 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Understanding-Oriented Robust Machine Reading Comprehension Model
Jul 01, 2022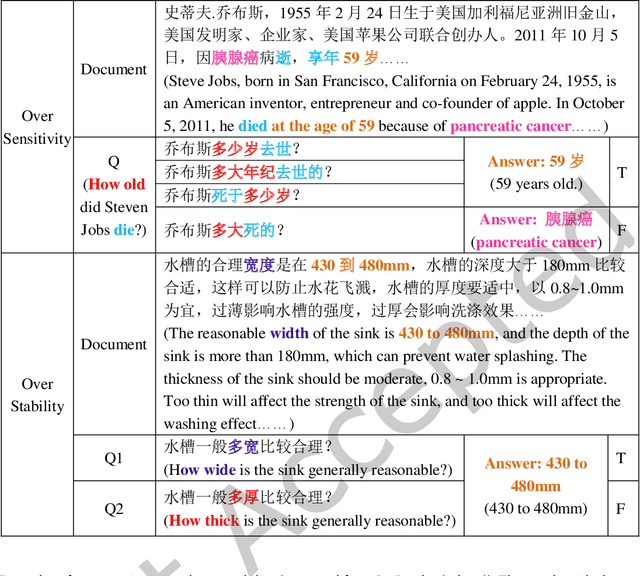
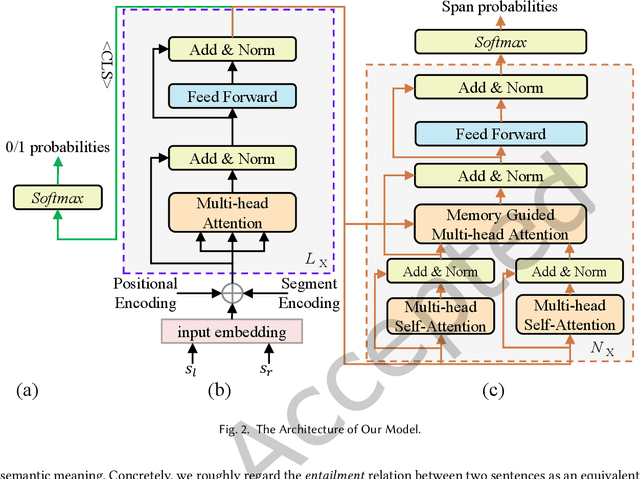
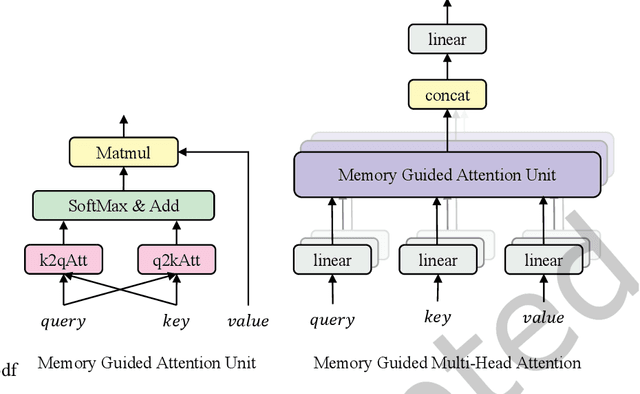
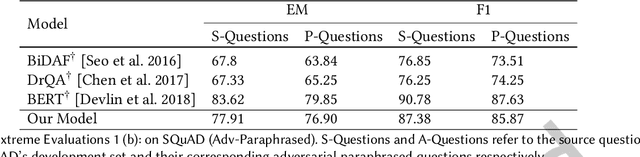
Although existing machine reading comprehension models are making rapid progress on many datasets, they are far from robust. In this paper, we propose an understanding-oriented machine reading comprehension model to address three kinds of robustness issues, which are over sensitivity, over stability and generalization. Specifically, we first use a natural language inference module to help the model understand the accurate semantic meanings of input questions so as to address the issues of over sensitivity and over stability. Then in the machine reading comprehension module, we propose a memory-guided multi-head attention method that can further well understand the semantic meanings of input questions and passages. Third, we propose a multilanguage learning mechanism to address the issue of generalization. Finally, these modules are integrated with a multi-task learning based method. We evaluate our model on three benchmark datasets that are designed to measure models robustness, including DuReader (robust) and two SQuAD-related datasets. Extensive experiments show that our model can well address the mentioned three kinds of robustness issues. And it achieves much better results than the compared state-of-the-art models on all these datasets under different evaluation metrics, even under some extreme and unfair evaluations. The source code of our work is available at: https://github.com/neukg/RobustMRC.
