 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiDO: Fusion-in-Decoder optimized for stronger performance and faster inference
Dec 15, 2022



Fusion-in-Decoder (FiD) is a powerful retrieval-augmented language model that sets the state-of-the-art on many knowledge-intensive NLP tasks. However, FiD suffers from very expensive inference. We show that the majority of inference time results from memory bandwidth constraints in the decoder, and propose two simple changes to the FiD architecture to speed up inference by 7x. The faster decoder inference then allows for a much larger decoder. We denote FiD with the above modifications as FiDO, and show that it strongly improves performance over existing FiD models for a wide range of inference budgets. For example, FiDO-Large-XXL performs faster inference than FiD-Base and achieves better performance than FiD-Large.
Generate-and-Retrieve: use your predictions to improve retrieval for semantic parsing
Sep 29, 2022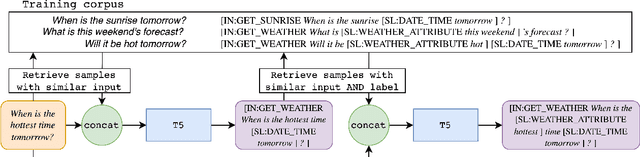
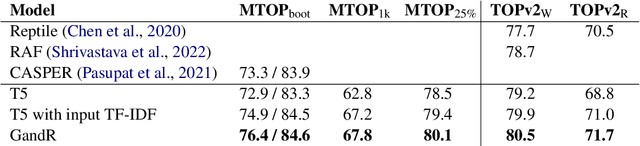
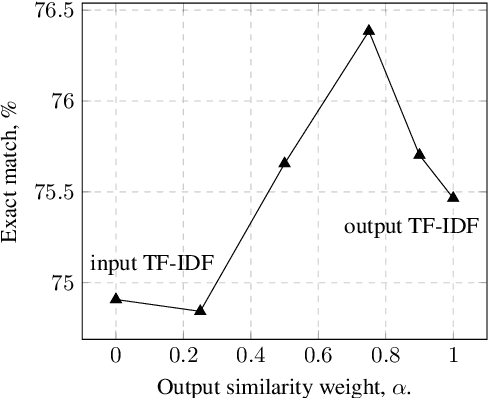
A common recent approach to semantic parsing augments sequence-to-sequence models by retrieving and appending a set of training samples, called exemplars. The effectiveness of this recipe is limited by the ability to retrieve informative exemplars that help produce the correct parse, which is especially challenging in low-resource settings. Existing retrieval is commonly based on similarity of query and exemplar inputs. We propose GandR, a retrieval procedure that retrieves exemplars for which outputs are also similar. GandRfirst generates a preliminary prediction with input-based retrieval. Then, it retrieves exemplars with outputs similar to the preliminary prediction which are used to generate a final prediction. GandR sets the state of the art on multiple low-resource semantic parsing tasks.
ALMA: Hierarchical Learning for Composite Multi-Agent Tasks
May 27, 2022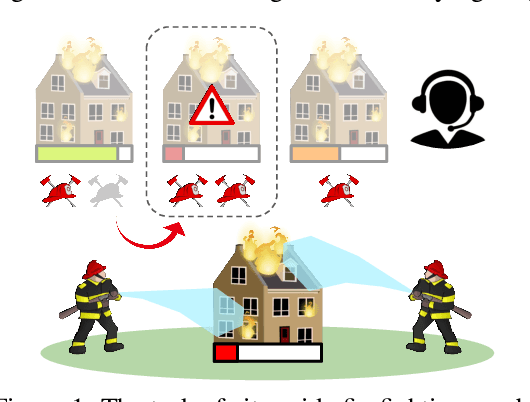

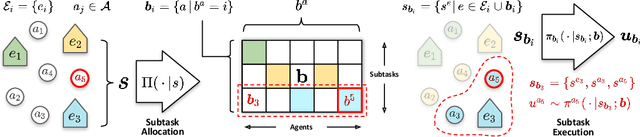
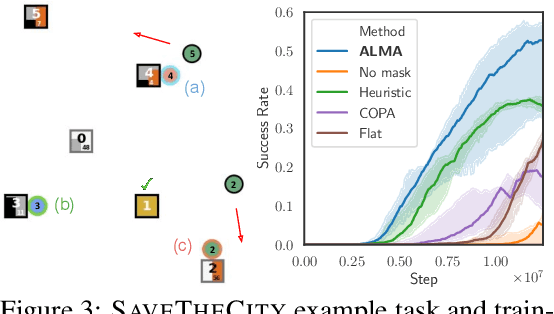
Despite significant progress on multi-agent reinforcement learning (MARL) in recent years, coordination in complex domains remains a challenge. Work in MARL often focuses on solving tasks where agents interact with all other agents and entities in the environment; however, we observe that real-world tasks are often composed of several isolated instances of local agent interactions (subtasks), and each agent can meaningfully focus on one subtask to the exclusion of all else in the environment. In these composite tasks, successful policies can often be decomposed into two levels of decision-making: agents are allocated to specific subtasks and each agent acts productively towards their assigned subtask alone. This decomposed decision making provides a strong structural inductive bias, significantly reduces agent observation spaces, and encourages subtask-specific policies to be reused and composed during training, as opposed to treating each new composition of subtasks as unique. We introduce ALMA, a general learning method for taking advantage of these structured tasks. ALMA simultaneously learns a high-level subtask allocation policy and low-level agent policies. We demonstrate that ALMA learns sophisticated coordination behavior in a number of challenging environments, outperforming strong baselines. ALMA's modularity also enables it to better generalize to new environment configurations. Finally, we find that while ALMA can integrate separately trained allocation and action policies, the best performance is obtained only by training all components jointly.
