 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFederated Neural Radiance Fields
May 02, 2023The ability of neural radiance fields or NeRFs to conduct accurate 3D modelling has motivated application of the technique to scene representation. Previous approaches have mainly followed a centralised learning paradigm, which assumes that all training images are available on one compute node for training. In this paper, we consider training NeRFs in a federated manner, whereby multiple compute nodes, each having acquired a distinct set of observations of the overall scene, learn a common NeRF in parallel. This supports the scenario of cooperatively modelling a scene using multiple agents. Our contribution is the first federated learning algorithm for NeRF, which splits the training effort across multiple compute nodes and obviates the need to pool the images at a central node. A technique based on low-rank decomposition of NeRF layers is introduced to reduce bandwidth consumption to transmit the model parameters for aggregation. Transferring compressed models instead of the raw data also contributes to the privacy of the data collecting agents.
Addressing the Challenges of Open-World Object Detection
Mar 27, 2023We address the challenging problem of open world object detection (OWOD), where object detectors must identify objects from known classes while also identifying and continually learning to detect novel objects. Prior work has resulted in detectors that have a relatively low ability to detect novel objects, and a high likelihood of classifying a novel object as one of the known classes. We approach the problem by identifying the three main challenges that OWOD presents and introduce OW-RCNN, an open world object detector that addresses each of these three challenges. OW-RCNN establishes a new state of the art using the open-world evaluation protocol on MS-COCO, showing a drastically increased ability to detect novel objects (16-21% absolute increase in U-Recall), to avoid their misclassification as one of the known classes (up to 52% reduction in A-OSE), and to incrementally learn to detect them while maintaining performance on previously known classes (1-6% absolute increase in mAP).
Predicting Class Distribution Shift for Reliable Domain Adaptive Object Detection
Feb 13, 2023



Unsupervised Domain Adaptive Object Detection (UDA-OD) uses unlabelled data to improve the reliability of robotic vision systems in open-world environments. Previous approaches to UDA-OD based on self-training have been effective in overcoming changes in the general appearance of images. However, shifts in a robot's deployment environment can also impact the likelihood that different objects will occur, termed class distribution shift. Motivated by this, we propose a framework for explicitly addressing class distribution shift to improve pseudo-label reliability in self-training. Our approach uses the domain invariance and contextual understanding of a pre-trained joint vision and language model to predict the class distribution of unlabelled data. By aligning the class distribution of pseudo-labels with this prediction, we provide weak supervision of pseudo-label accuracy. To further account for low quality pseudo-labels early in self-training, we propose an approach to dynamically adjust the number of pseudo-labels per image based on model confidence. Our method outperforms state-of-the-art approaches on several benchmarks, including a 4.7 mAP improvement when facing challenging class distribution shift.
ParticleNeRF: A Particle-Based Encoding for Online Neural Radiance Fields in Dynamic Scenes
