 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAbout latent roles in forecasting players in team sports
Apr 23, 2023Forecasting players in sports has grown in popularity due to the potential for a tactical advantage and the applicability of such research to multi-agent interaction systems. Team sports contain a significant social component that influences interactions between teammates and opponents. However, it still needs to be fully exploited. In this work, we hypothesize that each participant has a specific function in each action and that role-based interaction is critical for predicting players' future moves. We create RolFor, a novel end-to-end model for Role-based Forecasting. RolFor uses a new module we developed called Ordering Neural Networks (OrderNN) to permute the order of the players such that each player is assigned to a latent role. The latent role is then modeled with a RoleGCN. Thanks to its graph representation, it provides a fully learnable adjacency matrix that captures the relationships between roles and is subsequently used to forecast the players' future trajectories. Extensive experiments on a challenging NBA basketball dataset back up the importance of roles and justify our goal of modeling them using optimizable models. When an oracle provides roles, the proposed RolFor compares favorably to the current state-of-the-art (it ranks first in terms of ADE and second in terms of FDE errors). However, training the end-to-end RolFor incurs the issues of differentiability of permutation methods, which we experimentally review. Finally, this work restates differentiable ranking as a difficult open problem and its great potential in conjunction with graph-based interaction models. Project is available at: https://www.pinlab.org/aboutlatentroles
Best Practices for 2-Body Pose Forecasting
Apr 12, 2023The task of collaborative human pose forecasting stands for predicting the future poses of multiple interacting people, given those in previous frames. Predicting two people in interaction, instead of each separately, promises better performance, due to their body-body motion correlations. But the task has remained so far primarily unexplored. In this paper, we review the progress in human pose forecasting and provide an in-depth assessment of the single-person practices that perform best for 2-body collaborative motion forecasting. Our study confirms the positive impact of frequency input representations, space-time separable and fully-learnable interaction adjacencies for the encoding GCN and FC decoding. Other single-person practices do not transfer to 2-body, so the proposed best ones do not include hierarchical body modeling or attention-based interaction encoding. We further contribute a novel initialization procedure for the 2-body spatial interaction parameters of the encoder, which benefits performance and stability. Altogether, our proposed 2-body pose forecasting best practices yield a performance improvement of 21.9% over the state-of-the-art on the most recent ExPI dataset, whereby the novel initialization accounts for 3.5%. See our project page at https://www.pinlab.org/bestpractices2body
HYperbolic Self-Paced Learning for Self-Supervised Skeleton-based Action Representations
Mar 10, 2023Self-paced learning has been beneficial for tasks where some initial knowledge is available, such as weakly supervised learning and domain adaptation, to select and order the training sample sequence, from easy to complex. However its applicability remains unexplored in unsupervised learning, whereby the knowledge of the task matures during training. We propose a novel HYperbolic Self-Paced model (HYSP) for learning skeleton-based action representations. HYSP adopts self-supervision: it uses data augmentations to generate two views of the same sample, and it learns by matching one (named online) to the other (the target). We propose to use hyperbolic uncertainty to determine the algorithmic learning pace, under the assumption that less uncertain samples should be more strongly driving the training, with a larger weight and pace. Hyperbolic uncertainty is a by-product of the adopted hyperbolic neural networks, it matures during training and it comes with no extra cost, compared to the established Euclidean SSL framework counterparts. When tested on three established skeleton-based action recognition datasets, HYSP outperforms the state-of-the-art on PKU-MMD I, as well as on 2 out of 3 downstream tasks on NTU-60 and NTU-120. Additionally, HYSP only uses positive pairs and bypasses therefore the complex and computationally-demanding mining procedures required for the negatives in contrastive techniques. Code is available at https://github.com/paolomandica/HYSP.
Contracting Skeletal Kinematic Embeddings for Anomaly Detection
Jan 23, 2023



Detecting the anomaly of human behavior is paramount to timely recognizing endangering situations, such as street fights or elderly falls. However, anomaly detection is complex, since anomalous events are rare and because it is an open set recognition task, i.e., what is anomalous at inference has not been observed at training. We propose COSKAD, a novel model which encodes skeletal human motion by an efficient graph convolutional network and learns to COntract SKeletal kinematic embeddings onto a latent hypersphere of minimum volume for Anomaly Detection. We propose and analyze three latent space designs for COSKAD: the commonly-adopted Euclidean, and the new spherical-radial and hyperbolic volumes. All three variants outperform the state-of-the-art, including video-based techniques, on the ShangaiTechCampus, the Avenue, and on the most recent UBnormal dataset, for which we contribute novel skeleton annotations and the selection of human-related videos. The source code and dataset will be released upon acceptance.
