 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interspeech Zero Resource Speech Challenge 2021: Spoken language modelling
Apr 29, 2021
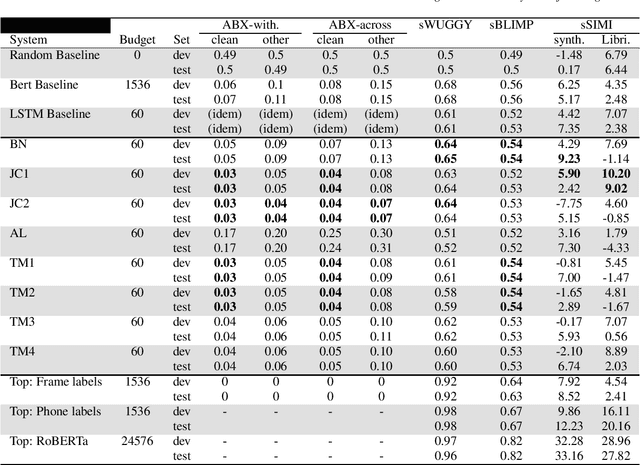
We present the Zero Resource Speech Challenge 2021, which asks participants to learn a language model directly from audio, without any text or labels. The challenge is based on the Libri-light dataset, which provides up to 60k hours of audio from English audio books without any associated text. We provide a pipeline baseline system consisting on an encoder based on contrastive predictive coding (CPC), a quantizer ($k$-means) and a standard language model (BERT or LSTM). The metrics evaluate the learned representations at the acoustic (ABX discrimination), lexical (spot-the-word), syntactic (acceptability judgment) and semantic levels (similarity judgment). We present an overview of the eight submitted systems from four groups and discuss the main results.
Speech Resynthesis from Discrete Disentangled Self-Supervised Representations
Apr 02, 2021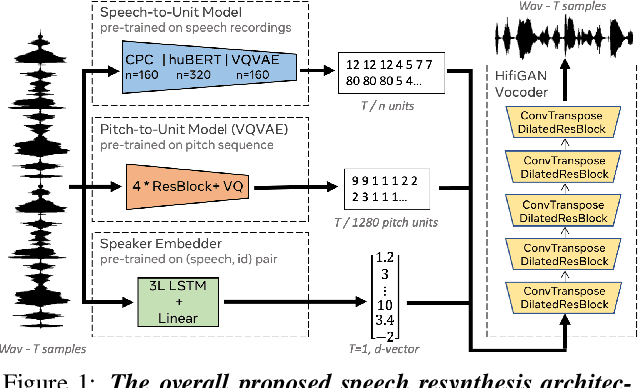
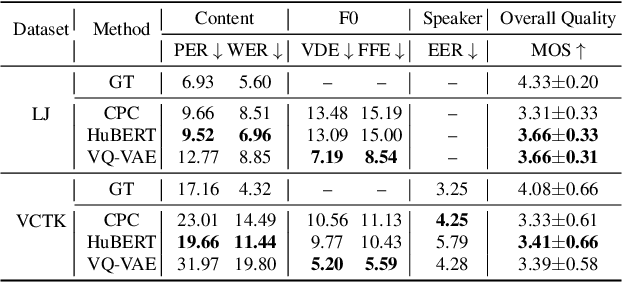
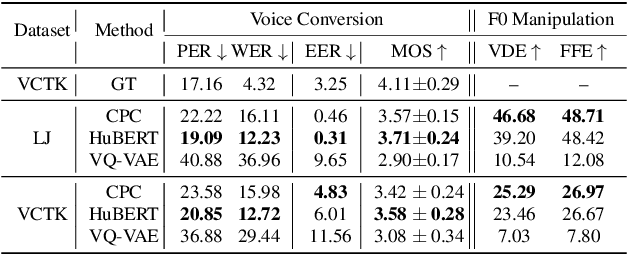
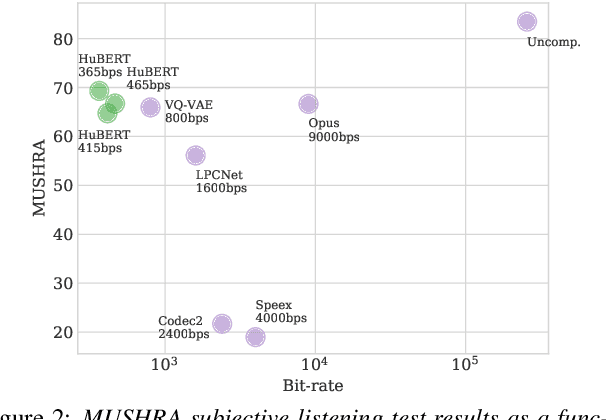
We propose using self-supervised discrete representations for the task of speech resynthesis. To generate disentangled representation, we separately extract low-bitrate representations for speech content, prosodic information, and speaker identity. This allows to synthesize speech in a controllable manner. We analyze various state-of-the-art, self-supervised representation learning methods and shed light on the advantages of each method while considering reconstruction quality and disentanglement properties. Specifically, we evaluate the F0 reconstruction, speaker identification performance (for both resynthesis and voice conversion), recordings' intelligibility, and overall