 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery-specific Variable Depth Pooling via Query Performance Prediction towards Reducing Relevance Assessment Effort
Apr 23, 2023Due to the massive size of test collections, a standard practice in IR evaluation is to construct a 'pool' of candidate relevant documents comprised of the top-k documents retrieved by a wide range of different retrieval systems - a process called depth-k pooling. A standard practice is to set the depth (k) to a constant value for each query constituting the benchmark set. However, in this paper we argue that the annotation effort can be substantially reduced if the depth of the pool is made a variable quantity for each query, the rationale being that the number of documents relevant to the information need can widely vary across queries. Our hypothesis is that a lower depth for the former class of queries and a higher depth for the latter can potentially reduce the annotation effort without a significant change in retrieval effectiveness evaluation. We make use of standard query performance prediction (QPP) techniques to estimate the number of potentially relevant documents for each query, which is then used to determine the depth of the pool. Our experiments conducted on standard test collections demonstrate that this proposed method of employing query-specific variable depths is able to adequately reflect the relative effectiveness of IR systems with a substantially smaller annotation effort.
Task2KB: A Public Task-Oriented Knowledge Base
Jan 24, 2023

Search engines and conversational assistants are commonly used to help users complete their every day tasks such as booking travel, cooking, etc. While there are some existing datasets that can be used for this purpose, their coverage is limited to very few domains. In this paper, we propose a novel knowledge base, 'Task2KB', which is