 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Optimization with High-Dimensional Outputs
Jun 24, 2021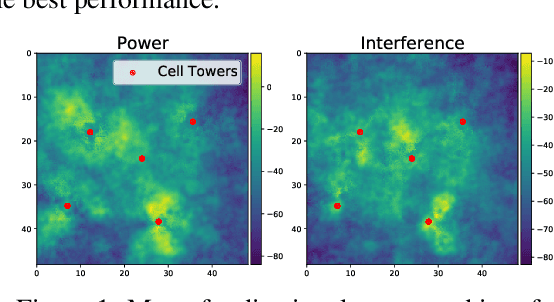
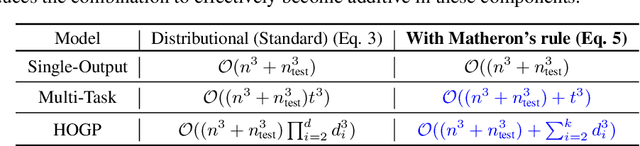
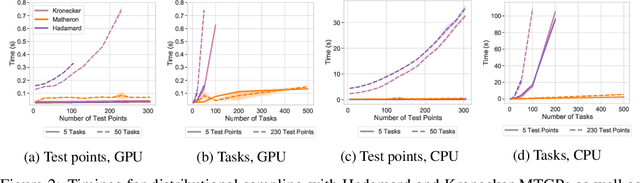

Bayesian Optimization is a sample-efficient black-box optimization procedure that is typically applied to problems with a small number of independent objectives. However, in practice we often wish to optimize objectives defined over many correlated outcomes (or ``tasks"). For example, scientists may want to optimize the coverage of a cell tower network across a dense grid of locations. Similarly, engineers may seek to balance the performance of a robot across dozens of different environments via constrained or robust optimization. However, the Gaussian Process (GP) models typically used as probabilistic surrogates for multi-task Bayesian Optimization scale poorly with the number of outcomes, greatly limiting applicability. We devise an efficient technique for exact multi-task GP sampling that combines exploiting Kronecker structure in the covariance matrices with Matheron's identity, allowing us to perform Bayesian Optimization using exact multi-task GP models with tens of thousands of correlated outputs. In doing so, we achieve substantial improvements in sample efficiency compared to existing approaches that only model aggregate functions of the outcomes. We demonstrate how this unlocks a new class of applications for Bayesian Optimization across a range of tasks in science and engineering, including optimizing interference patterns of an optical interferometer with more than 65,000 outputs.
Parallel Bayesian Optimization of Multiple Noisy Objectives with Expected Hypervolume Improvement
May 17, 2021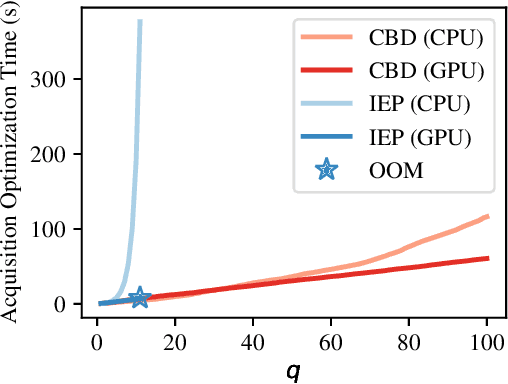
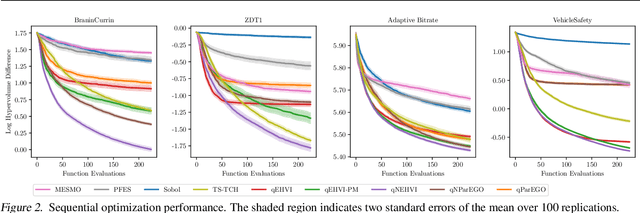

Optimizing multiple competing black-box objectives is a challenging problem in many fields, including science, engineering, and machine learning. Multi-objective Bayesian optimization is a powerful approach for identifying the optimal trade-offs between the objectives with very few function evaluations. However, existing methods tend to perform poorly when observations are corrupted by noise, as they do not take into account uncertainty in the true Pareto frontier over the previously evaluated designs. We propose a novel acquisition function, NEHVI, that overcomes this important practical limitation by applying a Bayesian treatment to the popular expected hypervolume improvement criterion to integrate over this uncertainty in the Pareto frontier. We further argue that, even in the noiseless setting, the problem of generating multiple candidates in parallel reduces that of handling uncertainty in the Pareto frontier. Through this lens, we derive a natural parallel variant of NEHVI that can efficiently generate large batches of candidates. We provide a theoretical convergence guarantee for optimizing a Monte Carlo estimator of NEHVI using exact sample-path gradients. Empirically, we show that NEHVI achieves state-of-the-art performance in noisy and large-batch environments.
