 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Competitive Algorithm for Agnostic Active Learning
Oct 28, 2023For some hypothesis classes and input distributions, active agnostic learning needs exponentially fewer samples than passive learning; for other classes and distributions, it offers little to no improvement. The most popular algorithms for agnostic active learning express their performance in terms of a parameter called the disagreement coefficient, but it is known that these algorithms are inefficient on some inputs. We take a different approach to agnostic active learning, getting an algorithm that is competitive with the optimal algorithm for any binary hypothesis class $H$ and distribution $D_X$ over $X$. In particular, if any algorithm can use $m^*$ queries to get $O(\eta)$ error, then our algorithm uses $O(m^* \log |H|)$ queries to get $O(\eta)$ error. Our algorithm lies in the vein of the splitting-based approach of Dasgupta [2004], which gets a similar result for the realizable ($\eta = 0$) setting. We also show that it is NP-hard to do better than our algorithm's $O(\log |H|)$ overhead in general.
Finite-Sample Symmetric Mean Estimation with Fisher Information Rate
Jun 28, 2023

The mean of an unknown variance-$\sigma^2$ distribution $f$ can be estimated from $n$ samples with variance $\frac{\sigma^2}{n}$ and nearly corresponding subgaussian rate. When $f$ is known up to translation, this can be improved asymptotically to $\frac{1}{n\mathcal I}$, where $\mathcal I$ is the Fisher information of the distribution. Such an improvement is not possible for general unknown $f$, but [Stone, 1975] showed that this asymptotic convergence $\textit{is}$ possible if $f$ is $\textit{symmetric}$ about its mean. Stone's bound is asymptotic, however: the $n$ required for convergence depends in an unspecified way on the distribution $f$ and failure probability $\delta$. In this paper we give finite-sample guarantees for symmetric mean estimation in terms of Fisher information. For every $f, n, \delta$ with $n > \log \frac{1}{\delta}$, we get convergence close to a subgaussian with variance $\frac{1}{n \mathcal I_r}$, where $\mathcal I_r$ is the $r$-$\textit{smoothed}$ Fisher information with smoothing radius $r$ that decays polynomially in $n$. Such a bound essentially matches the finite-sample guarantees in the known-$f$ setting.
Accelerated Video Annotation driven by Deep Detector and Tracker
Feb 19, 2023Annotating object ground truth in videos is vital for several downstream tasks in robot perception and machine learning, such as for evaluating the performance of an object tracker or training an image-based object detector. The accuracy of the annotated instances of the moving objects on every image frame in a video is crucially important. Achieving that through manual annotations is not only very time consuming and labor intensive, but is also prone to high error rate. State-of-the-art annotation methods depend on manually initializing the object bounding boxes only in the first frame and then use classical tracking methods, e.g., adaboost, or kernelized correlation filters, to keep track of those bounding boxes. These can quickly drift, thereby requiring tedious manual supervision. In this paper, we propose a new annotation method which leverages a combination of a learning-based detector (SSD) and a learning-based tracker (RE$^3$). Through this, we significantly reduce annotation drifts, and, consequently, the required manual supervision. We validate our approach through annotation experiments using our proposed annotation method and existing baselines on a set of drone video frames. Source code and detailed information on how to run the annotation program can be found at https://github.com/robot-perception-group/smarter-labelme
High-dimensional Location Estimation via Norm Concentration for Subgamma Vectors
Feb 05, 2023

In location estimation, we are given $n$ samples from a known distribution $f$ shifted by an unknown translation $\lambda$, and want to estimate $\lambda$ as precisely as possible. Asymptotically, the maximum likelihood estimate achieves the Cram\'er-Rao bound of error $\mathcal N(0, \frac{1}{n\mathcal I})$, where $\mathcal I$ is the Fisher information of $f$. However, the $n$ required for convergence depends on $f$, and may be arbitrarily large. We build on the theory using \emph{smoothed} estimators to bound the error for finite $n$ in terms of $\mathcal I_r$, the Fisher information of the $r$-smoothed distribution. As $n \to \infty$, $r \to 0$ at an explicit rate and this converges to the Cram\'er-Rao bound. We (1) improve the prior work for 1-dimensional $f$ to converge for constant failure probability in addition to high probability, and (2) extend the theory to high-dimensional distributions. In the process, we prove a new bound on the norm of a high-dimensional random variable whose 1-dimensional projections are subgamma, which may be of independent interest.
