 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStriving for data-model efficiency: Identifying data externalities on group performance
Nov 11, 2022


Building trustworthy, effective, and responsible machine learning systems hinges on understanding how differences in training data and modeling decisions interact to impact predictive performance. In this work, we seek to better understand how we might characterize, detect, and design for data-model synergies. We focus on a particular type of data-model inefficiency, in which adding training data from some sources can actually lower performance evaluated on key sub-groups of the population, a phenomenon we refer to as negative data externalities on group performance. Such externalities can arise in standard learning settings and can manifest differently depending on conditions between training set size and model size. Data externalities directly imply a lower bound on feasible model improvements, yet improving models efficiently requires understanding the underlying data-model tensions. From a broader perspective, our results indicate that data-efficiency is a key component of both accurate and trustworthy machine learning.
Retrieval Augmentation for T5 Re-ranker using External Sources
Oct 11, 2022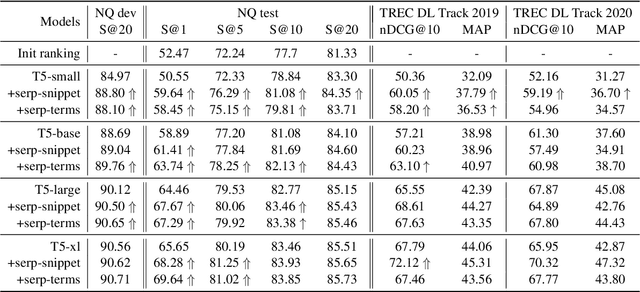
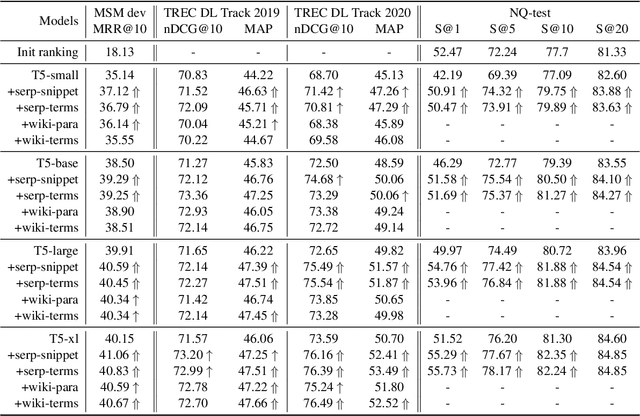
Retrieval augmentation has shown promising improvements in different tasks. However, whether such augmentation can assist a large language model based re-ranker remains unclear. We investigate how to augment T5-based re-rankers using high-quality information retrieved from two external corpora -- a commercial web search engine and Wikipedia. We empirically demonstrate how retrieval augmentation can substantially improve the effectiveness of T5-based re-rankers for both in-domain and zero-shot out-of-domain re-ranking tasks.
