 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextual Density Ratio for Language Model Biasing of Sequence to Sequence ASR Systems
Jun 29, 2022
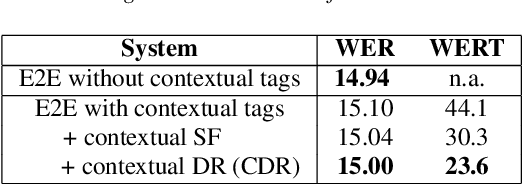

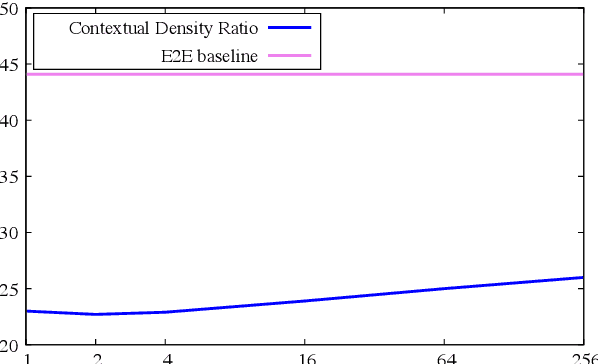
End-2-end (E2E) models have become increasingly popular in some ASR tasks because of their performance and advantages. These E2E models directly approximate the posterior distribution of tokens given the acoustic inputs. Consequently, the E2E systems implicitly define a language model (LM) over the output tokens, which makes the exploitation of independently trained language models less straightforward than in conventional ASR systems. This makes it difficult to dynamically adapt E2E ASR system to contextual profiles for better recognizing special words such as named entities. In this work, we propose a contextual density ratio approach for both training a contextual aware E2E model and adapting the language model to named entities. We apply the aforementioned technique to an E2E ASR system, which transcribes doctor and patient conversations, for better adapting the E2E system to the names in the conversations. Our proposed technique achieves a relative improvement of up to 46.5% on the names over an E2E baseline without degrading the overall recognition accuracy of the whole test set. Moreover, it also surpasses a contextual shallow fusion baseline by 22.1 % relative.
* Interspeech 2021 (draft)
On the Prediction Network Architecture in RNN-T for ASR
Jun 29, 2022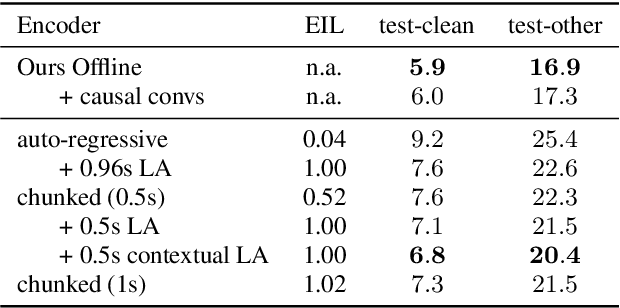
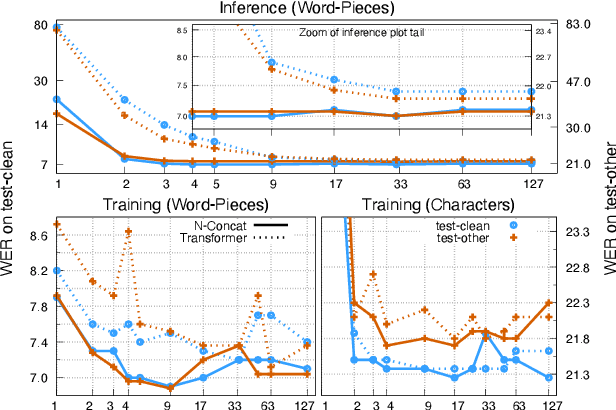
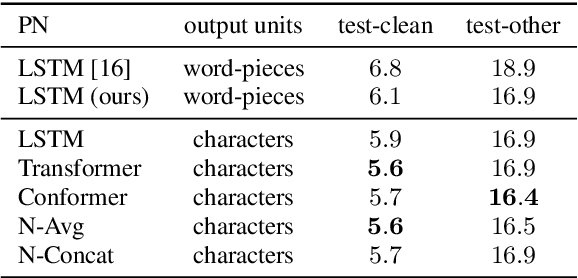
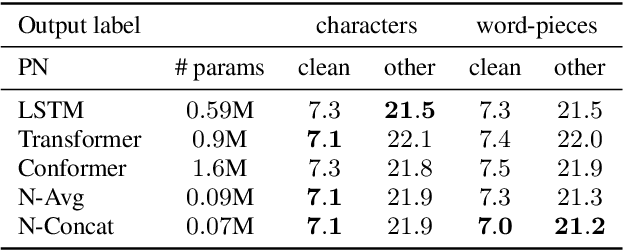
RNN-T models have gained popularity in the literature and in commercial systems because of their competitiveness and capability of operating in online streaming mode. In this work, we conduct an extensive study comparing several prediction network architectures for both monotonic and original RNN-T models. We compare 4 types