 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConformer with dual-mode chunked attention for joint online and offline ASR
Jun 22, 2022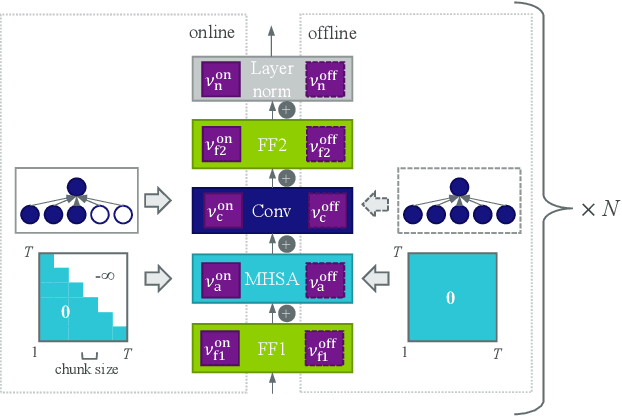
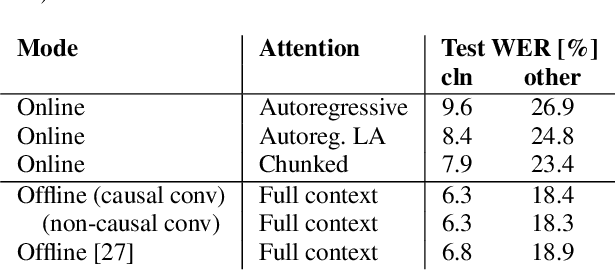
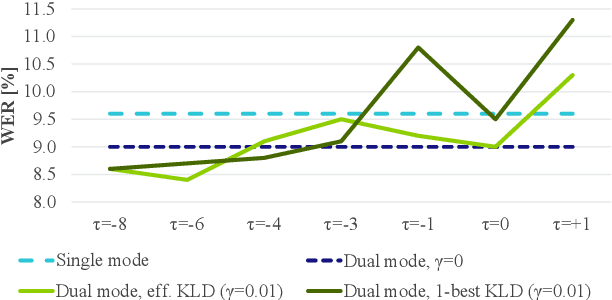
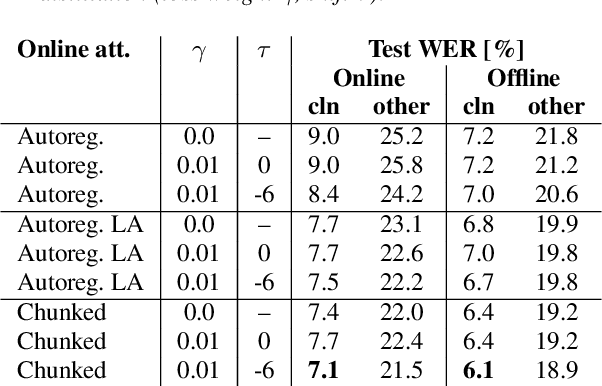
In this paper, we present an in-depth study on online attention mechanisms and distillation techniques for dual-mode (i.e., joint online and offline) ASR using the Conformer Transducer. In the dual-mode Conformer Transducer model, layers can function in online or offline mode while sharing parameters, and in-place knowledge distillation from offline to online mode is applied in training to improve online accuracy. In our study, we first demonstrate accuracy improvements from using chunked attention in the Conformer encoder compared to autoregressive attention with and without lookahead. Furthermore, we explore the efficient KLD and 1-best KLD losses with different shifts between online and offline outputs in the knowledge distillation. Finally, we show that a simplified dual-mode Conformer that only has mode-specific self-attention performs equally well as the one also having mode-specific convolutions and normalization. Our experiments are based on two very different datasets: the Librispeech task and an internal corpus of medical conversations. Results show that the proposed dual-mode system using chunked attention yields 5% and 4% relative WER improvement on the Librispeech and medical tasks, compared to the dual-mode system using autoregressive attention with similar average lookahead.
