 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEric Michael Smith
Multi-Modal Open-Domain Dialogue
Oct 02, 2020

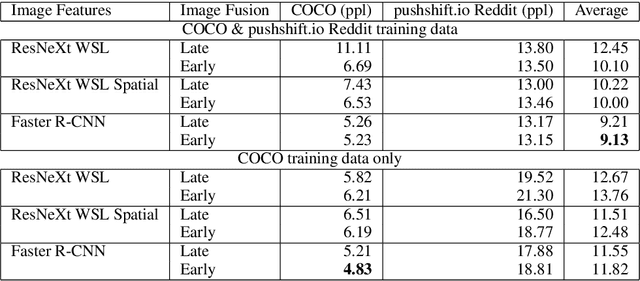
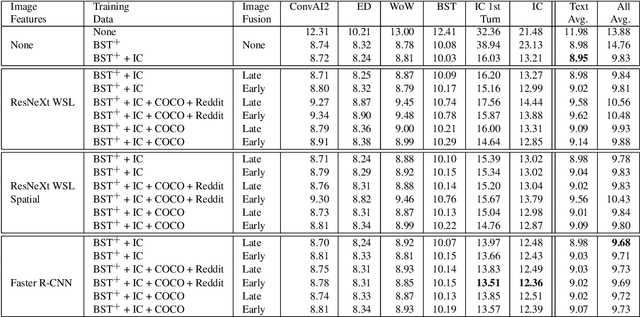

Recent work in open-domain conversational agents has demonstrated that significant improvements in model engagingness and humanness metrics can be achieved via massive scaling in both pre-training data and model size (Adiwardana et al., 2020; Roller et al., 2020). However, if we want to build agents with human-like abilities, we must expand beyond handling just text. A particularly important topic is the ability to see images and communicate about what is perceived. With the goal of engaging humans in multi-modal dialogue, we investigate combining components from state-of-the-art open-domain dialogue agents with those from state-of-the-art vision models. We study incorporating different image fusion schemes and domain-adaptive pre-training and fine-tuning strategies, and show that our best resulting model outperforms strong existing models in multi-modal dialogue while simultaneously performing as well as its predecessor (text-only) BlenderBot (Roller et al., 2020) in text-based conversation. We additionally investigate and incorporate safety components in our final model, and show that such efforts do not diminish model performance with respect to engagingness metrics.
Controlling Style in Generated Dialogue
Sep 22, 2020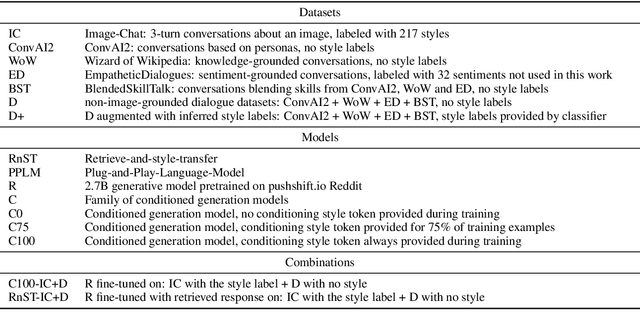
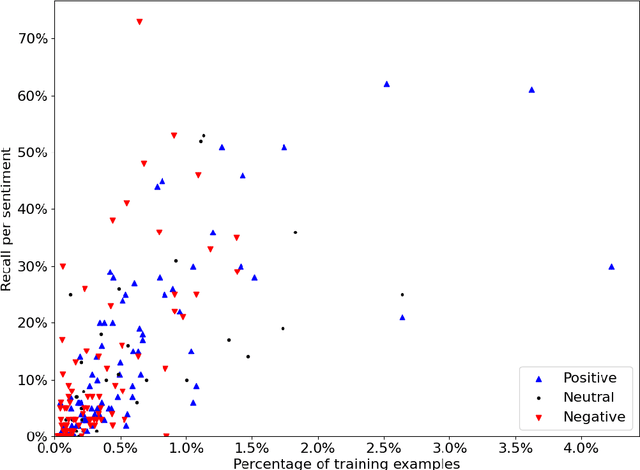
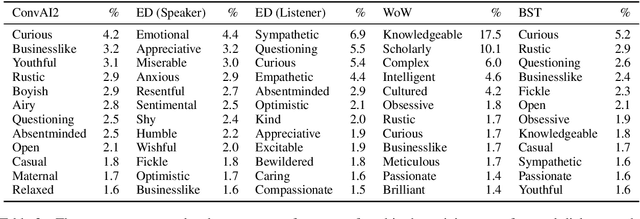
Open-domain conversation models have become good at generating natural-sounding dialogue, using very large architectures with billions of trainable parameters. The vast training data required to train these architectures aggregates many different styles, tones, and qualities. Using that data to train a single model makes it difficult to use the model as a consistent conversational agent, e.g. with a stable set of persona traits and a typical style of expression. Several architectures affording control mechanisms over generation architectures have been proposed, each with different trade-offs. However, it remains unclear whether their use in dialogue is viable, and what the trade-offs look like with the most recent state-of-the-art conversational architectures. In this work, we adapt three previously proposed controllable generation architectures to open-domain dialogue generation, controlling the style of the generation to match one among about 200 possible styles. We compare their respective performance and tradeoffs, and show how they can be used to provide insights into existing conversational datasets, and generate a varied set of styled conversation replies.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.
Can You Put it All Together: Evaluating Conversational Agents' Ability to Blend Skills
Apr 17, 2020

