 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Personalizing Vision-Language Models to Find Named Instances in Video
Jun 16, 2023Large-scale vision-language models (VLM) have shown impressive results for language-guided search applications. While these models allow category-level queries, they currently struggle with personalized searches for moments in a video where a specific object instance such as ``My dog Biscuit'' appears. We present the following three contributions to address this problem. First, we describe a method to meta-personalize a pre-trained VLM, i.e., learning how to learn to personalize a VLM at test time to search in video. Our method extends the VLM's token vocabulary by learning novel word embeddings specific to each instance. To capture only instance-specific features, we represent each instance embedding as a combination of shared and learned global category features. Second, we propose to learn such personalization without explicit human supervision. Our approach automatically identifies moments of named visual instances in video using transcripts and vision-language similarity in the VLM's embedding space. Finally, we introduce This-Is-My, a personal video instance retrieval benchmark. We evaluate our approach on This-Is-My and DeepFashion2 and show that we obtain a 15% relative improvement over the state of the art on the latter dataset.
Localizing Moments in Long Video Via Multimodal Guidance
Feb 26, 2023



The recent introduction of the large-scale long-form MAD dataset for language grounding in videos has enabled researchers to investigate the performance of current state-of-the-art methods in the long-form setup, with unexpected findings. In fact, current grounding methods alone fail at tackling this challenging task and setup due to their inability to process long video sequences. In this work, we propose an