 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo AI Overviews Benefit Search Engines? An Ecosystem Perspective
Jan 30, 2026The integration of AI Overviews into search engines enhances user experience but diverts traffic from content creators, potentially discouraging high-quality content creation and causing user attrition that undermines long-term search engine profit. To address this issue, we propose a game-theoretic model of creator competition with costly effort, characterize equilibrium behavior, and design two incentive mechanisms: a citation mechanism that references sources within an AI Overview, and a compensation mechanism that offers monetary rewards to creators. For both cases, we provide structural insights and near-optimal profit-maximizing mechanisms. Evaluations on real click data show that although AI Overviews harm long-term search engine profit, interventions based on our proposed mechanisms can increase long-term profit across a range of realistic scenarios, pointing toward a more sustainable trajectory for AI-enhanced search ecosystems.
Strategic Filtering for Content Moderation: Free Speech or Free of Distortion?
Jul 26, 2025User-generated content (UGC) on social media platforms is vulnerable to incitements and manipulations, necessitating effective regulations. To address these challenges, those platforms often deploy automated content moderators tasked with evaluating the harmfulness of UGC and filtering out content that violates established guidelines. However, such moderation inevitably gives rise to strategic responses from users, who strive to express themselves within the confines of guidelines. Such phenomena call for a careful balance between: 1. ensuring freedom of speech -- by minimizing the restriction of expression; and 2. reducing social distortion -- measured by the total amount of content manipulation. We tackle the problem of optimizing this balance through the lens of mechanism design, aiming at optimizing the trade-off between minimizing social distortion and maximizing free speech. Although determining the optimal trade-off is NP-hard, we propose practical methods to approximate the optimal solution. Additionally, we provide generalization guarantees determining the amount of finite offline data required to approximate the optimal moderator effectively.
Policy Design for Two-sided Platforms with Participation Dynamics
Feb 03, 2025



In two-sided platforms (e.g., video streaming or e-commerce), viewers and providers engage in interactive dynamics, where an increased provider population results in higher viewer utility and the increase of viewer population results in higher provider utility. Despite the importance of such "population effects" on long-term platform health, recommendation policies do not generally take the participation dynamics into account. This paper thus studies the dynamics and policy design on two-sided platforms under the population effects for the first time. Our control- and game-theoretic findings warn against the use of myopic-greedy policy and shed light on the importance of provider-side considerations (i.e., effectively distributing exposure among provider groups) to improve social welfare via population growth. We also present a simple algorithm to optimize long-term objectives by considering the population effects, and demonstrate its effectiveness in synthetic and real-data experiments.
Unveiling User Satisfaction and Creator Productivity Trade-Offs in Recommendation Platforms
Oct 31, 2024



On User-Generated Content (UGC) platforms, recommendation algorithms significantly impact creators' motivation to produce content as they compete for algorithmically allocated user traffic. This phenomenon subtly shapes the volume and diversity of the content pool, which is crucial for the platform's sustainability. In this work, we demonstrate, both theoretically and empirically, that a purely relevance-driven policy with low exploration strength boosts short-term user satisfaction but undermines the long-term richness of the content pool. In contrast, a more aggressive exploration policy may slightly compromise user satisfaction but promote higher content creation volume. Our findings reveal a fundamental trade-off between immediate user satisfaction and overall content production on UGC platforms. Building on this finding, we propose an efficient optimization method to identify the optimal exploration strength, balancing user and creator engagement. Our model can serve as a pre-deployment audit tool for recommendation algorithms on UGC platforms, helping to align their immediate objectives with sustainable, long-term goals.
Learning from Imperfect Human Feedback: a Tale from Corruption-Robust Dueling
May 18, 2024



This paper studies Learning from Imperfect Human Feedback (LIHF), motivated by humans' potential irrationality or imperfect perception of true preference. We revisit the classic dueling bandit problem as a model of learning from comparative human feedback, and enrich it by casting the imperfection in human feedback as agnostic corruption to user utilities. We start by identifying the fundamental limits of LIHF and prove a regret lower bound of $\Omega(\max\{T^{1/2},C\})$, even when the total corruption $C$ is known and when the corruption decays gracefully over time (i.e., user feedback becomes increasingly more accurate). We then turn to design robust algorithms applicable in real-world scenarios with arbitrary corruption and unknown $C$. Our key finding is that gradient-based algorithms enjoy a smooth efficiency-robustness tradeoff under corruption by varying their learning rates. Specifically, under general concave user utility, Dueling Bandit Gradient Descent (DBGD) of Yue and Joachims (2009) can be tuned to achieve regret $O(T^{1-\alpha} + T^{ \alpha} C)$ for any given parameter $\alpha \in (0, \frac{1}{4}]$. Additionally, this result enables us to pin down the regret lower bound of the standard DBGD (the $\alpha=1/4$ case) as $\Omega(T^{3/4})$ for the first time, to the best of our knowledge. For strongly concave user utility we show a better tradeoff: there is an algorithm that achieves $O(T^{\alpha} + T^{\frac{1}{2}(1-\alpha)}C)$ for any given $\alpha \in [\frac{1}{2},1)$. Our theoretical insights are corroborated by extensive experiments on real-world recommendation data.
User Welfare Optimization in Recommender Systems with Competing Content Creators
Apr 28, 2024