of prediction networks based on a common state-of-the-art Conformer encoder and report results obtained on Librispeech and an internal medical conversation data set. Our study covers both offline batch-mode and online streaming scenarios. In contrast to some previous works, our results show that Transformer does not always outperform LSTM when used as prediction network along with Conformer encoder. Inspired by our scoreboard, we propose a new simple prediction network architecture, N-Concat, that outperforms the others in our on-line streaming benchmark. Transformer and n-gram reduced architectures perform very similarly yet with some important distinct behaviour in terms of previous context. Overall we obtained up to 4.1 % relative WER improvement compared to our LSTM baseline, while reducing prediction network parameters by nearly an order of magnitude (8.4 times).
Conformer with dual-mode chunked attention for joint online and offline ASR
Jun 22, 2022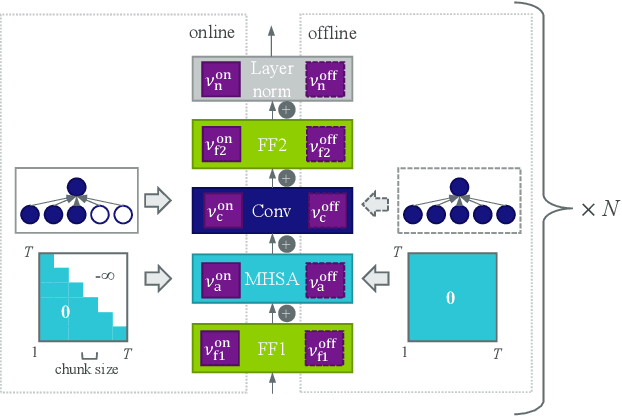
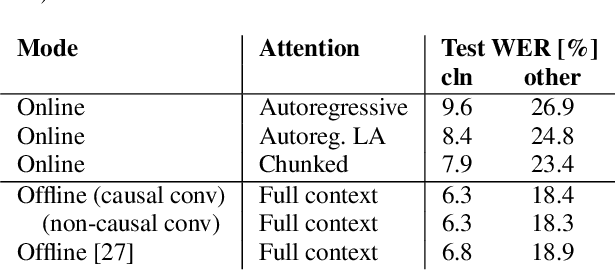
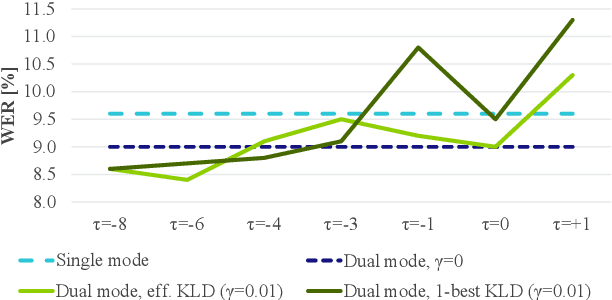
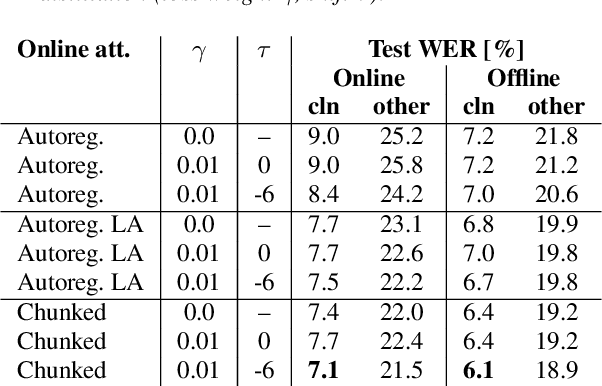
In this paper, we present an in-depth study on online attention mechanisms and distillation techniques for dual-mode (i.e., joint online and offline) ASR using the Conformer Transducer. In the dual-mode Conformer Transducer model, layers can function in online or offline mode while sharing parameters, and in-place knowledge distillation from offline to online mode is applied in training to improve online accuracy. In our study, we first demonstrate accuracy improvements from using chunked attention in the Conformer encoder compared to autoregressive attention with and without lookahead. Furthermore, we explore the efficient KLD and 1-best KLD losses with different shifts between online and offline outputs in the knowledge distillation. Finally, we show that a simplified dual-mode Conformer that only has mode-specific self-attention performs equally well as the