Are we certain it's anomalous?
Nov 16, 2022



The progress in modelling time series and, more generally, sequences of structured-data has recently revamped research in anomaly detection. The task stands for identifying abnormal behaviours in financial series, IT systems, aerospace measurements, and the medical domain, where anomaly detection may aid in isolating cases of depression and attend the elderly. Anomaly detection in time series is a complex task since anomalies are rare due to highly non-linear temporal correlations and since the definition of anomalous is sometimes subjective. Here we propose the novel use of Hyperbolic uncertainty for Anomaly Detection (HypAD). HypAD learns self-supervisedly to reconstruct the input signal. We adopt best practices from the state-of-the-art to encode the sequence by an LSTM, jointly learnt with a decoder to reconstruct the signal, with the aid of GAN critics. Uncertainty is estimated end-to-end by means of a hyperbolic neural network. By using uncertainty, HypAD may assess whether it is certain about the input signal but it fails to reconstruct it because this is anomalous; or whether the reconstruction error does not necessarily imply anomaly, as the model is uncertain, e.g. a complex but regular input signal. The novel key idea is that a detectable anomaly is one where the model is certain but it predicts wrongly. HypAD outperforms the current state-of-the-art for univariate anomaly detection on established benchmarks based on data from NASA, Yahoo, Numenta, Amazon, Twitter. It also yields state-of-the-art performance on a multivariate dataset of anomaly activities in elderly home residences, and it outperforms the baseline on SWaT. Overall, HypAD yields the lowest false alarms at the best performance rate, thanks to successfully identifying detectable anomalies.
Query-Guided Networks for Few-shot Fine-grained Classification and Person Search
Sep 21, 2022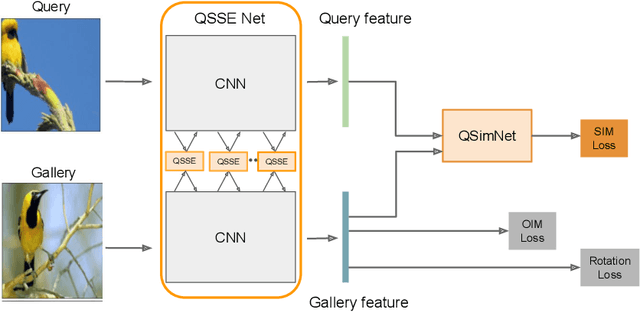
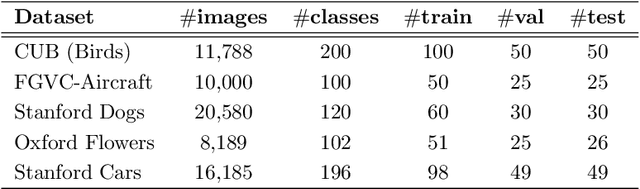
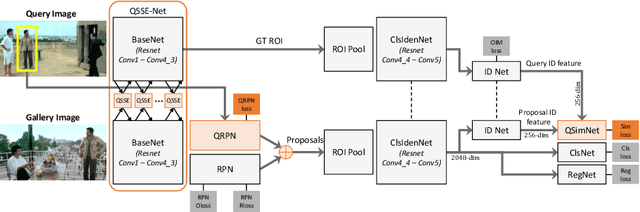
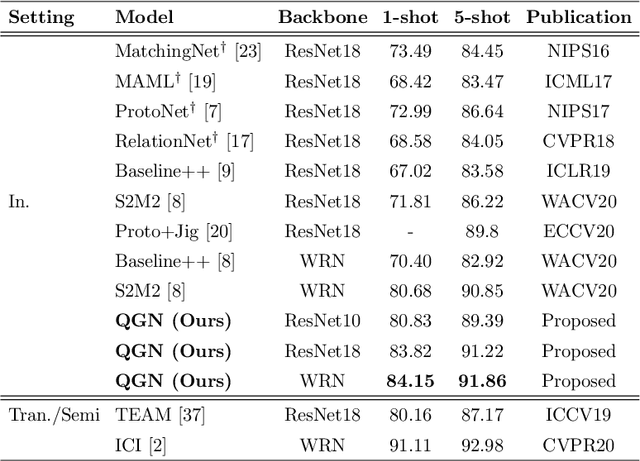
Few-shot fine-grained classification and person search appear as distinct tasks and literature has treated them separately. But a closer look unveils important similarities: both tasks target categories that can only be discriminated by specific object details; and the relevant models should generalize to new categories, not seen during training. We propose a novel unified Query-Guided Network (QGN) applicable to both tasks. QGN consists of a Query-guided Siamese-Squeeze-and-Excitation subnetwork which re-weights both the query and gallery features across all network layers, a Query-guided Region Proposal subnetwork for query-specific localisation, and a Query-guided Similarity subnetwork for metric learning. QGN improves on a few recent few-shot fine-grained datasets, outperforming other techniques on CUB by a large margin. QGN also performs competitively on the person search CUHK-SYSU and PRW datasets, where we perform in-depth analysis.
CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
Jul 20, 20223D LiDAR semantic segmentation is fundamental for autonomous driving. Several Unsupervised Domain Adaptation (UDA) methods for point cloud data have been recently proposed to improve model generalization for different sensors and environments. Researchers working on UDA problems in the image domain have shown that sample mixing can mitigate domain shift. We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing. CoSMix consists of a two-branch symmetric network that can process labelled synthetic data (source) and real-world unlabelled point clouds (target) concurrently. Each branch operates on one domain by mixing selected pieces of data from the other one, and by using the semantic information derived from source labels and target pseudo-labels. We evaluate CoSMix on two large-scale datasets, showing that it outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/saltoricristiano/cosmix-uda.
GIPSO: Geometrically Informed Propagation for Online Adaptation in 3D LiDAR Segmentation
Jul 20, 2022
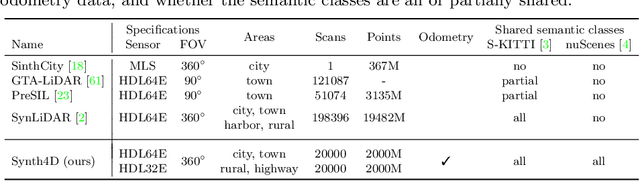
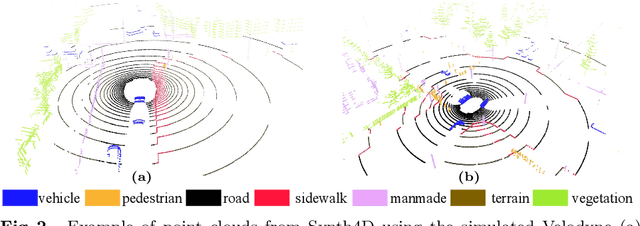
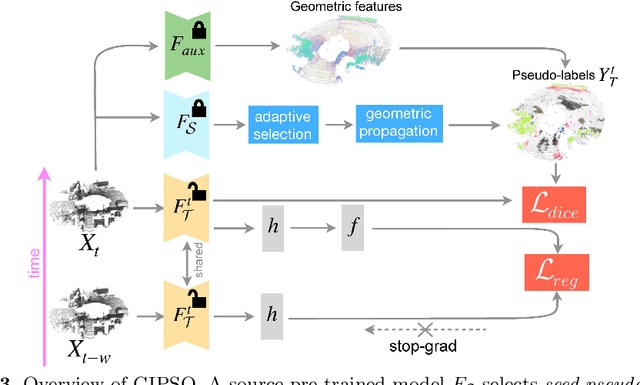
3D point cloud semantic segmentation is fundamental for autonomous driving. Most approaches in the literature neglect an important aspect, i.e., how to deal with domain shift when handling dynamic scenes. This can significantly hinder the navigation capabilities of self-driving vehicles. This paper advances the state of the art in this research field. Our first contribution consists in analysing a new unexplored scenario in point cloud segmentation, namely Source-Free Online Unsupervised Domain Adaptation (SF-OUDA). We experimentally show that state-of-the-art methods have a rather limited ability to adapt pre-trained deep network models to unseen domains in an online manner. Our second contribution is an approach that relies on adaptive self-training and geometric-feature propagation to adapt a pre-trained source model online without requiring either source data or target labels. Our third contribution is to study SF-OUDA in a challenging setup where source data is synthetic and target data is point clouds captured in the real world. We use the recent SynLiDAR dataset as a synthetic source and introduce two new synthetic (source) datasets, which can stimulate future synthetic-to-real autonomous driving research. Our experiments show the effectiveness of our segmentation approach on thousands of real-world point clouds. Code and synthetic datasets are available at https://github.com/saltoricristiano/gipso-sfouda.
