 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStrategies and Principles of Distributed Machine Learning on Big Data
Dec 31, 2015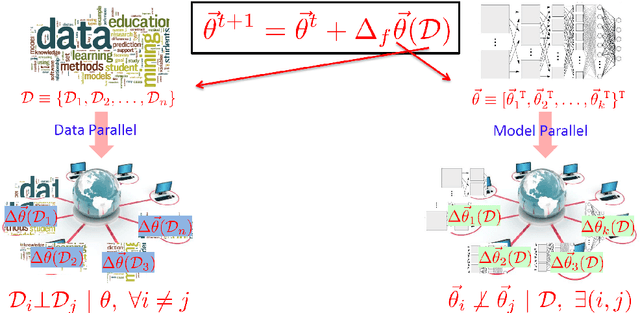
The rise of Big Data has led to new demands for Machine Learning (ML) systems to learn complex models with millions to billions of parameters, that promise adequate capacity to digest massive datasets and offer powerful predictive analytics thereupon. In order to run ML algorithms at such scales, on a distributed cluster with 10s to 1000s of machines, it is often the case that significant engineering efforts are required --- and one might fairly ask if such engineering truly falls within the domain of ML research or not. Taking the view that Big ML systems can benefit greatly from ML-rooted statistical and algorithmic insights --- and that ML researchers should therefore not shy away from such systems design --- we discuss a series of principles and strategies distilled from our recent efforts on industrial-scale ML solutions. These principles and strategies span a continuum from application, to engineering, and to theoretical research and development of Big ML systems and architectures, with the goal of understanding how to make them efficient, generally-applicable, and supported with convergence and scaling guarantees. They concern four key questions which traditionally receive little attention in ML research: How to distribute an ML program over a cluster? How to bridge ML computation with inter-machine communication? How to perform such communication? What should be communicated between machines? By exposing underlying statistical and algorithmic characteristics unique to ML programs but not typically seen in traditional computer programs, and by dissecting successful cases to reveal how we have harnessed these principles to design and develop both high-performance distributed ML software as well as general-purpose ML frameworks, we present opportunities for ML researchers and practitioners to further shape and grow the area that lies between ML and systems.
Distributed Training of Deep Neural Networks with Theoretical Analysis: Under SSP Setting
Dec 11, 2015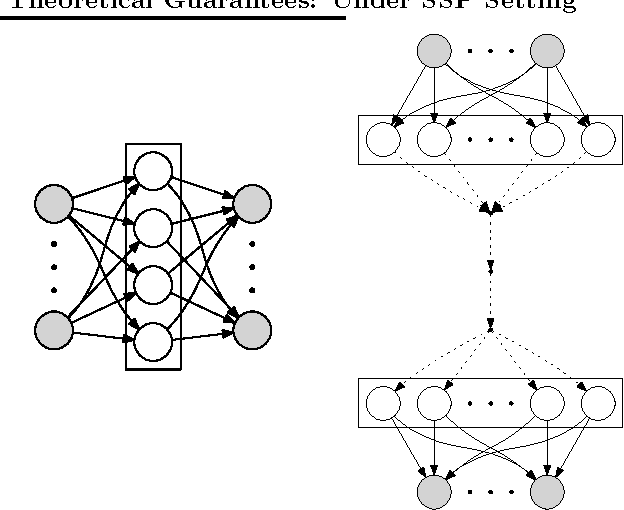

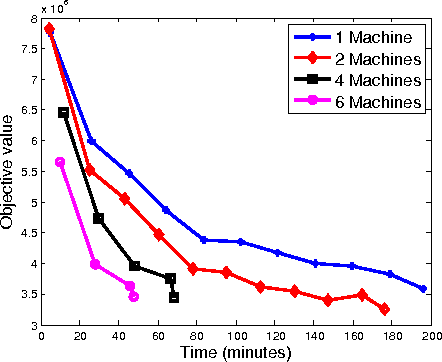
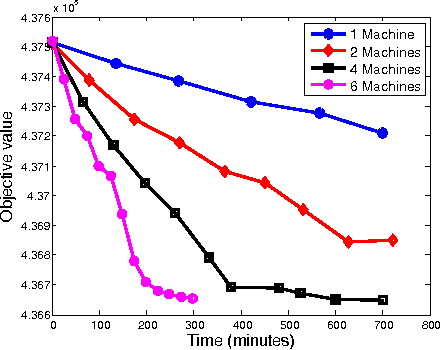
We propose a distributed approach to train deep neural networks (DNNs), which has guaranteed convergence theoretically and great scalability empirically: close to 6 times faster on instance of ImageNet data set when run with 6 machines. The proposed scheme is close to optimally scalable in terms of number of machines, and guaranteed to converge to the same optima as the undistributed setting. The convergence and scalability of the distributed setting is shown empirically across different datasets (TIMIT and ImageNet) and machine learning tasks (image classification and phoneme extraction). The convergence analysis provides novel insights into this complex learning scheme, including: 1) layerwise convergence, and 2) convergence of the weights in probability.