Nov 11, 2022Neural Radiance Fields (NeRFs) learn implicit representations of - typically static - environments from images. Our paper extends NeRFs to handle dynamic scenes in an online fashion. We propose ParticleNeRF that adapts to changes in the geometry of the environment as they occur, learning a new up-to-date representation every 350 ms. ParticleNeRF can represent the current state of dynamic environments with much higher fidelity as other NeRF frameworks. To achieve this, we introduce a new particle-based parametric encoding, which allows the intermediate NeRF features - now coupled to particles in space - to move with the dynamic geometry. This is possible by backpropagating the photometric reconstruction loss into the position of the particles. The position gradients are interpreted as particle velocities and integrated into positions using a position-based dynamics (PBS) physics system. Introducing PBS into the NeRF formulation allows us to add collision constraints to the particle motion and creates future opportunities to add other movement priors into the system, such as rigid and deformable body
Noisy Inliers Make Great Outliers: Out-of-Distribution Object Detection with Noisy Synthetic Outliers
Aug 29, 2022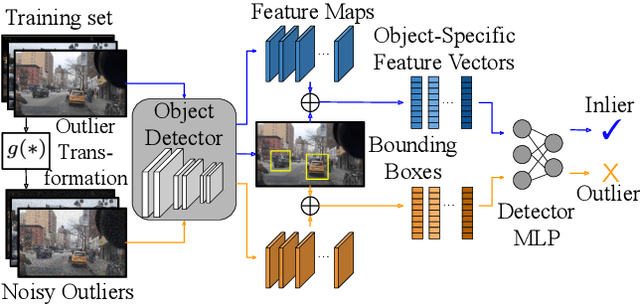
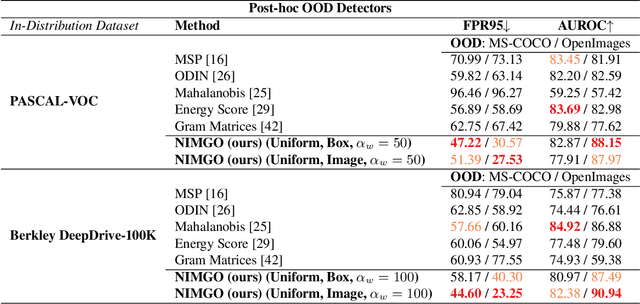

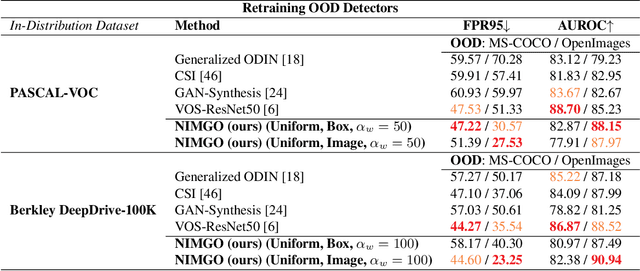
Many high-performing works on out-of-distribution (OOD) detection use real or synthetically generated outlier data to regularise model confidence; however, they often require retraining of the base network or specialised model architectures. Our work demonstrates that Noisy Inliers Make Great Outliers (NIMGO) in the challenging field of OOD object detection. We hypothesise that synthetic outliers need only be minimally perturbed variants of the in-distribution (ID) data in order to train a discriminator to identify OOD samples -- without expensive retraining of the base network. To test our hypothesis, we generate a synthetic outlier set by applying an additive-noise perturbation to ID samples at the image or bounding-box level. An auxiliary feature monitoring multilayer perceptron (MLP) is then trained to detect OOD feature representations using the perturbed ID samples as a proxy. During testing, we demonstrate that the auxiliary MLP distinguishes ID samples from OOD samples at a state-of-the-art level, reducing the false positive rate by more than 20\% (absolute) over the previous state-of-the-art on the OpenImages dataset. Extensive additional ablations provide empirical evidence in support of our hypothesis.
Implicit Object Mapping With Noisy Data
Apr 22, 2022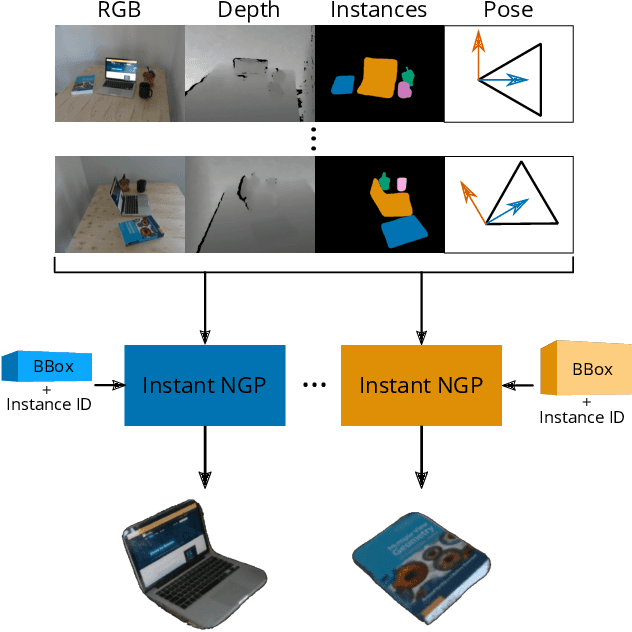
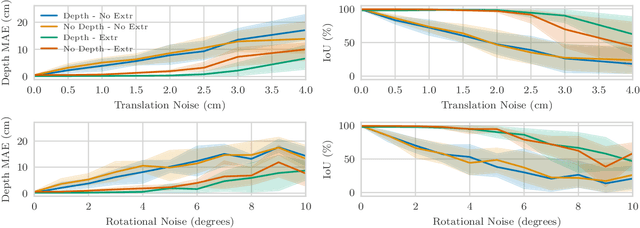


Modelling individual objects as Neural Radiance Fields (NeRFs) within a robotic context can benefit many downstream tasks such as scene understanding and object manipulation. However, real-world training data collected by a robot deviate from the ideal in several key aspects. (i) The trajectories are constrained and full visual coverage is not guaranteed - especially when obstructions are present. (ii) The poses associated with the images are noisy. (iii) The objects are not easily isolated from the background. This paper addresses the above three points and uses the outputs of an object-based SLAM system to bound objects in the scene with coarse primitives and - in concert with instance masks - identify obstructions in the training images. Objects are therefore automatically bounded, and non-relevant geometry is excluded from the NeRF representation. The method's performance is benchmarked under ideal conditions and tested against errors in the poses and instance masks. Our results show that object-based NeRFs are robust to pose variations but sensitive to the quality of the instance masks.