constructed using data crawled from WikiHow, an online knowledge resource offering instructional articles on a wide range of tasks. Task2KB encapsulates various types of task-related information and attributes, such as requirements, detailed step description, and available methods to complete tasks. Due to its higher coverage compared to existing related knowledge graphs, Task2KB can be highly useful in the development of general purpose task completion assistants
Pre-Training With Scientific Text Improves Educational Question Generation
Dec 07, 2022

With the boom of digital educational materials and scalable e-learning systems, the potential for realising AI-assisted personalised learning has skyrocketed. In this landscape, the automatic generation of educational questions will play a key role, enabling scalable self-assessment when a global population is manoeuvring their personalised learning journeys. We develop EduQG, a novel educational question generation model built by adapting a large language model. Our initial experiments demonstrate that EduQG can produce superior educational questions by pre-training on scientific text.
Can Population-based Engagement Improve Personalisation? A Novel Dataset and Experiments
Jun 22, 2022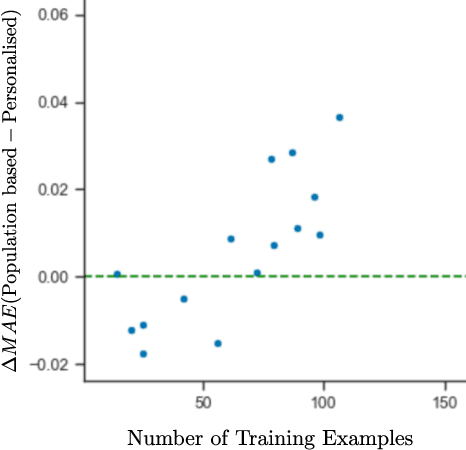
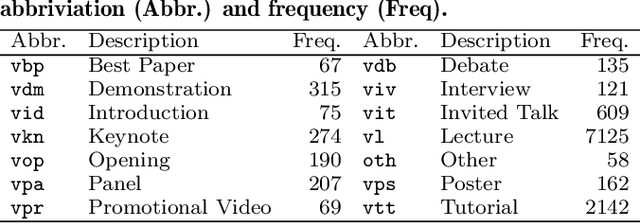
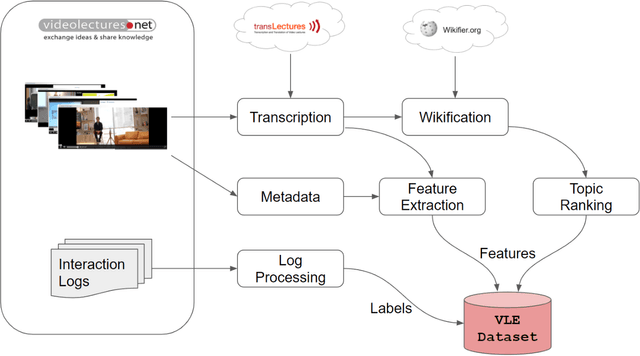
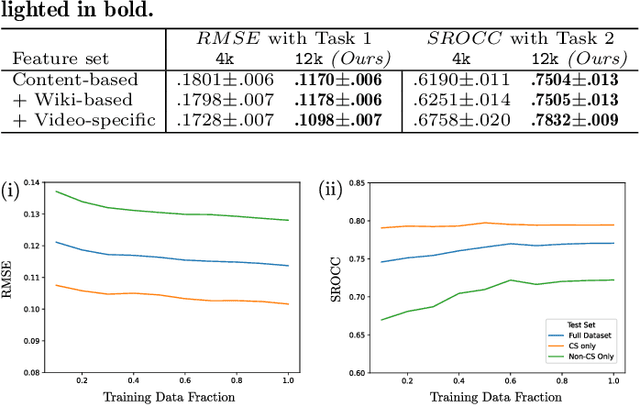
This work explores how population-based engagement prediction can address cold-start at scale in large learning resource collections. The paper introduces i) VLE, a novel dataset that consists of content and video based features extracted from publicly available scientific video lectures coupled with implicit and explicit signals related to learner engagement, ii) two standard tasks related to predicting and ranking context-agnostic engagement in video lectures with preliminary