 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhere Should I Spend My FLOPS? Efficiency Evaluations of Visual Pre-training Methods
Oct 06, 2022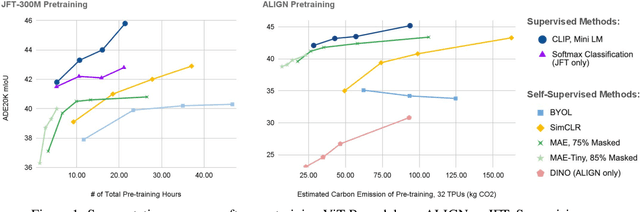
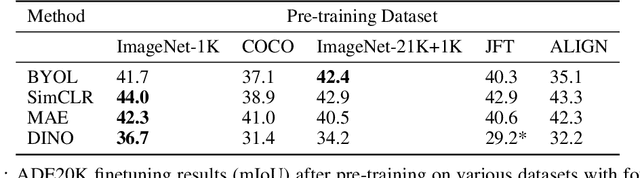
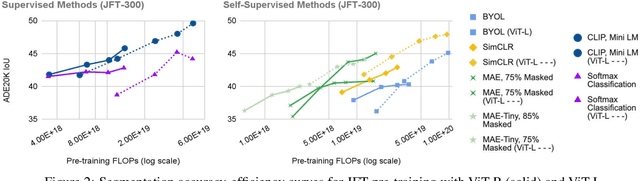
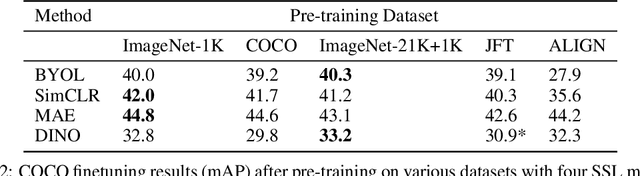
Self-supervised methods have achieved remarkable success in transfer learning, often achieving the same or better accuracy than supervised pre-training. Most prior work has done so by increasing pre-training computation by adding complex data augmentation, multiple views, or lengthy training schedules. In this work, we investigate a related, but orthogonal question: given a fixed FLOP budget, what are the best datasets, models, and (self-)supervised training methods for obtaining high accuracy on representative visual tasks? Given the availability of large datasets, this setting is often more relevant for both academic and industry labs alike. We examine five large-scale datasets (JFT-300M, ALIGN, ImageNet-1K, ImageNet-21K, and COCO) and six pre-training methods (CLIP, DINO, SimCLR, BYOL, Masked Autoencoding, and supervised). In a like-for-like fashion, we characterize their FLOP and CO$_2$ footprints, relative to their accuracy when transferred to a canonical image segmentation task. Our analysis reveals strong disparities in the computational efficiency of pre-training methods and their dependence on dataset quality. In particular, our results call into question the commonly-held assumption that self-supervised methods inherently scale to large, uncurated data. We therefore advocate for (1) paying closer attention to dataset curation and (2) reporting of accuracies in context of the total computational cost.