Distilled Thompson Sampling: Practical and Efficient Thompson Sampling via Imitation Learning
Dec 08, 2020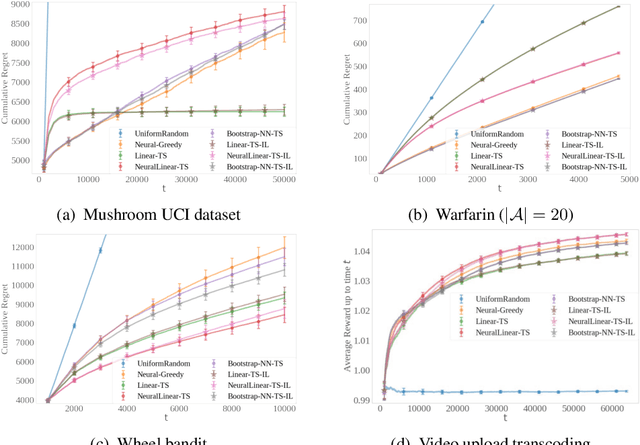
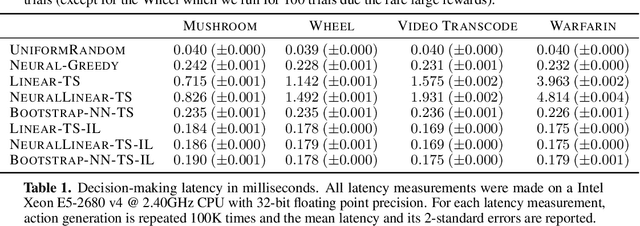
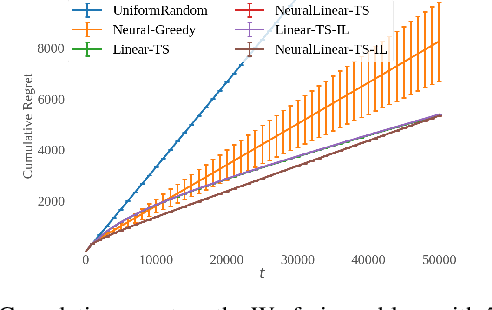

Thompson sampling (TS) has emerged as a robust technique for contextual bandit problems. However, TS requires posterior inference and optimization for action generation, prohibiting its use in many internet applications where latency and ease of deployment are of concern. We propose a novel imitation-learning-based algorithm that distills a TS policy into an explicit policy representation by performing posterior inference and optimization offline. The explicit policy representation enables fast online decision-making and easy deployment in mobile and server-based environments. Our algorithm iteratively performs offline batch updates to the TS policy and learns a new imitation policy. Since we update the TS policy with observations collected under the imitation policy, our algorithm emulates an off-policy version of TS. Our imitation algorithm guarantees Bayes regret comparable to TS, up to the sum of single-step imitation errors. We show these imitation errors can be made arbitrarily small when unlabeled contexts are cheaply available, which is the case for most large-scale internet applications. Empirically, we show that our imitation policy achieves comparable regret to TS, while reducing decision-time latency by over an order of magnitude.