Scalable Modeling of Conversational-role based Self-presentation Characteristics in Large Online Forums
Dec 10, 2015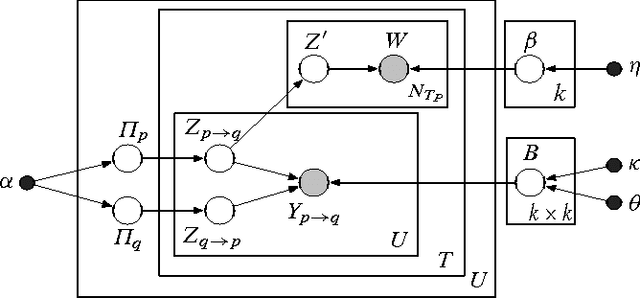
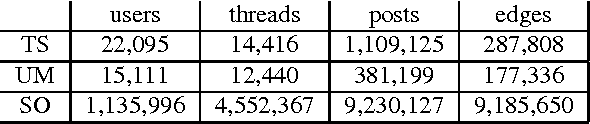
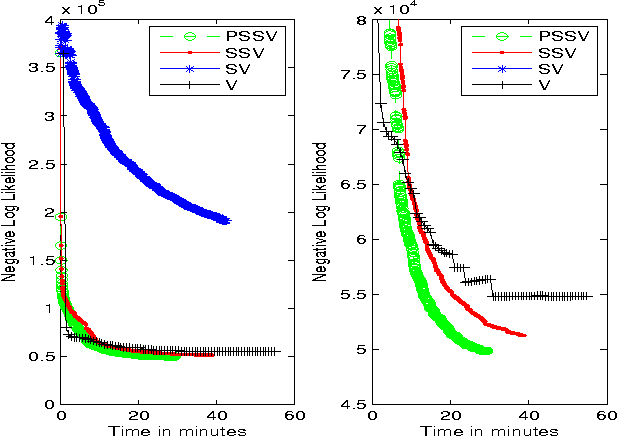
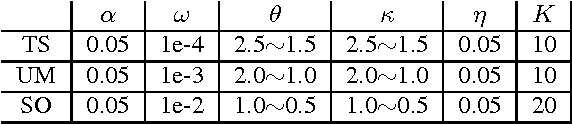
Online discussion forums are complex webs of overlapping subcommunities (macrolevel structure, across threads) in which users enact different roles depending on which subcommunity they are participating in within a particular time point (microlevel structure, within threads). This sub-network structure is implicit in massive collections of threads. To uncover this structure, we develop a scalable algorithm based on stochastic variational inference and leverage topic models (LDA) along with mixed membership stochastic block (MMSB) models. We evaluate our model on three large-scale datasets, Cancer-ThreadStarter (22K users and 14.4K threads), Cancer-NameMention(15.1K users and 12.4K threads) and StackOverFlow (1.19 million users and 4.55 million threads). Qualitatively, we demonstrate that our model can provide useful explanations of microlevel and macrolevel user presentation characteristics in different communities using the topics discovered from posts. Quantitatively, we show that our model does better than MMSB and LDA in predicting user reply structure within threads. In addition, we demonstrate via synthetic data experiments that the proposed active sub-network discovery model is stable and recovers the original parameters of the experimental setup with high probability.
