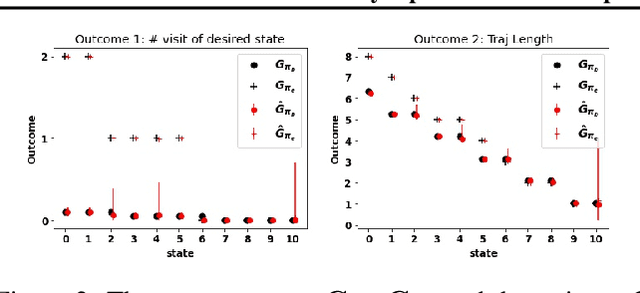

We develop a Reinforcement Learning (RL) framework for improving an existing behavior policy via sparse, user-interpretable changes. Our goal is to make minimal changes while gaining as much benefit as possible. We define a minimal change as having a sparse, global contrastive explanation between the original and proposed policy. We improve the current policy with the constraint of keeping that global contrastive explanation short. We demonstrate our framework with a discrete MDP and a continuous 2D navigation domain.
Connecting Algorithmic Research and Usage Contexts: A Perspective of Contextualized Evaluation for Explainable AI
Jun 22, 2022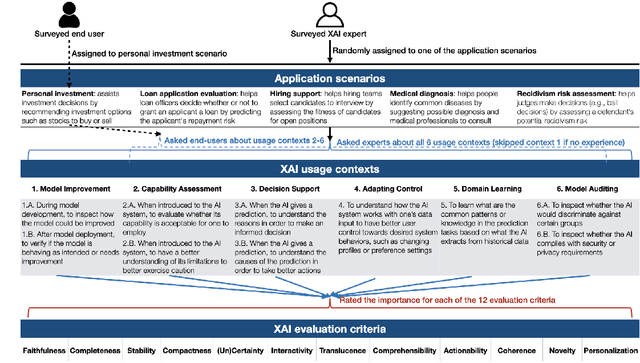
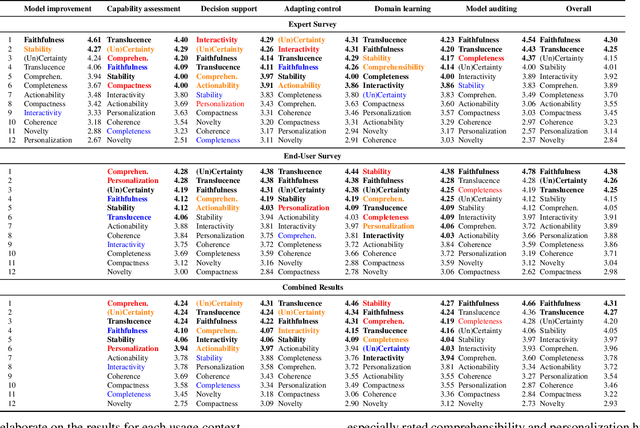

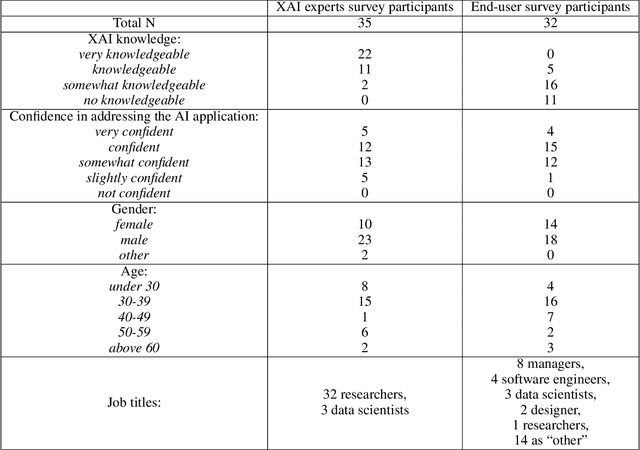
Recent years have seen a surge of interest in the field of explainable AI (XAI), with a plethora of algorithms proposed in the literature. However, a lack of consensus on how to evaluate XAI hinders the advancement of the field. We highlight that XAI is not a monolithic set of technologies -- researchers and practitioners have begun to leverage XAI algorithms to build XAI systems that serve different usage contexts, such as model debugging and decision-support. Algorithmic research of XAI, however, often does not account for these diverse downstream usage contexts, resulting in limited effectiveness or even unintended consequences for actual users, as well as difficulties for practitioners to make technical choices. We argue that one way to close the gap is to develop evaluation methods that account for different user requirements in these usage contexts. Towards this goal, we introduce a perspective of contextualized XAI evaluation by considering the relative importance of XAI evaluation criteria for prototypical usage contexts of XAI. To explore the context-dependency of XAI evaluation criteria, we conduct two survey studies, one with XAI topical experts and another with crowd workers. Our results urge for responsible AI research with usage-informed evaluation practices, and provide a nuanced understanding of user requirements for XAI in different usage contexts.