Real-world Video Adaptation with Reinforcement Learning
Aug 28, 2020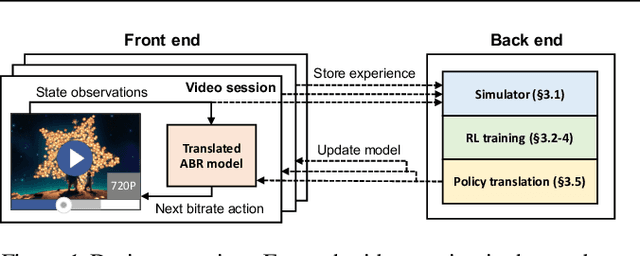
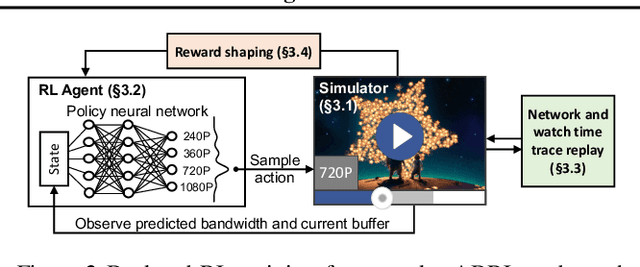
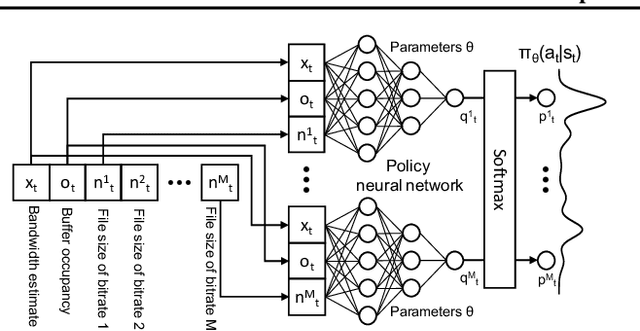
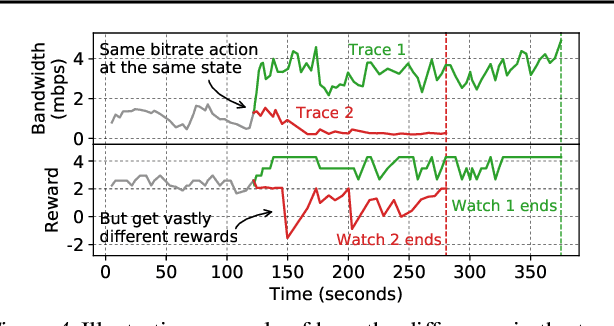
Client-side video players employ adaptive bitrate (ABR) algorithms to optimize user quality of experience (QoE). We evaluate recently proposed RL-based ABR methods in Facebook's web-based video streaming platform. Real-world ABR contains several challenges that requires customized designs beyond off-the-shelf RL algorithms -- we implement a scalable neural network architecture that supports videos with arbitrary bitrate encodings; we design a training method to cope with the variance resulting from the stochasticity in network conditions; and we leverage constrained Bayesian optimization for reward shaping in order to optimize the conflicting QoE objectives. In a week-long worldwide deployment with more than 30 million video streaming sessions, our RL approach outperforms the existing human-engineered ABR algorithms.