Analyzing the Effect of Sampling in GNNs on Individual Fairness
Sep 09, 2022
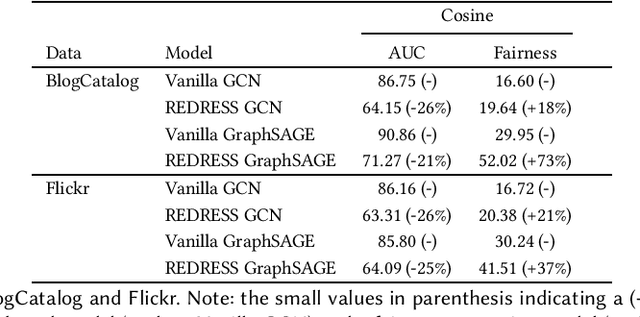
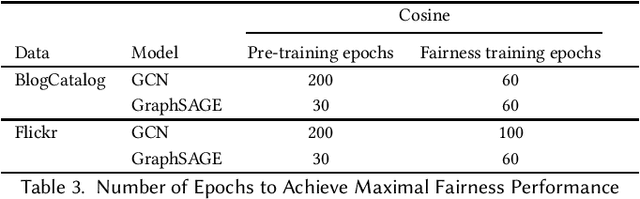
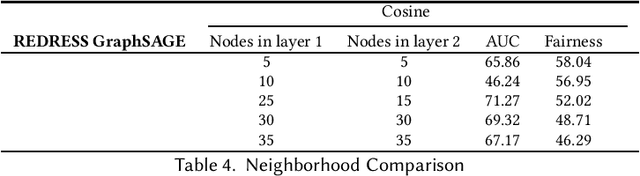
Graph neural network (GNN) based methods have saturated the field of recommender systems. The gains of these systems have been significant, showing the advantages of interpreting data through a network structure. However, despite the noticeable benefits of using graph structures in recommendation tasks, this representational form has also bred new challenges which exacerbate the complexity of mitigating algorithmic bias. When GNNs are integrated into downstream tasks, such as recommendation, bias mitigation can become even more difficult. Furthermore, the intractability of applying existing methods of fairness promotion to large, real world datasets places even more serious constraints on mitigation attempts. Our work sets out to fill in this gap by taking an existing method for promoting individual fairness on graphs and extending it to support mini-batch, or sub-sample based, training of a GNN, thus laying the groundwork for applying this method to a downstream recommendation task. We evaluate two popular GNN methods: Graph Convolutional Network (GCN), which trains on the entire graph, and GraphSAGE, which uses probabilistic random walks to create subgraphs for mini-batch training, and assess the effects of sub-sampling on individual fairness. We implement an individual fairness notion called \textit{REDRESS}, proposed by Dong et al., which uses rank optimization to learn individual fair node, or item, embeddings. We empirically show on two real world datasets that GraphSAGE is able to achieve, not just, comparable accuracy, but also, improved fairness as compared with the GCN model. These finding have consequential ramifications to individual fairness promotion, GNNs, and in downstream form, recommender systems, showing that mini-batch training facilitate individual fairness promotion by allowing for local nuance to guide the process of fairness promotion in representation learning.
Measuring Commonality in Recommendation of Cultural Content: Recommender Systems to Enhance Cultural Citizenship
Aug 02, 2022
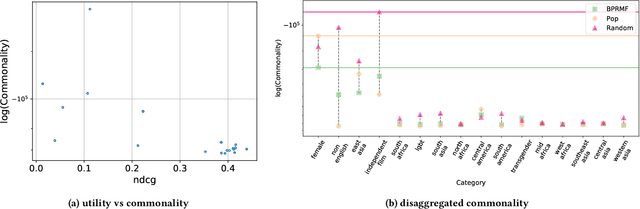
Recommender systems have become the dominant means of curating cultural content, significantly influencing the nature of individual cultural experience. While the majority of research on recommender systems optimizes for personalized user experience, this paradigm does not capture the ways that recommender systems impact cultural experience in the aggregate, across populations of users. Although existing novelty, diversity, and fairness studies probe how systems relate to the broader social role of cultural content, they do not adequately center culture as a core concept and challenge. In this work, we introduce commonality as a new measure that reflects the degree to which recommendations familiarize a given user population with specified categories of cultural content. Our proposed commonality metric responds to a set of arguments developed through an interdisciplinary dialogue between researchers in computer science and the social sciences and humanities. With reference to principles underpinning non-profit, public service media systems in democratic societies, we identify universality of address and content diversity in the service of strengthening cultural citizenship as particularly relevant goals for recommender systems delivering cultural content. Taking diversity in movie recommendation as a case study in enhancing pluralistic cultural experience, we empirically compare systems' performance using commonality and existing utility, diversity, and fairness metrics. Our results demonstrate that commonality captures a property of system behavior complementary to existing metrics and suggest the need for alternative, non-personalized interventions in recommender systems oriented to strengthening cultural citizenship across populations of users. In this way, commonality contributes to a growing body of scholarship developing 'public good' rationales for digital media and ML systems.
