 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairExpand: Individual Fairness on Graphs with Partial Similarity Information
Dec 20, 2025



Individual fairness, which requires that similar individuals should be treated similarly by algorithmic systems, has become a central principle in fair machine learning. Individual fairness has garnered traction in graph representation learning due to its practical importance in high-stakes Web areas such as user modeling, recommender systems, and search. However, existing methods assume the existence of predefined similarity information over all node pairs, an often unrealistic requirement that prevents their operationalization in practice. In this paper, we assume the similarity information is only available for a limited subset of node pairs and introduce FairExpand, a flexible framework that promotes individual fairness in this more realistic partial information scenario. FairExpand follows a two-step pipeline that alternates between refining node representations using a backbone model (e.g., a graph neural network) and gradually propagating similarity information, which allows fairness enforcement to effectively expand to the entire graph. Extensive experiments show that FairExpand consistently enhances individual fairness while preserving performance, making it a practical solution for enabling graph-based individual fairness in real-world applications with partial similarity information.
LARP: Language Audio Relational Pre-training for Cold-Start Playlist Continuation
Jun 20, 2024As online music consumption increasingly shifts towards playlist-based listening, the task of playlist continuation, in which an algorithm suggests songs to extend a playlist in a personalized and musically cohesive manner, has become vital to the success of music streaming. Currently, many existing playlist continuation approaches rely on collaborative filtering methods to perform recommendation. However, such methods will struggle to recommend songs that lack interaction data, an issue known as the cold-start problem. Current approaches to this challenge design complex mechanisms for extracting relational signals from sparse collaborative data and integrating them into content representations. However, these approaches leave content representation learning out of scope and utilize frozen, pre-trained content models that may not be aligned with the distribution or format of a specific musical setting. Furthermore, even the musical state-of-the-art content modules are either (1) incompatible with the cold-start setting or (2) unable to effectively integrate cross-modal and relational signals. In this paper, we introduce LARP, a multi-modal cold-start playlist continuation model, to effectively overcome these limitations. LARP is a three-stage contrastive learning framework that integrates both multi-modal and relational signals into its learned representations. Our framework uses increasing stages of task-specific abstraction: within-track (language-audio) contrastive loss, track-track contrastive loss, and track-playlist contrastive loss. Experimental results on two publicly available datasets demonstrate the efficacy of LARP over uni-modal and multi-modal models for playlist continuation in a cold-start setting. Code and dataset are released at: https://github.com/Rsalganik1123/LARP.
Fairness Through Domain Awareness: Mitigating Popularity Bias For Music Discovery
Aug 28, 2023



As online music platforms grow, music recommender systems play a vital role in helping users navigate and discover content within their vast musical databases. At odds with this larger goal, is the presence of popularity bias, which causes algorithmic systems to favor mainstream content over, potentially more relevant, but niche items. In this work we explore the intrinsic relationship between music discovery and popularity bias. To mitigate this issue we propose a domain-aware, individual fairness-based approach which addresses popularity bias in graph neural network (GNNs) based recommender systems. Our approach uses individual fairness to reflect a ground truth listening experience, i.e., if two songs sound similar, this similarity should be reflected in their representations. In doing so, we facilitate meaningful music discovery that is robust to popularity bias and grounded in the music domain. We apply our BOOST methodology to two discovery based tasks, performing recommendations at both the playlist level and user level. Then, we ground our evaluation in the cold start setting, showing that our approach outperforms existing fairness benchmarks in both performance and recommendation of lesser-known content. Finally, our analysis explains why our proposed methodology is a novel and promising approach to mitigating popularity bias and improving the discovery of new and niche content in music recommender systems.
Analyzing the Effect of Sampling in GNNs on Individual Fairness
Sep 09, 2022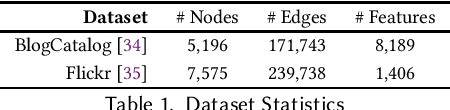
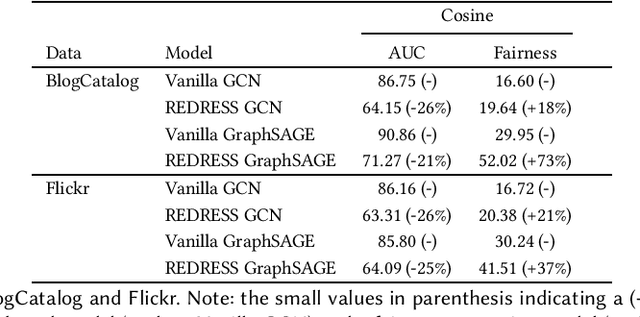
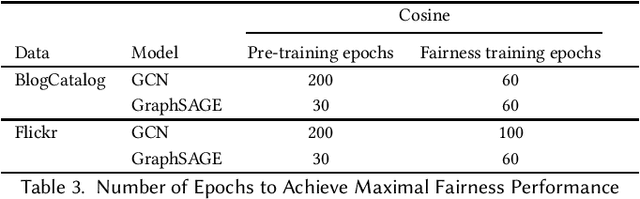
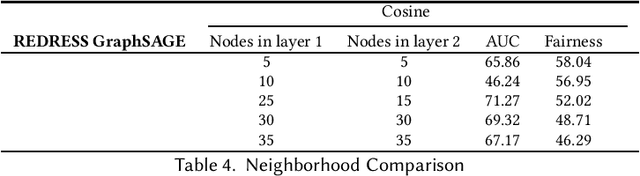
Graph neural network (GNN) based methods have saturated the field of recommender systems. The gains of these systems have been significant, showing the advantages of interpreting data through a network structure. However, despite the noticeable benefits of using graph structures in recommendation tasks, this representational form has also bred new challenges which exacerbate the complexity of mitigating algorithmic bias. When GNNs are integrated into downstream tasks, such as recommendation, bias mitigation can become even more difficult. Furthermore, the intractability of applying existing methods of fairness promotion to large, real world datasets places even more serious constraints on mitigation attempts. Our work sets out to fill in this gap by taking an existing method for promoting individual fairness on graphs and extending it to support mini-batch, or sub-sample based, training of a GNN, thus laying the groundwork for applying this method to a downstream recommendation task. We evaluate two popular GNN methods: Graph Convolutional Network (GCN), which trains on the entire graph, and GraphSAGE, which uses probabilistic random walks to create subgraphs for mini-batch training, and assess the effects of sub-sampling on individual fairness. We implement an individual fairness notion called \textit{REDRESS}, proposed by Dong et al., which uses rank optimization to learn individual fair node, or item, embeddings. We empirically show on two real world datasets that GraphSAGE is able to achieve, not just, comparable accuracy, but also, improved fairness as compared with the GCN model. These finding have consequential ramifications to individual fairness promotion, GNNs, and in downstream form, recommender systems, showing that mini-batch training facilitate individual fairness promotion by allowing for local nuance to guide the process of fairness promotion in representation learning.