Differentiable Expected Hypervolume Improvement for Parallel Multi-Objective Bayesian Optimization
Jun 11, 2020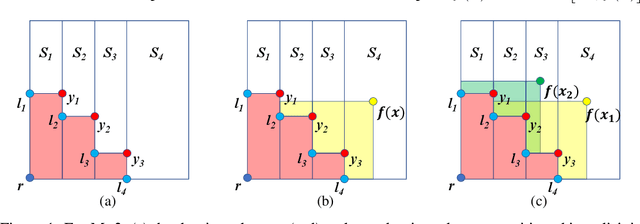
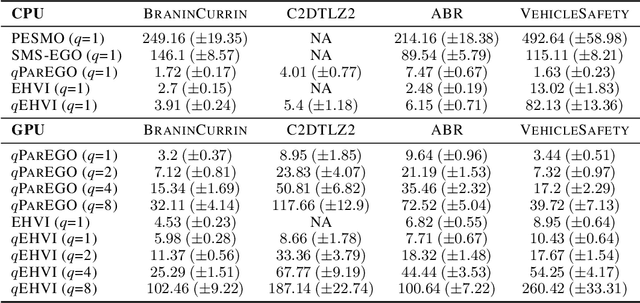
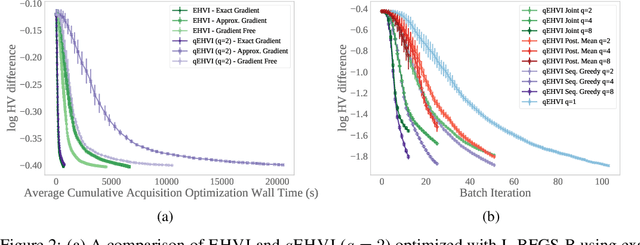

In many real-world scenarios, decision makers seek to efficiently optimize multiple competing objectives in a sample-efficient fashion. Multi-objective Bayesian optimization (BO) is a common approach, but many existing acquisition functions do not have known analytic gradients and suffer from high computational overhead. We leverage recent advances in programming models and hardware acceleration for multi-objective BO using Expected Hypervolume Improvement (EHVI)---an algorithm notorious for its high computational complexity. We derive a novel formulation of $q$-Expected Hypervolume Improvement ($q$EHVI), an acquisition function that extends EHVI to the parallel, constrained evaluation setting. $q$EHVI is an exact computation of the joint EHVI of $q$ new candidate points (up to Monte-Carlo (MC) integration error). Whereas previous EHVI formulations rely on gradient-free acquisition optimization or approximated gradients, we compute exact gradients of the MC estimator via auto-differentiation, thereby enabling efficient and effective optimization using first-order and quasi-second-order methods. Lastly, our empirical evaluation demonstrates that $q$EHVI is computationally tractable in many practical scenarios and outperforms state-of-the-art multi-objective BO algorithms at a fraction of their wall time.
Re-Examining Linear Embeddings for High-Dimensional Bayesian Optimization
Jan 31, 2020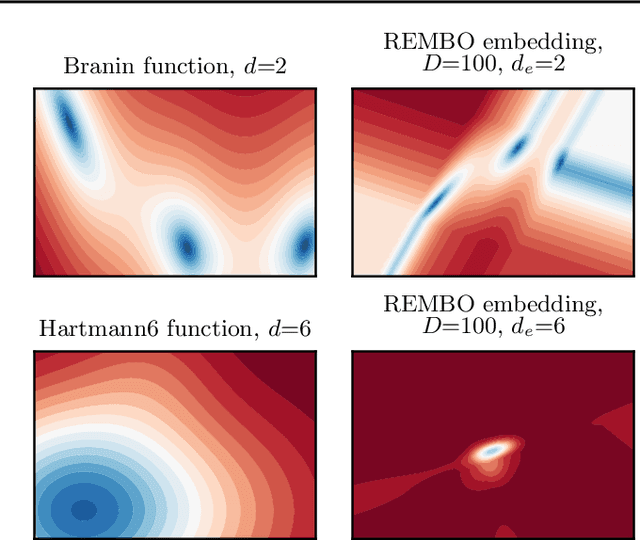
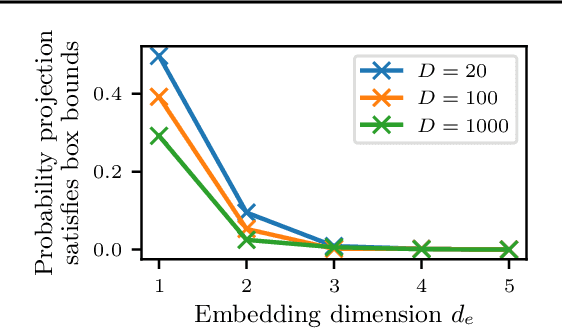
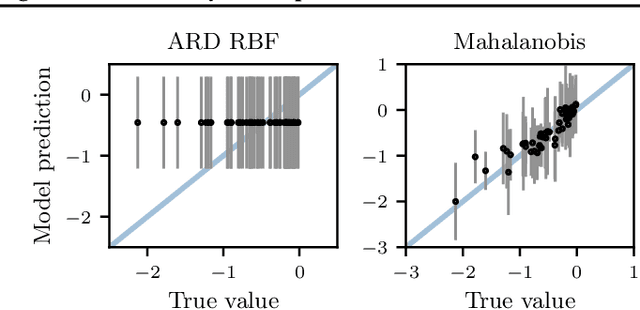
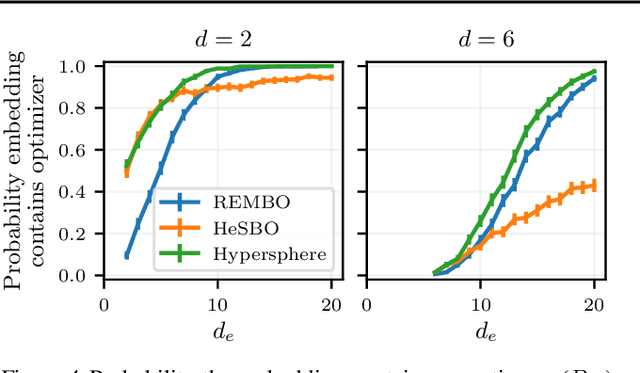
