 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePETRA: Parallel End-to-end Training with Reversible Architectures
Jun 04, 2024



Reversible architectures have been shown to be capable of performing on par with their non-reversible architectures, being applied in deep learning for memory savings and generative modeling. In this work, we show how reversible architectures can solve challenges in parallelizing deep model training. We introduce PETRA, a novel alternative to backpropagation for parallelizing gradient computations. PETRA facilitates effective model parallelism by enabling stages (i.e., a set of layers) to compute independently on different devices, while only needing to communicate activations and gradients between each other. By decoupling the forward and backward passes and keeping a single updated version of the parameters, the need for weight stashing is also removed. We develop a custom autograd-like training framework for PETRA, and we demonstrate its effectiveness on CIFAR-10, ImageNet32, and ImageNet, achieving competitive accuracies comparable to backpropagation using ResNet-18, ResNet-34, and ResNet-50 models.
ACCO: Accumulate while you Communicate, Hiding Communications in Distributed LLM Training
Jun 03, 2024



Training Large Language Models (LLMs) relies heavily on distributed implementations, employing multiple GPUs to compute stochastic gradients on model replicas in parallel. However, synchronizing gradients in data parallel settings induces a communication overhead increasing with the number of distributed workers, which can impede the efficiency gains of parallelization. To address this challenge, optimization algorithms reducing inter-worker communication have emerged, such as local optimization methods used in Federated Learning. While effective in minimizing communication overhead, these methods incur significant memory costs, hindering scalability: in addition to extra momentum variables, if communications are only allowed between multiple local optimization steps, then the optimizer's states cannot be sharded among workers. In response, we propose $\textbf{AC}$cumulate while $\textbf{CO}$mmunicate ($\texttt{ACCO}$), a memory-efficient optimization algorithm tailored for distributed training of LLMs. $\texttt{ACCO}$ allows to shard optimizer states across workers, overlaps gradient computations and communications to conceal communication costs, and accommodates heterogeneous hardware. Our method relies on a novel technique to mitigate the one-step delay inherent in parallel execution of gradient computations and communications, eliminating the need for warmup steps and aligning with the training dynamics of standard distributed optimization while converging faster in terms of wall-clock time. We demonstrate the effectiveness of $\texttt{ACCO}$ on several LLMs training and fine-tuning tasks.
WASH: Train your Ensemble with Communication-Efficient Weight Shuffling, then Average
May 27, 2024



The performance of deep neural networks is enhanced by ensemble methods, which average the output of several models. However, this comes at an increased cost at inference. Weight averaging methods aim at balancing the generalization of ensembling and the inference speed of a single model by averaging the parameters of an ensemble of models. Yet, naive averaging results in poor performance as models converge to different loss basins, and aligning the models to improve the performance of the average is challenging. Alternatively, inspired by distributed training, methods like DART and PAPA have been proposed to train several models in parallel such that they will end up in the same basin, resulting in good averaging accuracy. However, these methods either compromise ensembling accuracy or demand significant communication between models during training. In this paper, we introduce WASH, a novel distributed method for training model ensembles for weight averaging that achieves state-of-the-art image classification accuracy. WASH maintains models within the same basin by randomly shuffling a small percentage of weights during training, resulting in diverse models and lower communication costs compared to standard parameter averaging methods.
Cyclic Data Parallelism for Efficient Parallelism of Deep Neural Networks
Mar 13, 2024Training large deep learning models requires parallelization techniques to scale. In existing methods such as Data Parallelism or ZeRO-DP, micro-batches of data are processed in parallel, which creates two drawbacks: the total memory required to store the model's activations peaks at the end of the forward pass, and gradients must be simultaneously averaged at the end of the backpropagation step. We propose Cyclic Data Parallelism, a novel paradigm shifting the execution of the micro-batches from simultaneous to sequential, with a uniform delay. At the cost of a slight gradient delay, the total memory taken by activations is constant, and the gradient communications are balanced during the training step. With Model Parallelism, our technique reduces the number of GPUs needed, by sharing GPUs across micro-batches. Within the ZeRO-DP framework, our technique allows communication of the model states with point-to-point operations rather than a collective broadcast operation. We illustrate the strength of our approach on the CIFAR-10 and ImageNet datasets.
Can Forward Gradient Match Backpropagation?
Jun 12, 2023Forward Gradients - the idea of using directional derivatives in forward differentiation mode - have recently been shown to be utilizable for neural network training while avoiding problems generally associated with backpropagation gradient computation, such as locking and memorization requirements. The cost is the requirement to guess the step direction, which is hard in high dimensions. While current solutions rely on weighted averages over isotropic guess vector distributions, we propose to strongly bias our gradient guesses in directions that are much more promising, such as feedback obtained from small, local auxiliary networks. For a standard computer vision neural network, we conduct a rigorous study systematically covering a variety of combinations of gradient targets and gradient guesses, including those previously presented in the literature. We find that using gradients obtained from a local loss as a candidate direction drastically improves on random noise in Forward Gradient methods.
Paraphrases do not explain word analogies
Feb 23, 2021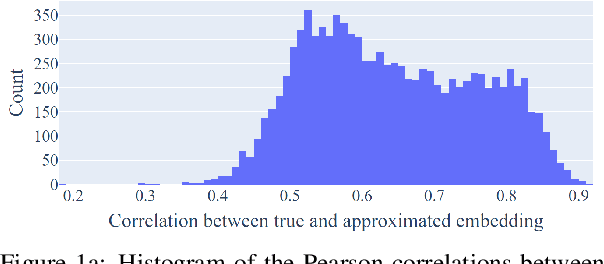
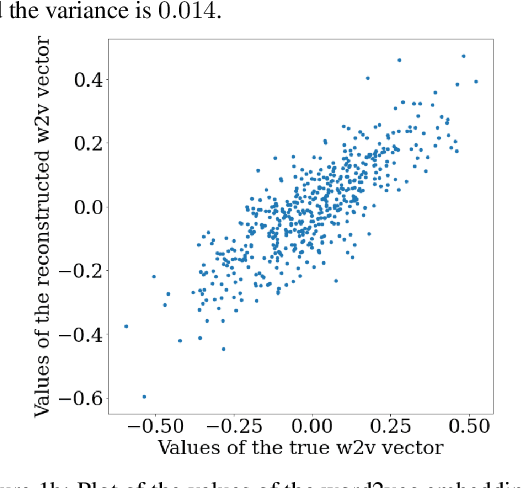
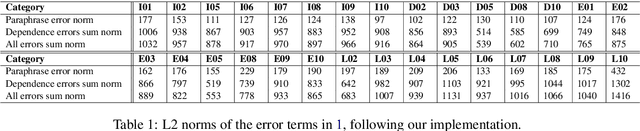