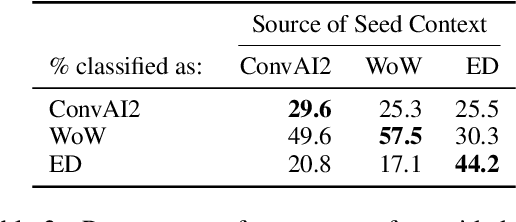
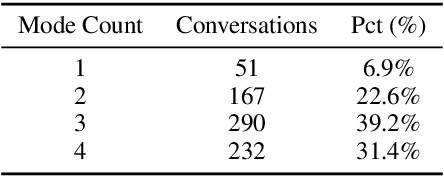
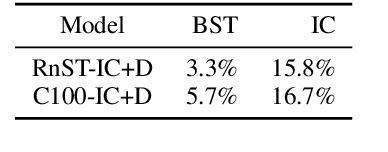
Being engaging, knowledgeable, and empathetic are all desirable general qualities in a conversational agent. Previous work has introduced tasks and datasets that aim to help agents to learn those qualities in isolation and gauge how well they can express them. But rather than being specialized in one single quality, a good open-domain conversational agent should be able to seamlessly blend them all into one cohesive conversational flow. In this work, we investigate several ways to combine models trained towards isolated capabilities, ranging from simple model aggregation schemes that require minimal additional training, to various forms of multi-task training that encompass several skills at all training stages. We further propose a new dataset, BlendedSkillTalk, to analyze how these capabilities would mesh together in a natural conversation, and compare the performance of different architectures and training schemes. Our experiments show that multi-tasking over several tasks that focus on particular capabilities results in better blended conversation performance compared to models trained on a single skill, and that both unified or two-stage approaches perform well if they are constructed to avoid unwanted bias in skill selection or are fine-tuned on our new task.
Zero-Shot Fine-Grained Style Transfer: Leveraging Distributed Continuous Style Representations to Transfer To Unseen Styles
Nov 10, 2019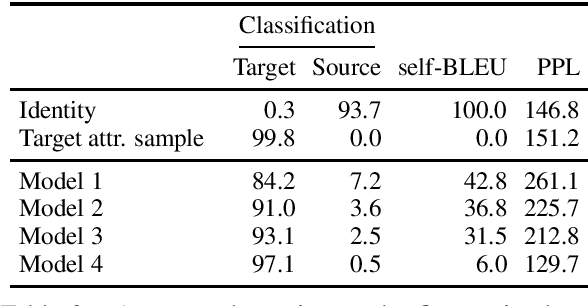