Hyperdimensional Feature Fusion for Out-Of-Distribution Detection
Dec 10, 2021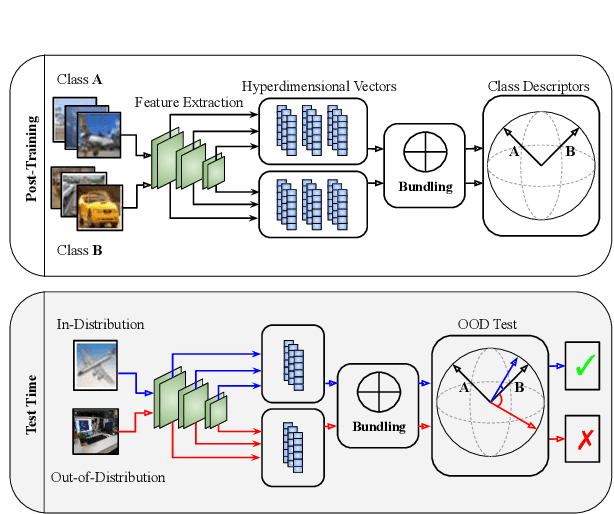
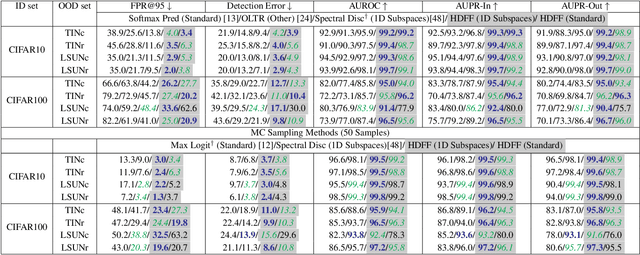
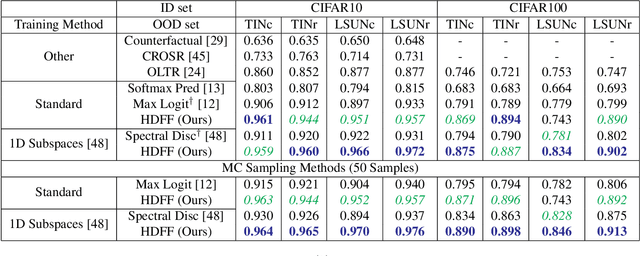
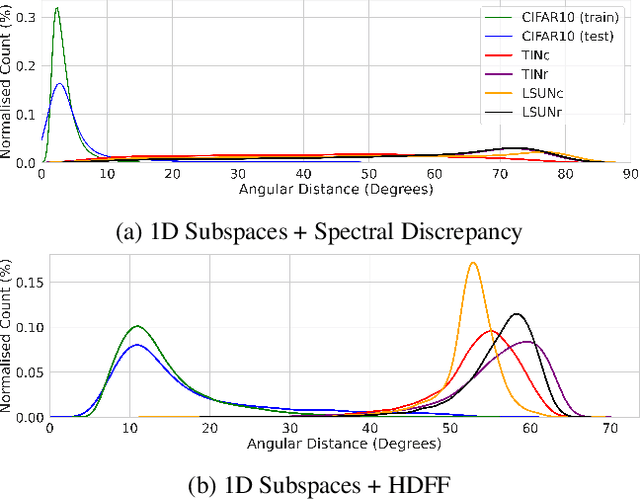
We introduce powerful ideas from Hyperdimensional Computing into the challenging field of Out-of-Distribution (OOD) detection. In contrast to most existing work that performs OOD detection based on only a single layer of a neural network, we use similarity-preserving semi-orthogonal projection matrices to project the feature maps from multiple layers into a common vector space. By repeatedly applying the bundling operation $\oplus$, we create expressive class-specific descriptor vectors for all in-distribution classes. At test time, a simple and efficient cosine similarity calculation between descriptor vectors consistently identifies OOD samples with better performance than the current state-of-the-art. We show that the hyperdimensional fusion of multiple network layers is critical to achieve best general performance.