The Human Kernel
Dec 03, 2015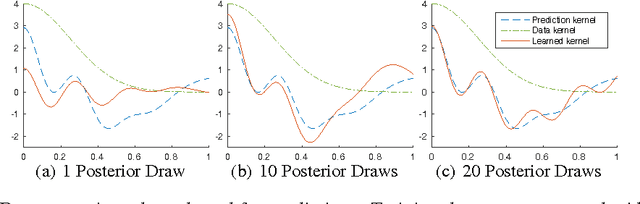
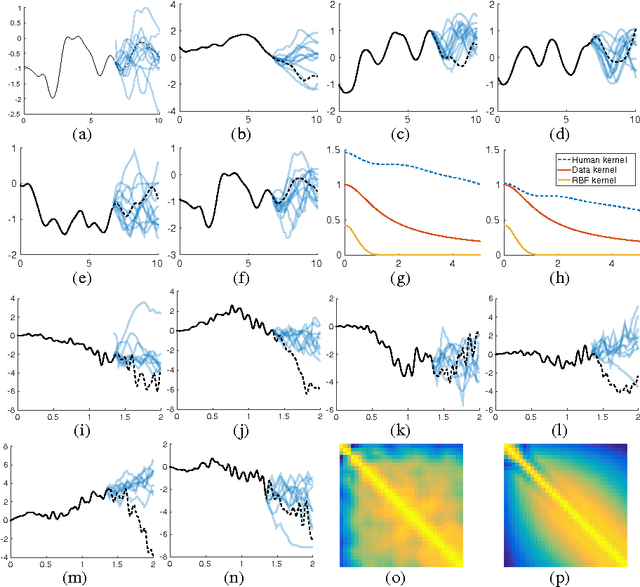
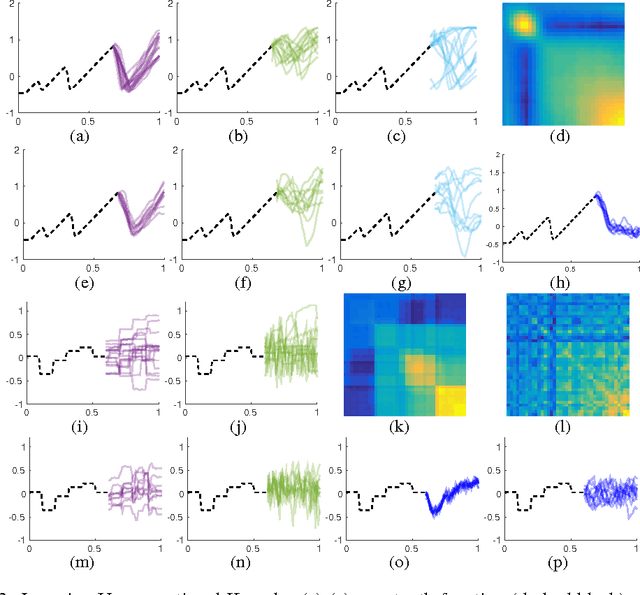
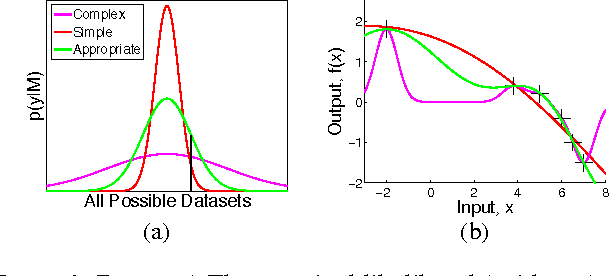
Bayesian nonparametric models, such as Gaussian processes, provide a compelling framework for automatic statistical modelling: these models have a high degree of flexibility, and automatically calibrated complexity. However, automating human expertise remains elusive; for example, Gaussian processes with standard kernels struggle on function extrapolation problems that are trivial for human learners. In this paper, we create function extrapolation problems and acquire human responses, and then design a kernel learning framework to reverse engineer the inductive biases of human learners across a set of behavioral experiments. We use the learned kernels to gain psychological insights and to extrapolate in human-like ways that go beyond traditional stationary and polynomial kernels. Finally, we investigate Occam's razor in human and Gaussian process based function learning.