effective way to circumvent the long-form burden by introducing a new component to grounding pipelines: a Guidance model. The purpose of the Guidance model is to efficiently remove irrelevant video segments from the search space of grounding methods by coarsely aligning the sentence to chunks of the movies and then applying legacy grounding methods where high correlation is found. We term these video segments as non-describable moments. This two-stage approach reveals to be effective in boosting the performance of several different grounding baselines on the challenging MAD dataset, achieving new state-of-the-art performance.
PIVOT: Prompting for Video Continual Learning
Dec 09, 2022



Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.
Videogenic: Video Highlights via Photogenic Moments
Nov 22, 2022This paper investigates the challenge of extracting highlight moments from videos. To perform this task, a system needs to understand what constitutes a highlight for arbitrary video domains while at the same time being able to scale across different domains. Our key insight is that photographs taken by photographers tend to capture the most remarkable or photogenic moments of an activity. Drawing on this insight, we present Videogenic, a system capable of creating domain-specific highlight videos for a wide range of domains. In a human evaluation study (N=50), we show that a high-quality photograph collection combined with CLIP-based retrieval (which uses a neural network with semantic knowledge of images) can serve as an excellent prior for finding video highlights. In a within-subjects expert study (N=12), we demonstrate the usefulness of Videogenic in helping video editors create highlight videos with lighter workload, shorter task completion time, and better usability.
VideoMap: Video Editing in Latent Space
Nov 22, 2022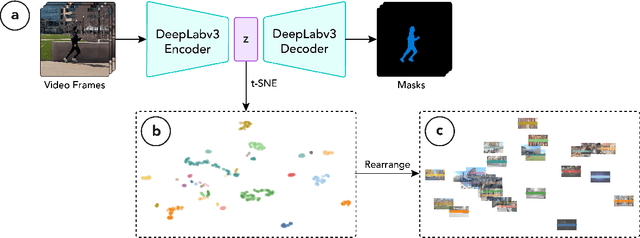