ChannelAugment: Improving generalization of multi-channel ASR by training with input channel randomization
Sep 23, 2021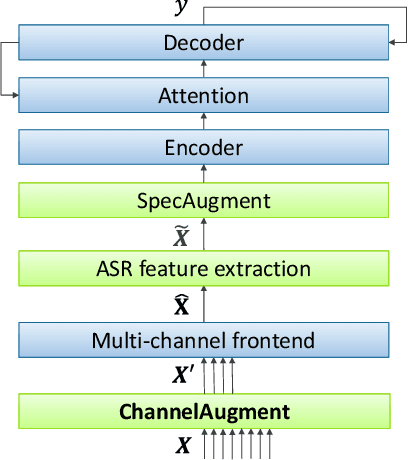
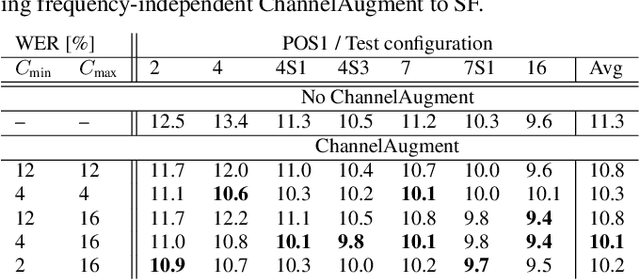
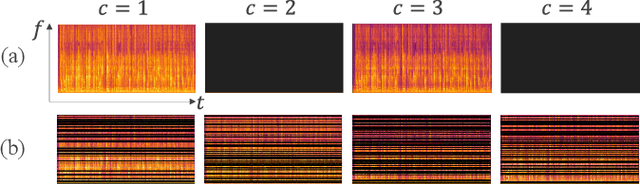
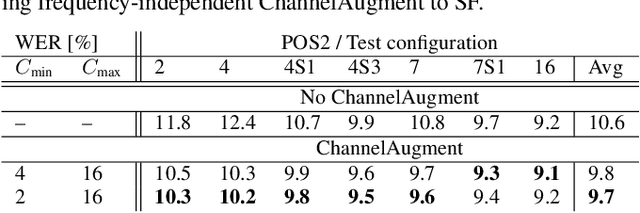
End-to-end (E2E) multi-channel ASR systems show state-of-the-art performance in far-field ASR tasks by joint training of a multi-channel front-end along with the ASR model. The main limitation of such systems is that they are usually trained with data from a fixed array geometry, which can lead to degradation in accuracy when a different array is used in testing. This makes it challenging to deploy these systems in practice, as it is costly to retrain and deploy different models for various array configurations. To address this, we present a simple and effective data augmentation technique, which is based on randomly dropping channels in the multi-channel audio input during training, in order to improve the robustness to various array configurations at test time. We call this technique ChannelAugment, in contrast to SpecAugment (SA) which drops time and/or frequency components of a single channel input audio. We apply ChannelAugment to the Spatial Filtering (SF) and Minimum Variance Distortionless Response (MVDR) neural beamforming approaches. For SF, we observe 10.6% WER improvement across various array configurations employing different numbers of microphones. For MVDR, we achieve a 74% reduction in training time without causing degradation of recognition accuracy.