Deep Kernel Learning
Nov 06, 2015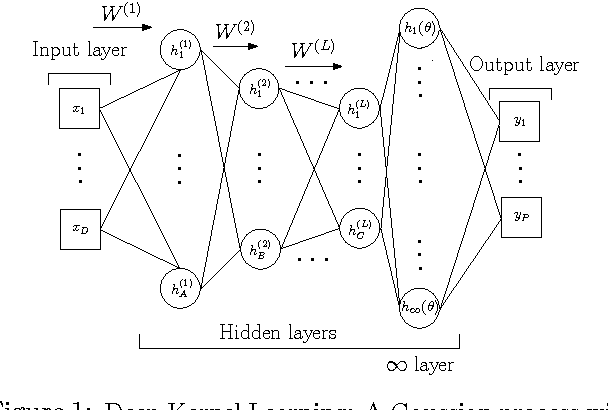
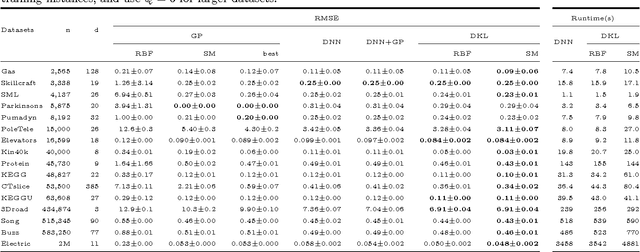


We introduce scalable deep kernels, which combine the structural properties of deep learning architectures with the non-parametric flexibility of kernel methods. Specifically, we transform the inputs of a spectral mixture base kernel with a deep architecture, using local kernel interpolation, inducing points, and structure exploiting (Kronecker and Toeplitz) algebra for a scalable kernel representation. These closed-form kernels can be used as drop-in replacements for standard kernels, with benefits in expressive power and scalability. We jointly learn the properties of these kernels through the marginal likelihood of a Gaussian process. Inference and learning cost $O(n)$ for $n$ training points, and predictions cost $O(1)$ per test point. On a large and diverse collection of applications, including a dataset with 2 million examples, we show improved performance over scalable Gaussian processes with flexible kernel learning models, and stand-alone deep architectures.
Petuum: A New Platform for Distributed Machine Learning on Big Data
May 14, 2015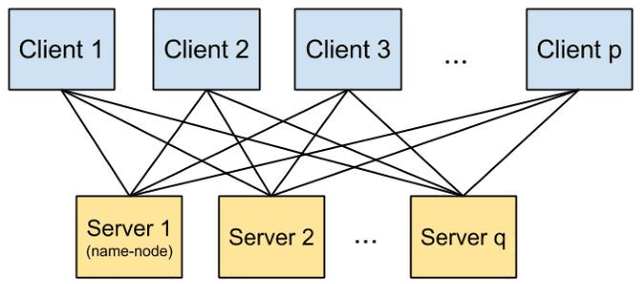
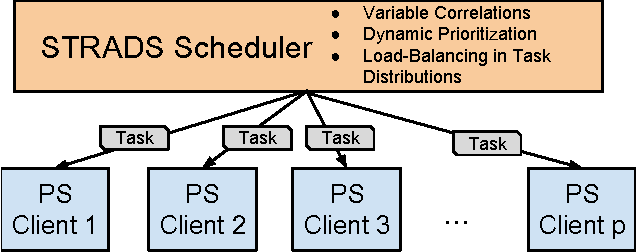
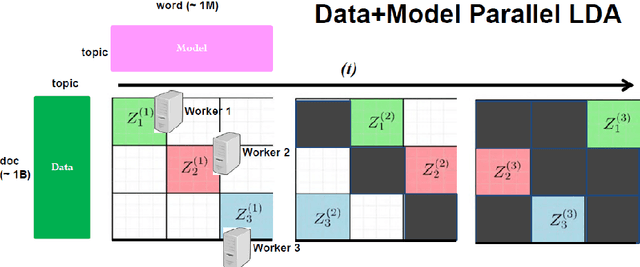
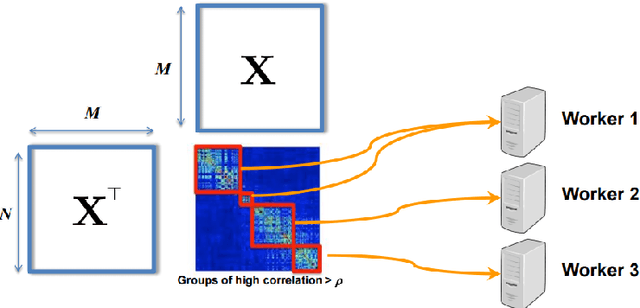
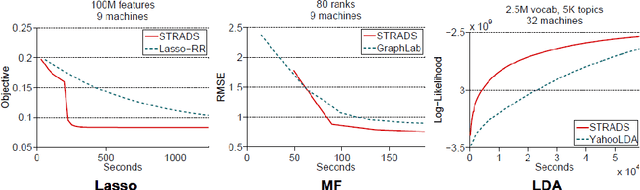
What is a systematic way to efficiently apply a wide spectrum of advanced ML programs to industrial scale problems, using Big Models (up to 100s of billions of parameters) on Big Data (up to terabytes or petabytes)? Modern parallelization strategies employ fine-grained operations and scheduling beyond the classic bulk-synchronous processing paradigm popularized by MapReduce, or even specialized graph-based execution that relies on graph representations of ML programs. The variety of approaches tends to pull systems and algorithms design in different directions, and it remains difficult to find a universal platform applicable to a wide range of ML programs at scale. We propose a general-purpose framework that systematically addresses data- and model-parallel challenges in large-scale ML, by observing that many ML programs are fundamentally optimization-centric and admit error-tolerant, iterative-convergent algorithmic solutions. This presents unique opportunities for an integrative system design, such as bounded-error network synchronization and dynamic scheduling based on ML program structure. We demonstrate the efficacy of these system designs versus well-known implementations of modern ML algorithms, allowing ML programs to run in much less time and at considerably larger model sizes, even on modestly-sized compute clusters.