Designing Reinforcement Learning Algorithms for Digital Interventions: Pre-implementation Guidelines
Jun 08, 2022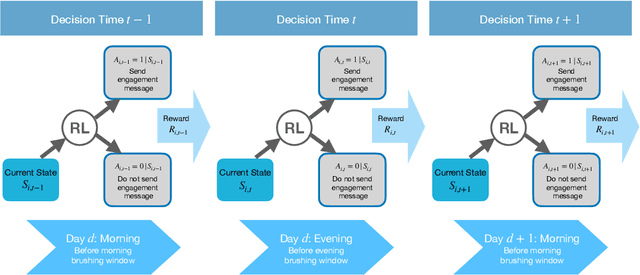

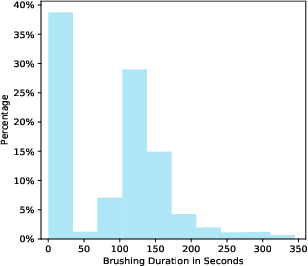
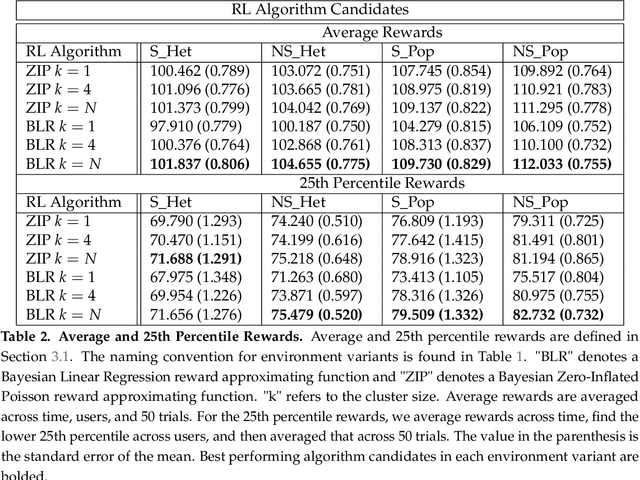
Online reinforcement learning (RL) algorithms are increasingly used to personalize digital interventions in the fields of mobile health and online education. Common challenges in designing and testing an RL algorithm in these settings include ensuring the RL algorithm can learn and run stably under real-time constraints, and accounting for the complexity of the environment, e.g., a lack of accurate mechanistic models for the user dynamics. To guide how one can tackle these challenges, we extend the PCS (Predictability, Computability, Stability) framework, a data science framework that incorporates best practices from machine learning and statistics in supervised learning (Yu and Kumbier, 2020), to the design of RL algorithms for the digital interventions setting. Further, we provide guidelines on how to design simulation environments, a crucial tool for evaluating RL candidate algorithms using the PCS framework. We illustrate the use of the PCS framework for designing an RL algorithm for Oralytics, a mobile health study aiming to improve users' tooth-brushing behaviors through the personalized delivery of intervention messages. Oralytics will go into the field in late 2022.