baselines and iii) a set of experiments that validate the usefulness of the proposed dataset. Our experimental results indicate that the newly proposed VLE dataset leads to building context-agnostic engagement prediction models that are significantly performant than ones based on previous datasets, mainly attributing to the increase of training examples. VLE dataset's suitability in building models towards Computer Science/ Artificial Intelligence education focused on e-learning/ MOOC use-cases is also evidenced. Further experiments in combining the built model with a personalising algorithm show promising improvements in addressing the cold-start problem encountered in educational recommenders. This is the largest and most diverse publicly available dataset to our knowledge that deals with learner engagement prediction tasks. The dataset, helper tools, descriptive statistics and example code snippets are available publicly.
Integrated Weak Learning
Jun 19, 2022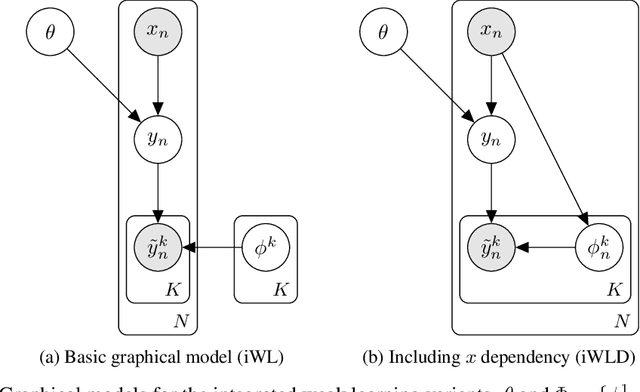
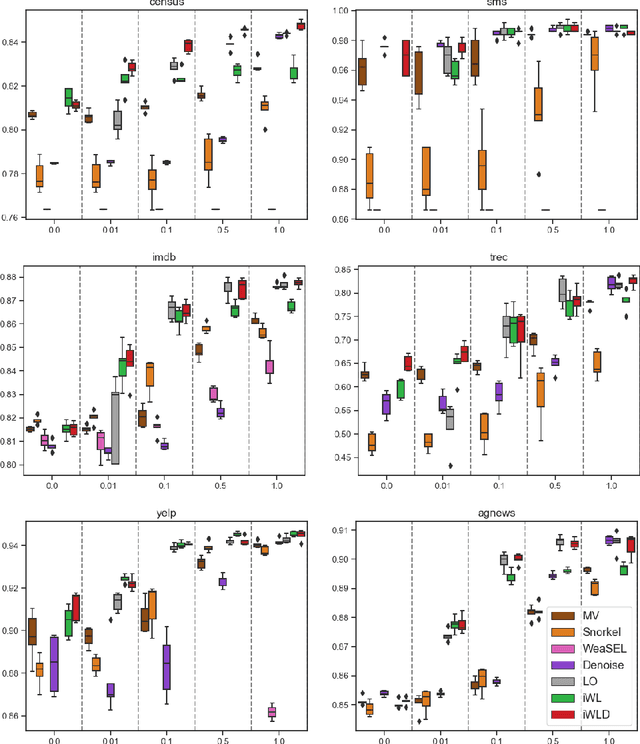
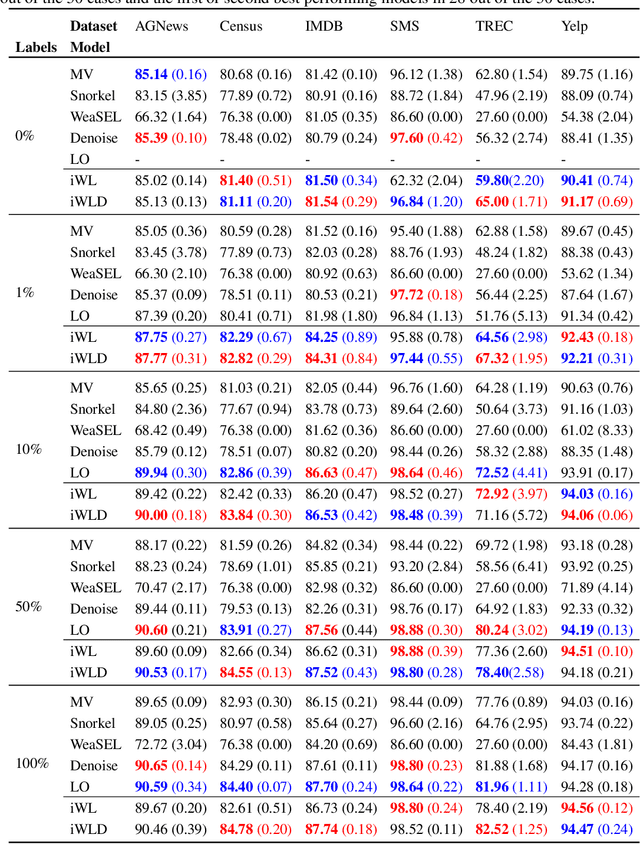
We introduce Integrated Weak Learning, a principled framework that integrates weak supervision into the training process of machine learning models. Our approach jointly trains the end-model and a label model that aggregates multiple sources of weak supervision. We introduce a label model that can learn to aggregate weak supervision sources differently for different datapoints and takes into consideration the performance of the end-model during training. We show that our approach outperforms existing weak learning techniques across a set of 6 benchmark classification datasets. When both a small amount of labeled data and weak supervision are present the increase in performance is both consistent and large, reliably getting a 2-5 point test F1 score gain over non-integrated methods.
