 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLARITY: A Framework and Benchmark for Conversational Language Ambiguity and Unanswerability in Interactive NL2SQL Systems
Apr 24, 2026NL2SQL systems deployed in industry settings often encounter ambiguous or unanswerable queries, particularly in interactive scenarios with incomplete user clarification. Existing benchmarks typically assume a single source of ambiguity and rely on user interaction for resolution, overlooking realistic failure modes. We introduce Clarity, a framework for automatically generating an NL2SQL benchmark with multi-faceted ambiguities and diverse user behaviors across both single- and multi-turn settings. Using a constraint-driven pipeline, Clarity transforms executable SQL into ambiguous queries, augmented with grounded conversational continuations and schema-level metadata. Empirical evaluation on Spider and BIRD shows that leading NL2SQL systems, including those based on strong LLMs, suffer significant performance degradation under multi-faceted ambiguity. While these systems often detect ambiguity, they struggle to accurately localize and resolve the underlying schema-level sources. Our results highlight the need for more robust ambiguity detection and resolution in industry-grade NL2SQL systems.
Proverbs Run in Pairs: Evaluating Proverb Translation Capability of Large Language Model
Jan 21, 2025Despite achieving remarkable performance, machine translation (MT) research remains underexplored in terms of translating cultural elements in languages, such as idioms, proverbs, and colloquial expressions. This paper investigates the capability of state-of-the-art neural machine translation (NMT) and large language models (LLMs) in translating proverbs, which are deeply rooted in cultural contexts. We construct a translation dataset of standalone proverbs and proverbs in conversation for four language pairs. Our experiments show that the studied models can achieve good translation between languages with similar cultural backgrounds, and LLMs generally outperform NMT models in proverb translation. Furthermore, we find that current automatic evaluation metrics such as BLEU, CHRF++ and COMET are inadequate for reliably assessing the quality of proverb translation, highlighting the need for more culturally aware evaluation metrics.
Decompose, Enrich, and Extract! Schema-aware Event Extraction using LLMs
Jun 03, 2024



Large Language Models (LLMs) demonstrate significant capabilities in processing natural language data, promising efficient knowledge extraction from diverse textual sources to enhance situational awareness and support decision-making. However, concerns arise due to their susceptibility to hallucination, resulting in contextually inaccurate content. This work focuses on harnessing LLMs for automated Event Extraction, introducing a new method to address hallucination by decomposing the task into Event Detection and Event Argument Extraction. Moreover, the proposed method integrates dynamic schema-aware augmented retrieval examples into prompts tailored for each specific inquiry, thereby extending and adapting advanced prompting techniques such as Retrieval-Augmented Generation. Evaluation findings on prominent event extraction benchmarks and results from a synthesized benchmark illustrate the method's superior performance compared to baseline approaches.
Modelling Political Coalition Negotiations Using LLM-based Agents
Feb 18, 2024



Coalition negotiations are a cornerstone of parliamentary democracies, characterised by complex interactions and strategic communications among political parties. Despite its significance, the modelling of these negotiations has remained unexplored with the domain of Natural Language Processing (NLP), mostly due to lack of proper data. In this paper, we introduce coalition negotiations as a novel NLP task, and model it as a negotiation between large language model-based agents. We introduce a multilingual dataset, POLCA, comprising manifestos of European political parties and coalition agreements over a number of elections in these countries. This dataset addresses the challenge of the current scope limitations in political negotiation modelling by providing a diverse, real-world basis for simulation. Additionally, we propose a hierarchical Markov decision process designed to simulate the process of coalition negotiation between political parties and predict the outcomes. We evaluate the performance of state-of-the-art large language models (LLMs) as agents in handling coalition negotiations, offering insights into their capabilities and paving the way for future advancements in political modelling.
NormMark: A Weakly Supervised Markov Model for Socio-cultural Norm Discovery
May 26, 2023



Norms, which are culturally accepted guidelines for behaviours, can be integrated into conversational models to generate utterances that are appropriate for the socio-cultural context. Existing methods for norm recognition tend to focus only on surface-level features of dialogues and do not take into account the interactions within a conversation. To address this issue, we propose NormMark, a probabilistic generative Markov model to carry the latent features throughout a dialogue. These features are captured by discrete and continuous latent variables conditioned on the conversation history, and improve the model's ability in norm recognition. The model is trainable on weakly annotated data using the variational technique. On a dataset with limited norm annotations, we show that our approach achieves higher F1 score, outperforming current state-of-the-art methods, including GPT3.
Few-shot Domain-Adaptive Visually-fused Event Detection from Text
May 04, 2023