A Joint Learning Approach for Semi-supervised Neural Topic Modeling
Apr 07, 2022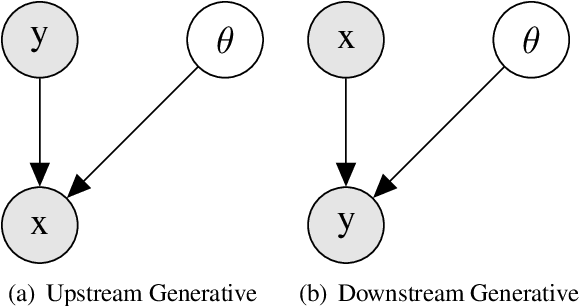

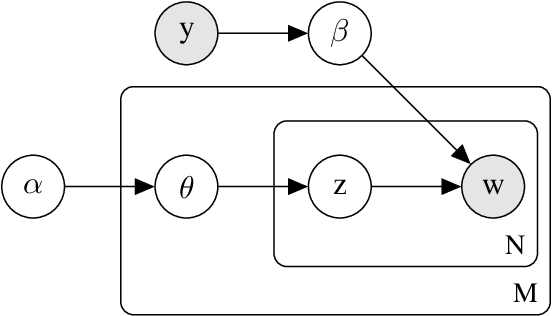

Topic models are some of the most popular ways to represent textual data in an interpret-able manner. Recently, advances in deep generative models, specifically auto-encoding variational Bayes (AEVB), have led to the introduction of unsupervised neural topic models, which leverage deep generative models as opposed to traditional statistics-based topic models. We extend upon these neural topic models by introducing the Label-Indexed Neural Topic Model (LI-NTM), which is, to the extent of our knowledge, the first effective upstream semi-supervised neural topic model. We find that LI-NTM outperforms existing neural topic models in document reconstruction benchmarks, with the most notable results in low labeled data regimes and for data-sets with informative labels; furthermore, our jointly learned classifier outperforms baseline classifiers in ablation studies.
Wide Mean-Field Bayesian Neural Networks Ignore the Data
Feb 23, 2022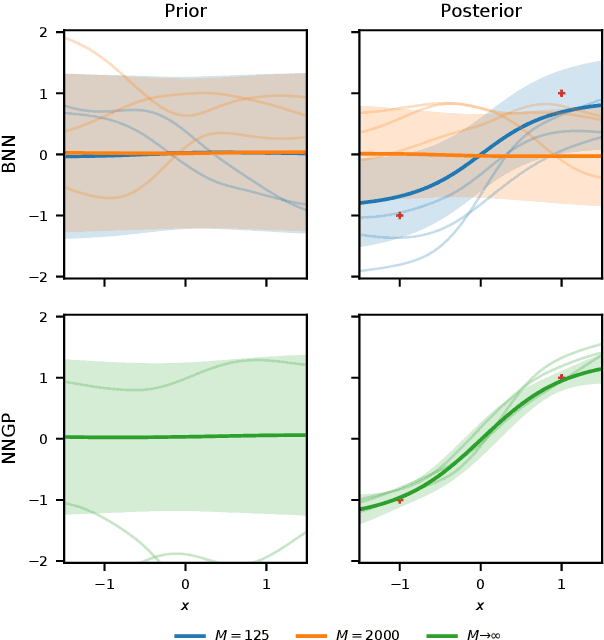
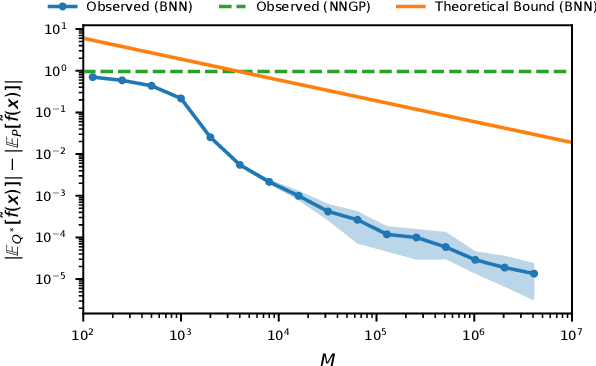
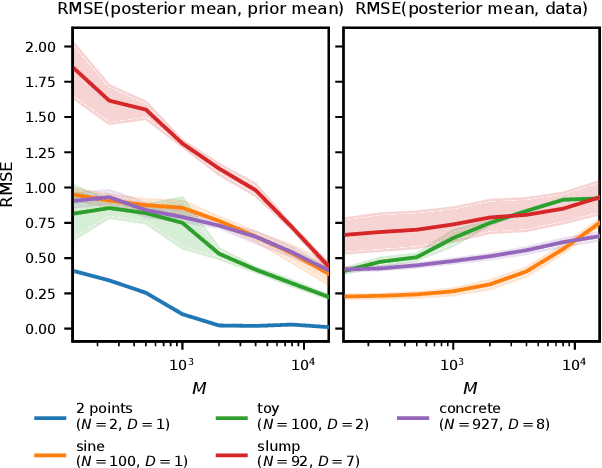
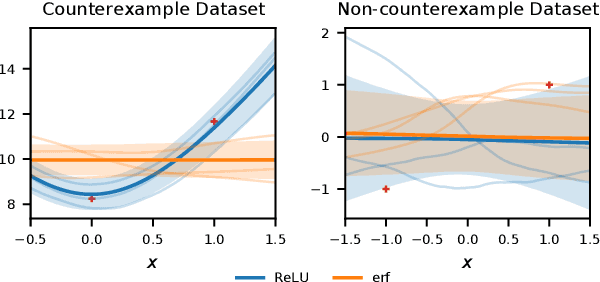
Bayesian neural networks (BNNs) combine the expressive power of deep learning with the advantages of Bayesian formalism. In recent years, the analysis of wide, deep BNNs has provided theoretical insight into their priors and posteriors. However, we have no analogous insight into their posteriors under approximate inference. In this work, we show that mean-field variational inference entirely fails to model the data when the network width is large and the activation function is odd. Specifically, for fully-connected BNNs with odd activation functions and a homoscedastic Gaussian likelihood, we show that the optimal mean-field variational posterior predictive (i.e., function space) distribution converges to the prior predictive distribution as the width tends to infinity. We generalize aspects of this result to other likelihoods. Our theoretical results are suggestive of underfitting behavior previously observered in BNNs. While our convergence bounds are non-asymptotic and constants in our analysis can be computed, they are currently too loose to be applicable in standard training regimes. Finally, we show that the optimal approximate posterior need not tend to the prior if the activation function is not odd, showing that our statements cannot be generalized arbitrarily.
