 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Crossword Solving
May 19, 2022
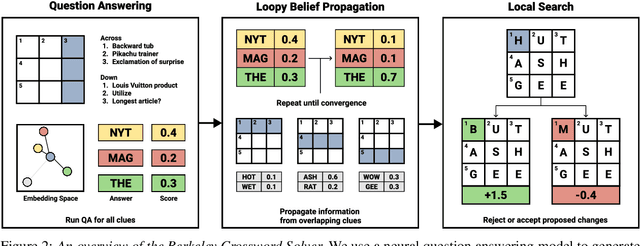
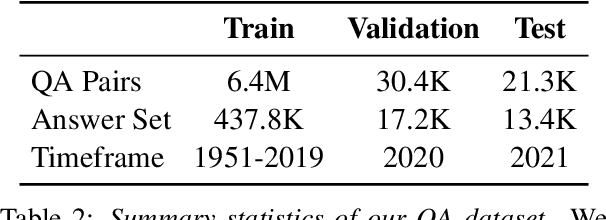
We present the Berkeley Crossword Solver, a state-of-the-art approach for automatically solving crossword puzzles. Our system works by generating answer candidates for each crossword clue using neural question answering models and then combines loopy belief propagation with local search to find full puzzle solutions. Compared to existing approaches, our system improves exact puzzle accuracy from 57% to 82% on crosswords from The New York Times and obtains 99.9% letter accuracy on themeless puzzles. Our system also won first place at the top human crossword tournament, which marks the first time that a computer program has surpassed human performance at this event. To facilitate research on question answering and crossword solving, we analyze our system's remaining errors and release a dataset of over six million question-answer pairs.
Benchmarking Generalization via In-Context Instructions on 1,600+ Language Tasks
Apr 16, 2022

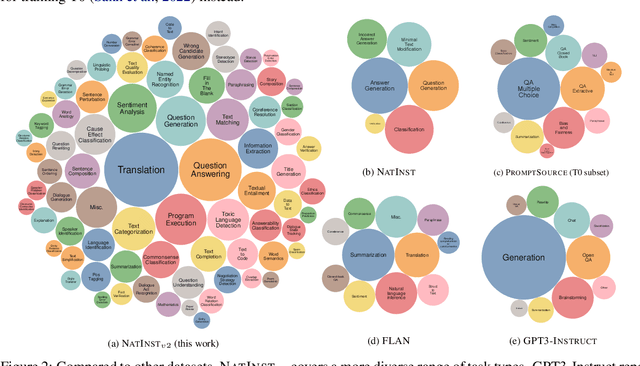
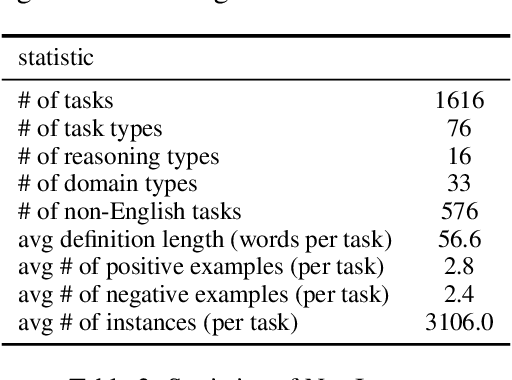
How can we measure the generalization of models to a variety of unseen tasks when provided with their language instructions? To facilitate progress in this goal, we introduce Natural-Instructions v2, a collection of 1,600+ diverse language tasks and their expert written instructions. More importantly, the benchmark covers 70+ distinct task types, such as tagging, in-filling, and rewriting. This benchmark is collected with contributions of NLP practitioners in the community and through an iterative peer review process to ensure their quality. This benchmark enables large-scale evaluation of cross-task generalization of the models -- training on a subset of tasks and evaluating on the remaining unseen ones. For instance, we are able to rigorously quantify generalization as a function of various scaling parameters, such as the number of observed tasks, the number of instances, and model sizes. As a by-product of these experiments. we introduce Tk-Instruct, an encoder-decoder Transformer that is trained to follow a variety of in-context instructions (plain language task definitions or k-shot examples) which outperforms existing larger models on our benchmark. We hope this benchmark facilitates future progress toward more general-purpose language understanding models.