Deep learning for laboratory earthquake prediction and autoregressive forecasting of fault zone stress
Mar 24, 2022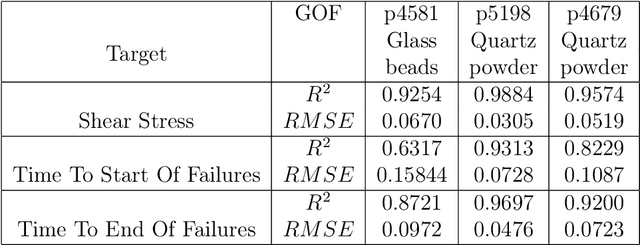
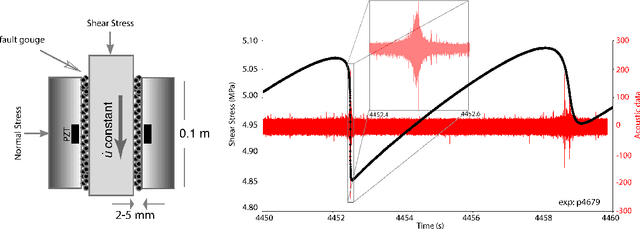
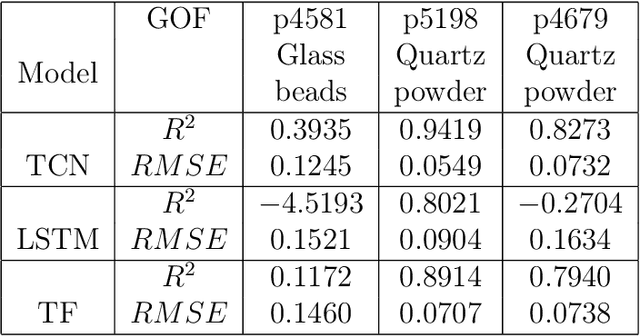
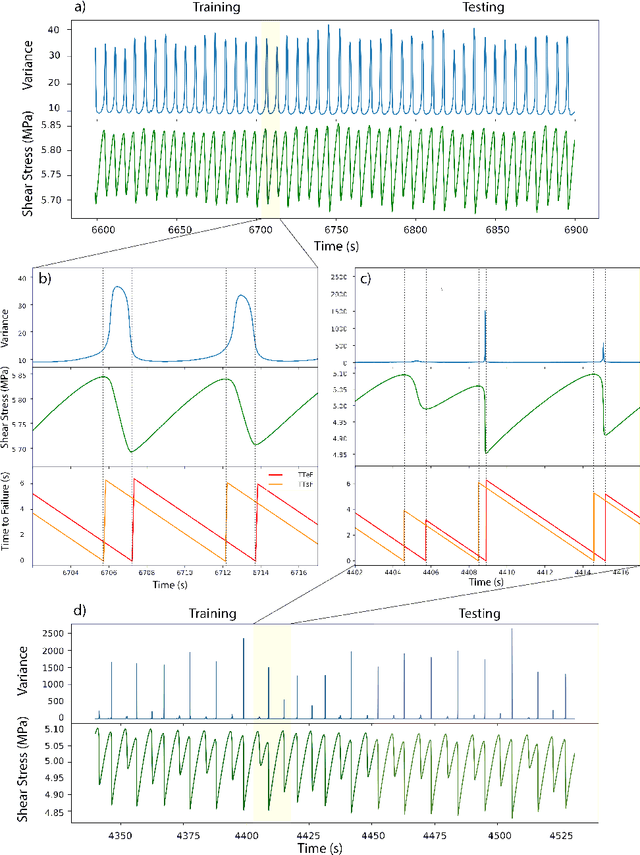
Earthquake forecasting and prediction have long and in some cases sordid histories but recent work has rekindled interest based on advances in early warning, hazard assessment for induced seismicity and successful prediction of laboratory earthquakes. In the lab, frictional stick-slip events provide an analog for earthquakes and the seismic cycle. Labquakes are ideal targets for machine learning (ML) because they can be produced in long sequences under controlled conditions. Recent works show that ML can predict several aspects of labquakes using fault zone acoustic emissions. Here, we generalize these results and explore deep learning (DL) methods for labquake prediction and autoregressive (AR) forecasting. DL improves existing ML methods of labquake prediction. AR methods allow forecasting at future horizons via iterative predictions. We demonstrate that DL models based on Long-Short Term Memory (LSTM) and Convolution Neural Networks predict labquakes under several conditions, and that fault zone stress can be predicted with fidelity, confirming that acoustic energy is a fingerprint of fault zone stress. We predict also time to start of failure (TTsF) and time to the end of Failure (TTeF) for labquakes. Interestingly, TTeF is successfully predicted in all seismic cycles, while the TTsF prediction varies with the amount of preseismic fault creep. We report AR methods to forecast the evolution of fault stress using three