quality using subjective human evaluation. Lastly, we demonstrate how these representations can be used for an ultra-lightweight speech codec. Using the obtained representations, we can get to a rate of 365 bits per second while providing better speech quality than the baseline methods. Audio samples can be found under https://resynthesis-ssl.github.io/.
Learning spectro-temporal representations of complex sounds with parameterized neural networks
Mar 12, 2021
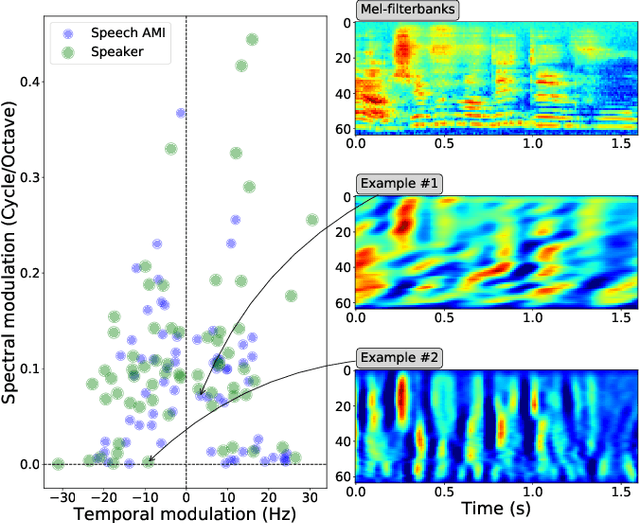


Deep Learning models have become potential candidates for auditory neuroscience research, thanks to their recent successes on a variety of auditory tasks. Yet, these models often lack interpretability to fully understand the exact computations that have been performed. Here, we proposed a parametrized neural network layer, that computes specific spectro-temporal modulations based on Gabor kernels (Learnable STRFs) and that is fully interpretable. We evaluated predictive capabilities of this layer on Speech Activity Detection, Speaker Verification, Urban Sound Classification and Zebra Finch Call Type Classification. We found out that models based on Learnable STRFs are on par for all tasks with different toplines, and obtain the best performance for Speech Activity Detection. As this layer is fully interpretable, we used quantitative measures to describe the distribution of the learned spectro-temporal modulations. The filters adapted to each task and focused mostly on low temporal and spectral modulations. The analyses show that the filters learned on human speech have similar spectro-temporal parameters as the ones measured directly in the human auditory cortex. Finally, we observed that the tasks organized in a meaningful way: the human vocalizations tasks closer to each other and bird vocalizations far away from human vocalizations and urban sounds tasks.