one also having mode-specific convolutions and normalization. Our experiments are based on two very different datasets: the Librispeech task and an internal corpus of medical conversations. Results show that the proposed dual-mode system using chunked attention yields 5% and 4% relative WER improvement on the Librispeech and medical tasks, compared to the dual-mode system using autoregressive attention with similar average lookahead.
ChannelAugment: Improving generalization of multi-channel ASR by training with input channel randomization
Sep 23, 2021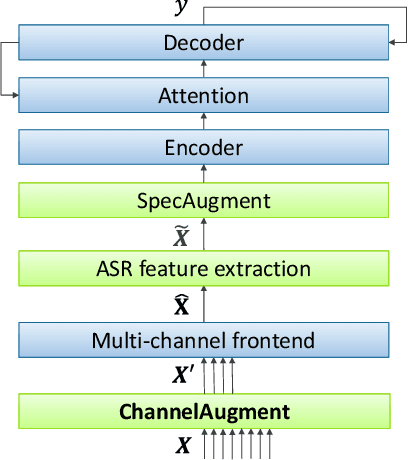
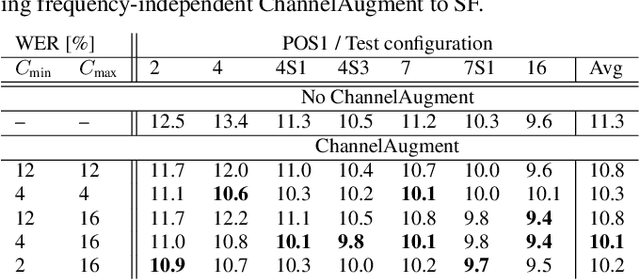
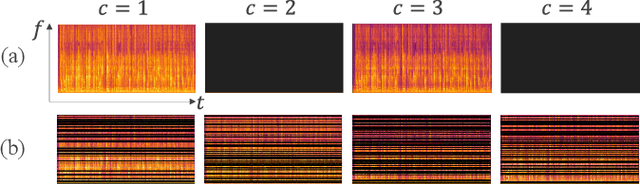
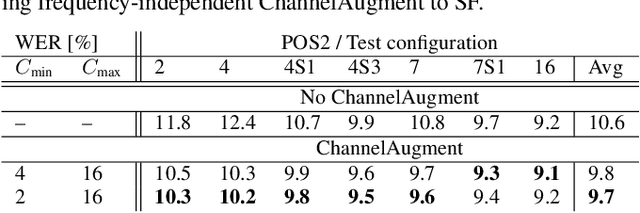
End-to-end (E2E) multi-channel ASR systems show state-of-the-art performance in far-field ASR tasks by joint training of a multi-channel front-end along with the ASR model. The main limitation of such systems is that they are usually trained with data from a fixed array geometry, which can lead to degradation in accuracy when a different array is used in testing. This makes it challenging to deploy these systems in practice, as it is costly to retrain and deploy different models for various array configurations. To address this, we present a simple and effective data augmentation technique, which is based on randomly dropping channels in the multi-channel audio input during training, in order to improve the robustness to various array configurations at test time. We call this technique ChannelAugment, in contrast to SpecAugment (SA) which drops time and/or frequency components of a single channel input audio. We apply ChannelAugment to the Spatial Filtering (SF) and Minimum Variance Distortionless Response (MVDR) neural beamforming approaches. For SF, we observe 10.6% WER improvement across various array configurations employing different numbers of microphones. For MVDR, we achieve a 74% reduction in training time without causing degradation of recognition accuracy.