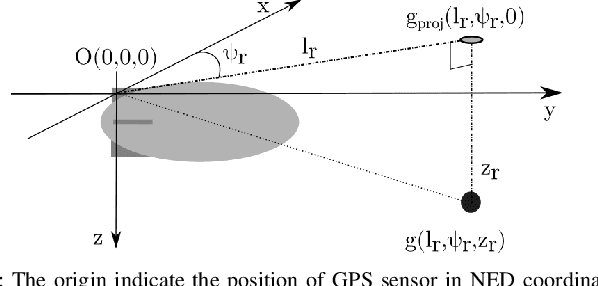
Perception-driven Formation Control of Airships
Sep 26, 2022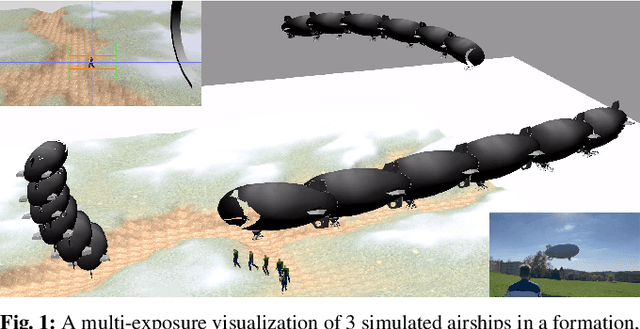
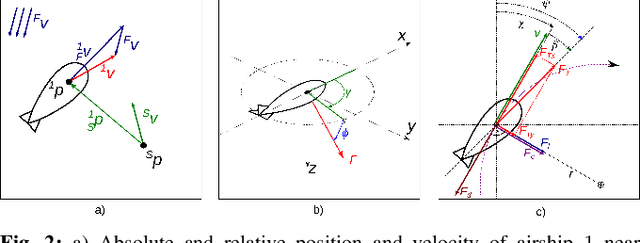
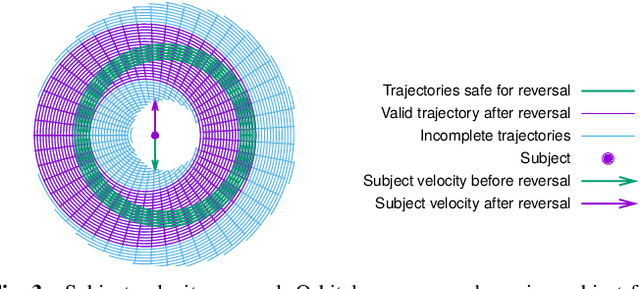
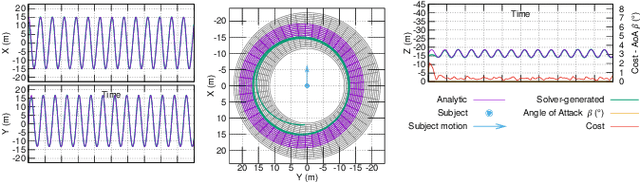
For tracking and motion capture (MoCap) of animals in their natural habitat, a formation of safe and silent aerial platforms, such as airships with on-board cameras, is well suited. However, unlike multi-rotors, airships are severely motion constrained and affected by ambient wind. Their orientation and flight direction are also tightly coupled. Therefore, state-of-the-art MPC-based formation control methods for perception tasks are not directly applicable for a team of airships. In this paper, we address this problem by first exploiting a periodic relationship between the airspeed of an airship and its distance to the subject. We use it to derive analytical and numeric solutions that satisfy the MoCap perception constraints. Based on this, we develop an MPC-based formation controller. We performed detailed analysis of our solution, including the effects of changing physical parameters (like angle of attack and pitch angle) on it. Extensive simulation experiments, comparing results for different formation sizes, different wind conditions and various subject speeds, are presented. A demonstration of our method on a real airship is also included. We have released all of our source code at https://github.com/robot-perception-group/Airship-MPC. A video describing our approach and results can be watched at https://youtu.be/ihS0_VRD_kk
Hardness and Algorithms for Robust and Sparse Optimization
Jun 29, 2022
We explore algorithms and limitations for sparse optimization problems such as sparse linear regression and robust linear regression. The goal of the sparse linear regression problem is to identify a small number of key features, while the goal of the robust linear regression problem is to identify a small number of erroneous measurements. Specifically, the sparse linear regression problem seeks a $k$-sparse vector $x\in\mathbb{R}^d$ to minimize $\|Ax-b\|_2$, given an input matrix $A\in\mathbb{R}^{n\times d}$ and a target vector $b\in\mathbb{R}^n$, while the robust linear regression problem seeks a set $S$ that ignores at most $k$ rows and a vector $x$ to minimize $\|(Ax-b)_S\|_2$. We first show bicriteria, NP-hardness of approximation for robust regression building on the work of [OWZ15] which implies a similar result for sparse regression. We further show fine-grained hardness of robust regression through a reduction from the minimum-weight $k$-clique conjecture. On the positive side, we give an algorithm for robust regression that achieves arbitrarily accurate additive error and uses runtime that closely matches the lower bound from the fine-grained hardness result, as well as an algorithm for sparse regression with similar runtime. Both our upper and lower bounds rely on a general reduction from robust linear regression to sparse regression that we introduce. Our algorithms, inspired by the 3SUM problem, use approximate nearest neighbor data structures and may be of independent interest for solving sparse optimization problems. For instance, we demonstrate that our techniques can also be used for the well-studied sparse PCA problem.
Sharp Constants in Uniformity Testing via the Huber Statistic
Jun 21, 2022
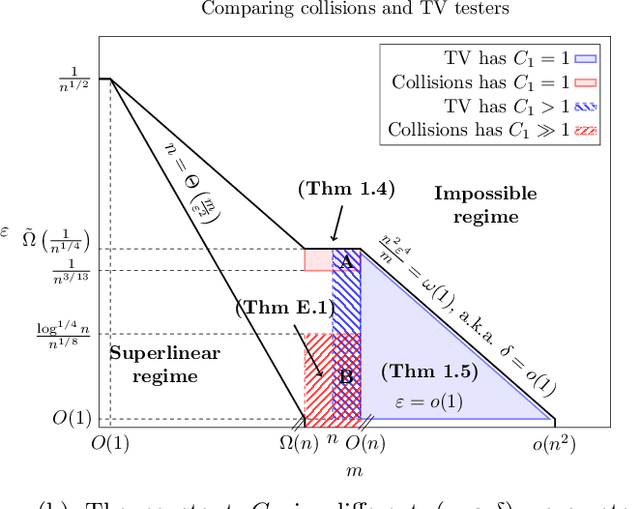
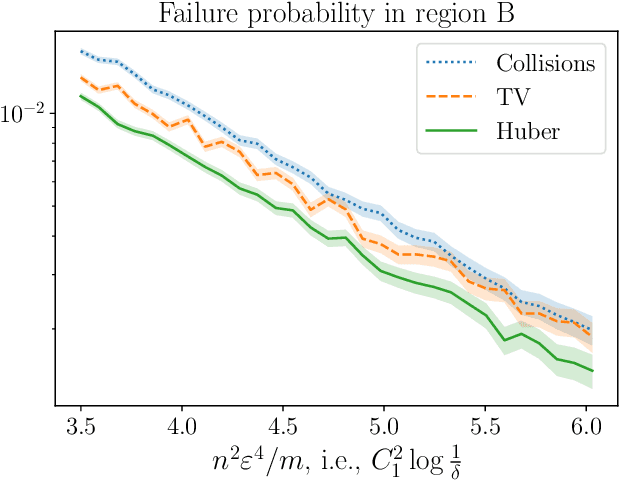
Uniformity testing is one of the most well-studied problems in property testing, with many known test statistics, including ones based on counting collisions, singletons, and the empirical TV distance. It is known that the optimal sample complexity to distinguish the uniform distribution on $m$ elements from any $\epsilon$-far distribution with $1-\delta$ probability is $n = \Theta\left(\frac{\sqrt{m \log (1/\delta)}}{\epsilon^2} + \frac{\log (1/\delta)}{\epsilon^2}\right)$, which is achieved by the empirical TV tester. Yet in simulation, these theoretical analyses are misleading: in many cases, they do not correctly rank order the performance of existing testers, even in an asymptotic regime of all parameters tending to $0$ or $\infty$. We