LightLDA: Big Topic Models on Modest Compute Clusters
Dec 04, 2014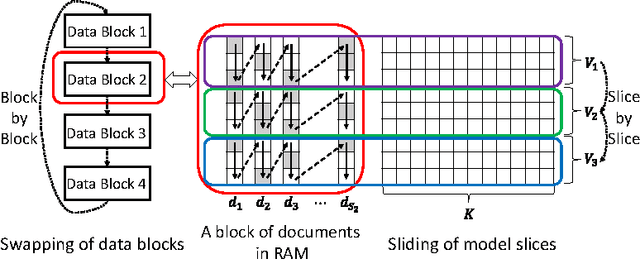

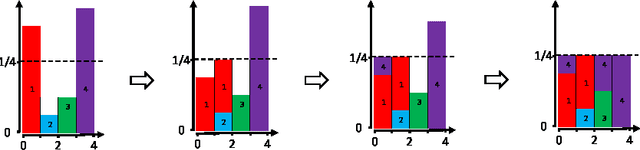
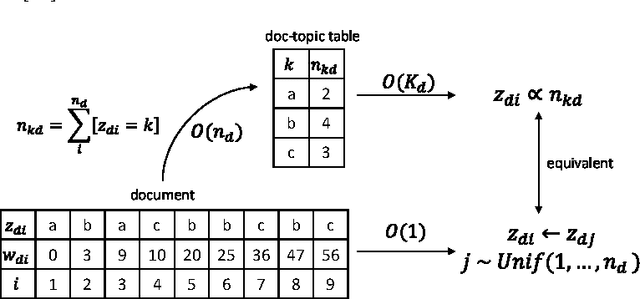
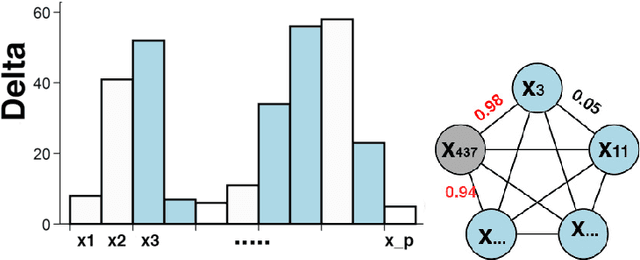
When building large-scale machine learning (ML) programs, such as big topic models or deep neural nets, one usually assumes such tasks can only be attempted with industrial-sized clusters with thousands of nodes, which are out of reach for most practitioners or academic researchers. We consider this challenge in the context of topic modeling on web-scale corpora, and show that with a modest cluster of as few as 8 machines, we can train a topic model with 1 million topics and a 1-million-word vocabulary (for a total of 1 trillion parameters), on a document collection with 200 billion tokens -- a scale not yet reported even with thousands of machines. Our major contributions include: 1) a new, highly efficient O(1) Metropolis-Hastings sampling algorithm, whose running cost is (surprisingly) agnostic of model size, and empirically converges nearly an order of magnitude faster than current state-of-the-art Gibbs samplers; 2) a structure-aware model-parallel scheme, which leverages dependencies within the topic model, yielding a sampling strategy that is frugal on machine memory and network communication; 3) a differential data-structure for model storage, which uses separate data structures for high- and low-frequency words to allow extremely large models to fit in memory, while maintaining high inference speed; and 4) a bounded asynchronous data-parallel scheme, which allows efficient distributed processing of massive data via a parameter server. Our distribution strategy is an instance of the model-and-data-parallel programming model underlying the Petuum framework for general distributed ML, and was implemented on top of the Petuum open-source system. We provide experimental evidence showing how this development puts massive models within reach on a small cluster while still enjoying proportional time cost reductions with increasing cluster size, in comparison with alternative options.