Dual-Encoder Architecture with Encoder Selection for Joint Close-Talk and Far-Talk Speech Recognition
Sep 17, 2021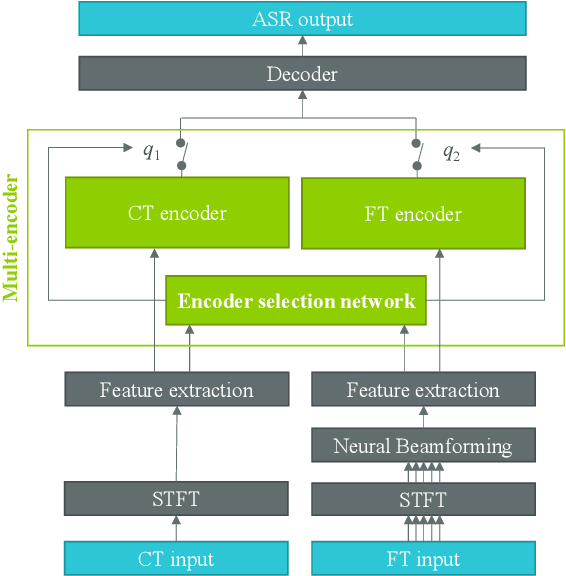

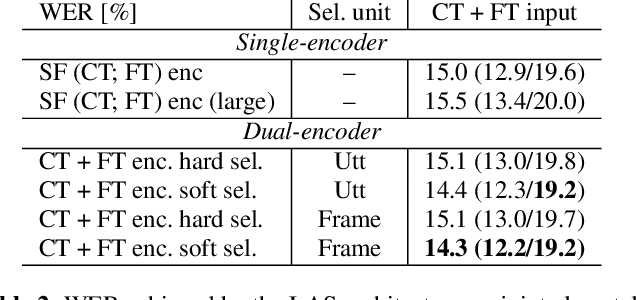
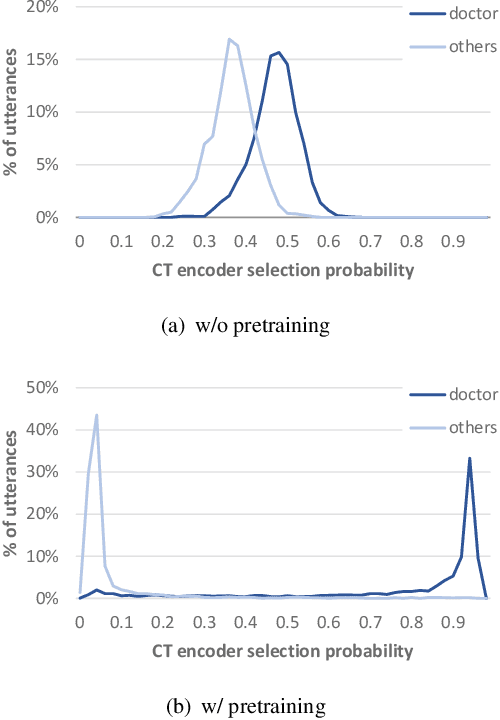
In this paper, we propose a dual-encoder ASR architecture for joint modeling of close-talk (CT) and far-talk (FT) speech, in order to combine the advantages of CT and FT devices for better accuracy. The key idea is to add an encoder selection network to choose the optimal input source (CT or FT) and the corresponding encoder. We use a single-channel encoder for CT speech and a multi-channel encoder with Spatial Filtering neural beamforming for FT speech, which are jointly trained with the encoder selection. We validate our approach on both attention-based and RNN Transducer end-to-end ASR systems. The experiments are done with conversational speech from a medical use case, which is recorded simultaneously with a CT device and a microphone array. Our results show that the proposed dual-encoder architecture obtains up to 9% relative WER reduction when using both CT and FT input, compared to the best single-encoder system trained and tested in matched condition.