Generative Spoken Language Modeling from Raw Audio
Feb 01, 2021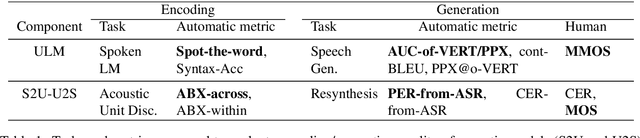
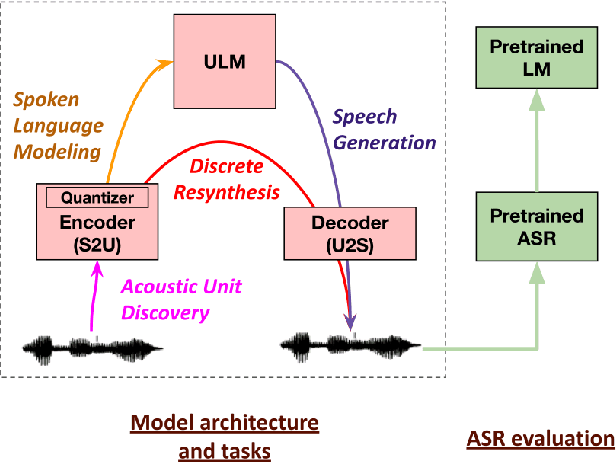
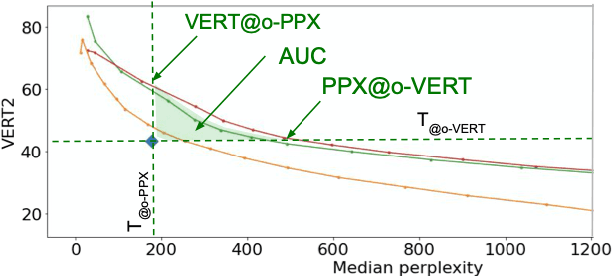
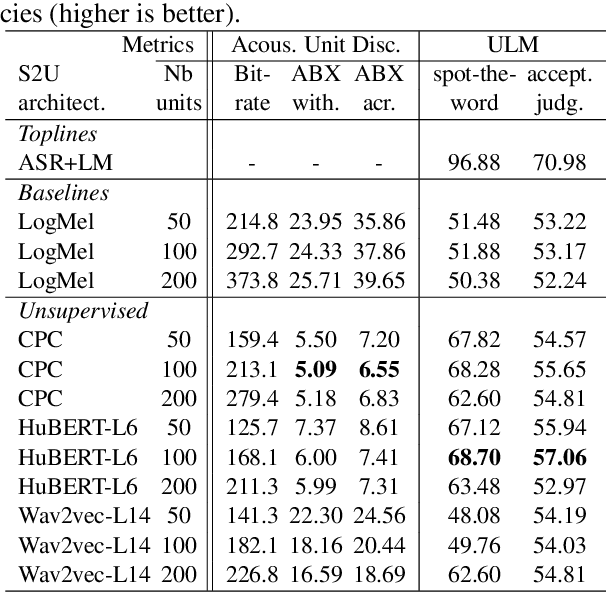
Generative spoken language modeling involves learning jointly the acoustic and linguistic characteristics of a language from raw audio only (without text or labels). We introduce metrics to automatically evaluate the generated output in terms of acoustic and linguistic quality in two associated end-to-end tasks, respectively: speech resynthesis (repeating the speech input using the system's own voice), and speech generation (producing novel speech outputs conditional on a spoken prompt, or unconditionally), and validate these metrics with human judgment. We test baseline systems consisting of a discrete speech encoder (returning discrete, low bitrate, pseudo-text units), a generative language model (trained on pseudo-text units), and a speech decoder (generating a waveform from pseudo-text). By comparing three state-of-the-art unsupervised speech encoders (Contrastive Predictive Coding (CPC), wav2vec 2.0, HuBERT), and varying the number of discrete units (50, 100, 200), we investigate how the generative performance depends on the quality of the learned units as measured by unsupervised metrics (zero-shot probe tasks). We will open source our evaluation stack and baseline models.