Dual-Encoder Architecture with Encoder Selection for Joint Close-Talk and Far-Talk Speech Recognition
Sep 17, 2021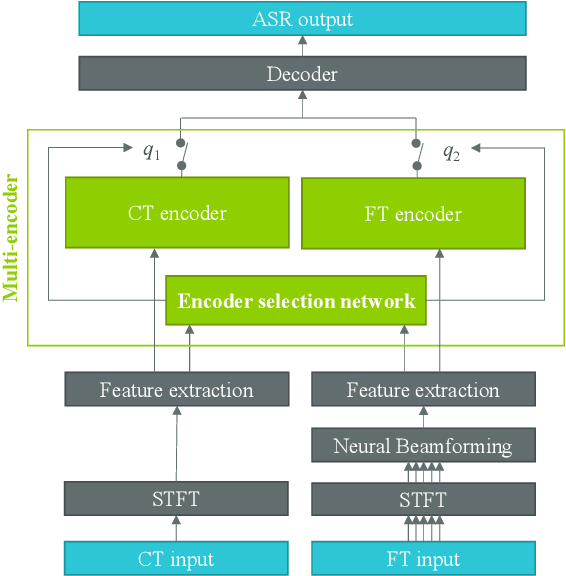

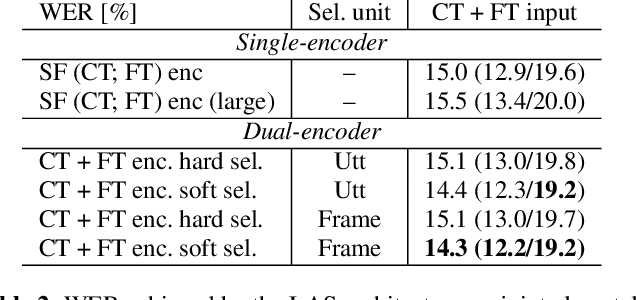
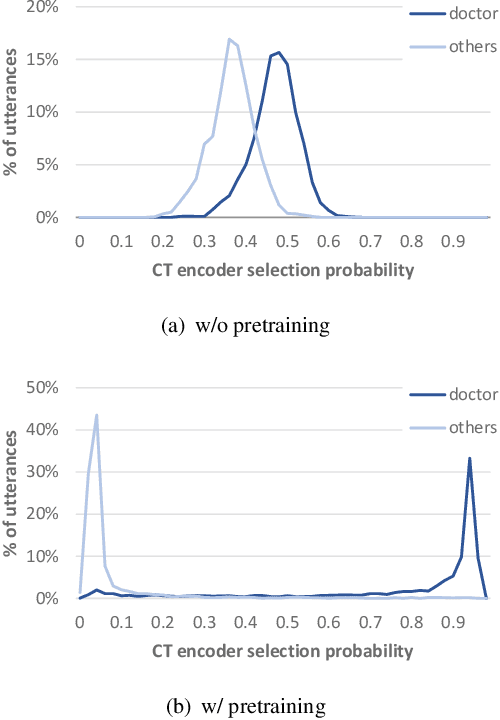
In this paper, we propose a dual-encoder ASR architecture for joint modeling of close-talk (CT) and far-talk (FT) speech, in order to combine the advantages of CT and FT devices for better accuracy. The key idea is to add an encoder selection network to choose the optimal input source (CT or FT) and the corresponding encoder. We use a single-channel encoder for CT speech and a multi-channel encoder with Spatial Filtering neural beamforming for FT speech, which are jointly trained with the encoder selection. We validate our approach on both attention-based and RNN Transducer end-to-end ASR systems. The experiments are done with conversational speech from a medical use case, which is recorded simultaneously with a CT device and a microphone array. Our results show that the proposed dual-encoder architecture obtains up to 9% relative WER reduction when using both CT and FT input, compared to the best single-encoder system trained and tested in matched condition.
Dyadic Speech-based Affect Recognition using DAMI-P2C Parent-child Multimodal Interaction Dataset
Aug 20, 2020
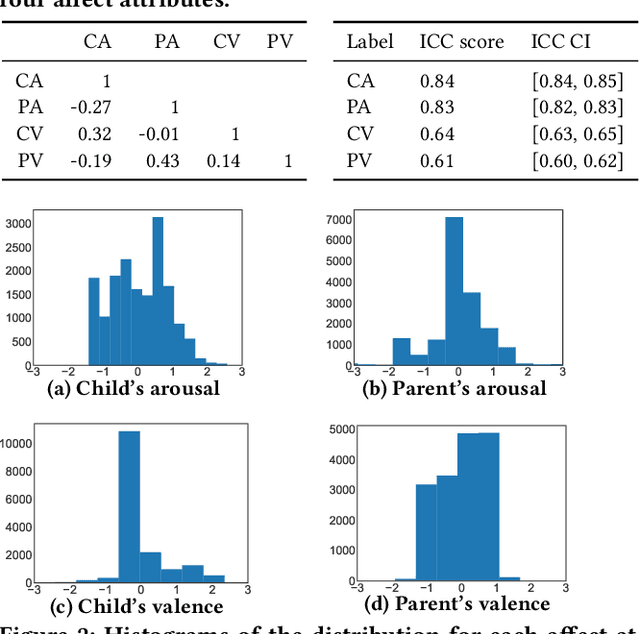

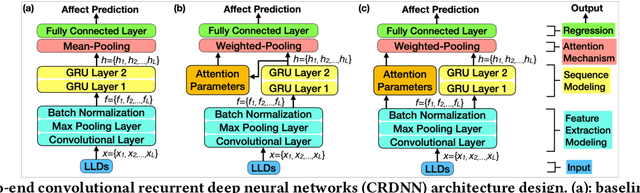
Automatic speech-based affect recognition of individuals in dyadic conversation is a challenging task, in part because of its heavy reliance on manual pre-processing. Traditional approaches frequently require hand-crafted speech features and segmentation of speaker turns. In this work, we design end-to-end deep learning methods to recognize each person's affective expression in an audio stream with two speakers, automatically discovering features and time regions relevant to the target speaker's affect. We integrate a local attention mechanism into the end-to-end architecture and compare the performance of three attention implementations -- one mean pooling and two weighted pooling methods. Our results show that the proposed weighted-pooling attention