Evaluating the Impact of Semantic Segmentation and Pose Estimation on Dense Semantic SLAM
Sep 16, 2021

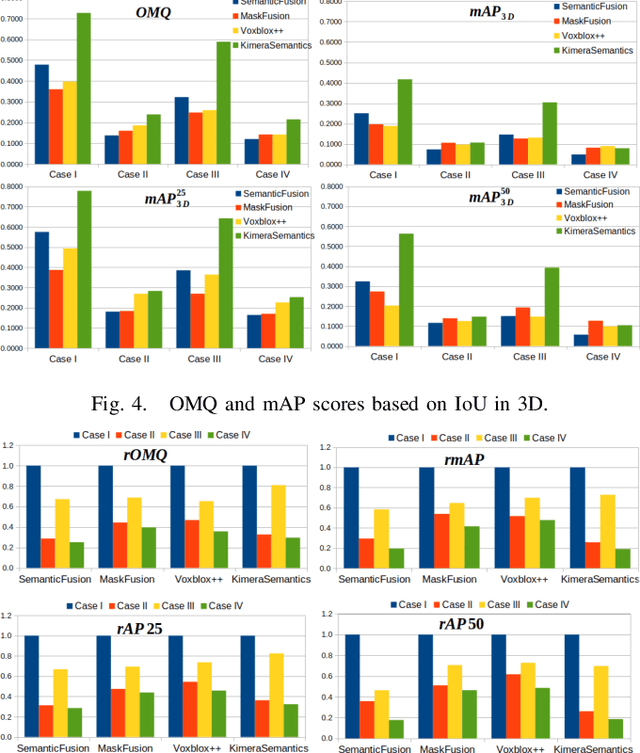
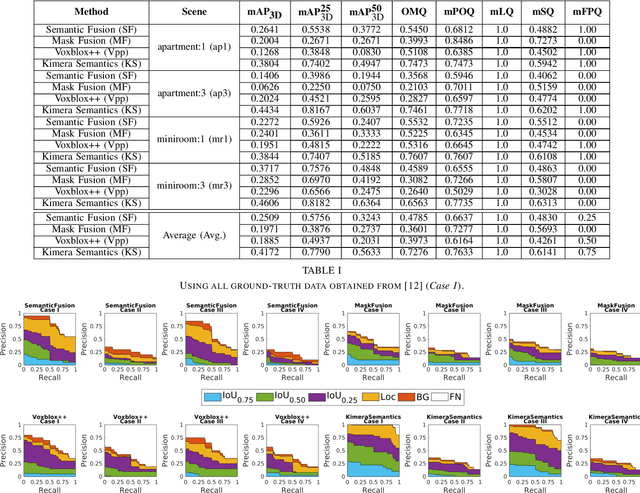
Recent Semantic SLAM methods combine classical geometry-based estimation with deep learning-based object detection or semantic segmentation. In this paper we evaluate the quality of semantic maps generated by state-of-the-art class- and instance-aware dense semantic SLAM algorithms whose codes are publicly available and explore the impacts both semantic segmentation and pose estimation have on the quality of semantic maps. We obtain these results by providing algorithms with ground-truth pose and/or semantic segmentation data available from simulated environments. We establish that semantic segmentation is the largest source of error through our experiments, dropping mAP and OMQ performance by up to 74.3% and 71.3% respectively.