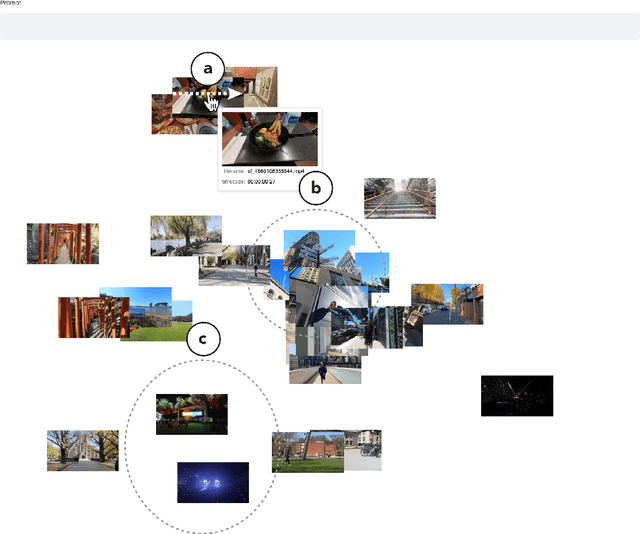
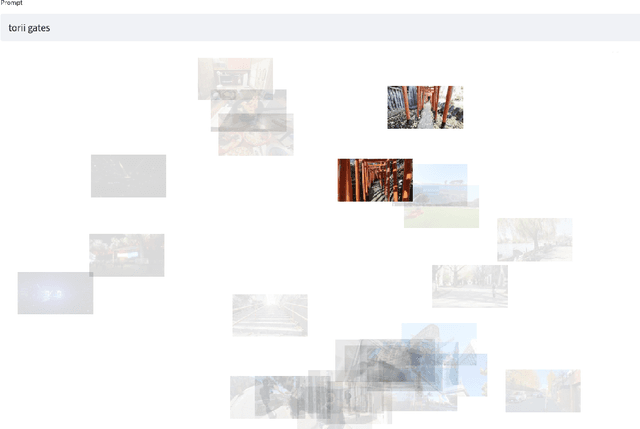
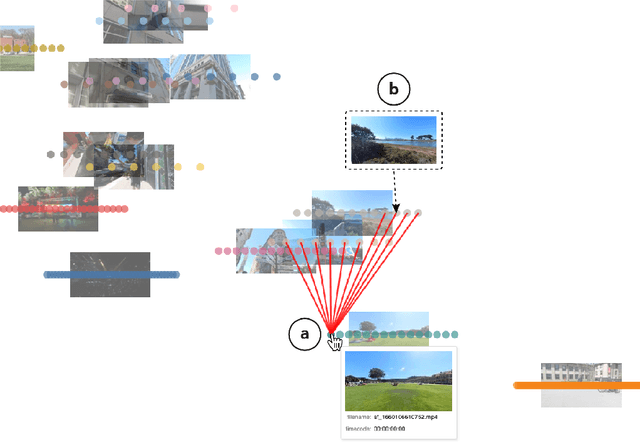
Video has become a dominant form of media. However, video editing interfaces have remained largely unchanged over the past two decades. Such interfaces typically consist of a grid-like asset management panel and a linear editing timeline. When working with a large number of video clips, it can be difficult to sort through them all and identify patterns within (e.g. opportunities for smooth transitions and storytelling). In this work, we imagine a new paradigm for video editing by mapping videos into a 2D latent space and building a proof-of-concept interface.
The Anatomy of Video Editing: A Dataset and Benchmark Suite for AI-Assisted Video Editing
Jul 21, 2022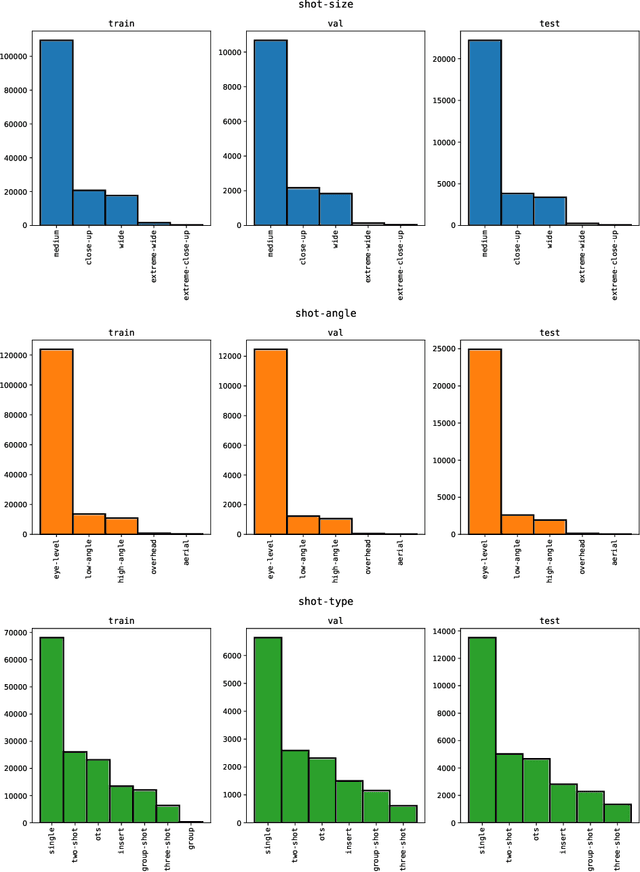
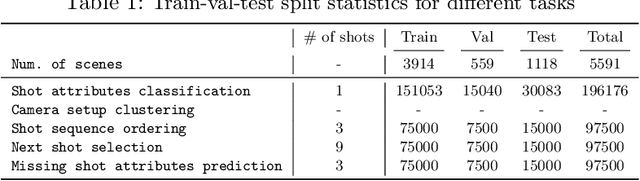
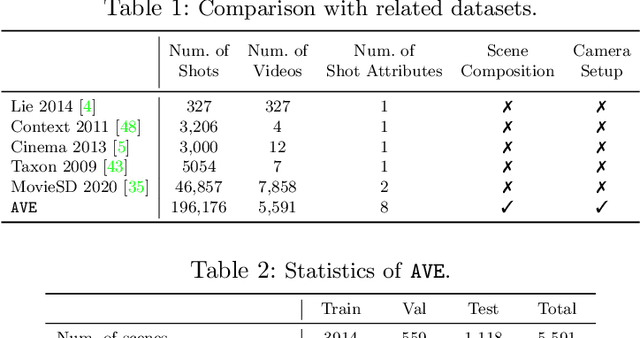
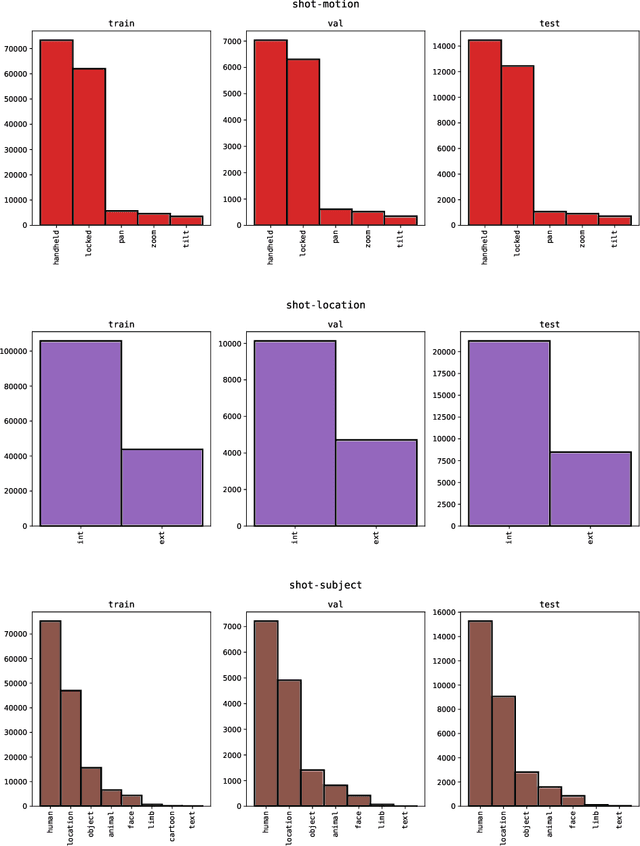
Machine learning is transforming the video editing industry. Recent advances in computer vision have leveled-up video editing tasks such as intelligent reframing, rotoscoping, color grading, or applying digital makeups. However, most of the solutions have focused on video manipulation and VFX. This work introduces the Anatomy of Video Editing, a dataset, and benchmark, to foster research in AI-assisted video editing. Our benchmark suite focuses on video editing tasks, beyond visual effects, such as automatic footage organization and assisted video assembling. To enable research on these fronts, we annotate more than 1.5M tags, with relevant concepts to cinematography, from 196176 shots sampled from movie scenes. We establish competitive baseline methods and detailed analyses for each of the tasks. We hope our work sparks innovative research towards underexplored areas of AI-assisted video editing.