On Natural Language User Profiles for Transparent and Scrutable Recommendation
May 19, 2022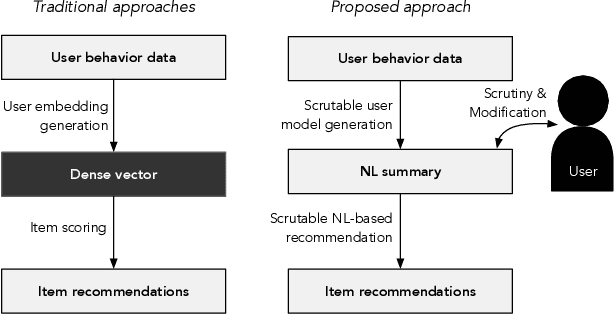



Natural interaction with recommendation and personalized search systems has received tremendous attention in recent years. We focus on the challenge of supporting people's understanding and control of these systems and explore a fundamentally new way of thinking about representation of knowledge in recommendation and personalization systems. Specifically, we argue that it may be both desirable and possible for algorithms that use natural language representations of users' preferences to be developed. We make the case that this could provide significantly greater transparency, as well as affordances for practical actionable interrogation of, and control over, recommendations. Moreover, we argue that such an approach, if successfully applied, may enable a major step towards systems that rely less on noisy implicit observations while increasing portability of knowledge of one's interests.
Retrieval-Enhanced Machine Learning
May 02, 2022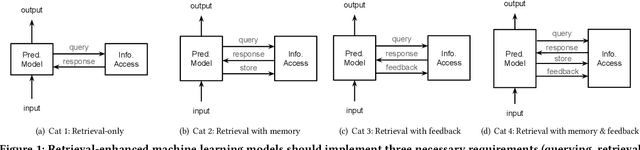
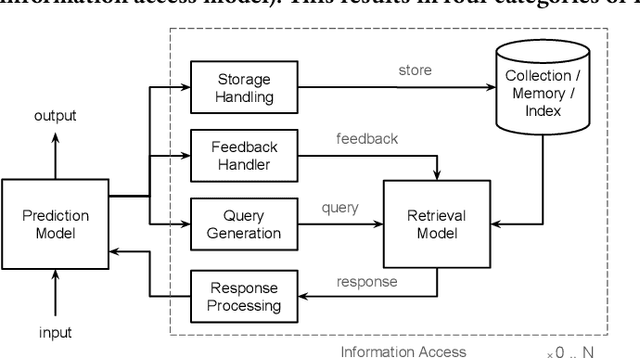
Although information access systems have long supported people in accomplishing a wide range of tasks, we propose broadening the scope of users of information access systems to include task-driven machines, such as machine learning models. In this way, the core principles of indexing, representation, retrieval, and ranking can be applied and extended to substantially improve model generalization, scalability, robustness, and interpretability. We describe a generic retrieval-enhanced machine learning (REML) framework, which includes a number of existing models as special cases. REML challenges information retrieval conventions, presenting opportunities for novel advances in core areas, including optimization. The REML research agenda lays a foundation for a new style of information access research and paves a path towards advancing machine learning and artificial intelligence.