solutions are able to learn to focus on the regions containing target speaker's affective information and successfully extract the individual's valence and arousal intensity. Here we introduce and use a "dyadic affect in multimodal interaction - parent to child" (DAMI-P2C) dataset collected in a study of 34 families, where a parent and a child (3-7 years old) engage in reading storybooks together. In contrast to existing public datasets for affect recognition, each instance for both speakers in the DAMI-P2C dataset is annotated for the perceived affect by three labelers. To encourage more research on the challenging task of multi-speaker affect sensing, we make the annotated DAMI-P2C dataset publicly available, including acoustic features of the dyads' raw audios, affect annotations, and a diverse set of developmental, social, and demographic profiles of each dyad.
openXDATA: A Tool for Multi-Target Data Generation and Missing Label Completion
Jul 27, 2020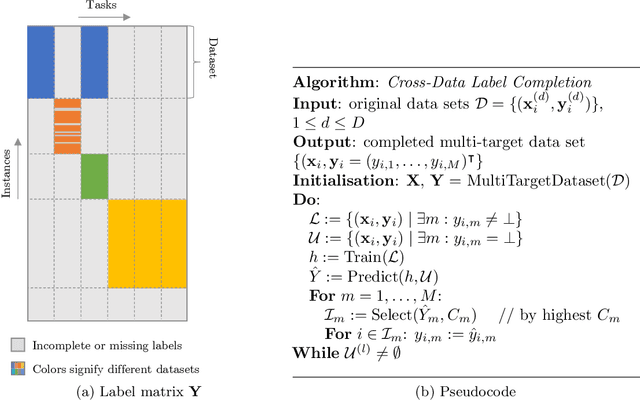
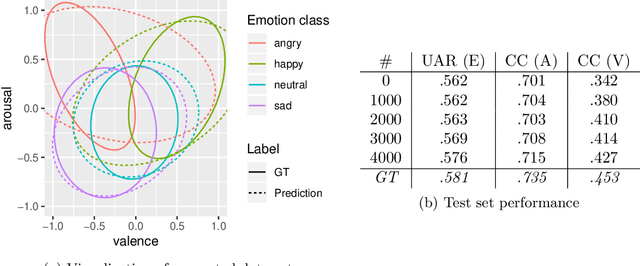
A common problem in machine learning is to deal with datasets with disjoint label spaces and missing labels. In this work, we introduce the openXDATA tool that completes the missing labels in partially labelled or unlabelled datasets in order to generate multi-target data with labels in the joint label space of the datasets. To this end, we designed and implemented the cross-data label completion (CDLC) algorithm that uses a multi-task shared-hidden-layer DNN to iteratively complete the sparse label matrix of the instances from the different datasets. We apply the new tool to estimate labels across four emotion datasets: one labeled with discrete emotion categories (e.g., happy, sad, angry), one labeled with continuous values along arousal and valence dimensions, one with both kinds of labels, and one unlabeled. Testing with drop-out of true labels, we show the ability to estimate both categories and continuous labels for all of the datasets, at rates that approached the ground truth values. openXDATA is available under the GNU General Public License from https://github.com/fweninger/openXDATA.
