 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Factored Action Spaces for Efficient Offline Reinforcement Learning in Healthcare
May 02, 2023Many reinforcement learning (RL) applications have combinatorial action spaces, where each action is a composition of sub-actions. A standard RL approach ignores this inherent factorization structure, resulting in a potential failure to make meaningful inferences about rarely observed sub-action combinations; this is particularly problematic for offline settings, where data may be limited. In this work, we propose a form of linear Q-function decomposition induced by factored action spaces. We study the theoretical properties of our approach, identifying scenarios where it is guaranteed to lead to zero bias when used to approximate the Q-function. Outside the regimes with theoretical guarantees, we show that our approach can still be useful because it leads to better sample efficiency without necessarily sacrificing policy optimality, allowing us to achieve a better bias-variance trade-off. Across several offline RL problems using simulators and real-world datasets motivated by healthcare, we demonstrate that incorporating factored action spaces into value-based RL can result in better-performing policies. Our approach can help an agent make more accurate inferences within underexplored regions of the state-action space when applying RL to observational datasets.
Robust Decision-Focused Learning for Reward Transfer
Apr 06, 2023



Decision-focused (DF) model-based reinforcement learning has recently been introduced as a powerful algorithm which can focus on learning the MDP dynamics which are most relevant for obtaining high rewards. While this approach increases the performance of agents by focusing the learning towards optimizing for the reward directly, it does so by learning less accurate dynamics (from a MLE standpoint), and may thus be brittle to changes in the reward function. In this work, we develop the robust decision-focused (RDF) algorithm which leverages the non-identifiability of DF solutions to learn models which maximize expected returns while simultaneously learning models which are robust to changes in the reward function. We demonstrate on a variety of toy example and healthcare simulators that RDF significantly increases the robustness of DF to changes in the reward function, without decreasing the overall return the agent obtains.
Modeling Mobile Health Users as Reinforcement Learning Agents
Dec 01, 2022



Mobile health (mHealth) technologies empower patients to adopt/maintain healthy behaviors in their daily lives, by providing interventions (e.g. push notifications) tailored to the user's needs. In these settings, without intervention, human decision making may be impaired (e.g. valuing near term pleasure over own long term goals). In this work, we formalize this relationship with a framework in which the user optimizes a (potentially impaired) Markov Decision Process (MDP) and the mHealth agent intervenes on the user's MDP parameters. We show that different types of impairments imply different types of optimal intervention. We also provide analytical and empirical explorations of these differences.
An Empirical Analysis of the Advantages of Finite- v.s. Infinite-Width Bayesian Neural Networks
Nov 28, 2022Comparing Bayesian neural networks (BNNs) with different widths is challenging because, as the width increases, multiple model properties change simultaneously, and, inference in the finite-width case is intractable. In this work, we empirically compare finite- and infinite-width BNNs, and provide quantitative and qualitative explanations for their performance difference. We find that when the model is mis-specified, increasing width can hurt BNN performance. In these cases, we provide evidence that finite-width BNNs generalize better partially due to the properties of their frequency spectrum that allows them to adapt under model mismatch.
(When) Are Contrastive Explanations of Reinforcement Learning Helpful?
Nov 14, 2022