Evaluating the Impact of Model Scale for Compositional Generalization in Semantic Parsing
May 24, 2022
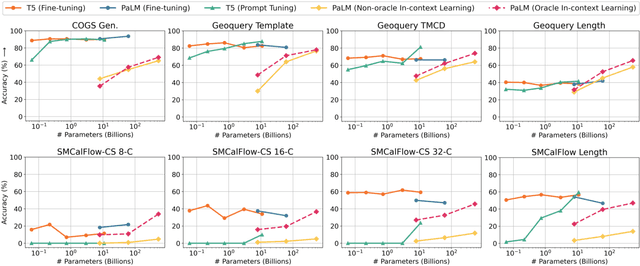
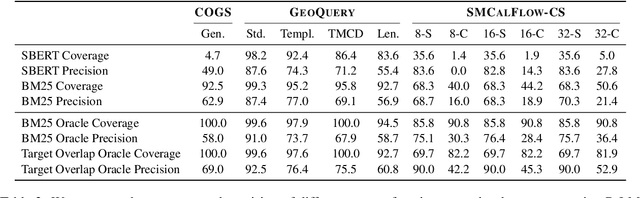
Despite their strong performance on many tasks, pre-trained language models have been shown to struggle on out-of-distribution compositional generalization. Meanwhile, recent work has shown considerable improvements on many NLP tasks from model scaling. Can scaling up model size also improve compositional generalization in semantic parsing? We evaluate encoder-decoder models up to 11B parameters and decoder-only models up to 540B parameters, and compare model scaling curves for three different methods for transfer learning: fine-tuning all parameters, prompt tuning, and in-context learning. We observe that fine-tuning generally has flat or negative scaling curves on out-of-distribution compositional generalization in semantic parsing evaluations. In-context learning has positive scaling curves, but is generally outperformed by much smaller fine-tuned models. Prompt-tuning can outperform fine-tuning, suggesting further potential improvements from scaling as it exhibits a more positive scaling curve. Additionally, we identify several error trends that vary with model scale. For example, larger models are generally better at modeling the syntax of the output space, but are also more prone to certain types of overfitting. Overall, our study highlights limitations of current techniques for effectively leveraging model scale for compositional generalization, while our analysis also suggests promising directions for future work.