explain this discrepancy by studying the \emph{constant factors} required by the algorithms. We show that the collisions tester achieves a sharp maximal constant in the number of standard deviations of separation between uniform and non-uniform inputs. We then introduce a new tester based on the Huber loss, and show that it not only matches this separation, but also has tails corresponding to a Gaussian with this separation. This leads to a sample complexity of $(1 + o(1))\frac{\sqrt{m \log (1/\delta)}}{\epsilon^2}$ in the regime where this term is dominant, unlike all other existing testers.
Finite-Sample Maximum Likelihood Estimation of Location
Jun 06, 2022
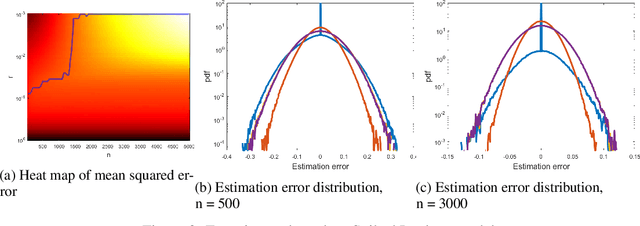
We consider 1-dimensional location estimation, where we estimate a parameter $\lambda$ from $n$ samples $\lambda + \eta_i$, with each $\eta_i$ drawn i.i.d. from a known distribution $f$. For fixed $f$ the maximum-likelihood estimate (MLE) is well-known to be optimal in the limit as $n \to \infty$: it is asymptotically normal with variance matching the Cram\'er-Rao lower bound of $\frac{1}{n\mathcal{I}}$, where $\mathcal{I}$ is the Fisher information of $f$. However, this bound does not hold for finite $n$, or when $f$ varies with $n$. We show for arbitrary $f$ and $n$ that one can recover a similar theory based on the Fisher information of a smoothed version of $f$, where the smoothing radius decays with $n$.
Deep Residual Reinforcement Learning based Autonomous Blimp Control
Mar 10, 2022
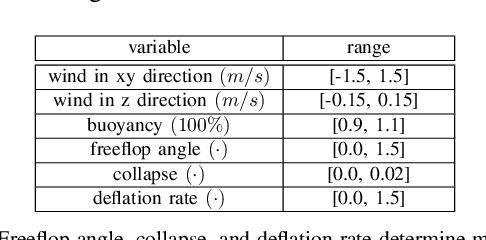
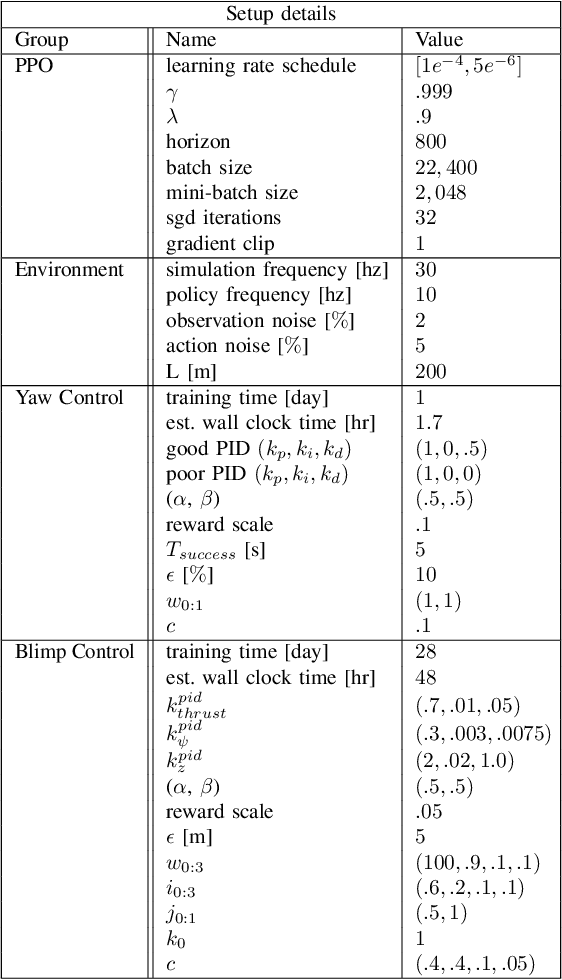
Blimps are well suited to perform long-duration aerial tasks as they are energy efficient, relatively silent and safe. To address the blimp navigation and control task, in previous work we developed a hardware and software-in-the-loop framework and a PID-based controller for large blimps in the presence of wind disturbance. However, blimps have a deformable structure and their dynamics are inherently non-linear and time-delayed, making PID controllers difficult to tune. Thus, often resulting in large tracking errors. Moreover, the