Global explanations of a reinforcement learning (RL) agent's expected behavior can make it safer to deploy. However, such explanations are often difficult to understand because of the complicated nature of many RL policies. Effective human explanations are often contrastive, referencing a known contrast (policy) to reduce redundancy. At the same time, these explanations also require the additional effort of referencing that contrast when evaluating an explanation. We conduct a user study to understand whether and when contrastive explanations might be preferable to complete explanations that do not require referencing a contrast. We find that complete explanations are generally more effective when they are the same size or smaller than a contrastive explanation of the same policy, and no worse when they are larger. This suggests that contrastive explanations are not sufficient to solve the problem of effectively explaining reinforcement learning policies, and require additional careful study for use in this context.
Does the explanation satisfy your needs?: A unified view of properties of explanations
Nov 10, 2022Interpretability provides a means for humans to verify aspects of machine learning (ML) models and empower human+ML teaming in situations where the task cannot be fully automated. Different contexts require explanations with different properties. For example, the kind of explanation required to determine if an early cardiac arrest warning system is ready to be integrated into a care setting is very different from the type of explanation required for a loan applicant to help determine the actions they might need to take to make their application successful. Unfortunately, there is a lack of standardization when it comes to properties of explanations: different papers may use the same term to mean different quantities, and different terms to mean the same quantity. This lack of a standardized terminology and categorization of the properties of ML explanations prevents us from both rigorously comparing interpretable machine learning methods and identifying what properties are needed in what contexts. In this work, we survey properties defined in interpretable machine learning papers, synthesize them based on what they actually measure, and describe the trade-offs between different formulations of these properties. In doing so, we enable more informed selection of task-appropriate formulations of explanation properties as well as standardization for future work in interpretable machine learning.
Gathering Strength, Gathering Storms: The One Hundred Year Study on Artificial Intelligence (AI100) 2021 Study Panel Report
Oct 27, 2022In September 2021, the "One Hundred Year Study on Artificial Intelligence" project (AI100) issued the second report of its planned long-term periodic assessment of artificial intelligence (AI) and its impact on society. It was written by a panel of 17 study authors, each of whom is deeply rooted in AI research, chaired by Michael Littman of Brown University. The report, entitled "Gathering Strength, Gathering Storms," answers a set of 14 questions probing critical areas of AI development addressing the major risks and dangers of AI, its effects on society, its public perception and the future of the field. The report concludes that AI has made a major leap from the lab to people's lives in recent years, which increases the urgency to understand its potential negative effects. The questions were developed by the AI100 Standing Committee, chaired by Peter Stone of the University of Texas at Austin, consisting of a group of AI leaders with expertise in computer science, sociology, ethics, economics, and other disciplines.
Towards Robust Off-Policy Evaluation via Human Inputs
Sep 18, 2022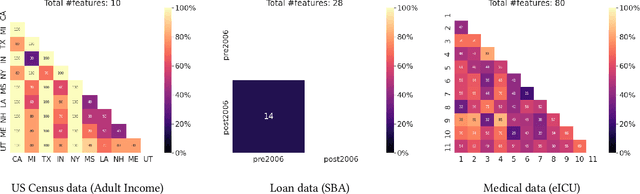

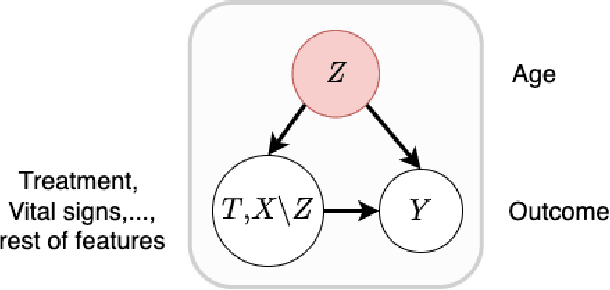
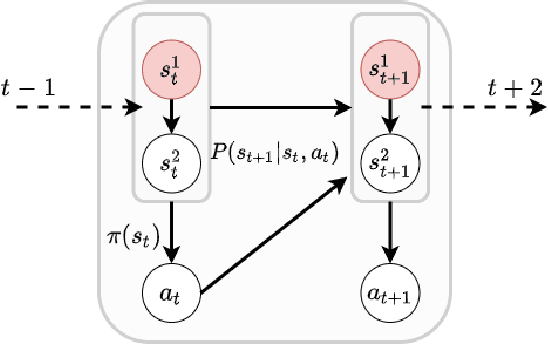
Off-policy Evaluation (OPE) methods are crucial tools for evaluating policies in high-stakes domains such as healthcare, where direct deployment is often infeasible, unethical, or expensive. When deployment environments are expected to undergo changes (that is, dataset shifts), it is important for OPE methods to perform robust evaluation of the policies amidst such changes. Existing approaches consider robustness against a large class of shifts that can arbitrarily change any observable property of the environment. This often results in highly pessimistic estimates of the utilities, thereby invalidating policies that might have been useful in deployment. In this work, we address the aforementioned problem by investigating how domain knowledge can help provide more realistic estimates of the utilities of policies. We leverage human inputs on which aspects of the environments may plausibly change, and adapt the OPE methods to only consider shifts on these aspects. Specifically, we propose a novel framework, Robust OPE (ROPE), which considers shifts on a subset of covariates in the data based on user inputs, and estimates worst-case utility under these shifts. We then develop computationally efficient algorithms for OPE that are robust to the aforementioned shifts for contextual bandits and Markov decision processes. We also theoretically analyze the sample complexity of these algorithms. Extensive experimentation with synthetic and real world datasets from the healthcare domain demonstrates that our approach not only captures realistic dataset shifts accurately, but also results in less pessimistic policy evaluations.
Reward Design For An Online Reinforcement Learning Algorithm Supporting Oral Self-Care
Aug 15, 2022
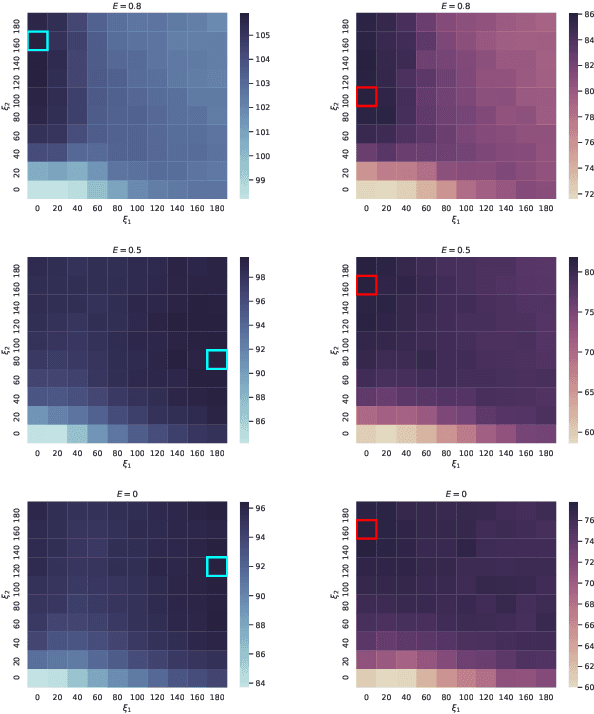