VoxPopuli: A Large-Scale Multilingual Speech Corpus for Representation Learning, Semi-Supervised Learning and Interpretation
Jan 02, 2021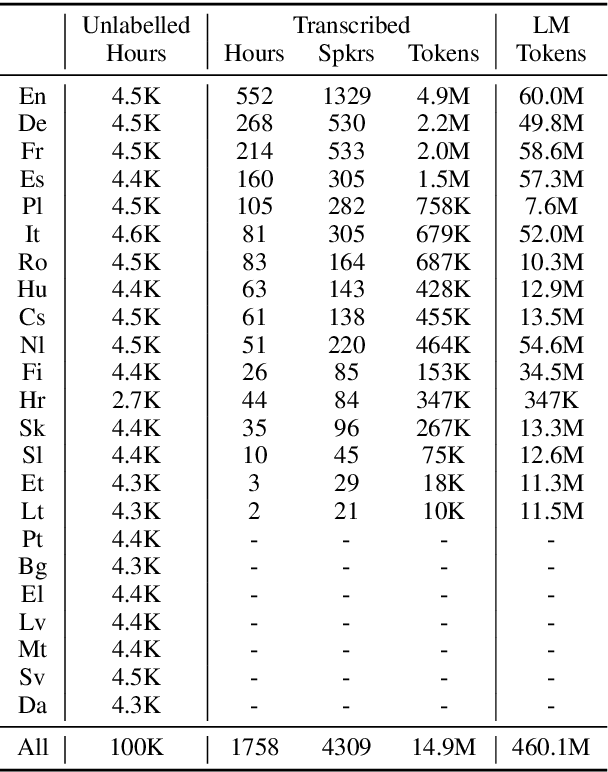
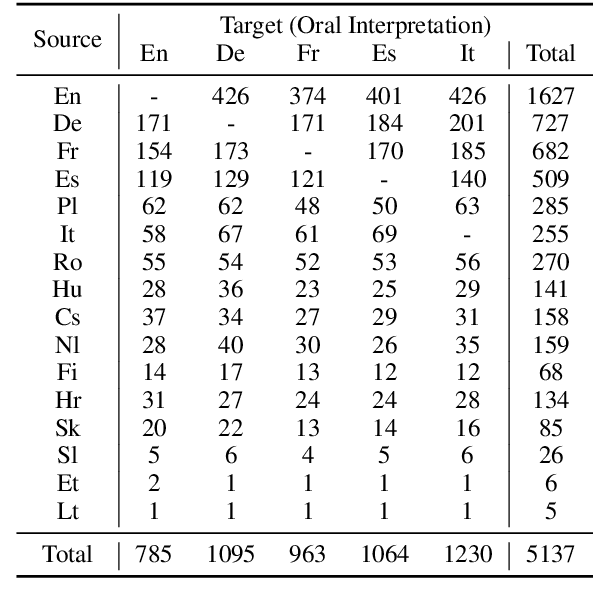

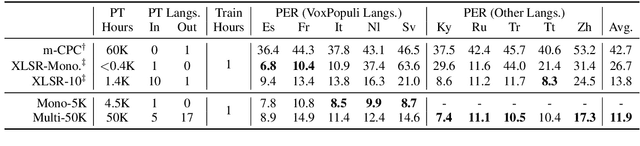
We introduce VoxPopuli, a large-scale multilingual corpus providing 100K hours of unlabelled speech data in 23 languages. It is the largest open data to date for unsupervised representation learning as well as semi-supervised learning. VoxPopuli also contains 1.8K hours of transcribed speeches in 16 languages and their aligned oral interpretations into 5 other languages totaling 5.1K hours. We provide speech recognition baselines and validate the versatility of VoxPopuli unlabelled data in semi-supervised learning under challenging out-of-domain settings. We will release the corpus at https://github.com/facebookresearch/voxpopuli under an open license.