Possibility Before Utility: Learning And Using Hierarchical Affordances
Mar 23, 2022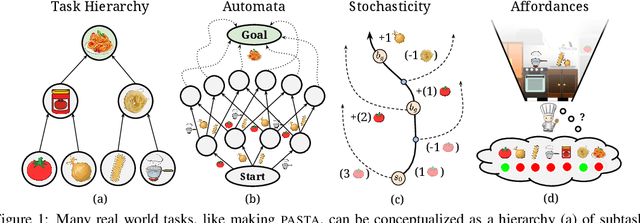
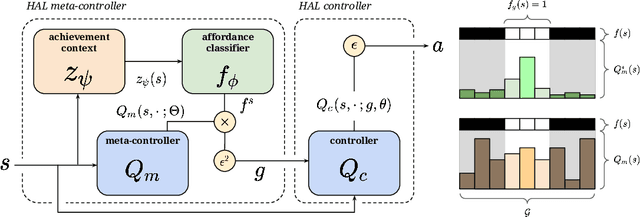
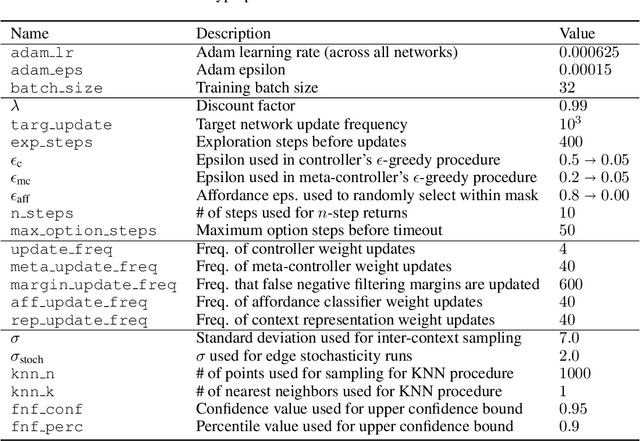
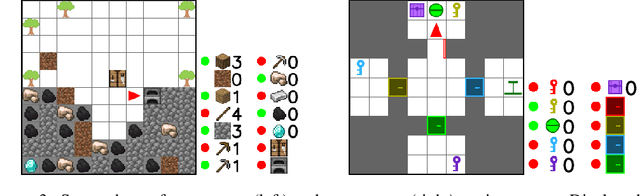
Reinforcement learning algorithms struggle on tasks with complex hierarchical dependency structures. Humans and other intelligent agents do not waste time assessing the utility of every high-level action in existence, but instead only consider ones they deem possible in the first place. By focusing only on what is feasible, or "afforded", at the present moment, an agent can spend more time both evaluating the utility of and acting on what matters. To this end, we present Hierarchical Affordance Learning (HAL), a method that learns a model of hierarchical affordances in order to prune impossible subtasks for more effective learning. Existing works in hierarchical reinforcement learning provide agents with structural representations of subtasks but are not affordance-aware, and by grounding our definition of hierarchical affordances in the present state, our approach is more flexible than the multitude of approaches that ground their subtask dependencies in a symbolic history. While these logic-based methods often require complete knowledge of the subtask hierarchy, our approach is able to utilize incomplete and varying symbolic specifications. Furthermore, we demonstrate that relative to non-affordance-aware methods, HAL agents are better able to efficiently learn complex tasks, navigate environment stochasticity, and acquire diverse skills in the absence of extrinsic supervision -- all of which are hallmarks of human learning.
Policy Learning and Evaluation with Randomized Quasi-Monte Carlo
Feb 21, 2022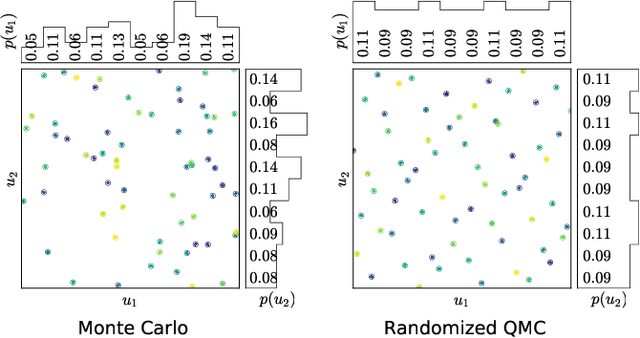
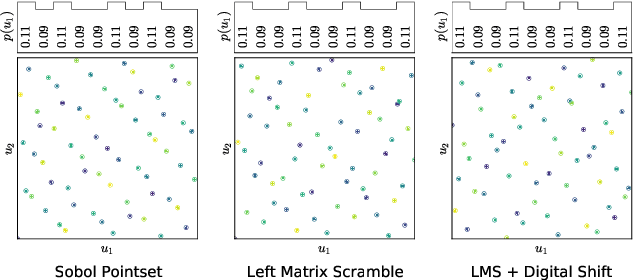
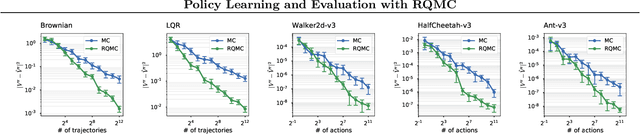
Reinforcement learning constantly deals with hard integrals, for example when computing expectations in policy evaluation and policy iteration. These integrals are rarely analytically solvable and typically estimated with the Monte Carlo method, which induces high variance in policy values and gradients. In this work, we propose to replace Monte Carlo samples with low-discrepancy point sets. We combine policy gradient methods with Randomized Quasi-Monte Carlo, yielding variance-reduced formulations of policy gradient and actor-critic algorithms. These formulations are effective for policy evaluation and policy improvement, as they outperform state-of-the-art algorithms on standardized continuous control benchmarks. Our empirical analyses validate the intuition that replacing Monte Carlo with Quasi-Monte Carlo yields significantly more accurate gradient estimates.