Dental disease is one of the most common chronic diseases despite being largely preventable. However, professional advice on optimal oral hygiene practices is often forgotten or abandoned by patients. Therefore patients may benefit from timely and personalized encouragement to engage in oral self-care behaviors. In this paper, we develop an online reinforcement learning (RL) algorithm for use in optimizing the delivery of mobile-based prompts to encourage oral hygiene behaviors. One of the main challenges in developing such an algorithm is ensuring that the algorithm considers the impact of the current action on the effectiveness of future actions (i.e., delayed effects), especially when the algorithm has been made simple in order to run stably and autonomously in a constrained, real-world setting (i.e., highly noisy, sparse data). We address this challenge by designing a quality reward which maximizes the desired health outcome (i.e., high-quality brushing) while minimizing user burden. We also highlight a procedure for optimizing the hyperparameters of the reward by building a simulation environment test bed and evaluating candidates using the test bed. The RL algorithm discussed in this paper will be deployed in Oralytics, an oral self-care app that provides behavioral strategies to boost patient engagement in oral hygiene practices.
Success of Uncertainty-Aware Deep Models Depends on Data Manifold Geometry
Aug 05, 2022
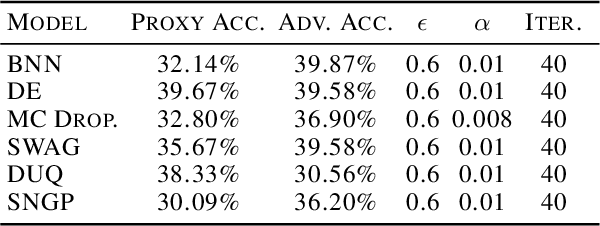
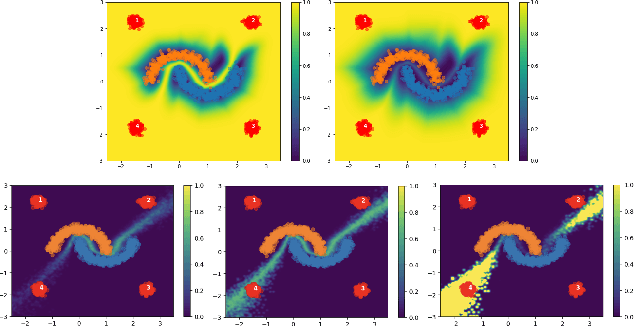
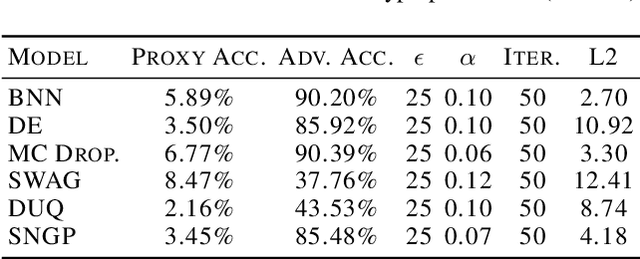
For responsible decision making in safety-critical settings, machine learning models must effectively detect and process edge-case data. Although existing works show that predictive uncertainty is useful for these tasks, it is not evident from literature which uncertainty-aware models are best suited for a given dataset. Thus, we compare six uncertainty-aware deep learning models on a set of edge-case tasks: robustness to adversarial attacks as well as out-of-distribution and adversarial detection. We find that the geometry of the data sub-manifold is an important factor in determining the success of various models. Our finding suggests an interesting direction in the study of uncertainty-aware deep learning models.