 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlashCP: Load-Balanced Communication-Efficient Context Parallelism for LLM Training
Jun 07, 2026Context parallelism (CP) is essential for training large-scale, long-context language models, as it partitions sequences to reduce memory overhead. However, existing CP methods suffer from workload imbalance, inefficient kernels, and redundant communication due to static sequence sharding and key-value (KV) tensor communication. We present FlashCP, a load-balanced and communication-efficient framework for CP training. FlashCP introduces a sharding-aware communication mechanism to eliminate redundant KV communication and proposes a novel Whole-Doc sharding strategy that maximizes communication savings while maintaining balanced workloads. To efficiently combine Whole-Doc and Per-Doc sharding, FlashCP further designs a heuristic algorithm to search for near-optimal sharding plans. Extensive experiments show that FlashCP achieves up to 1.63x speedup over state-of-the-art CP frameworks across diverse datasets.
MLLMs Know When Before Speaking: Revealing and Recovering Temporal Grounding via Attention Cues
May 21, 2026Video temporal grounding (VTG), which localizes the start and end times of a queried event in an untrimmed video, is a key test of whether multimodal large language models (MLLMs) understand not only what happens but also when it happens. Although modern MLLMs describe video content fluently, their timestamp predictions remain unreliable, while existing remedies either require costly post-training on temporal annotations or rely on coarse training-free heuristics. In this work, we probe the cross-modal attention of MLLMs and uncover a perception-generation gap. Our key finding is that MLLMs often know the target interval during prefill, but lose this signal when generating the final answer. In the prefill stage, a sparse set of attention heads, which we call \emph{Temporal Grounding Heads} (TG-Heads), concentrates query-to-video attention on the ground-truth interval. During autoregressive decoding, however, the answer tokens shift attention away from this interval toward visually salient but query-irrelevant segments. This observation motivates an inference-time read-then-regenerate framework. We first convert TG-Head prefill attention into a debiased frame-level relevance signal and extract the high-attention interval it highlights. We then re-invoke the MLLM with visual context restricted to this interval, using video cropping or attention masking to suppress distractors. Without parameter updates and architectural changes, our framework consistently improves MiMo-VL-7B, Qwen3-VL-8B, and TimeLens-8B on three VTG benchmarks, with gains of up to +3.5 mIoU. The project website can be found at https://ddz16.github.io/mllmsknowwhen.github.io/.
Learning Spatiotemporal Sensitivity in Video LLMs via Counterfactual Reinforcement Learning
May 21, 2026Video large language models (Video LLMs) achieve strong benchmark accuracy, yet often answer video questions through shortcuts such as single-frame cues and language priors rather than by tracking spatiotemporal dynamics. This issue is exacerbated in RL post-training, where correctness-only rewards can further reinforce shortcut policies that obtain high reward without tracking video dynamics. We address this by asking a controlled counterfactual question: if the visual world changed while the question remained fixed, should the answer change or stay the same? Based on this view, we propose \textbf{Counterfactual Relational Policy Optimization (CRPO)}, a dual-branch RL framework for improving \emph{spatiotemporal sensitivity}. CRPO constructs counterfactual videos through horizontal flips and temporal reversals, trains on both original and counterfactual branches, and introduces a \textbf{Counterfactual Relation Reward (CRR)} between their answers. CRR encourages answers to change for dynamic questions and remain unchanged for static questions. This cross-branch constraint makes it difficult for shortcut policies to be consistently rewarded across both branches. To evaluate this property, we introduce \textbf{DyBench}, a paired counterfactual video benchmark with 3,014 videos covering reversible dynamics, moving direction, and event sequence, together with a strict pair-accuracy metric that prevents fixed-answer shortcuts from inflating scores. Experiments show that CRPO outperforms prior RL methods on spatiotemporal-sensitive evaluations while maintaining competitive general video performance. On Qwen3-VL-8B, CRPO improves DyBench P-Acc by +7.7 and TimeBlind I-Acc by +8.2 over the base model, indicating improved spatiotemporal sensitivity rather than stronger reliance on static shortcuts. The project website can be found at https://ddz16.github.io/crpo.github.io/ .