Joint Multisided Exposure Fairness for Recommendation
Apr 29, 2022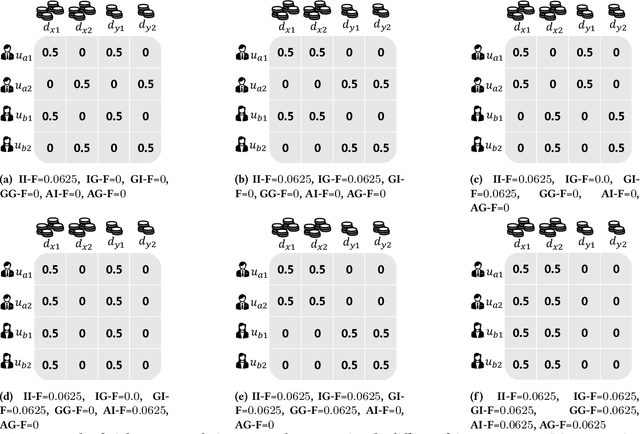
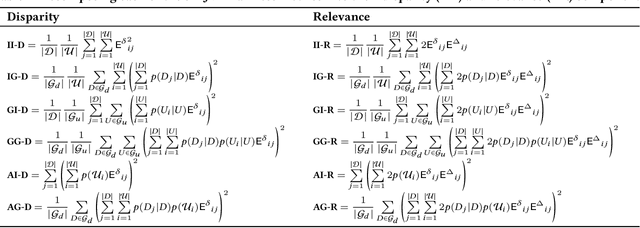
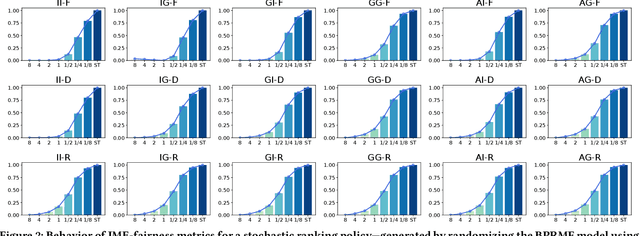
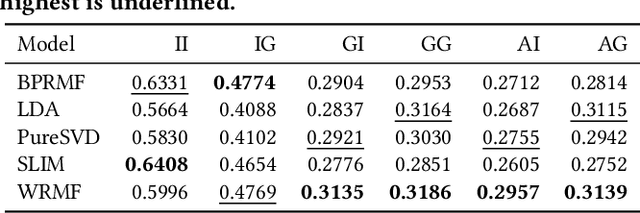
Prior research on exposure fairness in the context of recommender systems has focused mostly on disparities in the exposure of individual or groups of items to individual users of the system. The problem of how individual or groups of items may be systemically under or over exposed to groups of users, or even all users, has received relatively less attention. However, such systemic disparities in information exposure can result in observable social harms, such as withholding economic opportunities from historically marginalized groups (allocative harm) or amplifying gendered and racialized stereotypes (representational harm). Previously, Diaz et al. developed the expected exposure metric -- that incorporates existing user browsing models that have previously been developed for information retrieval -- to study fairness of content exposure to individual users. We extend their proposed framework to formalize a family of exposure fairness metrics that model the problem jointly from the perspective of both the consumers and producers. Specifically, we consider group attributes for both types of stakeholders to identify and mitigate