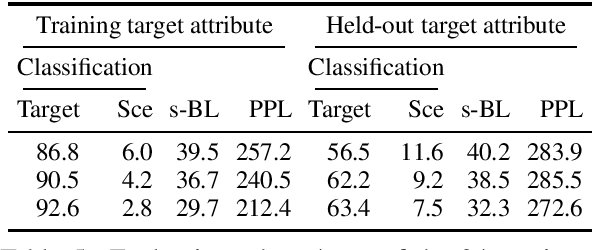

Text style transfer is usually performed using attributes that can take a handful of discrete values (e.g., positive to negative reviews). In this work, we introduce an architecture that can leverage pre-trained consistent continuous distributed style representations and use them to transfer to an attribute unseen during training, without requiring any re-tuning of the style transfer model. We demonstrate the method by training an architecture to transfer text conveying one sentiment to another sentiment, using a fine-grained set of over 20 sentiment labels rather than the binary positive/negative often used in style transfer. Our experiments show that this model can then rewrite text to match a target sentiment that was unseen during training.
Multiple-Attribute Text Style Transfer
Nov 01, 2018
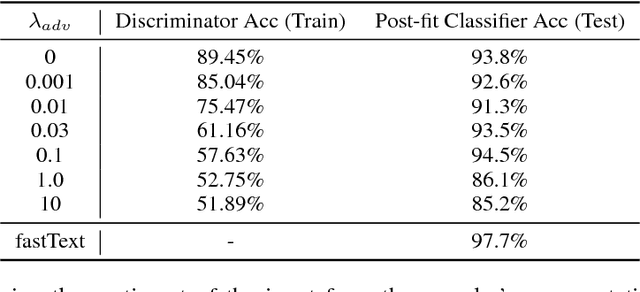
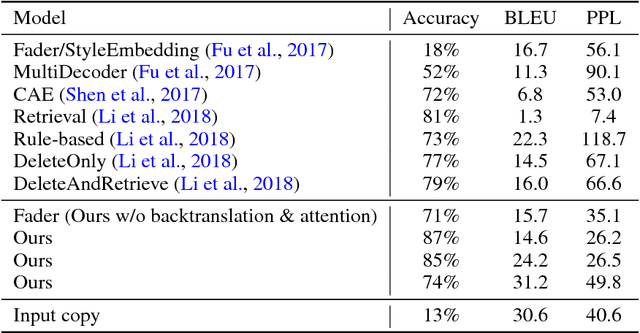
The dominant approach to unsupervised "style transfer" in text is based on the idea of learning a latent representation, which is independent of the attributes specifying its "style". In this paper, we show that this condition is not necessary and is not always met in practice, even with domain adversarial training that explicitly aims at learning such disentangled representations. We thus propose a new model that controls several factors of variation in textual data where this condition on disentanglement is replaced with a simpler mechanism based on back-translation. Our method allows control over multiple attributes, like gender, sentiment, product type, etc., and a more fine-grained control on the trade-off between content preservation and change of style with a pooling operator in the latent space. Our experiments demonstrate that the fully entangled model produces better generations, even when tested on new and more challenging benchmarks comprising reviews with multiple sentences and multiple attributes.
I Know the Feeling: Learning to Converse with Empathy
Nov 01, 2018
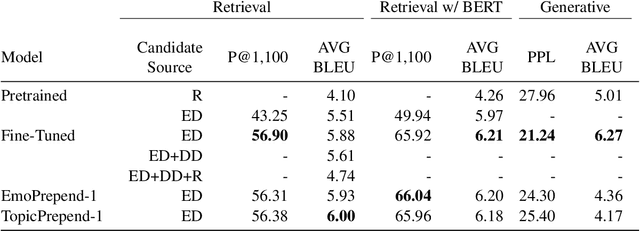


Beyond understanding what is being discussed, human communication requires an awareness of what someone is feeling. One challenge for dialogue agents is being able to recognize feelings in the conversation partner and reply accordingly, a key communicative skill that is trivial for humans. Research in this area is made difficult by the paucity of large-scale publicly available datasets both for emotion and relevant dialogues. This work proposes a new task for empathetic dialogue generation and EmpatheticDialogues, a dataset of 25k conversations grounded in emotional contexts to facilitate training and evaluating dialogue systems. Our experiments indicate that models explicitly leveraging emotion predictions from previous utterances are perceived to be more empathetic by human evaluators, while improving on other metrics as well (e.g. perceived relevance of responses, BLEU scores).