Generalizing Off-Policy Evaluation From a Causal Perspective For Sequential Decision-Making
Jan 20, 2022Assessing the effects of a policy based on observational data from a different policy is a common problem across several high-stake decision-making domains, and several off-policy evaluation (OPE) techniques have been proposed. However, these methods largely formulate OPE as a problem disassociated from the process used to generate the data (i.e. structural assumptions in the form of a causal graph). We argue that explicitly highlighting this association has important implications on our understanding of the fundamental limits of OPE. First, this implies that current formulation of OPE corresponds to a narrow set of tasks, i.e. a specific causal estimand which is focused on prospective evaluation of policies over populations or sub-populations. Second, we demonstrate how this association motivates natural desiderata to consider a general set of causal estimands, particularly extending the role of OPE for counterfactual off-policy evaluation at the level of individuals of the population. A precise description of the causal estimand highlights which OPE estimands are identifiable from observational data under the stated generative assumptions. For those OPE estimands that are not identifiable, the causal perspective further highlights where more experimental data is necessary, and highlights situations where human expertise can aid identification and estimation. Furthermore, many formalisms of OPE overlook the role of uncertainty entirely in the estimation process.We demonstrate how specifically characterising the causal estimand highlights the different sources of uncertainty and when human expertise can naturally manage this uncertainty. We discuss each of these aspects as actionable desiderata for future OPE research at scale and in-line with practical utility.