Detoxifying Language Models Risks Marginalizing Minority Voices
Apr 13, 2021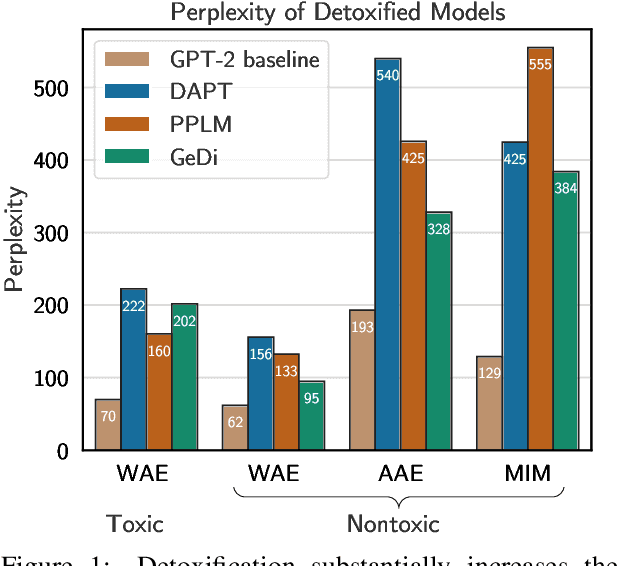

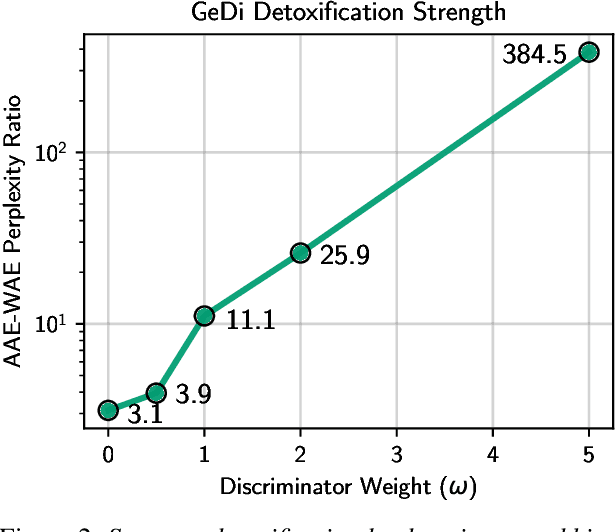
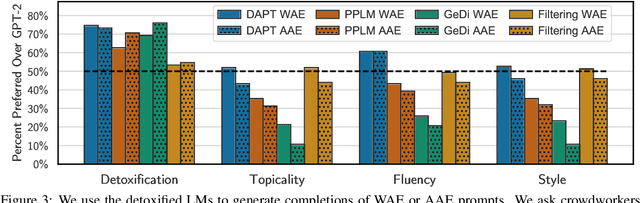
Language models (LMs) must be both safe and equitable to be responsibly deployed in practice. With safety in mind, numerous detoxification techniques (e.g., Dathathri et al. 2020; Krause et al. 2020) have been proposed to mitigate toxic LM generations. In this work, we show that current detoxification techniques hurt equity: they decrease the utility of LMs on language used by marginalized groups (e.g., African-American English and minority identity mentions). In particular, we perform automatic and human evaluations of text generation quality when LMs are conditioned on inputs with different dialects and group identifiers. We find that detoxification makes LMs more brittle to distribution shift, especially on language used by marginalized groups. We identify that these failures stem from detoxification methods exploiting spurious correlations in toxicity datasets. Overall, our results highlight the tension between the controllability and distributional robustness of LMs.