fairness concerns that go beyond individual users and items towards more systemic biases in recommendation. Furthermore, we study and discuss the relationships between the different exposure fairness dimensions proposed in this paper, as well as demonstrate how stochastic ranking policies can be optimized towards said fairness goals.
Offline Retrieval Evaluation Without Evaluation Metrics
Apr 25, 2022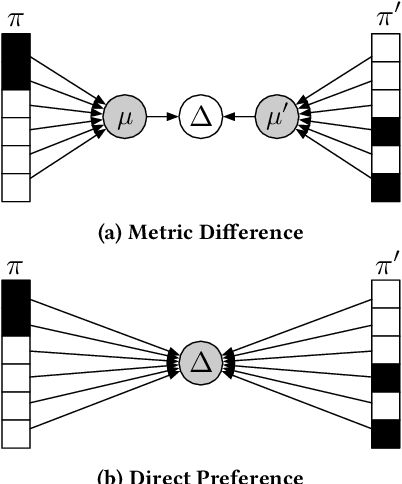
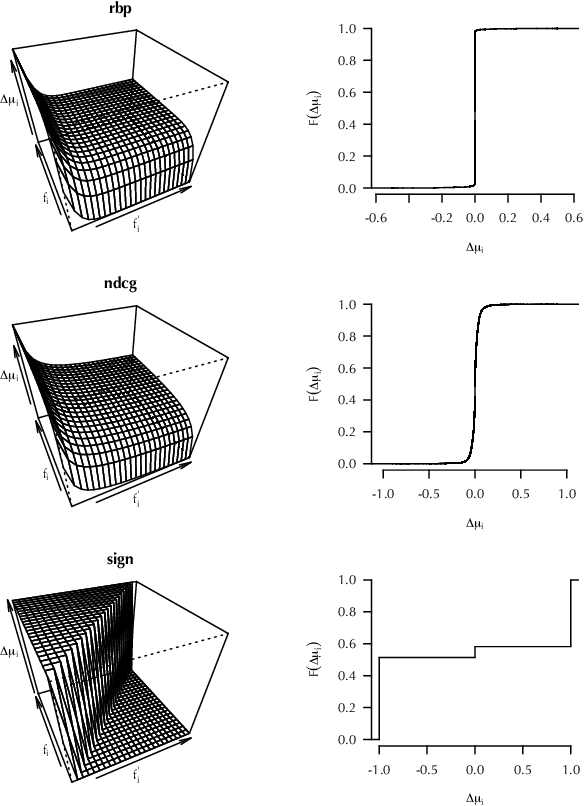
Offline evaluation of information retrieval and recommendation has traditionally focused on distilling the quality of a ranking into a scalar metric such as average precision or normalized discounted cumulative gain. We can use this metric to compare the performance of multiple systems for the same request. Although evaluation metrics provide a convenient summary of system performance, they also collapse subtle differences across users into a single number and can carry assumptions about user behavior and utility not supported across retrieval scenarios. We propose recall-paired preference (RPP), a metric-free evaluation method based on directly computing a preference between ranked lists. RPP simulates multiple user subpopulations per query and compares systems across these pseudo-populations. Our results across multiple search and recommendation tasks demonstrate that RPP substantially improves discriminative power while correlating well with existing metrics and being equally robust to incomplete data.