Semi-Supervised Learning with Data Augmentation for End-to-End ASR
Jul 27, 2020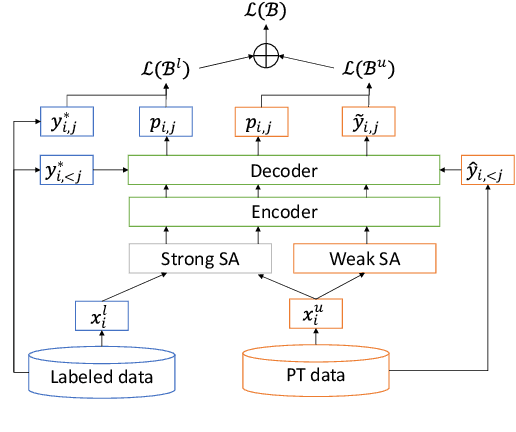

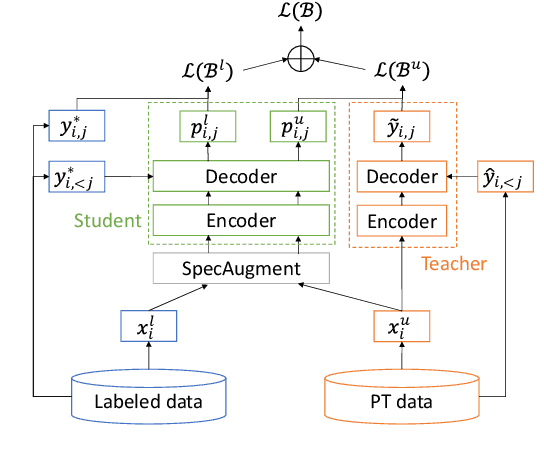
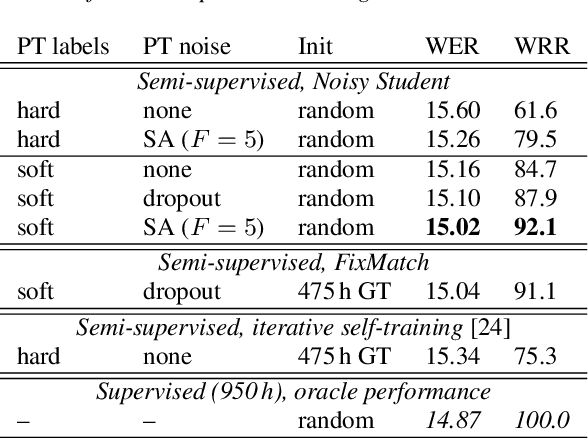
In this paper, we apply Semi-Supervised Learning (SSL) along with Data Augmentation (DA) for improving the accuracy of End-to-End ASR. We focus on the consistency regularization principle, which has been successfully applied to image classification tasks, and present sequence-to-sequence (seq2seq) versions of the FixMatch and Noisy Student algorithms. Specifically, we generate the pseudo labels for the unlabeled data on-the-fly with a seq2seq model after perturbing the input features with DA. We also propose soft label variants of both algorithms to cope with pseudo label errors, showing further performance improvements. We conduct SSL experiments on a conversational speech data set with 1.9kh manually transcribed training data, using only 25% of the original labels (475h labeled data). In the result, the Noisy Student algorithm with soft labels and consistency regularization achieves 10.4% word error rate (WER) reduction when adding 475h of unlabeled data, corresponding to a recovery rate of 92%. Furthermore, when iteratively adding 950h more unlabeled data, our best SSL performance is within 5% WER increase compared to using the full labeled training set (recovery rate: 78%).