Diffusion of Lexical Change in Social Media
Nov 24, 2014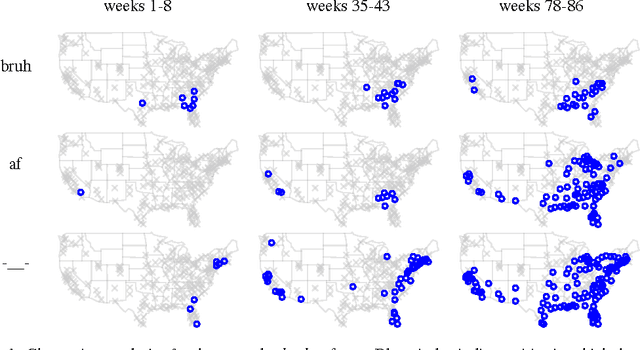

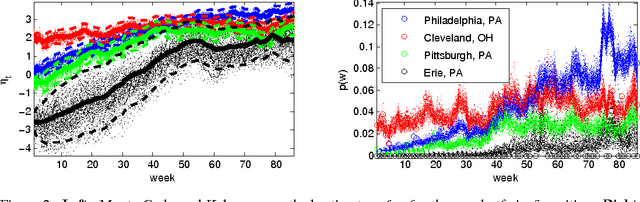

Computer-mediated communication is driving fundamental changes in the nature of written language. We investigate these changes by statistical analysis of a dataset comprising 107 million Twitter messages (authored by 2.7 million unique user accounts). Using a latent vector autoregressive model to aggregate across thousands of words, we identify high-level patterns in diffusion of linguistic change over the United States. Our model is robust to unpredictable changes in Twitter's sampling rate, and provides a probabilistic characterization of the relationship of macro-scale linguistic influence to a set of demographic and geographic predictors. The results of this analysis offer support for prior arguments that focus on geographical proximity and population size. However, demographic similarity -- especially with regard to race -- plays an even more central role, as cities with similar racial demographics are far more likely to share linguistic influence. Rather than moving towards a single unified "netspeak" dialect, language evolution in computer-mediated communication reproduces existing fault lines in spoken American English.