Incorporating auxiliary modalities such as images into event detection models has attracted increasing interest over the last few years. The complexity of natural language in describing situations has motivated researchers to leverage the related visual context to improve event detection performance. However, current approaches in this area suffer from data scarcity, where a large amount of labelled text-image pairs are required for model training. Furthermore, limited access to the visual context at inference time negatively impacts the performance of such models, which makes them practically ineffective in real-world scenarios. In this paper, we present a novel domain-adaptive visually-fused event detection approach that can be trained on a few labelled image-text paired data points. Specifically, we introduce a visual imaginator method that synthesises images from text in the absence of visual context. Moreover, the imaginator can be customised to a specific domain. In doing so, our model can leverage the capabilities of pre-trained vision-language models and can be trained in a few-shot setting. This also allows for effective inference where only single-modality data (i.e. text) is available. The experimental evaluation on the benchmark M2E2 dataset shows that our model outperforms existing state-of-the-art models, by up to 11 points.
Neural-Symbolic Commonsense Reasoner with Relation Predictors
May 14, 2021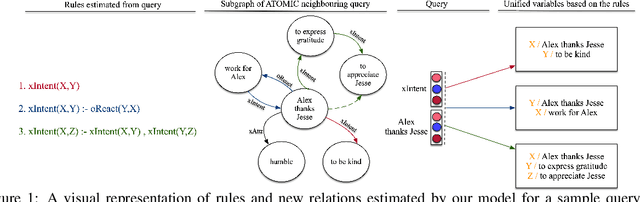

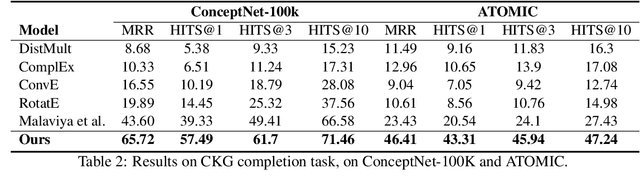

Commonsense reasoning aims to incorporate sets of commonsense facts, retrieved from Commonsense Knowledge Graphs (CKG), to draw conclusion about ordinary situations. The dynamic nature of commonsense knowledge postulates models capable of performing multi-hop reasoning over new situations. This feature also results in having large-scale sparse Knowledge Graphs, where such reasoning process is needed to predict relations between new events. However, existing approaches in this area are limited by considering CKGs as a limited set of facts, thus rendering them unfit for reasoning over new unseen situations and events. In this paper, we present a neural-symbolic reasoner, which is capable of reasoning over large-scale dynamic CKGs. The logic rules for reasoning over CKGs are learned during training by our model. In addition to providing interpretable explanation, the learned logic rules help to generalise prediction to newly introduced events. Experimental results on the task of link prediction on CKGs prove the effectiveness of our model by outperforming the state-of-the-art models.
Domain Adaptative Causality Encoder
Nov 27, 2020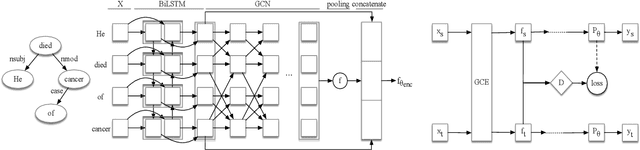
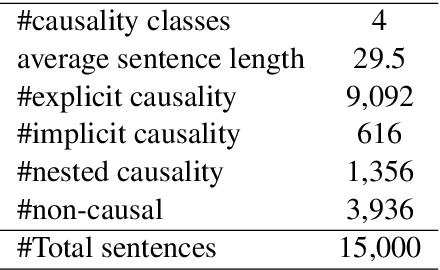
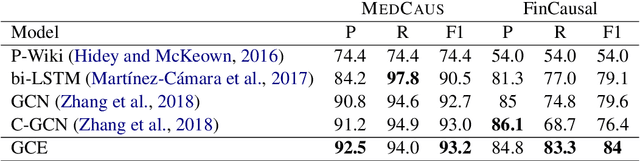