MARAGE: Transferable Multi-Model Adversarial Attack for Retrieval-Augmented Generation Data Extraction
Feb 05, 2025Retrieval-Augmented Generation (RAG) offers a solution to mitigate hallucinations in Large Language Models (LLMs) by grounding their outputs to knowledge retrieved from external sources. The use of private resources and data in constructing these external data stores can expose them to risks of extraction attacks, in which attackers attempt to steal data from these private databases. Existing RAG extraction attacks often rely on manually crafted prompts, which limit their effectiveness. In this paper, we introduce a framework called MARAGE for optimizing an adversarial string that, when appended to user queries submitted to a target RAG system, causes outputs containing the retrieved RAG data verbatim. MARAGE leverages a continuous optimization scheme that integrates gradients from multiple models with different architectures simultaneously to enhance the transferability of the optimized string to unseen models. Additionally, we propose a strategy that emphasizes the initial tokens in the target RAG data, further improving the attack's generalizability. Evaluations show that MARAGE consistently outperforms both manual and optimization-based baselines across multiple LLMs and RAG datasets, while maintaining robust transferability to previously unseen models. Moreover, we conduct probing tasks to shed light on the reasons why MARAGE is more effective compared to the baselines and to analyze the impact of our approach on the model's internal state.
ANVIL: Anomaly-based Vulnerability Identification without Labelled Training Data
Aug 28, 2024



Supervised learning-based software vulnerability detectors often fall short due to the inadequate availability of labelled training data. In contrast, Large Language Models (LLMs) such as GPT-4, are not trained on labelled data, but when prompted to detect vulnerabilities, LLM prediction accuracy is only marginally better than random guessing. In this paper, we explore a different approach by reframing vulnerability detection as one of anomaly detection. Since the vast majority of code does not contain vulnerabilities and LLMs are trained on massive amounts of such code, vulnerable code can be viewed as an anomaly from the LLM's predicted code distribution, freeing the model from the need for labelled data to provide a learnable representation of vulnerable code. Leveraging this perspective, we demonstrate that LLMs trained for code generation exhibit a significant gap in prediction accuracy when prompted to reconstruct vulnerable versus non-vulnerable code. Using this insight, we implement ANVIL, a detector that identifies software vulnerabilities at line-level granularity. Our experiments explore the discriminating power of different anomaly scoring methods, as well as the sensitivity of ANVIL to context size. We also study the effectiveness of ANVIL on various LLM families, and conduct leakage experiments on vulnerabilities that were discovered after the knowledge cutoff of our evaluated LLMs. On a collection of vulnerabilities from the Magma benchmark, ANVIL outperforms state-of-the-art line-level vulnerability detectors, LineVul and LineVD, which have been trained with labelled data, despite ANVIL having never been trained with labelled vulnerabilities. Specifically, our approach achieves $1.62\times$ to $2.18\times$ better Top-5 accuracies and $1.02\times$ to $1.29\times$ times better ROC scores on line-level vulnerability detection tasks.
MotionScript: Natural Language Descriptions for Expressive 3D Human Motions
Dec 19, 2023



This paper proposes MotionScript, a motion-to-text conversion algorithm and natural language representation for human body motions. MotionScript aims to describe movements in greater detail and with more accuracy than previous natural language approaches. Many motion datasets describe relatively objective and simple actions with little variation on the way they are expressed (e.g. sitting, walking, dribbling a ball). But for expressive actions that contain a diversity of movements in the class (e.g. being sad, dancing), or for actions outside the domain of standard motion capture datasets (e.g. stylistic walking, sign-language), more specific and granular natural language descriptions are needed. Our proposed MotionScript descriptions differ from existing natural language representations in that it provides direct descriptions in natural language instead of simple action labels or high-level human captions. To the best of our knowledge, this is the first attempt at translating 3D motions to natural language descriptions without requiring training data. Our experiments show that when MotionScript representations are used in a text-to-motion neural task, body movements are more accurately reconstructed, and large language models can be used to generate unseen complex motions.