Semi-Supervised Learning with Data Augmentation for End-to-End ASR
Jul 27, 2020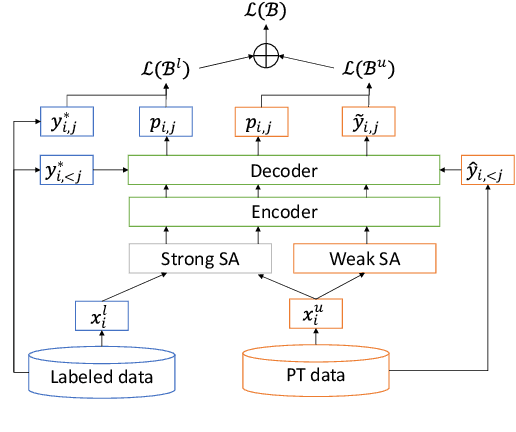

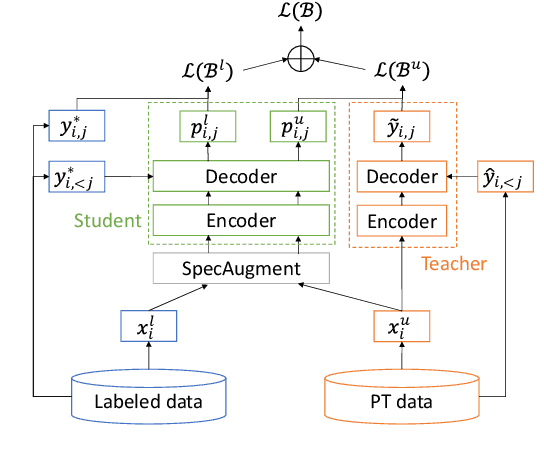
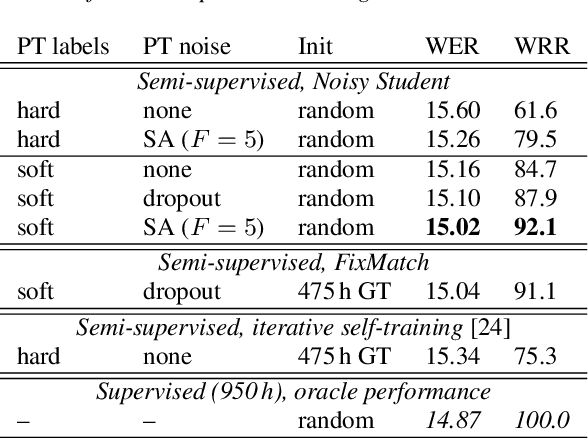
In this paper, we apply Semi-Supervised Learning (SSL) along with Data Augmentation (DA) for improving the accuracy of End-to-End ASR. We focus on the consistency regularization principle, which has been successfully applied to image classification tasks, and present sequence-to-sequence (seq2seq) versions of the FixMatch and Noisy Student algorithms. Specifically, we generate the pseudo labels for the unlabeled data on-the-fly with a seq2seq model after perturbing the input features with DA. We also propose soft label variants of both algorithms to cope with pseudo label errors, showing further performance improvements. We conduct SSL experiments on a conversational speech data set with 1.9kh manually transcribed training data, using only 25% of the original labels (475h labeled data). In the result, the Noisy Student algorithm with soft labels and consistency regularization achieves 10.4% word error rate (WER) reduction when adding 475h of unlabeled data, corresponding to a recovery rate of 92%. Furthermore, when iteratively adding 950h more unlabeled data, our best SSL performance is within 5% WER increase compared to using the full labeled training set (recovery rate: 78%).
