 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEric Jang
Time-Contrastive Networks: Self-Supervised Learning from Video
Mar 20, 2018


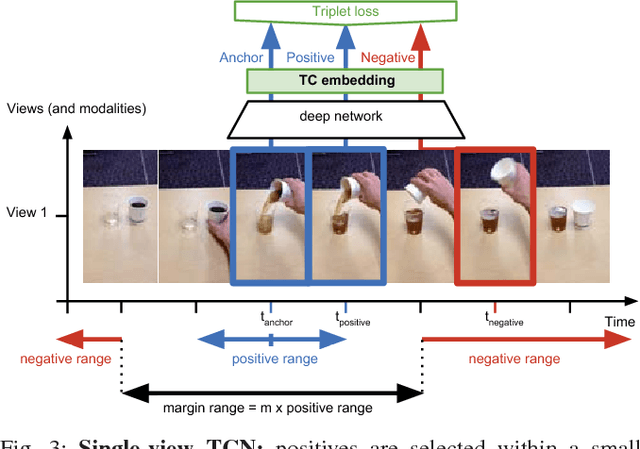
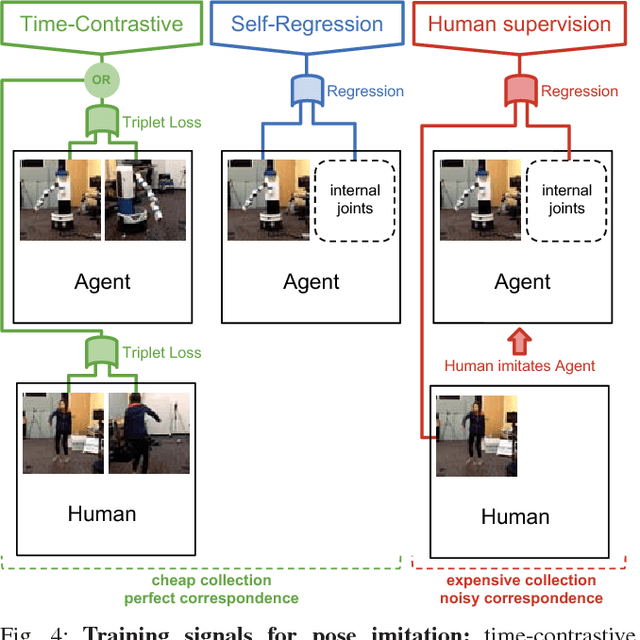
We propose a self-supervised approach for learning representations and robotic behaviors entirely from unlabeled videos recorded from multiple viewpoints, and study how this representation can be used in two robotic imitation settings: imitating object interactions from videos of humans, and imitating human poses. Imitation of human behavior requires a viewpoint-invariant representation that captures the relationships between end-effectors (hands or robot grippers) and the environment, object attributes, and body pose. We train our representations using a metric learning loss, where multiple simultaneous viewpoints of the same observation are attracted in the embedding space, while being repelled from temporal neighbors which are often visually similar but functionally different. In other words, the model simultaneously learns to recognize what is common between different-looking images, and what is different between similar-looking images. This signal causes our model to discover attributes that do not change across viewpoint, but do change across time, while ignoring nuisance variables such as occlusions, motion blur, lighting and background. We demonstrate that this representation can be used by a robot to directly mimic human poses without an explicit correspondence, and that it can be used as a reward function within a reinforcement learning algorithm. While representations are learned from an unlabeled collection of task-related videos, robot behaviors such as pouring are learned by watching a single 3rd-person demonstration by a human. Reward functions obtained by following the human demonstrations under the learned representation enable efficient reinforcement learning that is practical for real-world robotic systems. Video results, open-source code and dataset are available at https://sermanet.github.io/imitate