Video-ReTime: Learning Temporally Varying Speediness for Time Remapping
May 11, 2022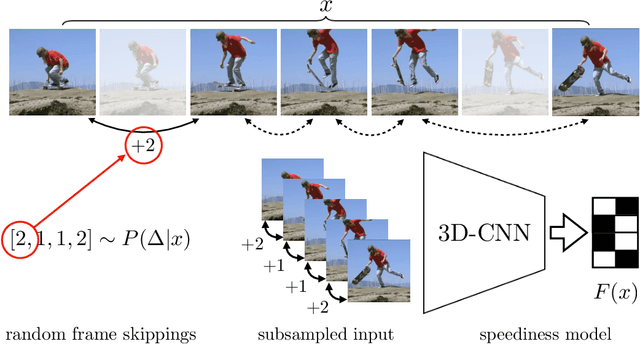
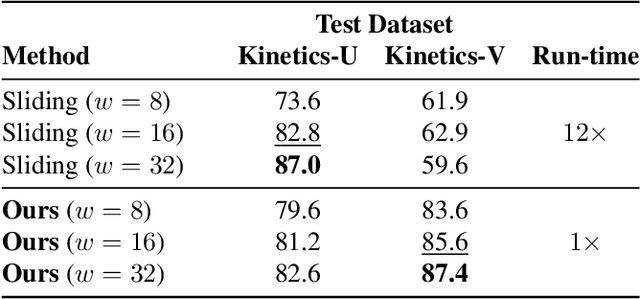
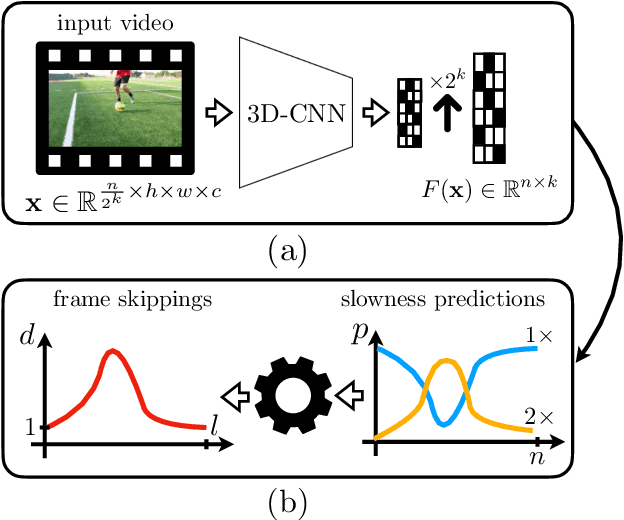
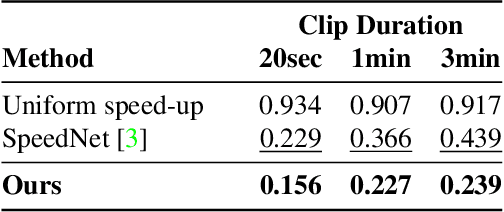
We propose a method for generating a temporally remapped video that matches the desired target duration while maximally preserving natural video dynamics. Our approach trains a neural network through self-supervision to recognize and accurately localize temporally varying changes in the video playback speed. To re-time videos, we 1. use the model to infer the slowness of individual video frames, and 2. optimize the temporal frame sub-sampling to be consistent with the model's slowness predictions. We demonstrate that this model can detect playback speed variations more accurately while also being orders of magnitude more efficient than prior approaches. Furthermore, we propose an optimization for video re-timing that enables precise control over the target duration and performs more robustly on longer videos than prior methods. We evaluate the model quantitatively on artificially speed-up videos, through transfer to action recognition, and qualitatively through user studies.
FitCLIP: Refining Large-Scale Pretrained Image-Text Models for Zero-Shot Video Understanding Tasks
Mar 24, 2022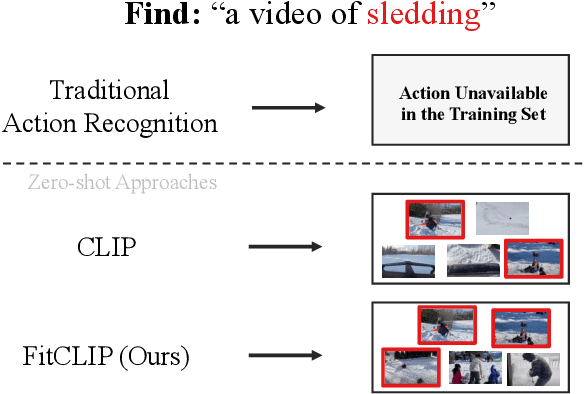
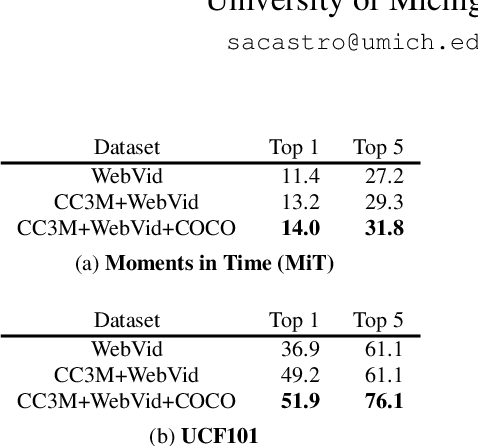
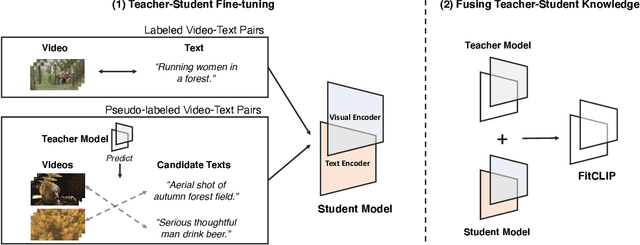
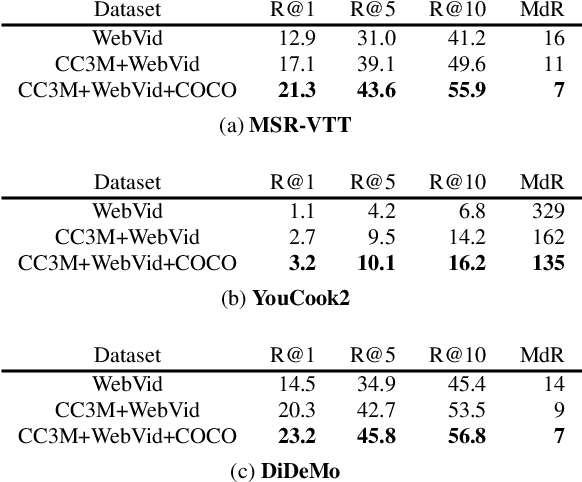