The Zero Resource Speech Benchmark 2021: Metrics and baselines for unsupervised spoken language modeling
Dec 01, 2020


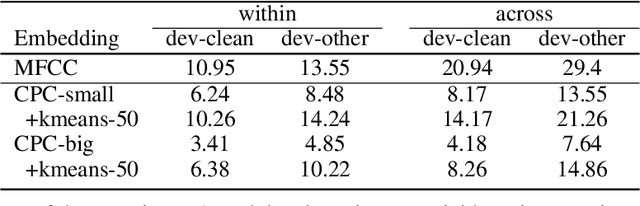
We introduce a new unsupervised task, spoken language modeling: the learning of linguistic representations from raw audio signals without any labels, along with the Zero Resource Speech Benchmark 2021: a suite of 4 black-box, zero-shot metrics probing for the quality of the learned models at 4 linguistic levels: phonetics, lexicon, syntax and semantics. We present the results and analyses of a composite baseline made of the concatenation of three unsupervised systems: self-supervised contrastive representation learning (CPC), clustering (k-means) and language modeling (LSTM or BERT). The language models learn on the basis of the pseudo-text derived from clustering the learned representations. This simple pipeline shows better than chance performance on all four metrics, demonstrating the feasibility of spoken language modeling from raw speech. It also yields worse performance compared to text-based 'topline' systems trained on the same data, delineating the space to be explored by more sophisticated end-to-end models.
Comparison of Speaker Role Recognition and Speaker Enrollment Protocol for conversational Clinical Interviews
Nov 05, 2020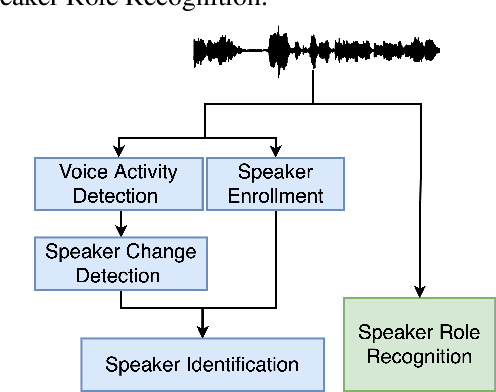
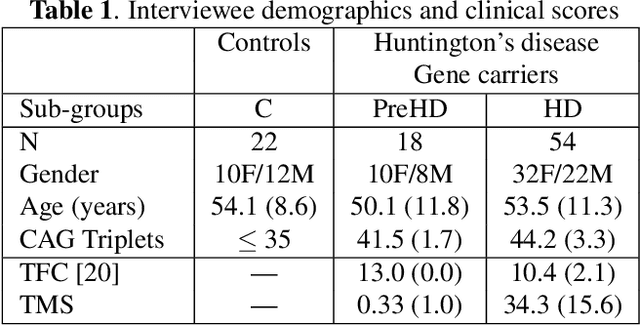
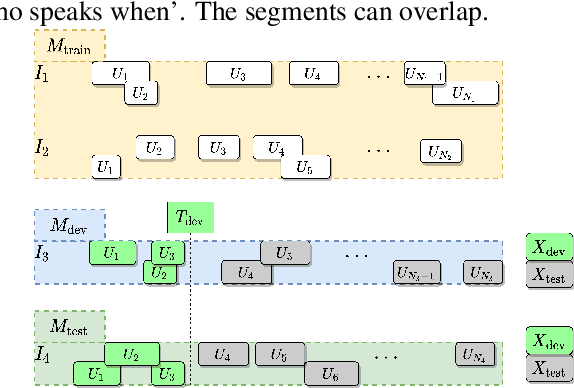
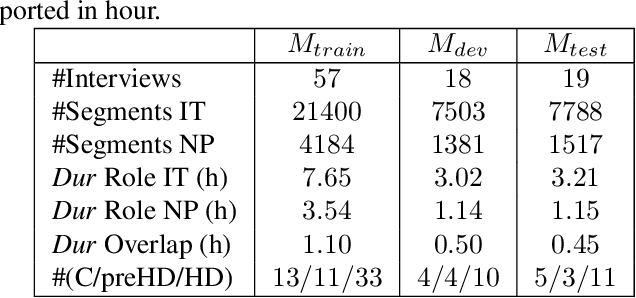