Model-Parallel Inference for Big Topic Models
Nov 10, 2014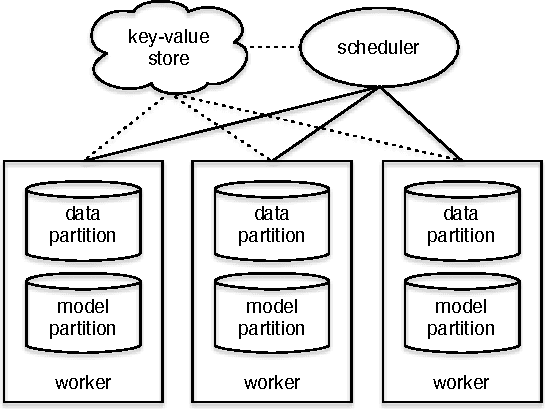

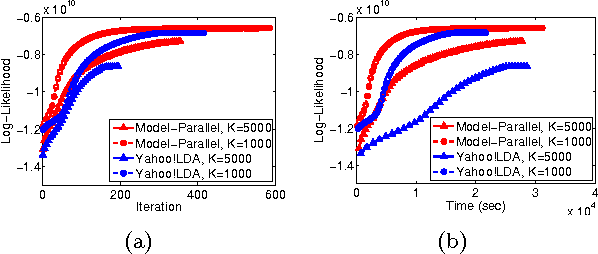
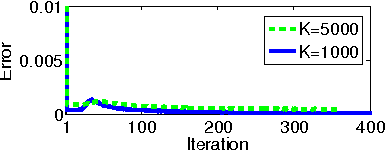
In real world industrial applications of topic modeling, the ability to capture gigantic conceptual space by learning an ultra-high dimensional topical representation, i.e., the so-called "big model", is becoming the next desideratum after enthusiasms on "big data", especially for fine-grained downstream tasks such as online advertising, where good performances are usually achieved by regression-based predictors built on millions if not billions of input features. The conventional data-parallel approach for training gigantic topic models turns out to be rather inefficient in utilizing the power of parallelism, due to the heavy dependency on a centralized image of "model". Big model size also poses another challenge on the storage, where available model size is bounded by the smallest RAM of nodes. To address these issues, we explore another type of parallelism, namely model-parallelism, which enables training of disjoint blocks of a big topic model in parallel. By integrating data-parallelism with model-parallelism, we show that dependencies between distributed elements can be handled seamlessly, achieving not only faster convergence but also an ability to tackle significantly bigger model size. We describe an architecture for model-parallel inference of LDA, and present a variant of collapsed Gibbs sampling algorithm tailored for it. Experimental results demonstrate the ability of this system to handle topic modeling with unprecedented amount of 200 billion model variables only on a low-end cluster with very limited computational resources and bandwidth.
High-Performance Distributed ML at Scale through Parameter Server Consistency Models
Oct 29, 2014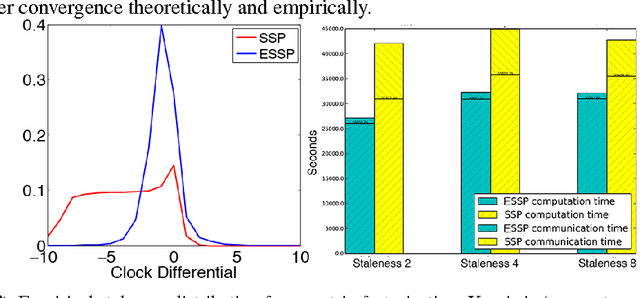
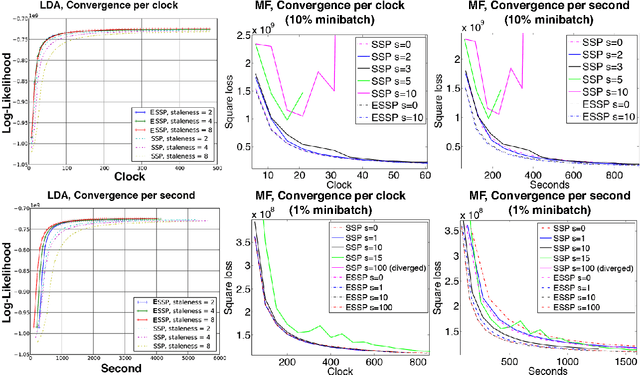
As Machine Learning (ML) applications increase in data size and model complexity, practitioners turn to distributed clusters to satisfy the increased computational and memory demands. Unfortunately, effective use of clusters for ML requires considerable expertise in writing distributed code, while highly-abstracted frameworks like Hadoop have not, in practice, approached the performance seen in specialized ML implementations. The recent Parameter Server (PS) paradigm is a middle ground between these extremes, allowing easy conversion of single-machine parallel ML applications into distributed ones, while maintaining high throughput through relaxed "consistency models" that allow inconsistent parameter reads. However, due to insufficient theoretical study, it is not clear which of these consistency models can really ensure correct ML algorithm output; at the same time, there remain many theoretically-motivated but undiscovered opportunities to maximize computational throughput. Motivated by this challenge, we study both the theoretical guarantees and empirical behavior of iterative-convergent ML algorithms in existing PS consistency models. We then use the gleaned insights to improve a consistency model using an "eager" PS communication mechanism, and implement it as a new PS system that enables ML algorithms to reach their solution more quickly.