Parallel Bayesian Global Optimization of Expensive Functions
Nov 01, 2017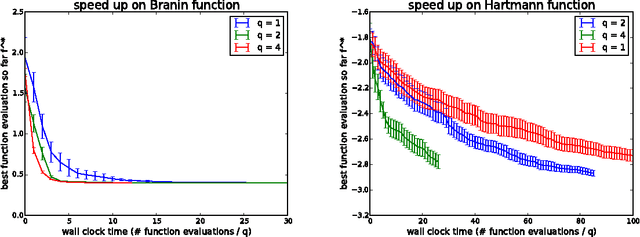
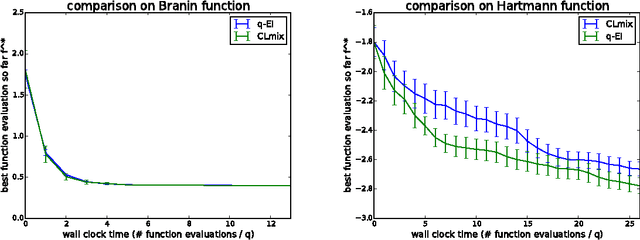
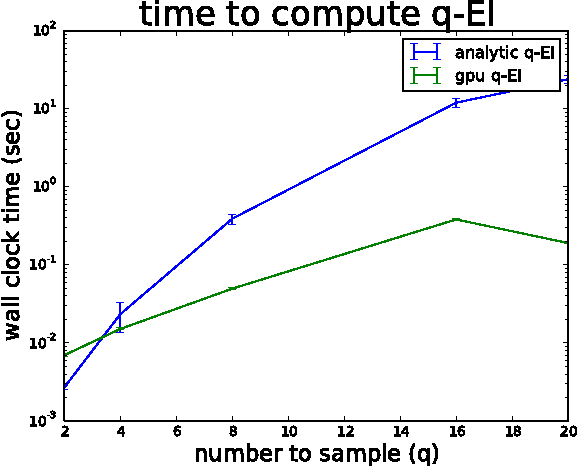
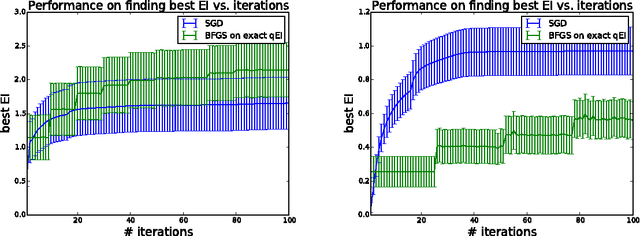
We consider parallel global optimization of derivative-free expensive-to-evaluate functions, and propose an efficient method based on stochastic approximation for implementing a conceptual Bayesian optimization algorithm proposed by Ginsbourger et al. (2007). To accomplish this, we use infinitessimal perturbation analysis (IPA) to construct a stochastic gradient estimator and show that this estimator is unbiased. We also show that the stochastic gradient ascent algorithm using the constructed gradient estimator converges to a stationary point of the q-EI surface, and therefore, as the number of multiple starts of the gradient ascent algorithm and the number of steps for each start grow large, the one-step Bayes optimal set of points is recovered. We show in numerical experiments that our method for maximizing the q-EI is faster than methods based on closed-form evaluation using high-dimensional integration, when considering many parallel function evaluations, and is comparable in speed when considering few. We also show that the resulting one-step Bayes optimal algorithm for parallel global optimization finds high quality solutions with fewer evaluations that a heuristic based on approximately maximizing the q-EI. A high quality open source implementation of this algorithm is available in the open source Metrics Optimization Engine (MOE).