Improving Compositional Generalization with Latent Structure and Data Augmentation
Dec 14, 2021
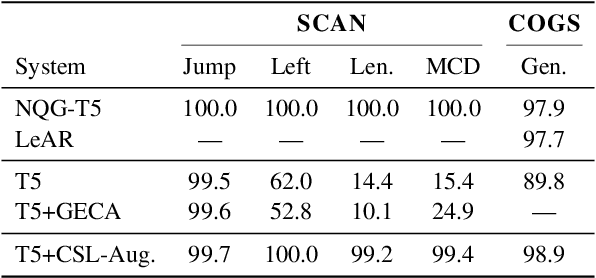
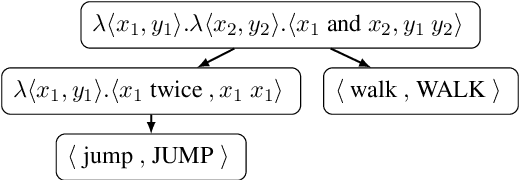
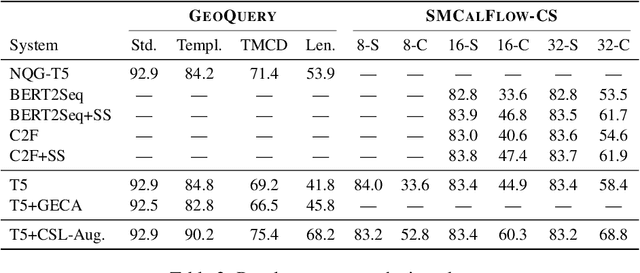
Generic unstructured neural networks have been shown to struggle on out-of-distribution compositional generalization. Compositional data augmentation via example recombination has transferred some prior knowledge about compositionality to such black-box neural models for several semantic parsing tasks, but this often required task-specific engineering or provided limited gains. We present a more powerful data recombination method using a model called Compositional Structure Learner (CSL). CSL is a generative model with a quasi-synchronous context-free grammar backbone, which we induce from the training data. We sample recombined examples from CSL and add them to the fine-tuning data of a pre-trained sequence-to-sequence model (T5). This procedure effectively transfers most of CSL's compositional bias to T5 for diagnostic tasks, and results in a model even stronger than a T5-CSL ensemble on two real world compositional generalization tasks. This results in new state-of-the-art performance for these challenging semantic parsing tasks requiring generalization to both natural language variation and novel compositions of elements.
Co-training Transformer with Videos and Images Improves Action Recognition
Dec 14, 2021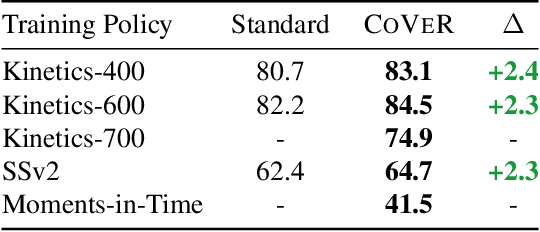
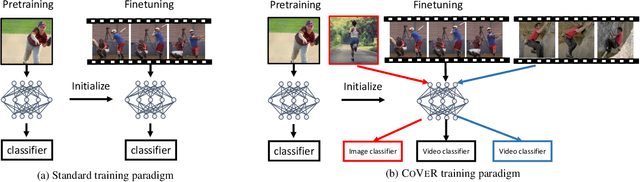

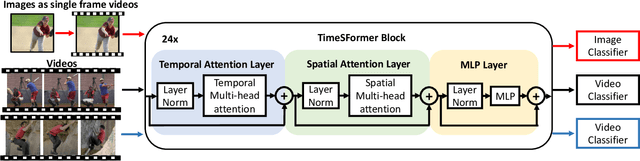
In learning action recognition, models are typically pre-trained on object recognition with images, such as ImageNet, and later fine-tuned on target action recognition with videos. This approach has achieved good empirical performance especially with recent transformer-based video architectures. While recently many works aim to design more advanced transformer architectures for action recognition, less effort has been made on how to train video transformers. In this work, we explore several training paradigms and present two findings. First, video transformers benefit from joint training on diverse video datasets and label spaces (e.g., Kinetics is appearance-focused while SomethingSomething is motion-focused). Second, by further co-training with images (as single-frame videos), the video transformers learn even better video representations. We term this approach as Co-training Videos and Images for Action Recognition (CoVeR). In particular, when pretrained on ImageNet-21K based on the TimeSFormer architecture, CoVeR improves Kinetics-400 Top-1 Accuracy by 2.4%, Kinetics-600 by 2.3%, and SomethingSomething-v2 by 2.3%. When pretrained on larger-scale image datasets following previous state-of-the-art, CoVeR achieves best results on Kinetics-400 (87.2%), Kinetics-600 (87.9%), Kinetics-700 (79.8%), SomethingSomething-v2 (70.9%), and Moments-in-Time (46.1%), with a simple spatio-temporal video transformer.