Conversations between a clinician and a patient, in natural conditions, are valuable sources of information for medical follow-up. The automatic analysis of these dialogues could help extract new language markers and speed-up the clinicians' reports. Yet, it is not clear which speech processing pipeline is the most performing to detect and identify the speaker turns, especially for individuals with speech and language disorders. Here, we proposed a split of the data that allows conducting a comparative evaluation of speaker role recognition and speaker enrollment methods to solve this task. We trained end-to-end neural network architectures to adapt to each task and evaluate each approach under the same metric. Experimental results are reported on naturalistic clinical conversations between Neuropsychologist and Interviewees, at different stages of Huntington's disease. We found that our Speaker Role Recognition model gave the best performances. In addition, our study underlined the importance of retraining models with in-domain data. Finally, we observed that results do not depend on the demographics of the Interviewee, highlighting the clinical relevance of our methods.
The Zero Resource Speech Challenge 2020: Discovering discrete subword and word units
Oct 12, 2020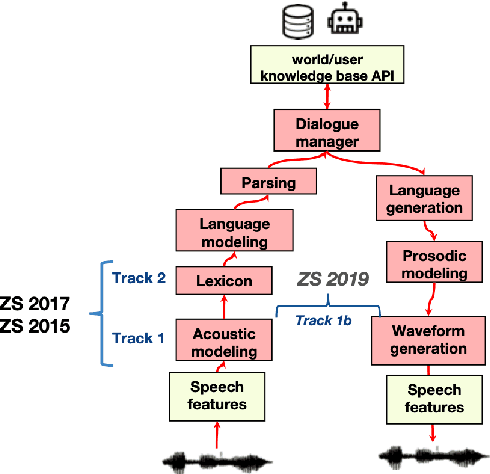

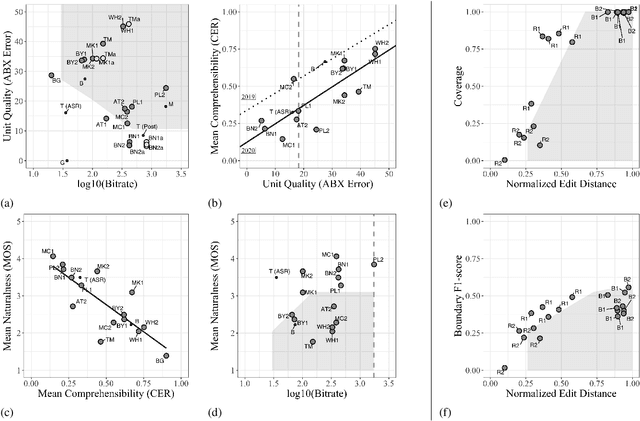
We present the Zero Resource Speech Challenge 2020, which aims at learning speech representations from raw audio signals without any labels. It combines the data sets and metrics from two previous benchmarks (2017 and 2019) and features two tasks which tap into two levels of speech representation. The first task is to discover low bit-rate subword representations that optimize the quality of speech synthesis; the second one is to discover word-like units from unsegmented raw speech. We present the results of the twenty submitted models and discuss the implications of the main findings for unsupervised speech learning.