Back to the Source: Diffusion-Driven Test-Time Adaptation
Jul 07, 2022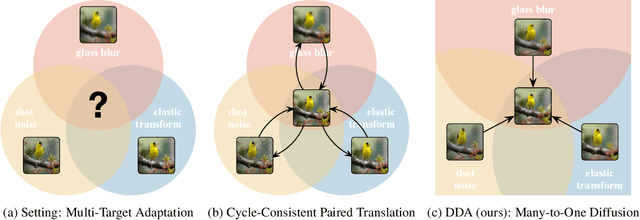

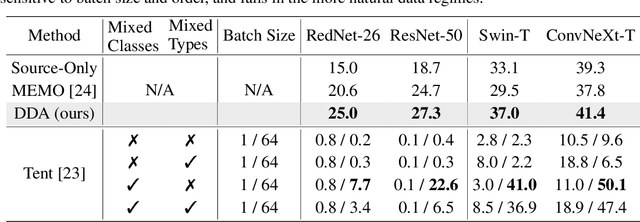
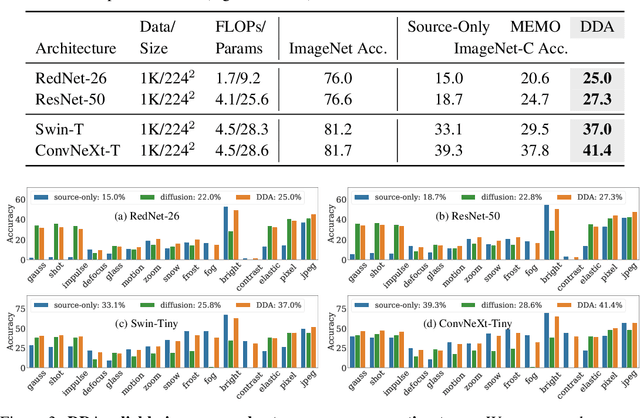
Test-time adaptation harnesses test inputs to improve the accuracy of a model trained on source data when tested on shifted target data. Existing methods update the source model by (re-)training on each target domain. While effective, re-training is sensitive to the amount and order of the data and the hyperparameters for optimization. We instead update the target data, by projecting all test inputs toward the source domain with a generative diffusion model. Our diffusion-driven adaptation method, DDA, shares its models for classification and generation across all domains. Both models are trained on the source domain, then fixed during testing. We augment diffusion with image guidance and self-ensembling to automatically decide how much to adapt. Input adaptation by DDA is more robust than prior model adaptation approaches across a variety of corruptions, architectures, and data regimes on the ImageNet-C benchmark. With its input-wise updates, DDA succeeds where model adaptation degrades on too little data in small batches, dependent data in non-uniform order, or mixed data with multiple corruptions.
Object discovery and representation networks
Mar 16, 2022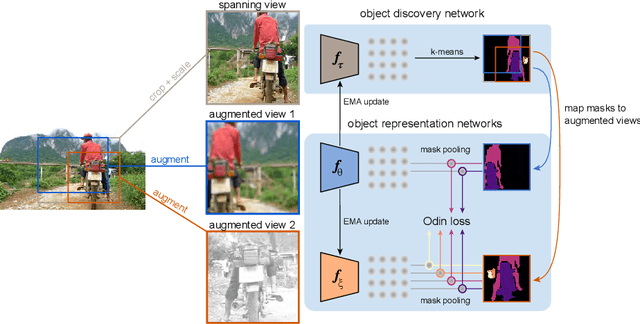
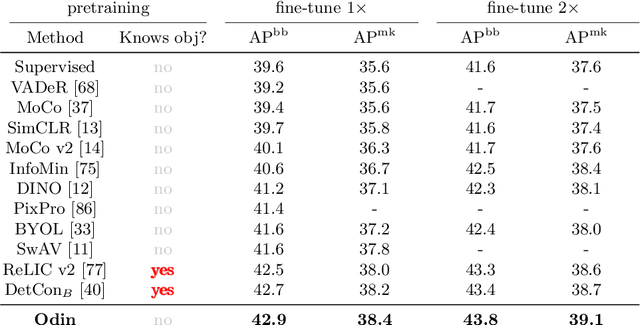
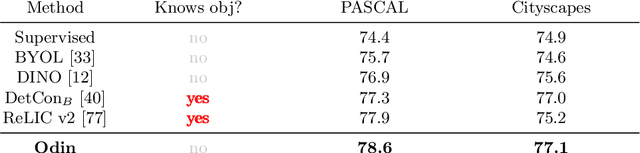

The promise of self-supervised learning (SSL) is to leverage large amounts of unlabeled data to solve complex tasks. While there has been excellent progress with simple, image-level learning, recent methods have shown the advantage of including knowledge of image structure. However, by introducing hand-crafted image segmentations to define regions of interest, or specialized augmentation strategies, these methods sacrifice the simplicity and generality that makes SSL so powerful. Instead, we propose a self-supervised learning paradigm that discovers the structure encoded in these priors by itself. Our method, Odin, couples object discovery and representation networks to discover meaningful image segmentations without any supervision. The resulting learning paradigm is simpler, less brittle, and more general, and achieves state-of-the-art transfer learning results for object detection and instance segmentation on COCO, and semantic segmentation on PASCAL and Cityscapes, while strongly surpassing supervised pre-training for video segmentation on DAVIS.