Many types of distributional word embeddings (weakly) encode linguistic regularities as directions (the difference between "jump" and "jumped" will be in a similar direction to that of "walk" and "walked," and so on). Several attempts have been made to explain this fact. We respond to Allen and Hospedales' recent (ICML, 2019) theoretical explanation, which claims that word2vec and GloVe will encode linguistic regularities whenever a specific relation of paraphrase holds between the four words involved in the regularity. We demonstrate that the explanation does not go through: the paraphrase relations needed under this explanation do not hold empirically.
Analogies minus analogy test: measuring regularities in word embeddings
Oct 07, 2020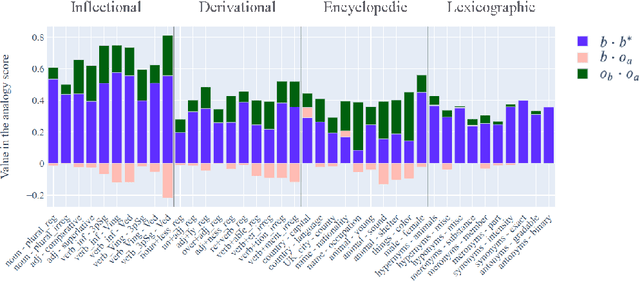
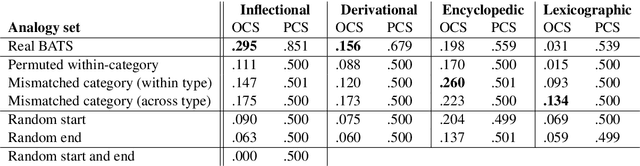
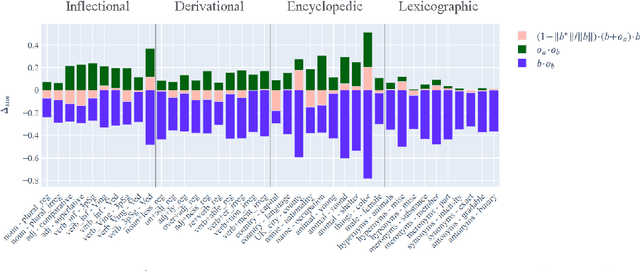
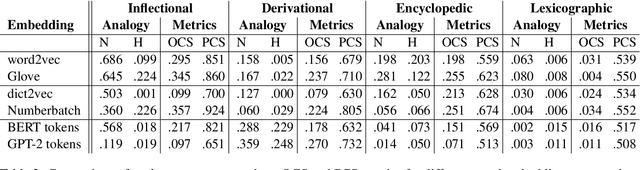
Vector space models of words have long been claimed to capture linguistic regularities as simple vector translations, but problems have been raised with this claim. We decompose and empirically analyze the classic arithmetic word analogy test, to motivate two new metrics that address the issues with the standard test, and which distinguish between class-wise offset concentration (similar directions between pairs of words drawn from different broad classes, such as France--London, China--Ottawa, ...) and pairing consistency (the existence of a regular transformation between correctly-matched pairs such as France:Paris::China:Beijing). We show that, while the standard analogy test is flawed, several popular word embeddings do nevertheless encode linguistic regularities.