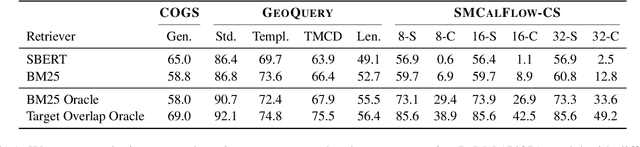
Learning to Generalize Compositionally by Transferring Across Semantic Parsing Tasks
Nov 09, 2021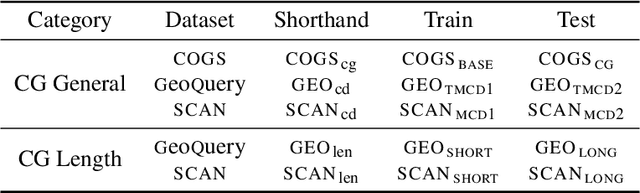

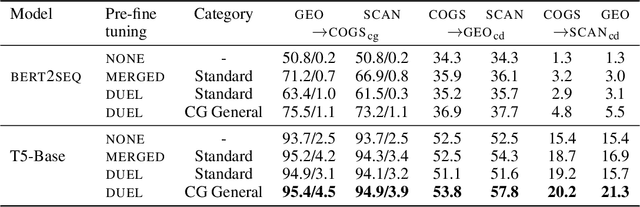

Neural network models often generalize poorly to mismatched domains or distributions. In NLP, this issue arises in particular when models are expected to generalize compositionally, that is, to novel combinations of familiar words and constructions. We investigate learning representations that facilitate transfer learning from one compositional task to another: the representation and the task-specific layers of the models are strategically trained differently on a pre-finetuning task such that they generalize well on mismatched splits that require compositionality. We apply this method to semantic parsing, using three very different datasets, COGS, GeoQuery and SCAN, used alternately as the pre-finetuning and target task. Our method significantly improves compositional generalization over baselines on the test set of the target task, which is held out during fine-tuning. Ablation studies characterize the utility of the major steps in the proposed algorithm and support our hypothesis.
HyperPINN: Learning parameterized differential equations with physics-informed hypernetworks
Oct 28, 2021
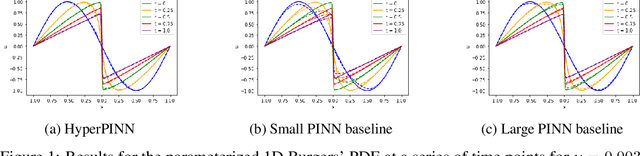
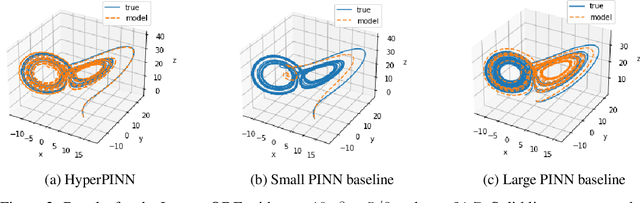
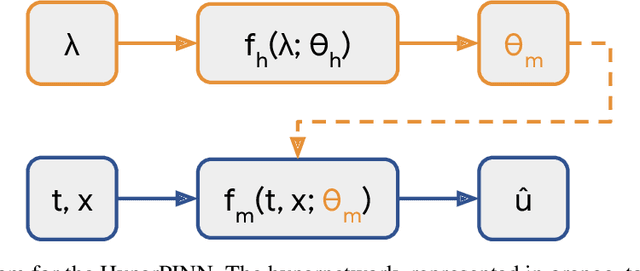
Many types of physics-informed neural network models have been proposed in recent years as approaches for learning solutions to differential equations. When a particular task requires solving a differential equation at multiple parameterizations, this requires either re-training the model, or expanding its representation capacity to include the parameterization -- both solution that increase its computational cost. We propose the HyperPINN, which uses hypernetworks to learn to generate neural networks that can solve a differential equation from a given parameterization. We demonstrate with experiments on both a PDE and an ODE that this type of model can lead to neural network solutions to differential equations that maintain a small size, even when learning a family of solutions over a parameter space.