Evaluating the Adversarial Robustness of Adaptive Test-time Defenses
Feb 28, 2022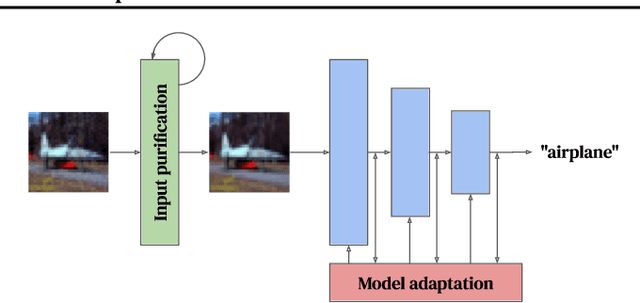



Adaptive defenses that use test-time optimization promise to improve robustness to adversarial examples. We categorize such adaptive test-time defenses and explain their potential benefits and drawbacks. In the process, we evaluate some of the latest proposed adaptive defenses (most of them published at peer-reviewed conferences). Unfortunately, none significantly improve upon static models when evaluated appropriately. Some even weaken the underlying static model while simultaneously increasing inference cost. While these results are disappointing, we still believe that adaptive test-time defenses are a promising avenue of research and, as such, we provide recommendations on evaluating such defenses. We go beyond the checklist provided by Carlini et al. (2019) by providing concrete steps that are specific to this type of defense.
Hierarchical Perceiver
Feb 22, 2022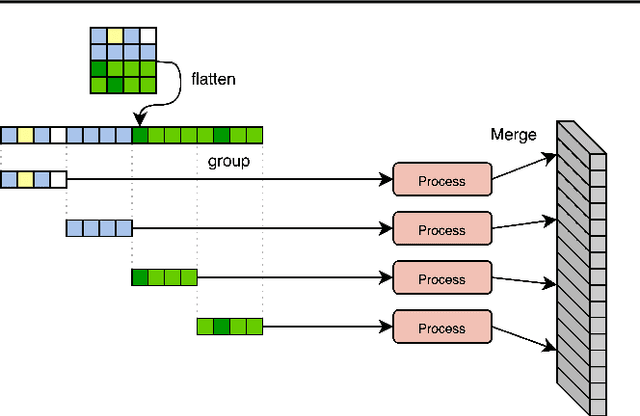

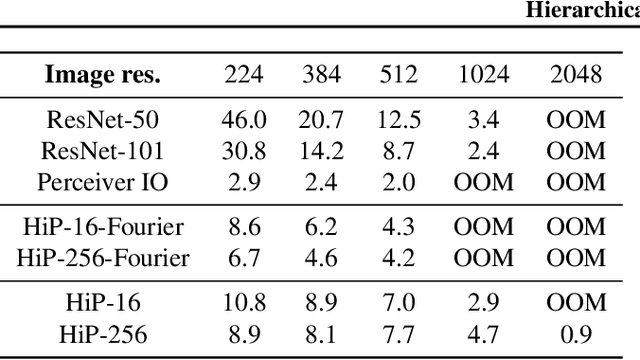

General perception systems such as Perceivers can process arbitrary modalities in any combination and are able to handle up to a few hundred thousand inputs. They achieve this generality by exclusively using global attention operations. This however hinders them from scaling up to the inputs sizes required to process raw high-resolution images or video. In this paper, we show that some degree of locality can be introduced back into these models, greatly improving their efficiency while preserving their generality. To scale them further, we introduce a self-supervised approach that enables learning dense low-dimensional positional embeddings for very large signals. We call the resulting model a Hierarchical Perceiver (HiP). HiP retains the ability to process arbitrary modalities, but now at higher-resolution and without any specialized preprocessing, improving over flat Perceivers in both efficiency and accuracy on the ImageNet, Audioset and PASCAL VOC datasets.