Deep Understanding based Multi-Document Machine Reading Comprehension
Feb 25, 2022
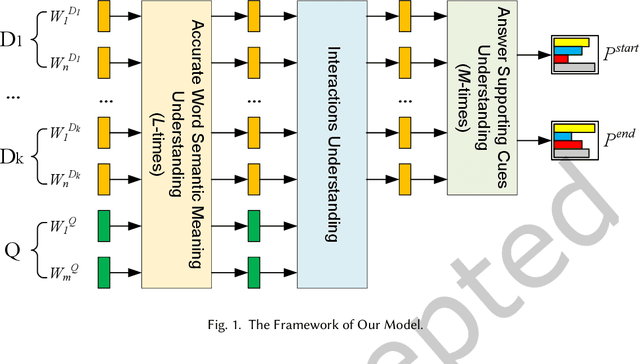
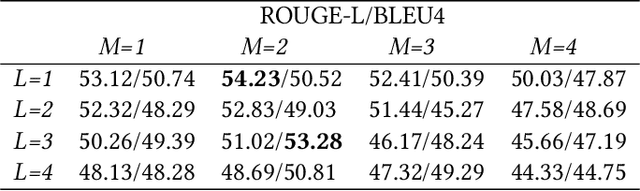
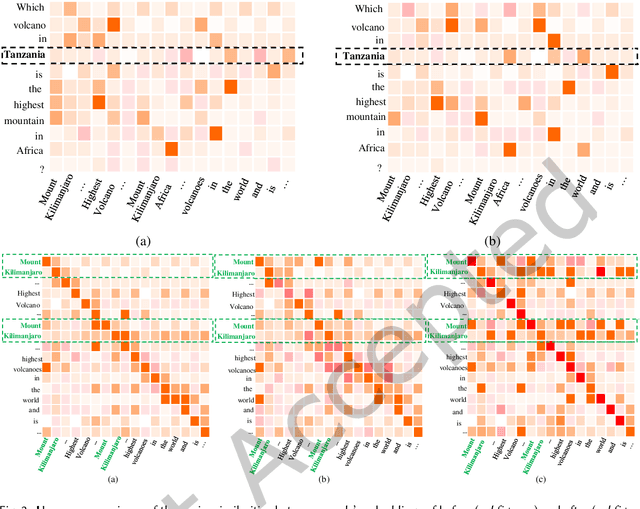
Most existing multi-document machine reading comprehension models mainly focus on understanding the interactions between the input question and documents, but ignore following two kinds of understandings. First, to understand the semantic meaning of words in the input question and documents from the perspective of each other. Second, to understand the supporting cues for a correct answer from the perspective of intra-document and inter-documents. Ignoring these two kinds of important understandings would make the models oversee some important information that may be helpful for inding correct answers. To overcome this deiciency, we propose a deep understanding based model for multi-document machine reading comprehension. It has three cascaded deep understanding modules which are designed to understand the accurate semantic meaning of words, the interactions between the input question and documents, and the supporting cues for the correct answer. We evaluate our model on two large scale benchmark datasets, namely TriviaQA Web and DuReader. Extensive experiments show that our model achieves state-of-the-art results on both datasets.