sequence modeling frameworks: LSTM, Temporal Convolution Network and Transformer Network. AR forecasting is distinct from existing predictive models, which predict only a target variable at a specific time. The results for forecasting beyond a single seismic cycle are limited but encouraging. Our ML/DL models outperform the state-of-the-art and our autoregressive model represents a novel framework that could enhance current methods of earthquake forecasting.
Under the Hood of Transformer Networks for Trajectory Forecasting
Mar 22, 2022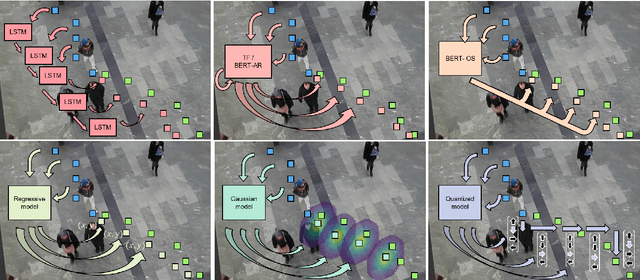
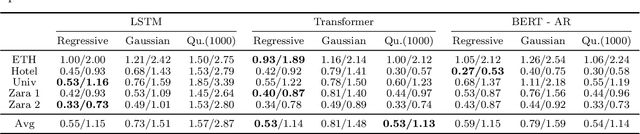
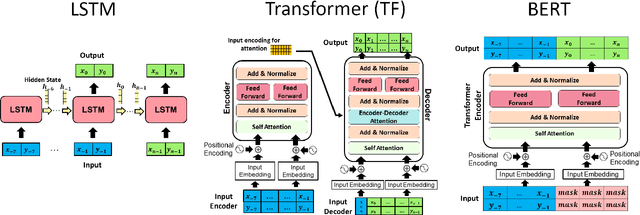
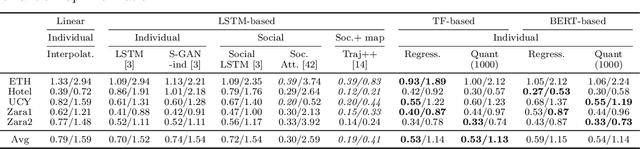
Transformer Networks have established themselves as the de-facto state-of-the-art for trajectory forecasting but there is currently no systematic study on their capability to model the motion patterns of people, without interactions with other individuals nor the social context. This paper proposes the first in-depth study of Transformer Networks (TF) and Bidirectional Transformers (BERT) for the forecasting of the individual motion of people, without bells and whistles. We conduct an exhaustive evaluation of input/output representations, problem formulations and sequence modeling, including a novel analysis of their capability to predict multi-modal futures. Out of comparative evaluation on the ETH+UCY benchmark, both TF and BERT are top performers in predicting individual motions, definitely overcoming RNNs and LSTMs. Furthermore, they remain within a narrow margin wrt more complex techniques, which include both social interactions and scene contexts. Source code will be released for all conducted experiments.