Driven by the new economic opportunities created by the creator economy, an increasing number of content creators rely on and compete for revenue generated from online content recommendation platforms. This burgeoning competition reshapes the dynamics of content distribution and profoundly impacts long-term user welfare on the platform. However, the absence of a comprehensive picture of global user preference distribution often traps the competition, especially the creators, in states that yield sub-optimal user welfare. To encourage creators to best serve a broad user population with relevant content, it becomes the platform's responsibility to leverage its information advantage regarding user preference distribution to accurately signal creators. In this study, we perform system-side user welfare optimization under a competitive game setting among content creators. We propose an algorithmic solution for the platform, which dynamically computes a sequence of weights for each user based on their satisfaction of the recommended content. These weights are then utilized to design mechanisms that adjust the recommendation policy or the post-recommendation rewards, thereby influencing creators' content production strategies. To validate the effectiveness of our proposed method, we report our findings from a series of experiments, including: 1. a proof-of-concept negative example illustrating how creators' strategies converge towards sub-optimal states without platform intervention; 2. offline experiments employing our proposed intervention mechanisms on diverse datasets; and 3. results from a three-week online experiment conducted on a leading short-video recommendation platform.
Preference Elicitation with Soft Attributes in Interactive Recommendation
Oct 22, 2023



Preference elicitation plays a central role in interactive recommender systems. Most preference elicitation approaches use either item queries that ask users to select preferred items from a slate, or attribute queries that ask them to express their preferences for item characteristics. Unfortunately, users often wish to describe their preferences using soft attributes for which no ground-truth semantics is given. Leveraging concept activation vectors for soft attribute semantics, we develop novel preference elicitation methods that can accommodate soft attributes and bring together both item and attribute-based preference elicitation. Our techniques query users using both items and soft attributes to update the recommender system's belief about their preferences to improve recommendation quality. We demonstrate the effectiveness of our methods vis-a-vis competing approaches on both synthetic and real-world datasets.
How Bad is Top-$K$ Recommendation under Competing Content Creators?
Feb 03, 2023