buoyancy of a blimp is constantly changing due to variations in ambient temperature and pressure. To address these issues, in this paper we present a learning-based framework based on deep residual reinforcement learning (DRRL), for the blimp control task. Within this framework, we first employ a PID controller to provide baseline performance. Subsequently, the DRRL agent learns to modify the PID decisions by interaction with the environment. We demonstrate in simulation that DRRL agent consistently improves the PID performance. Through rigorous simulation experiments, we show that the agent is robust to changes in wind speed and buoyancy. In real-world experiments, we demonstrate that the agent, trained only in simulation, is sufficiently robust to control an actual blimp in windy conditions. We openly provide the source code of our approach at https://github.com/ robot-perception-group/AutonomousBlimpDRL.
Coresets for Data Discretization and Sine Wave Fitting
Mar 06, 2022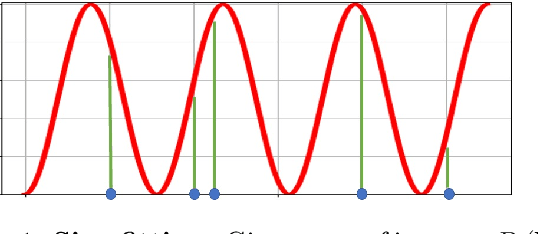
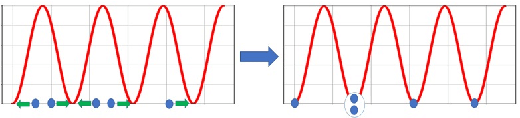


In the \emph{monitoring} problem, the input is an unbounded stream $P={p_1,p_2\cdots}$ of integers in $[N]:=\{1,\cdots,N\}$, that are obtained from a sensor (such as GPS or heart beats of a human). The goal (e.g., for anomaly detection) is to approximate the $n$ points received so far in $P$ by a single frequency $\sin$, e.g. $\min_{c\in C}cost(P,c)+\lambda(c)$, where $cost(P,c)=\sum_{i=1}^n \sin^2(\frac{2\pi}{N} p_ic)$, $C\subseteq [N]$ is a feasible set of solutions, and $\lambda$ is a given regularization function. For any approximation error $\varepsilon>0$, we prove that \emph{every} set $P$ of $n$ integers has a weighted subset $S\subseteq P$ (sometimes called core-set) of cardinality $|S|\in O(\log(N)^{O(1)})$ that approximates $cost(P,c)$ (for every $c\in [N]$) up to a multiplicative factor of $1\pm\varepsilon$. Using known coreset techniques, this implies streaming algorithms using only $O((\log(N)\log(n))^{O(1)})$ memory. Our results hold for a large family of functions. Experimental results and open source code are provided.