Large-scale pretrained image-text models have shown incredible zero-shot performance in a handful of tasks, including video ones such as action recognition and text-to-video retrieval. However, these models haven't been adapted to video, mainly because they don't account for the time dimension but also because video frames are different from the typical images (e.g., containing motion blur, less sharpness). In this paper, we present a fine-tuning strategy to refine these large-scale pretrained image-text models for zero-shot video understanding tasks. We show that by carefully adapting these models we obtain considerable improvements on two zero-shot Action Recognition tasks and three zero-shot Text-to-video Retrieval tasks. The code is available at https://github.com/bryant1410/fitclip
OWL (Observe, Watch, Listen): Localizing Actions in Egocentric Video via Audiovisual Temporal Context
Feb 14, 2022
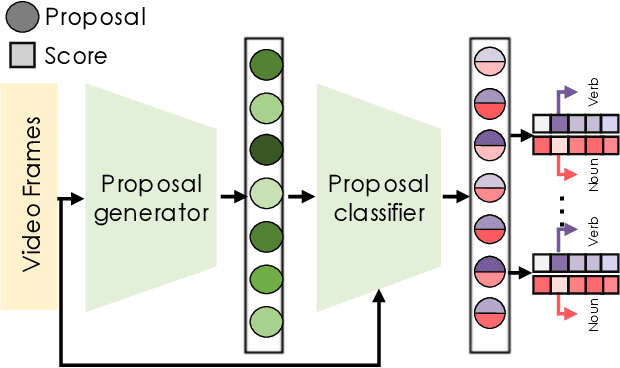

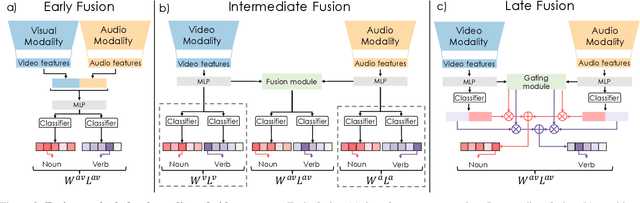
Temporal action localization (TAL) is an important task extensively explored and improved for third-person videos in recent years. Recent efforts have been made to perform fine-grained temporal localization on first-person videos. However, current TAL methods only use visual signals, neglecting the audio modality that exists in most videos and that shows meaningful action information in egocentric videos. In this work, we take a deep look into the effectiveness of audio in detecting actions in egocentric videos and introduce a simple-yet-effective approach via Observing, Watching, and Listening (OWL) to leverage audio-visual information and context for egocentric TAL. For doing that, we: 1) compare and study different strategies for where and how to fuse the two modalities; 2) propose a transformer-based model to incorporate temporal audio-visual context. Our experiments show that our approach achieves state-of-the-art performance on EPIC-KITCHENS-100.
