 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevealing Domain-Spatiality Patterns for Configuration Tuning: Domain Knowledge Meets Fitness Landscapes
Mar 23, 2026Configuration tuning for better performance is crucial in quality assurance. Yet, there has long been a mystery on tuners' effectiveness, due to the black-box nature of configurable systems. Prior efforts predominantly adopt static domain analysis (e.g., static taint analysis), which often lacks generalizability, or dynamic data analysis (e.g., benchmarking performance analysis), limiting explainability. In this work, we embrace Fitness Landscape Analysis (FLA) as a bridge between domain knowledge and difficulty of the tuning. We propose Domland, a two-pronged methodology that synergizes the spatial information obtained from FLA and domain-driven analysis to systematically capture the hidden characteristics of configuration tuning cases, explaining how and why a tuner might succeed or fail. This helps to better interpret and contextualize the behavior of tuners and inform tuner design. To evaluate Domland, we conduct a case study of nine software systems and 93 workloads, from which we reveal several key findings: (1) configuration landscapes are inherently system-specific, with no single domain factor (e.g., system area, programming language, or resource intensity) consistently shaping their structure; (2) the core options (e.g., pic-struct of x264), which control the main functional flows, exert a stronger influence on landscape ruggedness (i.e. the difficulty of tuning) compared to resource options (e.g., cpu-independent of x264); (3) Workload effects on landscape structure are not uniformly tied to type or scale. Both contribute to landscape variations, but their impact is system-dependent.
Distilled Lifelong Self-Adaptation for Configurable Systems
Jan 01, 2025



Modern configurable systems provide tremendous opportunities for engineering future intelligent software systems. A key difficulty thereof is how to effectively self-adapt the configuration of a running system such that its performance (e.g., runtime and throughput) can be optimized under time-varying workloads. This unfortunately remains unaddressed in existing approaches as they either overlook the available past knowledge or rely on static exploitation of past knowledge without reasoning the usefulness of information when planning for self-adaptation. In this paper, we tackle this challenging problem by proposing DLiSA, a framework that self-adapts configurable systems. DLiSA comes with two properties: firstly, it supports lifelong planning, and thereby the planning process runs continuously throughout the lifetime of the system, allowing dynamic exploitation of the accumulated knowledge for rapid adaptation. Secondly, the planning for a newly emerged workload is boosted via distilled knowledge seeding, in which the knowledge is dynamically purified such that only useful past configurations are seeded when necessary, mitigating misleading information. Extensive experiments suggest that the proposed DLiSA significantly outperforms state-of-the-art approaches, demonstrating a performance improvement of up to 229% and a resource acceleration of up to 2.22x on generating promising adaptation configurations. All data and sources can be found at our repository: https://github.com/ideas-labo/dlisa.
GreenStableYolo: Optimizing Inference Time and Image Quality of Text-to-Image Generation
Jul 20, 2024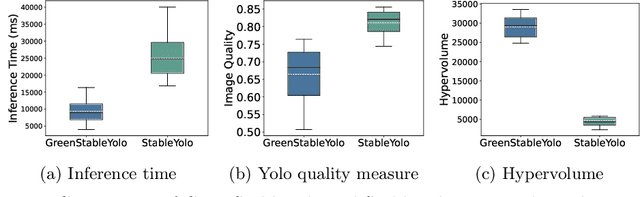
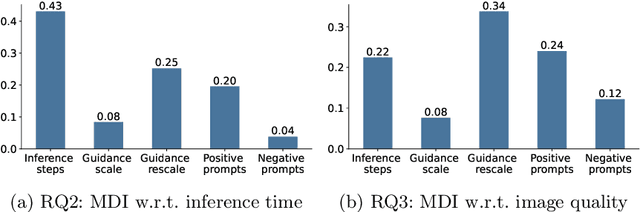
Tuning the parameters and prompts for improving AI-based text-to-image generation has remained a substantial yet unaddressed challenge. Hence we introduce GreenStableYolo, which improves the parameters and prompts for Stable Diffusion to both reduce GPU inference time and increase image generation quality using NSGA-II and Yolo. Our experiments show that despite a relatively slight trade-off (18%) in image quality compared to StableYolo (which only considers image quality), GreenStableYolo achieves a substantial reduction in inference time (266% less) and a 526% higher hypervolume, thereby advancing the state-of-the-art for text-to-image generation.