Exposing Query Identification for Search Transparency
Oct 14, 2021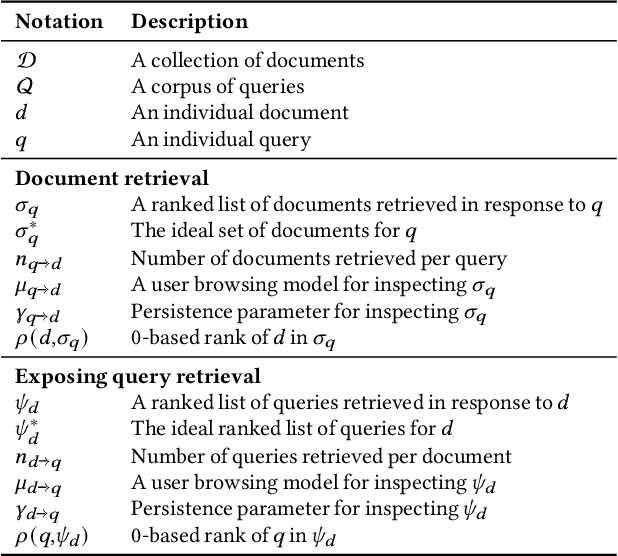

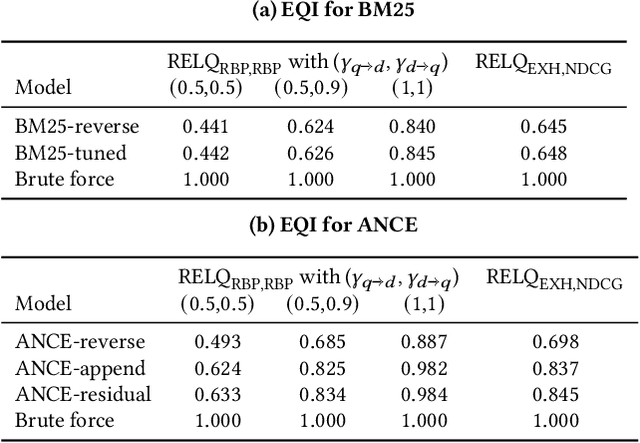
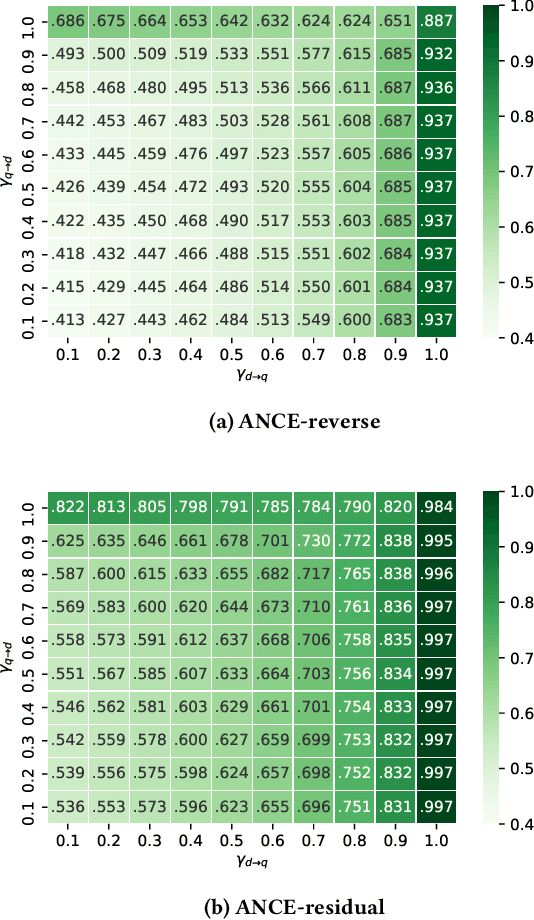
Search systems control the exposure of ranked content to searchers. In many cases, creators value not only the exposure of their content but, moreover, an understanding of the specific searches where the content is surfaced. The problem of identifying which queries expose a given piece of content in the ranking results is an important and relatively under-explored search transparency challenge. Exposing queries are useful for quantifying various issues of search bias, privacy, data protection, security, and search engine optimization. Exact identification of exposing queries in a given system is computationally expensive, especially in dynamic contexts such as web search. In quest of a more lightweight solution, we explore the feasibility of approximate exposing query identification (EQI) as a retrieval task by reversing the role of queries and documents in two classes of search systems: dense dual-encoder models and traditional BM25 models. We then propose how this approach can be improved through metric learning over the retrieval embedding space. We further derive an evaluation metric to measure the quality of a ranking of exposing queries, as well as conducting an empirical analysis focusing on various practical aspects of approximate EQI.