vCLIMB: A Novel Video Class Incremental Learning Benchmark
Jan 23, 2022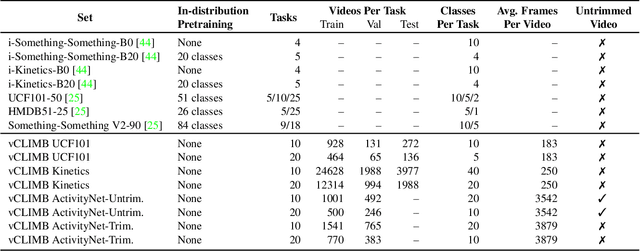
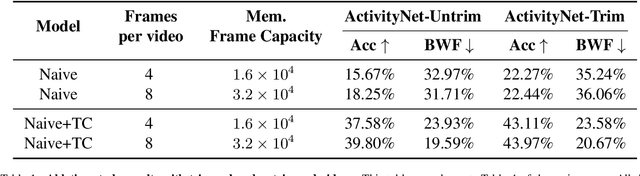
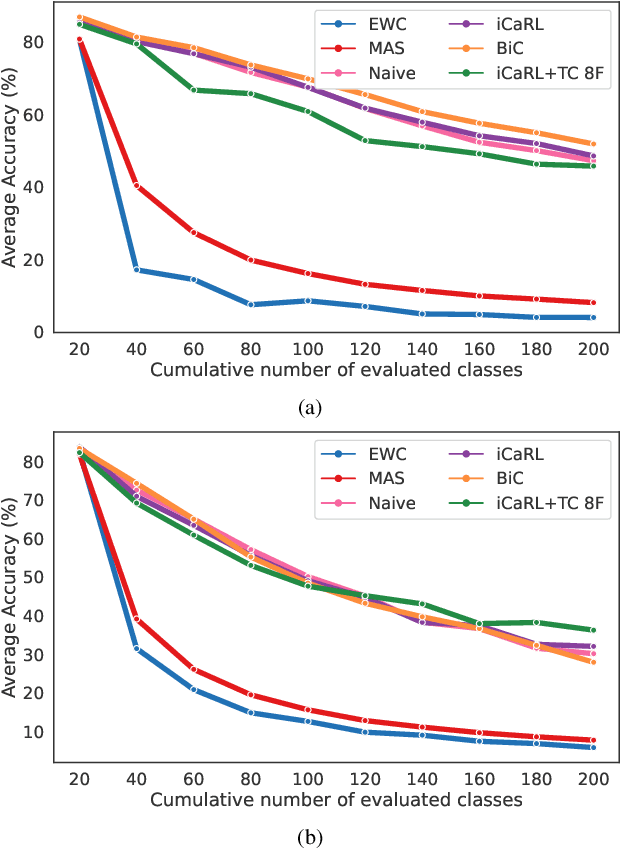
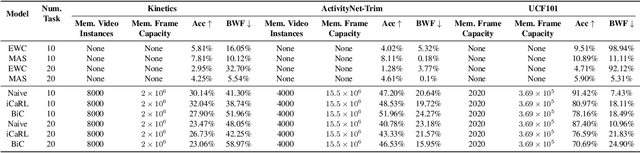
Continual learning (CL) is under-explored in the video domain. The few existing works contain splits with imbalanced class distributions over the tasks, or study the problem in unsuitable datasets. We introduce vCLIMB, a novel video continual learning benchmark. vCLIMB is a standardized test-bed to analyze catastrophic forgetting of deep models in video continual learning. In contrast to previous work, we focus on class incremental continual learning with models trained on a sequence of disjoint tasks, and distribute the number of classes uniformly across the tasks. We perform in-depth evaluations of existing CL methods in vCLIMB, and observe two unique challenges in video data. The selection of instances to store in episodic memory is performed at the frame level. Second, untrimmed training data influences the effectiveness of frame sampling strategies. We address these two challenges by proposing a temporal consistency regularization that can be applied on top of memory-based continual learning methods. Our approach significantly improves the baseline, by up to 24% on the untrimmed continual learning task. To streamline and foster future research in video continual learning, we will publicly release the code for our benchmark and method.