Current approaches which are mainly based on the extraction of low-level relations among individual events are limited by the shortage of publicly available labelled data. Therefore, the resulting models perform poorly when applied to a distributionally different domain for which labelled data did not exist at the time of training. To overcome this limitation, in this paper, we leverage the characteristics of dependency trees and adversarial learning to address the tasks of adaptive causality identification and localisation. The term adaptive is used since the training and test data come from two distributionally different datasets, which to the best of our knowledge, this work is the first to address. Moreover, we present a new causality dataset, namely MedCaus, which integrates all types of causality in the text. Our experiments on four different benchmark causality datasets demonstrate the superiority of our approach over the existing baselines, by up to 7% improvement, on the tasks of identification and localisation of the causal relations from the text.
Learning Causal Bayesian Networks from Text
Nov 26, 2020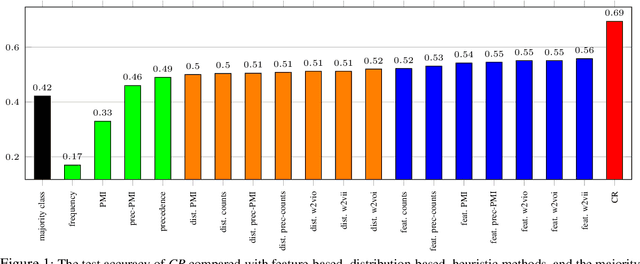
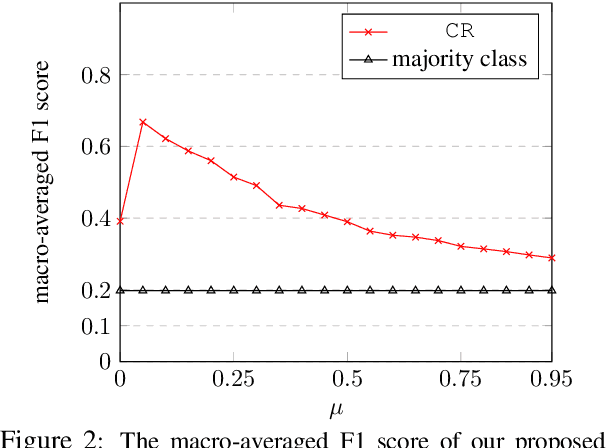
Causal relationships form the basis for reasoning and decision-making in Artificial Intelligence systems. To exploit the large volume of textual data available today, the automatic discovery of causal relationships from text has emerged as a significant challenge in recent years. Existing approaches in this realm are limited to the extraction of low-level relations among individual events. To overcome the limitations of the existing approaches, in this paper, we propose a method for automatic inference of causal relationships from human written language at conceptual level. To this end, we leverage the characteristics of hierarchy of concepts and linguistic variables created from text, and represent the extracted causal relationships in the form of a Causal Bayesian Network. Our experiments demonstrate superiority of our approach over the existing approaches in inferring complex causal reasoning from the text.
COSMO: Conditional SEQ2SEQ-based Mixture Model for Zero-Shot Commonsense Question Answering
Nov 02, 2020
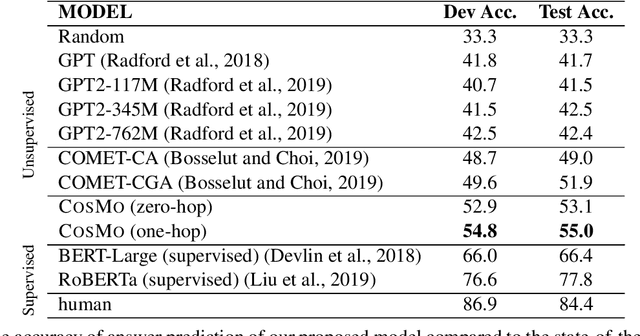
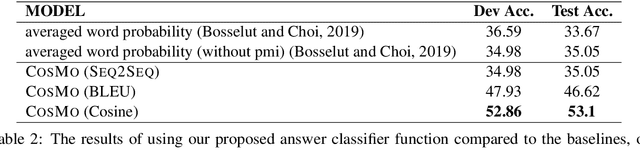
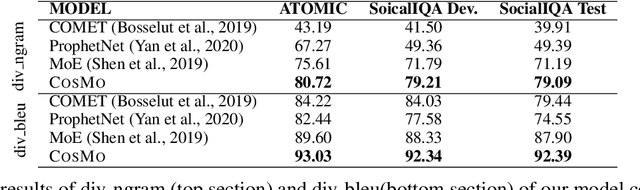
Commonsense reasoning refers to the ability of evaluating a social situation and acting accordingly. Identification of the implicit causes and effects of a social context is the driving capability which can enable machines to perform commonsense reasoning. The dynamic world of social interactions requires context-dependent on-demand systems to infer such underlying information. However, current approaches in this realm lack the ability to perform commonsense reasoning upon facing an unseen situation, mostly due to incapability of identifying a diverse range of implicit social relations. Hence they fail to estimate the correct reasoning path. In this paper, we present Conditional SEQ2SEQ-based Mixture model (COSMO), which provides us with the capabilities of dynamic and diverse content generation. We use COSMO to generate context-dependent clauses, which form a dynamic Knowledge Graph (KG) on-the-fly for commonsense reasoning. To show the adaptability of our model to context-dependant knowledge generation, we address the task of zero-shot commonsense question answering. The empirical results indicate an improvement of up to +5.2% over the state-of-the-art models.