Sim2Real View Invariant Visual Servoing by Recurrent Control
Dec 20, 2017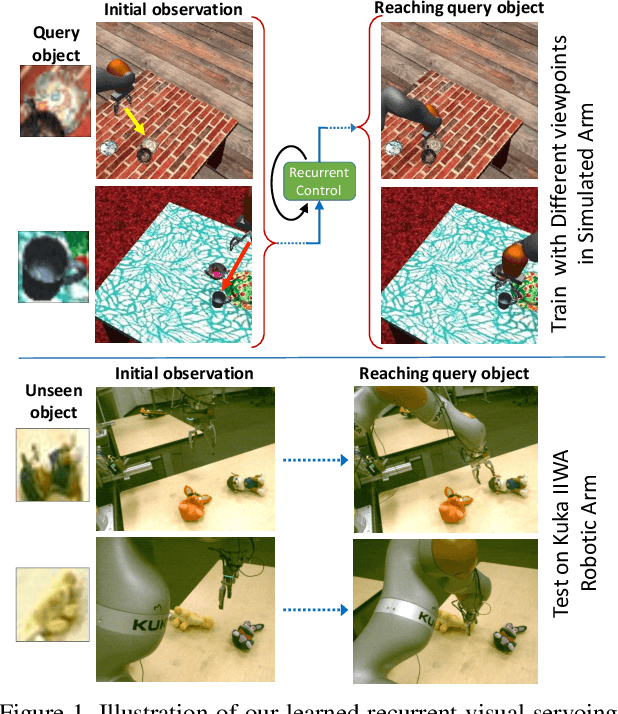
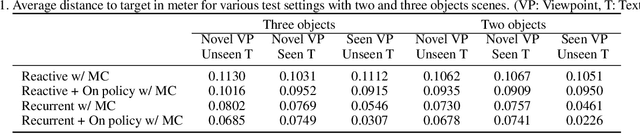
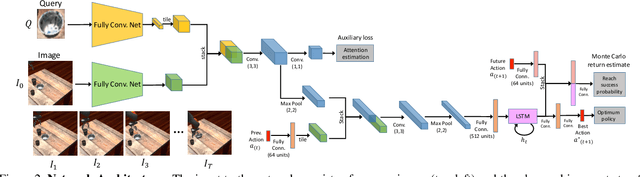
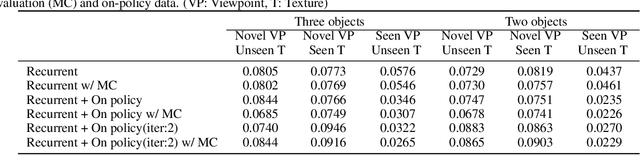
Humans are remarkably proficient at controlling their limbs and tools from a wide range of viewpoints and angles, even in the presence of optical distortions. In robotics, this ability is referred to as visual servoing: moving a tool or end-point to a desired location using primarily visual feedback. In this paper, we study how viewpoint-invariant visual servoing skills can be learned automatically in a robotic manipulation scenario. To this end, we train a deep recurrent controller that can automatically determine which actions move the end-point of a robotic arm to a desired object. The problem that must be solved by this controller is fundamentally ambiguous: under severe variation in viewpoint, it may be impossible to determine the actions in a single feedforward operation. Instead, our visual servoing system must use its memory of past movements to understand how the actions affect the robot motion from the current viewpoint, correcting mistakes and gradually moving closer to the target. This ability is in stark contrast to most visual servoing methods, which either assume known dynamics or require a calibration phase. We show how we can learn this recurrent controller using simulated data and a reinforcement learning objective. We then describe how the resulting model can be transferred to a real-world robot by disentangling perception from control and only adapting the visual layers. The adapted model can servo to previously unseen objects from novel viewpoints on a real-world Kuka IIWA robotic arm. For supplementary videos, see: https://fsadeghi.github.io/Sim2RealViewInvariantServo
End-to-End Learning of Semantic Grasping
Nov 09, 2017
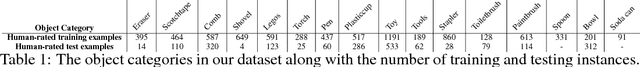
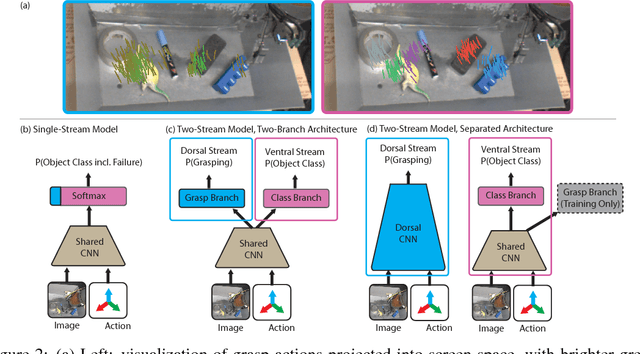
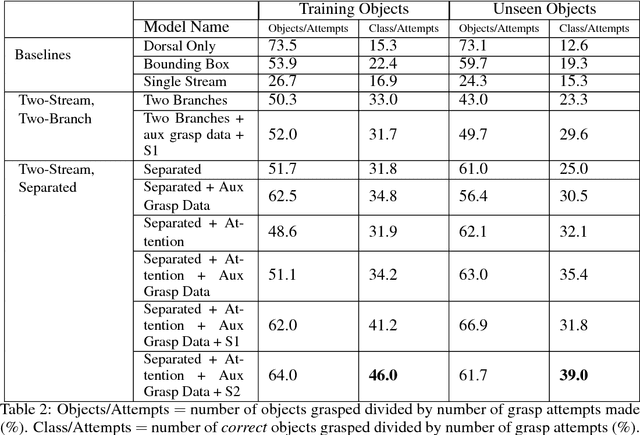