Content creators compete for exposure on recommendation platforms, and such strategic behavior leads to a dynamic shift over the content distribution. However, how the creators' competition impacts user welfare and how the relevance-driven recommendation influences the dynamics in the long run are still largely unknown. This work provides theoretical insights into these research questions. We model the creators' competition under the assumptions that: 1) the platform employs an innocuous top-$K$ recommendation policy; 2) user decisions follow the Random Utility model; 3) content creators compete for user engagement and, without knowing their utility function in hindsight, apply arbitrary no-regret learning algorithms to update their strategies. We study the user welfare guarantee through the lens of Price of Anarchy and show that the fraction of user welfare loss due to creator competition is always upper bounded by a small constant depending on $K$ and randomness in user decisions; we also prove the tightness of this bound. Our result discloses an intrinsic merit of the myopic approach to the recommendation, i.e., relevance-driven matching performs reasonably well in the long run, as long as users' decisions involve randomness and the platform provides reasonably many alternatives to its users.
Learning from a Learning User for Optimal Recommendations
Feb 03, 2022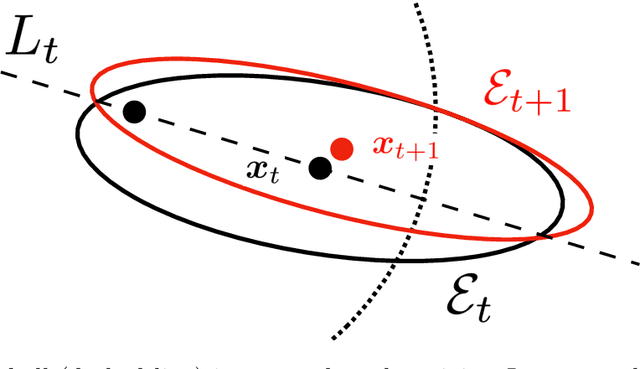
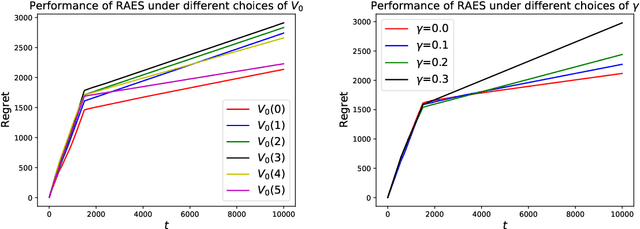
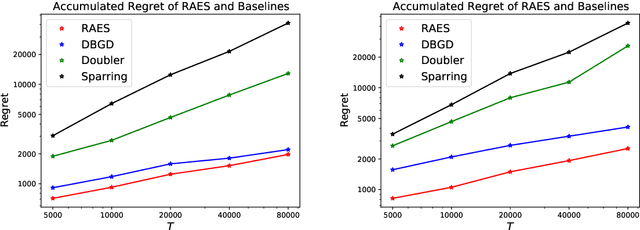
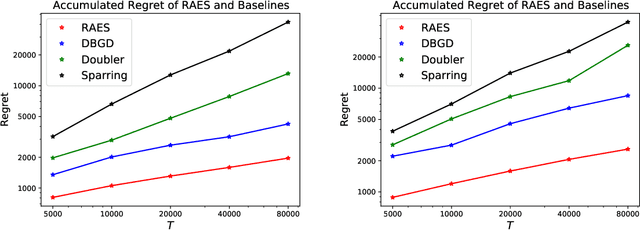
In real-world recommendation problems, especially those with a formidably large item space, users have to gradually learn to estimate the utility of any fresh recommendations from their experience about previously consumed items. This in turn affects their interaction dynamics with the system and can invalidate previous algorithms built on the omniscient user assumption. In this paper, we formalize a model to capture such "learning users" and design an efficient system-side learning solution, coined Noise-Robust Active Ellipsoid Search (RAES), to confront the challenges brought by the non-stationary feedback from such a learning user. Interestingly, we prove that the regret of RAES deteriorates gracefully as the convergence rate of user learning becomes worse, until reaching linear regret when the user's learning fails to converge. Experiments on synthetic datasets demonstrate the strength of RAES for such a contemporaneous system-user learning problem. Our study provides a novel perspective on modeling the feedback loop in recommendation problems.
Multi-Agent Learning for Iterative Dominance Elimination: Formal Barriers and New Algorithms
Nov 10, 2021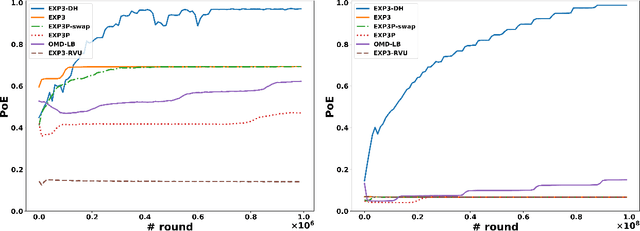
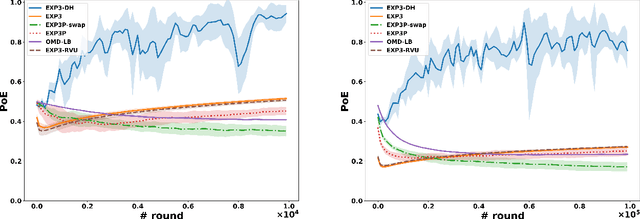
Dominated actions are natural (and perhaps the simplest possible) multi-agent generalizations of sub-optimal actions as in standard single-agent decision making. Thus similar to standard bandit learning, a basic learning question in multi-agent systems is whether agents can learn to efficiently eliminate all dominated actions in an unknown game if they can only observe noisy bandit feedback about the payoff of their played actions. Surprisingly, despite a seemingly simple task, we show a quite negative result; that is, standard no regret algorithms -- including the entire family of Dual Averaging algorithms -- provably take exponentially many rounds to eliminate all dominated actions. Moreover, algorithms with the stronger no swap regret also suffer similar exponential inefficiency. To overcome these barriers, we develop a new algorithm that adjusts Exp3 with Diminishing Historical rewards (termed Exp3-DH); Exp3-DH gradually forgets history at carefully tailored rates. We prove that when all agents run Exp3-DH (a.k.a., self-play in multi-agent learning), all dominated actions can be iteratively eliminated within polynomially many rounds. Our experimental results further demonstrate the efficiency of Exp3-DH, and that state-of-the-art bandit algorithms, even those developed specifically for learning in games, fail to eliminate all dominated actions efficiently.