Listen, Attend, Spell and Adapt: Speaker Adapted Sequence-to-Sequence ASR
Jul 08, 2019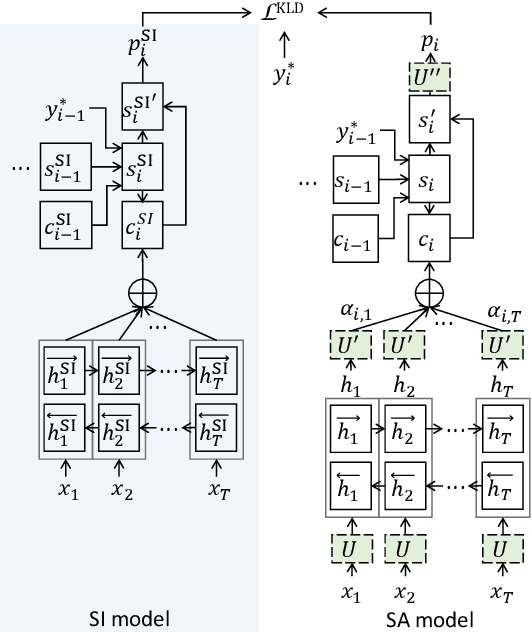
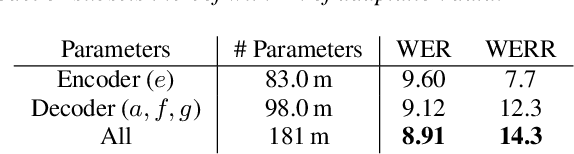

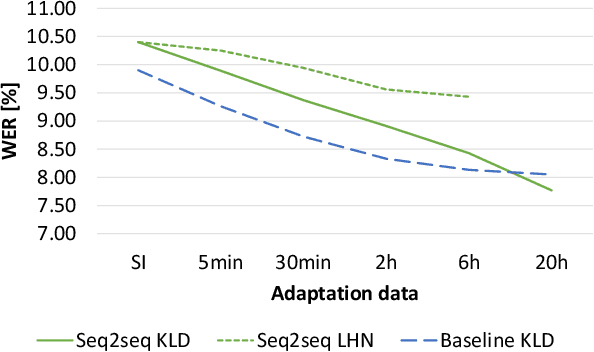
Sequence-to-sequence (seq2seq) based ASR systems have shown state-of-the-art performances while having clear advantages in terms of simplicity. However, comparisons are mostly done on speaker independent (SI) ASR systems, though speaker adapted conventional systems are commonly used in practice for improving robustness to speaker and environment variations. In this paper, we apply speaker adaptation to seq2seq models with the goal of matching the performance of conventional ASR adaptation. Specifically, we investigate Kullback-Leibler divergence (KLD) as well as Linear Hidden Network (LHN) based adaptation for seq2seq ASR, using different amounts (up to 20 hours) of adaptation data per speaker. Our SI models are trained on large amounts of dictation data and achieve state-of-the-art results. We obtained 25% relative word error rate (WER) improvement with KLD adaptation of the seq2seq model vs. 18.7% gain from acoustic model adaptation in the conventional system. We also show that the WER of the seq2seq model decreases log-linearly with the amount of adaptation data. Finally, we analyze adaptation based on the minimum WER criterion and adapting the language model (LM) for score fusion with the speaker adapted seq2seq model, which result in further improvements of the seq2seq system performance.