We consider the task of semantic robotic grasping, in which a robot picks up an object of a user-specified class using only monocular images. Inspired by the two-stream hypothesis of visual reasoning, we present a semantic grasping framework that learns object detection, classification, and grasp planning in an end-to-end fashion. A "ventral stream" recognizes object class while a "dorsal stream" simultaneously interprets the geometric relationships necessary to execute successful grasps. We leverage the autonomous data collection capabilities of robots to obtain a large self-supervised dataset for training the dorsal stream, and use semi-supervised label propagation to train the ventral stream with only a modest amount of human supervision. We experimentally show that our approach improves upon grasping systems whose components are not learned end-to-end, including a baseline method that uses bounding box detection. Furthermore, we show that jointly training our model with auxiliary data consisting of non-semantic grasping data, as well as semantically labeled images without grasp actions, has the potential to substantially improve semantic grasping performance.
Categorical Reparameterization with Gumbel-Softmax
Aug 05, 2017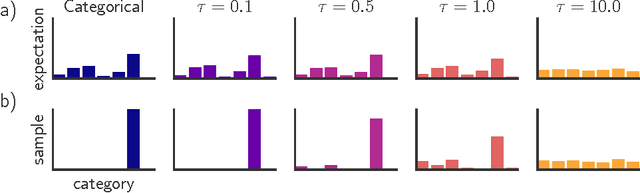

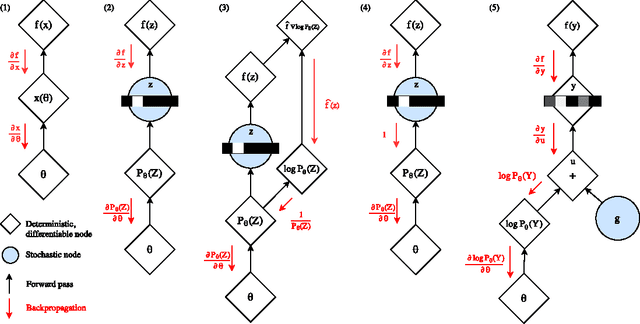
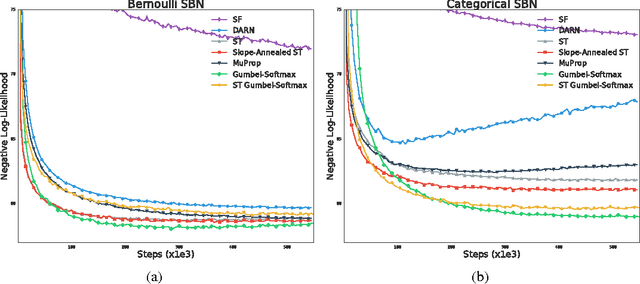
Categorical variables are a natural choice for representing discrete structure in the world. However, stochastic neural networks rarely use categorical latent variables due to the inability to backpropagate through samples. In this work, we present an efficient gradient estimator that replaces the non-differentiable sample from a categorical distribution with a differentiable sample from a novel Gumbel-Softmax distribution. This distribution has the essential property that it can be smoothly annealed into a categorical distribution. We show that our Gumbel-Softmax estimator outperforms state-of-the-art gradient estimators on structured output prediction and unsupervised generative modeling tasks with categorical latent variables, and enables large speedups on semi-supervised classification.