On-target Adaptation
Sep 02, 2021


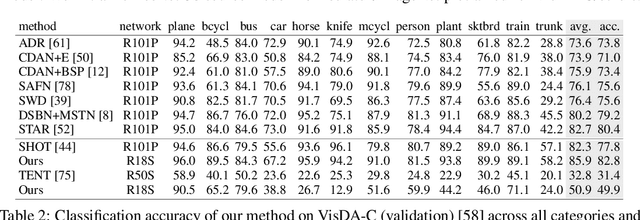
Domain adaptation seeks to mitigate the shift between training on the \emph{source} domain and testing on the \emph{target} domain. Most adaptation methods rely on the source data by joint optimization over source data and target data. Source-free methods replace the source data with a source model by fine-tuning it on target. Either way, the majority of the parameter updates for the model representation and the classifier are derived from the source, and not the target. However, target accuracy is the goal, and so we argue for optimizing as much as possible on the target data. We show significant improvement by on-target adaptation, which learns the representation purely from target data while taking only the source predictions for supervision. In the long-tailed classification setting, we show further improvement by on-target class distribution learning, which learns the (im)balance of classes from target data.
Perceiver IO: A General Architecture for Structured Inputs & Outputs
Aug 02, 2021
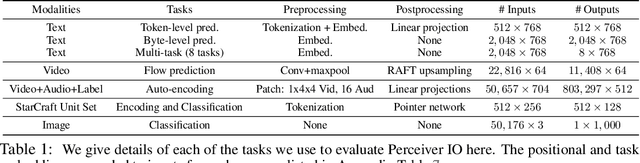
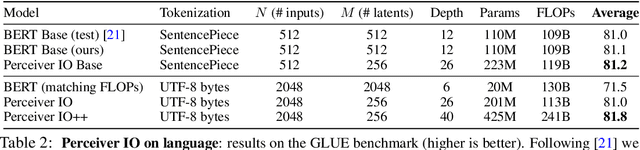
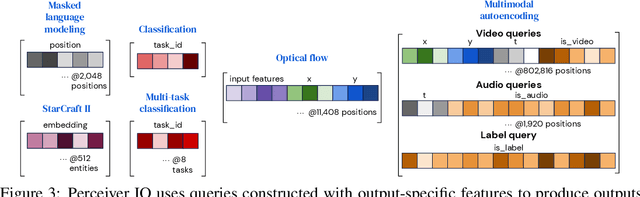
The recently-proposed Perceiver model obtains good results on several domains (images, audio, multimodal, point clouds) while scaling linearly in compute and memory with the input size. While the Perceiver supports many kinds of inputs, it can only produce very simple outputs such as class scores. Perceiver IO overcomes this limitation without sacrificing the original's appealing properties by learning to flexibly query the model's latent space to produce outputs of arbitrary size and semantics. Perceiver IO still decouples model depth from data size and still scales linearly with data size, but now with respect to both input and output sizes. The full Perceiver IO model achieves strong results on tasks with highly structured output spaces, such as natural language and visual understanding, StarCraft II, and multi-task and multi-modal domains. As highlights, Perceiver IO matches a Transformer-based BERT baseline on the GLUE language benchmark without the need for input tokenization and achieves state-of-the-art performance on Sintel optical flow estimation.