Listen, Attend, Spell and Adapt: Speaker Adapted Sequence-to-Sequence ASR
Jul 08, 2019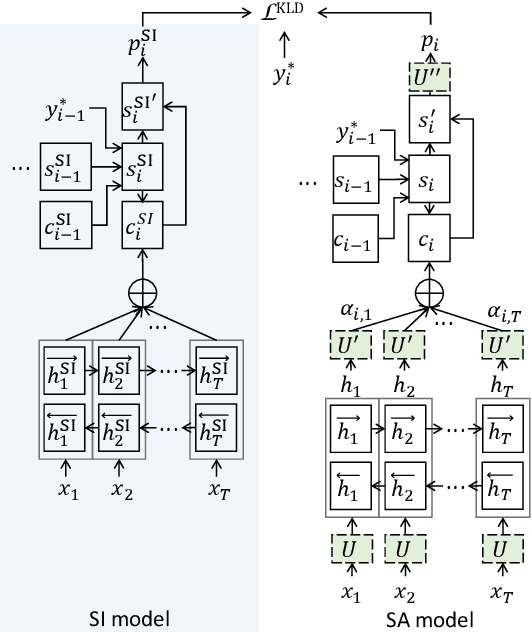
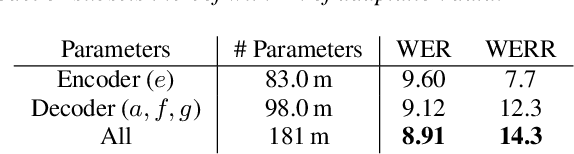

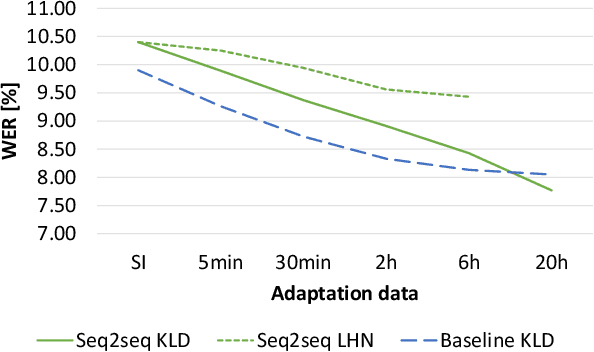
Sequence-to-sequence (seq2seq) based ASR systems have shown state-of-the-art performances while having clear advantages in terms of simplicity. However, comparisons are mostly done on speaker independent (SI) ASR systems, though speaker adapted conventional systems are commonly used in practice for improving robustness to speaker and environment variations. In this paper, we apply speaker adaptation to seq2seq models with the goal of matching the performance of conventional ASR adaptation. Specifically, we investigate Kullback-Leibler divergence (KLD) as well as Linear Hidden Network (LHN) based adaptation for seq2seq ASR, using different amounts (up to 20 hours) of adaptation data per speaker. Our SI models are trained on large amounts of dictation data and achieve state-of-the-art results. We obtained 25% relative word error rate (WER) improvement with KLD adaptation of the seq2seq model vs. 18.7% gain from acoustic model adaptation in the conventional system. We also show that the WER of the seq2seq model decreases log-linearly with the amount of adaptation data. Finally, we analyze adaptation based on the minimum WER criterion and adapting the language model (LM) for score fusion with the speaker adapted seq2seq model, which result in further improvements of the seq2seq system performance.
A Broadcast News Corpus for Evaluation and Tuning of German LVCSR Systems
Dec 15, 2014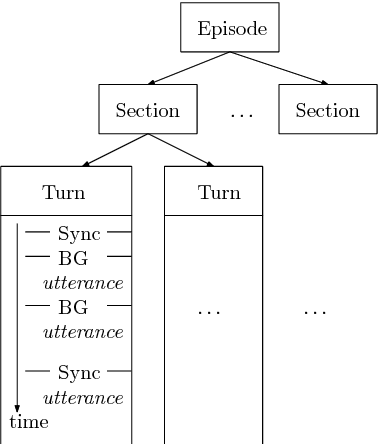
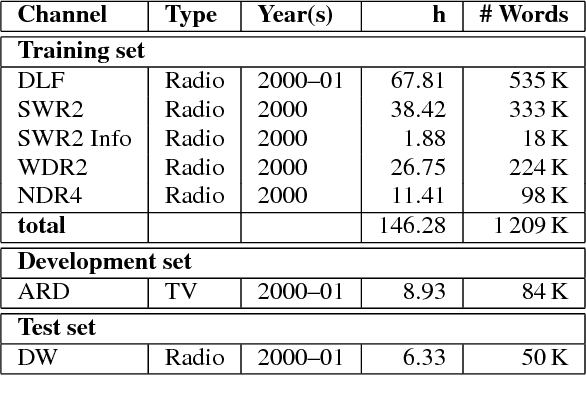
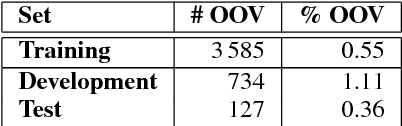
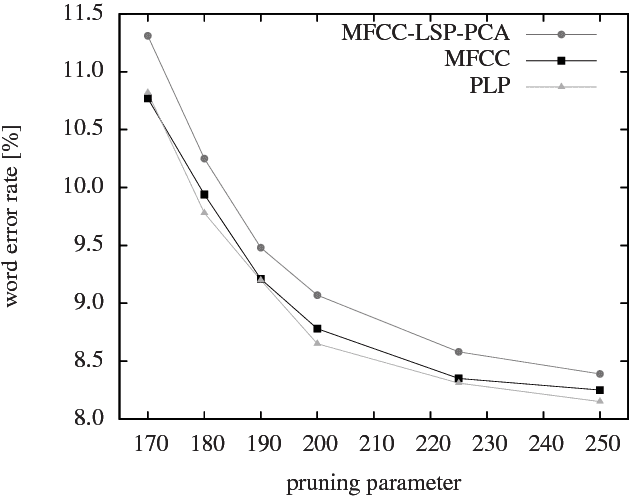