Bayesian optimization (BO) is a popular approach to optimize expensive-to-evaluate black-box functions. A significant challenge in BO is to scale to high-dimensional parameter spaces while retaining sample efficiency. A solution considered in existing literature is to embed the high-dimensional space in a lower-dimensional manifold, often via a random linear embedding. In this paper, we identify several crucial issues and misconceptions about the use of linear embeddings for BO. We study the properties of linear embeddings from the literature and show that some of the design choices in current approaches adversely impact their performance. We show empirically that properly addressing these issues significantly improves the efficacy of linear embeddings for BO on a range of problems, including learning a gait policy for robot locomotion.
Thompson Sampling for Contextual Bandit Problems with Auxiliary Safety Constraints
Nov 02, 2019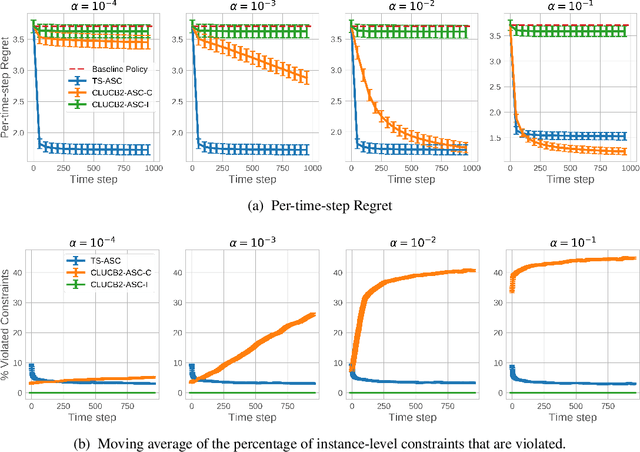
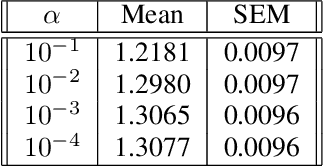
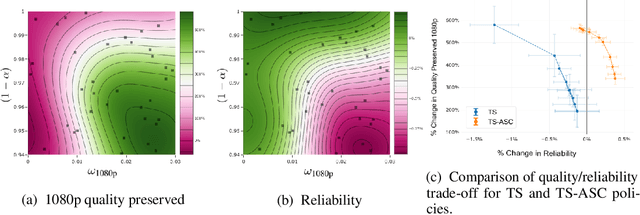
Recent advances in contextual bandit optimization and reinforcement learning have garnered interest in applying these methods to real-world sequential decision making problems. Real-world applications frequently have constraints with respect to a currently deployed policy. Many of the existing constraint-aware algorithms consider problems with a single objective (the reward) and a constraint on the reward with respect to a baseline policy. However, many important applications involve multiple competing objectives and auxiliary constraints. In this paper, we propose a novel Thompson sampling algorithm for multi-outcome contextual bandit problems with auxiliary constraints. We empirically evaluate our algorithm on a synthetic problem. Lastly, we apply our method to a real world video transcoding problem and provide a practical way for navigating the trade-off between safety and performance using Bayesian optimization.