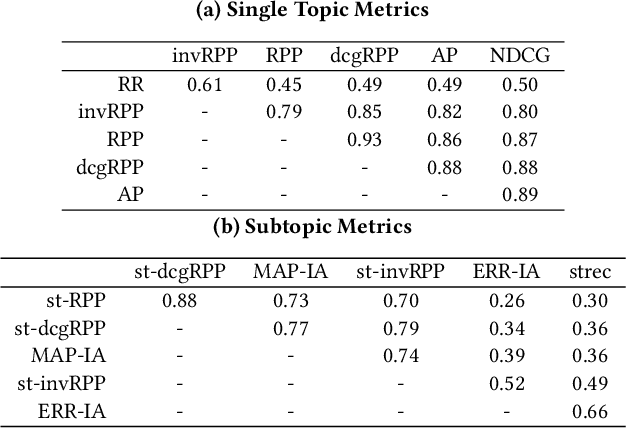
Estimation of Fair Ranking Metrics with Incomplete Judgments
Aug 11, 2021
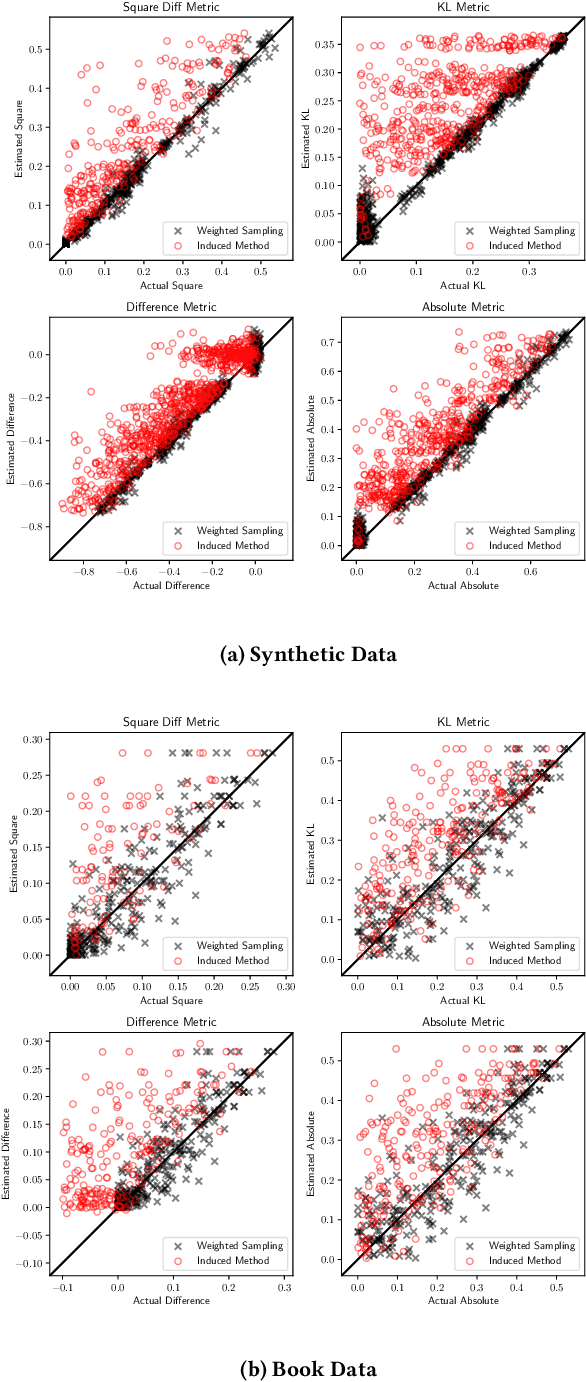
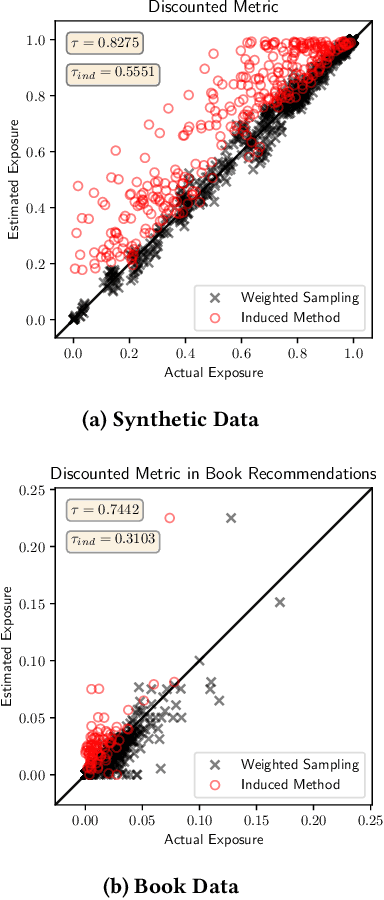

There is increasing attention to evaluating the fairness of search system ranking decisions. These metrics often consider the membership of items to particular groups, often identified using protected attributes such as gender or ethnicity. To date, these metrics typically assume the availability and completeness of protected attribute labels of items. However, the protected attributes of individuals are rarely present, limiting the application of fair ranking metrics in large scale systems. In order to address this problem, we propose a sampling strategy and estimation technique for four fair ranking metrics. We formulate a robust and unbiased estimator which can operate even with very limited number of labeled items. We evaluate our approach using both simulated and real world data. Our experimental results demonstrate that our method can estimate this family of fair ranking metrics and provides a robust, reliable alternative to exhaustive or random data annotation.