Transcription of broadcast news is an interesting and challenging application for large-vocabulary continuous speech recognition (LVCSR). We present in detail the structure of a manually segmented and annotated corpus including over 160 hours of German broadcast news, and propose it as an evaluation framework of LVCSR systems. We show our own experimental results on the corpus, achieved with a state-of-the-art LVCSR decoder, measuring the effect of different feature sets and decoding parameters, and thereby demonstrate that real-time decoding of our test set is feasible on a desktop PC at 9.2% word error rate.
Deep Unfolding: Model-Based Inspiration of Novel Deep Architectures
Nov 20, 2014
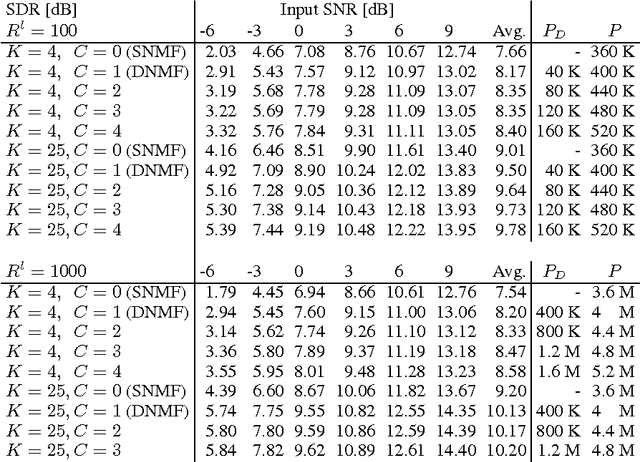
Model-based methods and deep neural networks have both been tremendously successful paradigms in machine learning. In model-based methods, problem domain knowledge can be built into the constraints of the model, typically at the expense of difficulties during inference. In contrast, deterministic deep neural networks are constructed in such a way that inference is straightforward, but their architectures are generic and it is unclear how to incorporate knowledge. This work aims to obtain the advantages of both approaches. To do so, we start with a model-based approach and an associated inference algorithm, and \emph{unfold} the inference iterations as layers in a deep network. Rather than optimizing the original model, we \emph{untie} the model parameters across layers, in order to create a more powerful network. The resulting architecture can be trained discriminatively to perform accurate inference within a fixed network size. We show how this framework allows us to interpret conventional networks as mean-field inference in Markov random fields, and to obtain new architectures by instead using belief propagation as the inference algorithm. We then show its application to a non-negative matrix factorization model that incorporates the problem-domain knowledge that sound sources are additive. Deep unfolding of this model yields a new kind of non-negative deep neural network, that can be trained using a multiplicative backpropagation-style update algorithm. We present speech enhancement experiments showing that our approach is competitive with conventional neural networks despite using far fewer parameters.