FSNet: A Failure Detection Framework for Semantic Segmentation
Aug 19, 2021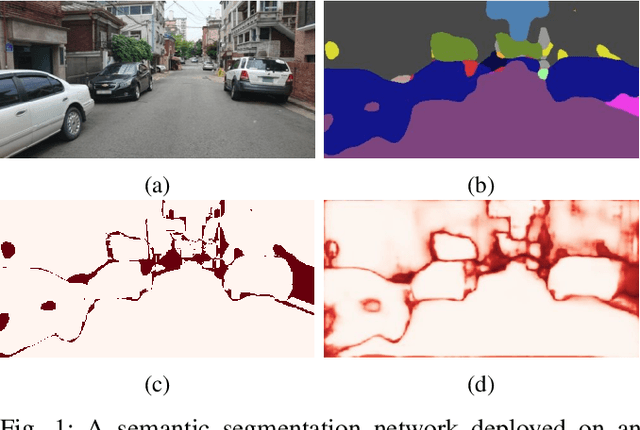
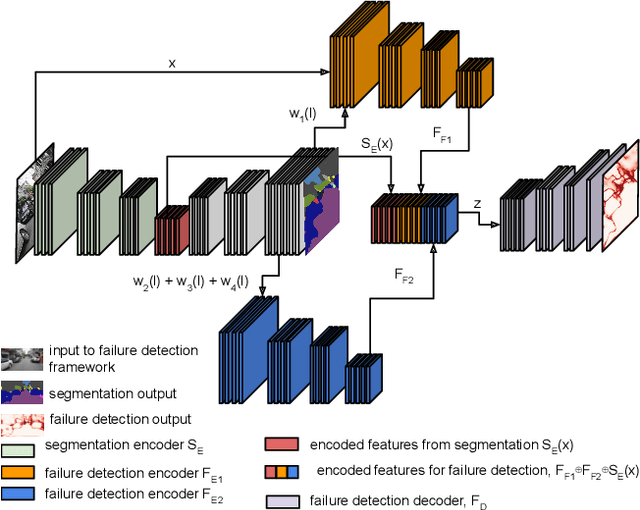


Semantic segmentation is an important task that helps autonomous vehicles understand their surroundings and navigate safely. During deployment, even the most mature segmentation models are vulnerable to various external factors that can degrade the segmentation performance with potentially catastrophic consequences for the vehicle and its surroundings. To address this issue, we propose a failure detection framework to identify pixel-level misclassification. We do so by exploiting internal features of the segmentation model and training it simultaneously with a failure detection network. During deployment, the failure detector can flag areas in the image where the segmentation model have failed to segment correctly. We evaluate the proposed approach against state-of-the-art methods and achieve 12.30%, 9.46%, and 9.65% performance improvement in the AUPR-Error metric for Cityscapes, BDD100K, and Mapillary semantic segmentation datasets.
Going Deeper into Semi-supervised Person Re-identification
Jul 24, 2021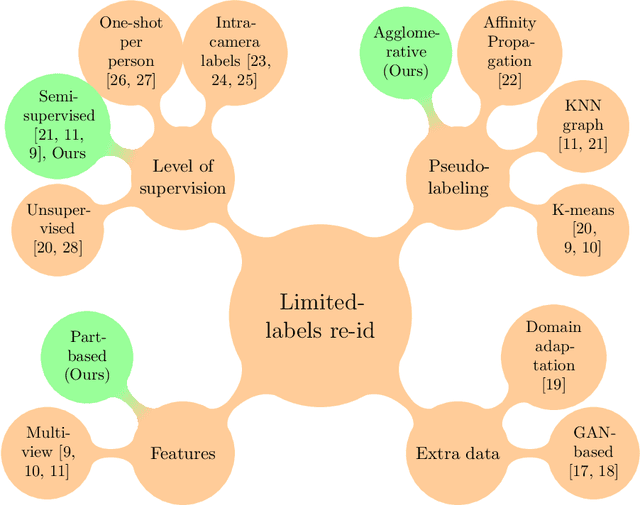
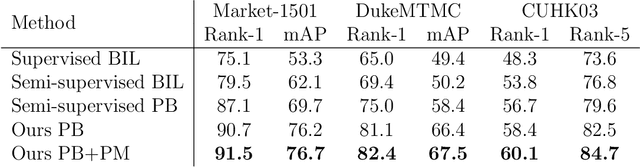
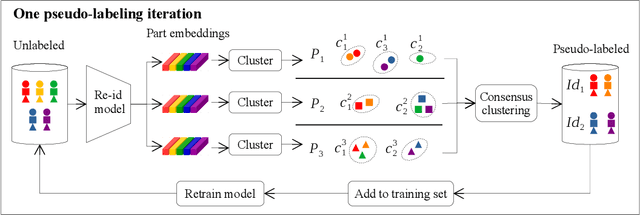

Person re-identification is the challenging task of identifying a person across different camera views. Training a convolutional neural network (CNN) for this task requires annotating a large dataset, and hence, it involves the time-consuming manual matching of people across cameras. To reduce the need for labeled data, we focus on a semi-supervised approach that requires only a subset of the training data to be labeled. We conduct a comprehensive survey in the area of person re-identification with limited labels. Existing works in this realm are limited in the sense that they utilize features from multiple CNNs and require the number of identities in the unlabeled data to be known. To overcome these limitations, we propose to employ part-based features from a single CNN without requiring the knowledge of the label space (i.e., the number of identities). This makes our approach more suitable for practical scenarios, and it significantly reduces the need for computational resources. We also propose a PartMixUp loss that improves the discriminative ability of learned part-based features for pseudo-labeling in semi-supervised settings. Our method outperforms the state-of-the-art results on three large-scale person re-id datasets and achieves the same level of performance as fully supervised methods with only one-third of labeled identities.