Identification of Subgroups With Similar Benefits in Off-Policy Policy Evaluation
Nov 28, 2021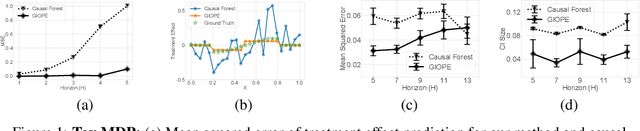
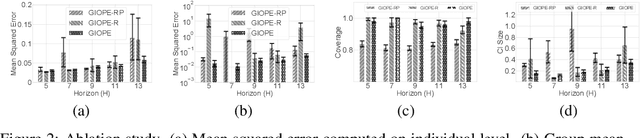
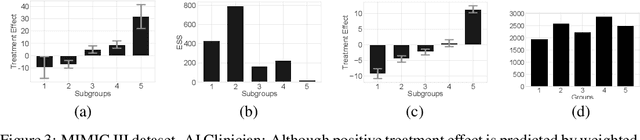
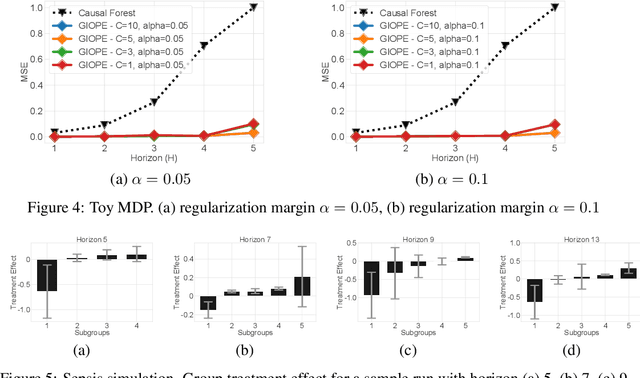
Off-policy policy evaluation methods for sequential decision making can be used to help identify if a proposed decision policy is better than a current baseline policy. However, a new decision policy may be better than a baseline policy for some individuals but not others. This has motivated a push towards personalization and accurate per-state estimates of heterogeneous treatment effects (HTEs). Given the limited data present in many important applications, individual predictions can come at a cost to accuracy and confidence in such predictions. We develop a method to balance the need for personalization with confident predictions by identifying subgroups where it is possible to confidently estimate the expected difference in a new decision policy relative to a baseline. We propose a novel loss function that accounts for uncertainty during the subgroup partitioning phase. In experiments, we show that our method can be used to form accurate predictions of HTEs where other methods struggle.
On Learning Prediction-Focused Mixtures
Oct 27, 2021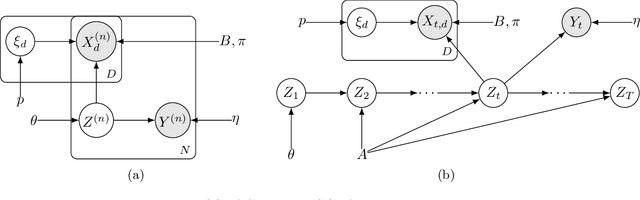
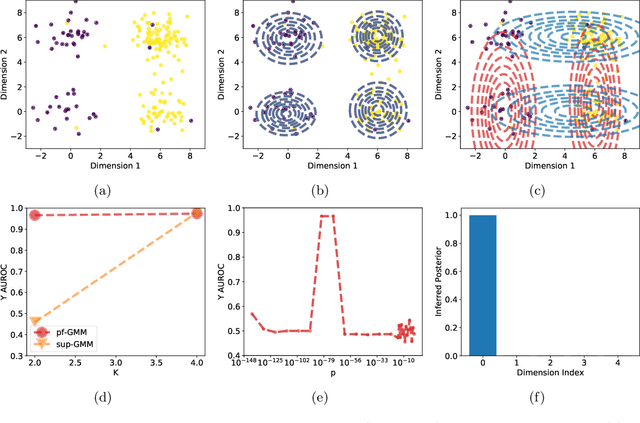
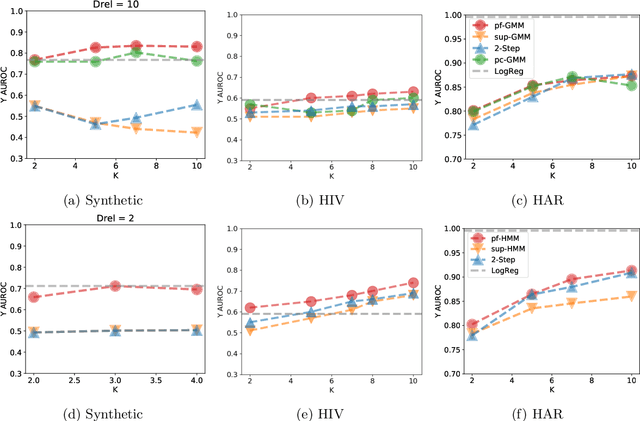
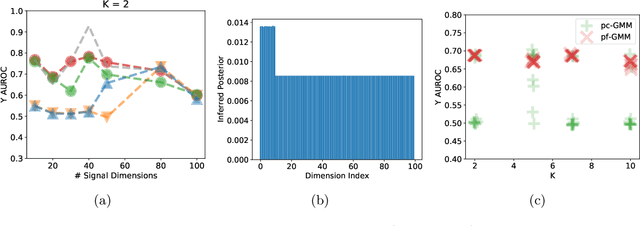