Analogies minus analogy test: measuring regularities in word embeddings
Oct 07, 2020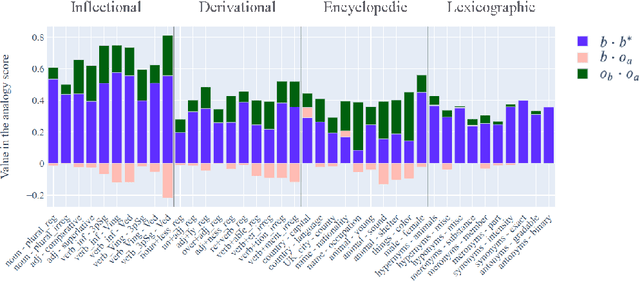
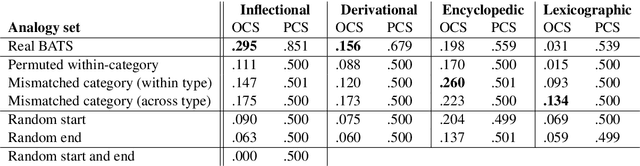
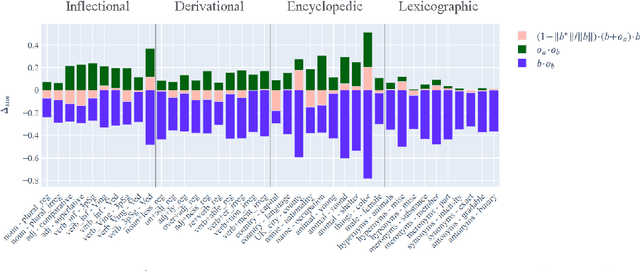
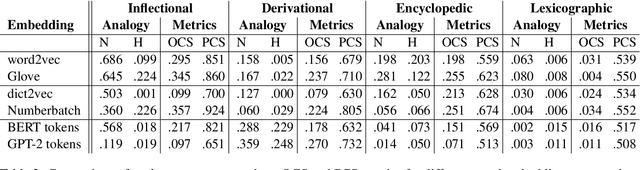
Vector space models of words have long been claimed to capture linguistic regularities as simple vector translations, but problems have been raised with this claim. We decompose and empirically analyze the classic arithmetic word analogy test, to motivate two new metrics that address the issues with the standard test, and which distinguish between class-wise offset concentration (similar directions between pairs of words drawn from different broad classes, such as France--London, China--Ottawa, ...) and pairing consistency (the existence of a regular transformation between correctly-matched pairs such as France:Paris::China:Beijing). We show that, while the standard analogy test is flawed, several popular word embeddings do nevertheless encode linguistic regularities.
"LazImpa": Lazy and Impatient neural agents learn to communicate efficiently
Oct 05, 2020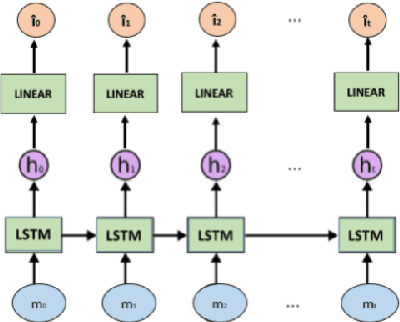

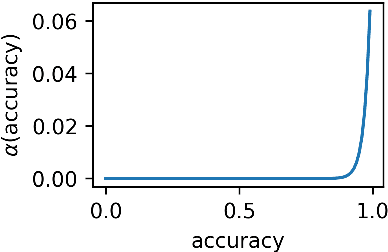

Previous work has shown that artificial neural agents naturally develop surprisingly non-efficient codes. This is illustrated by the fact that in a referential game involving a speaker and a listener neural networks optimizing accurate transmission over a discrete channel, the emergent messages fail to achieve an optimal length. Furthermore, frequent messages tend to be longer than infrequent ones, a pattern contrary to the Zipf Law of Abbreviation (ZLA) observed in all natural languages. Here, we show that near-optimal and ZLA-compatible messages can emerge, but only if both the speaker and the listener are modified. We hence introduce a new communication system, "LazImpa", where the speaker is made increasingly lazy, i.e. avoids long messages, and the listener impatient, i.e.,~seeks to guess the intended content as soon as possible.