Fighting Gradients with Gradients: Dynamic Defenses against Adversarial Attacks
May 18, 2021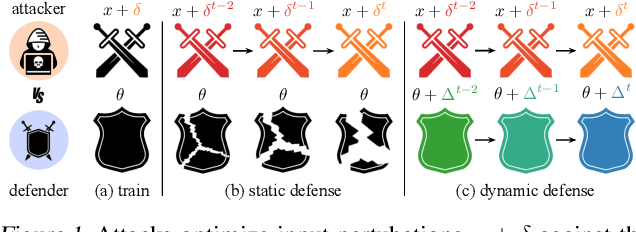
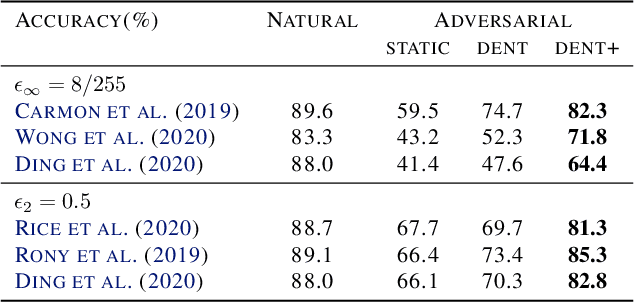


Adversarial attacks optimize against models to defeat defenses. Existing defenses are static, and stay the same once trained, even while attacks change. We argue that models should fight back, and optimize their defenses against attacks at test time. We propose dynamic defenses, to adapt the model and input during testing, by defensive entropy minimization (dent). Dent alters testing, but not training, for compatibility with existing models and train-time defenses. Dent improves the robustness of adversarially-trained defenses and nominally-trained models against white-box, black-box, and adaptive attacks on CIFAR-10/100 and ImageNet. In particular, dent boosts state-of-the-art defenses by 20+ points absolute against AutoAttack on CIFAR-10 at $\epsilon_\infty$ = 8/255.
Confidence Adaptive Anytime Pixel-Level Recognition
Apr 01, 2021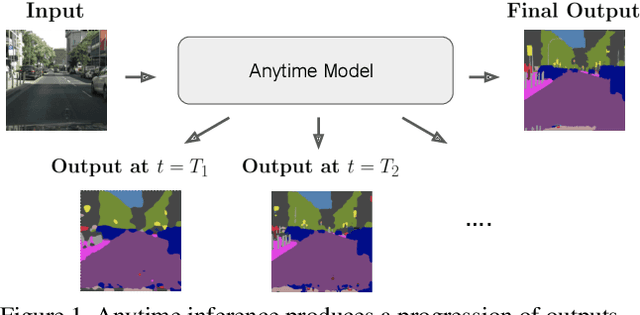
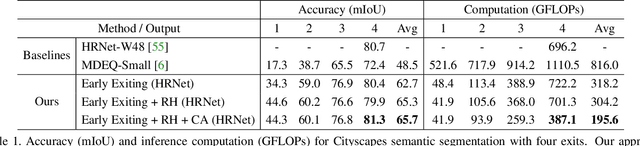
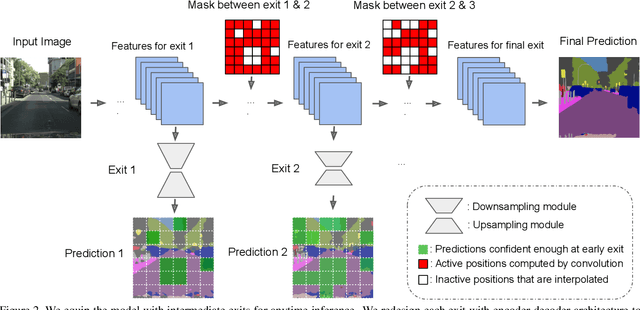
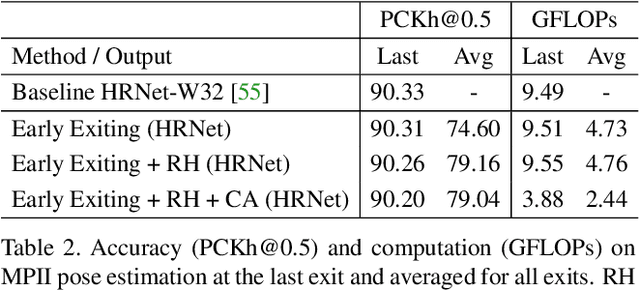
Anytime inference requires a model to make a progression of predictions which might be halted at any time. Prior research on anytime visual recognition has mostly focused on image classification. We propose the first unified and end-to-end model approach for anytime pixel-level recognition. A cascade of "exits" is attached to the model to make multiple predictions and direct further computation. We redesign the exits to account for the depth and spatial resolution of the features for each exit. To reduce total computation, and make full use of prior predictions, we