Probabilistic models help us encode latent structures that both model the data and are ideally also useful for specific downstream tasks. Among these, mixture models and their time-series counterparts, hidden Markov models, identify discrete components in the data. In this work, we focus on a constrained capacity setting, where we want to learn a model with relatively few components (e.g. for interpretability purposes). To maintain prediction performance, we introduce prediction-focused modeling for mixtures, which automatically selects the dimensions relevant to the prediction task. Our approach identifies relevant signal from the input, outperforms models that are not prediction-focused, and is easy to optimize; we also characterize when prediction-focused modeling can be expected to work.
Learning Predictive and Interpretable Timeseries Summaries from ICU Data
Sep 22, 2021
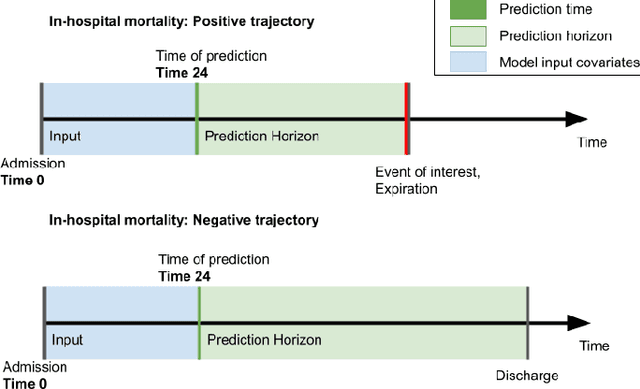
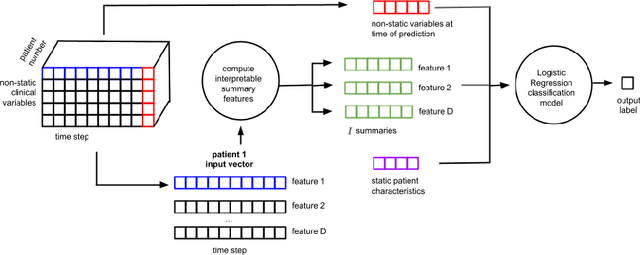
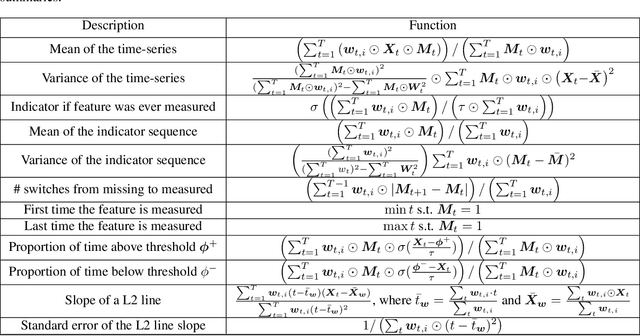
Machine learning models that utilize patient data across time (rather than just the most recent measurements) have increased performance for many risk stratification tasks in the intensive care unit. However, many of these models and their learned representations are complex and therefore difficult for clinicians to interpret, creating challenges for validation. Our work proposes a new procedure to learn summaries of clinical time-series that are both predictive and easily understood by humans. Specifically, our summaries consist of simple and intuitive functions of clinical data (e.g. falling mean arterial pressure). Our learned summaries outperform traditional interpretable model classes and achieve performance comparable to state-of-the-art deep learning models on an in-hospital mortality classification task.