BoTorch: Programmable Bayesian Optimization in PyTorch
Oct 14, 2019
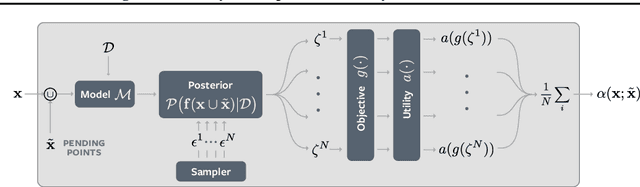
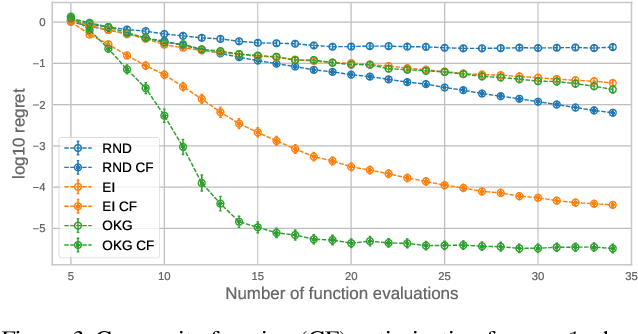
Bayesian optimization provides sample-efficient global optimization for a broad range of applications, including automatic machine learning, molecular chemistry, and experimental design. We introduce BoTorch, a modern programming framework for Bayesian optimization. Enabled by Monte-Carlo (MC) acquisition functions and auto-differentiation, BoTorch's modular design facilitates flexible specification and optimization of probabilistic models written in PyTorch, radically simplifying implementation of novel acquisition functions. Our MC approach is made practical by a distinctive algorithmic foundation that leverages fast predictive distributions and hardware acceleration. In experiments, we demonstrate the improved sample efficiency of BoTorch relative to other popular libraries. BoTorch is open source and available at https://github.com/pytorch/botorch.
Bayesian Optimization for Policy Search via Online-Offline Experimentation
Apr 29, 2019



Online field experiments are the gold-standard way of evaluating changes to real-world interactive machine learning systems. Yet our ability to explore complex, multi-dimensional policy spaces - such as those found in recommendation and ranking problems - is often constrained by the limited number of experiments that can be run simultaneously. To alleviate these constraints, we augment online experiments with an offline simulator and apply multi-task Bayesian optimization to tune live machine learning systems. We describe practical issues that arise in these types of applications, including biases that arise from using a simulator and assumptions for the multi-task kernel. We measure empirical learning curves which show substantial gains from including data from biased offline experiments, and show how these learning curves are consistent with theoretical results for multi-task Gaussian process generalization. We find that improved kernel inference is a significant driver of multi-task generalization. Finally, we show several examples of Bayesian optimization efficiently tuning a live machine learning system by combining offline and online experiments.