develop a novel spatially adaptive approach to avoid further computation on regions where early predictions are already sufficiently confident. Our full model with redesigned exit architecture and spatial adaptivity enables anytime inference, achieves the same level of final accuracy, and even significantly reduces total computation. We evaluate our approach on semantic segmentation and human pose estimation. On Cityscapes semantic segmentation and MPII human pose estimation, our approach enables anytime inference while also reducing the total FLOPs of its base models by 44.4% and 59.1% without sacrificing accuracy. As a new anytime baseline, we measure the anytime capability of deep equilibrium networks, a recent class of model that is intrinsically iterative, and we show that the accuracy-computation curve of our architecture strictly dominates it.
It Is Likely That Your Loss Should be a Likelihood
Jul 12, 2020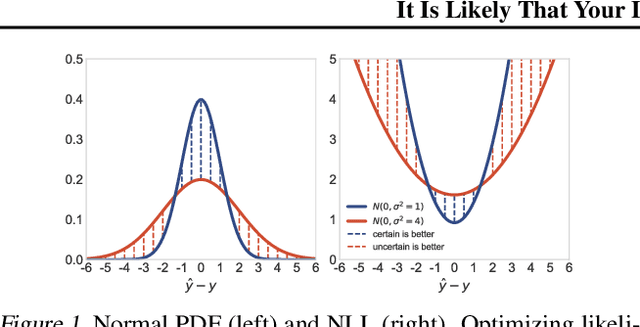
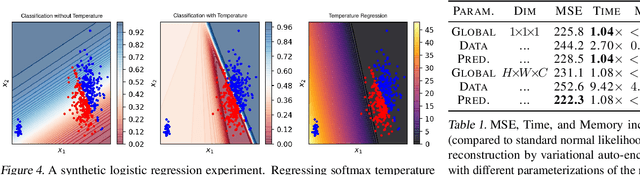

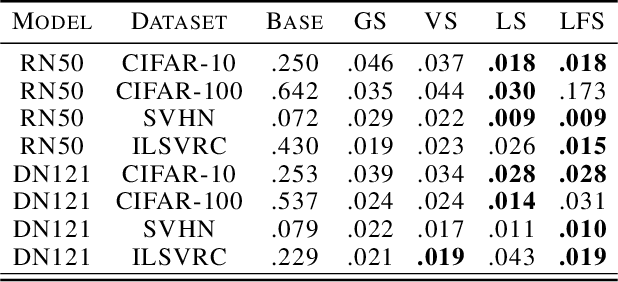
We recall that certain common losses are simplified likelihoods and instead argue for optimizing full likelihoods that include their parameters, such as the variance of the normal distribution and the temperature of the softmax distribution. Joint optimization of likelihood and model parameters can adaptively tune the scales and shapes of losses and the weights of regularizers. We survey and systematically evaluate how to parameterize and apply likelihood parameters for robust modeling and re-calibration. Additionally, we propose adaptively tuning $L_2$ and $L_1$ weights by fitting the scale parameters of normal and Laplace priors and introduce more flexible element-wise regularizers.