Constrained Bayesian Optimization with Noisy Experiments
Jun 26, 2018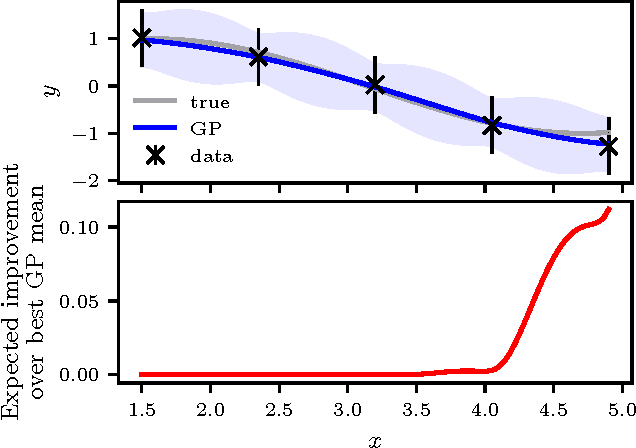
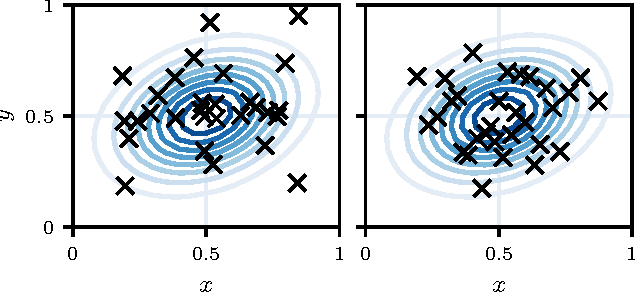
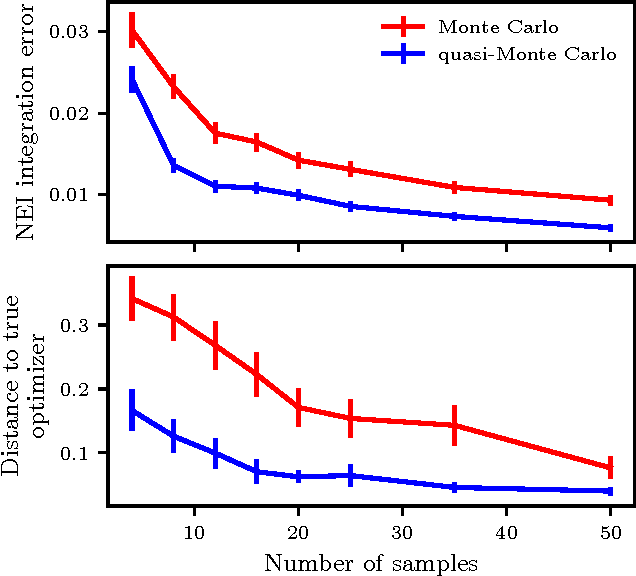
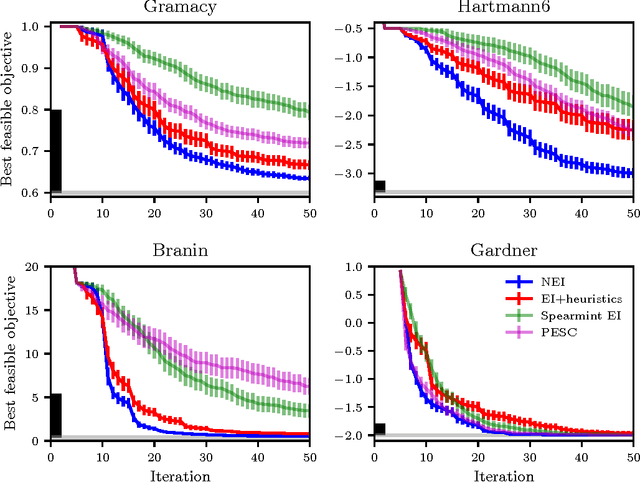
Randomized experiments are the gold standard for evaluating the effects of changes to real-world systems. Data in these tests may be difficult to collect and outcomes may have high variance, resulting in potentially large measurement error. Bayesian optimization is a promising technique for efficiently optimizing multiple continuous parameters, but existing approaches degrade in performance when the noise level is high, limiting its applicability to many randomized experiments. We derive an expression for expected improvement under greedy batch optimization with noisy observations and noisy constraints, and develop a quasi-Monte Carlo approximation that allows it to be efficiently optimized. Simulations with synthetic functions show that optimization performance on noisy, constrained problems outperforms existing methods. We further demonstrate the effectiveness of the method with two real-world experiments conducted at Facebook: optimizing a ranking system, and optimizing server compiler flags.