Dynamic Schema Graph Fusion Network for Multi-Domain Dialogue State Tracking
Apr 15, 2022
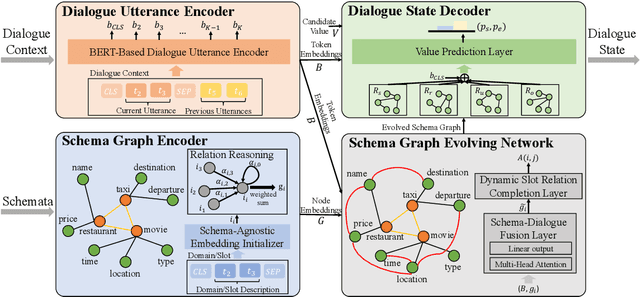
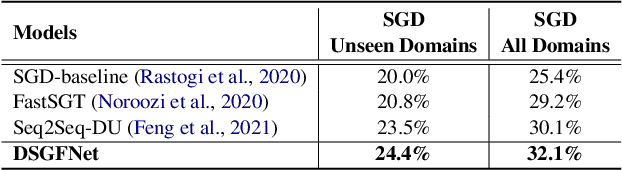
Dialogue State Tracking (DST) aims to keep track of users' intentions during the course of a conversation. In DST, modelling the relations among domains and slots is still an under-studied problem. Existing approaches that have considered such relations generally fall short in: (1) fusing prior slot-domain membership relations and dialogue-aware dynamic slot relations explicitly, and (2) generalizing to unseen domains. To address these issues, we propose a novel \textbf{D}ynamic \textbf{S}chema \textbf{G}raph \textbf{F}usion \textbf{Net}work (\textbf{DSGFNet}), which generates a dynamic schema graph to explicitly fuse the prior slot-domain membership relations and dialogue-aware dynamic slot relations. It also uses the schemata to facilitate knowledge transfer to new domains. DSGFNet consists of a dialogue utterance encoder, a schema graph encoder, a dialogue-aware schema graph evolving network, and a schema graph enhanced dialogue state decoder. Empirical results on benchmark datasets (i.e., SGD, MultiWOZ2.1, and MultiWOZ2.2), show that DSGFNet outperforms existing methods.
ASSIST: Towards Label Noise-Robust Dialogue State Tracking
Mar 11, 2022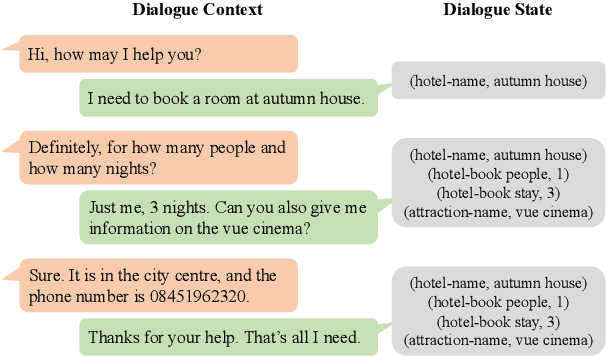
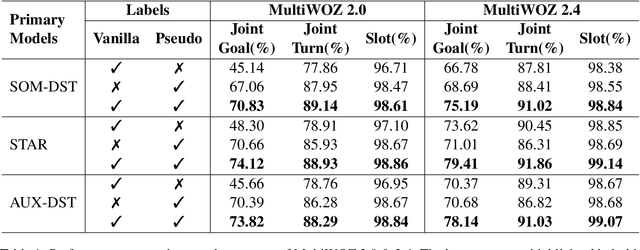
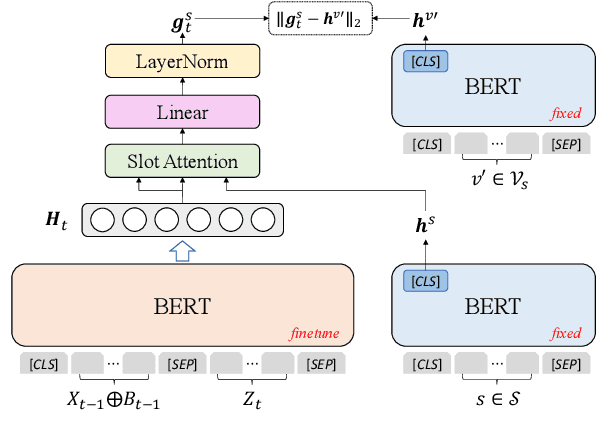
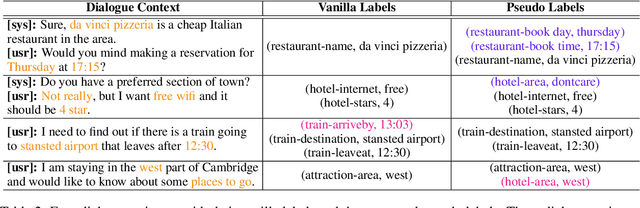
The MultiWOZ 2.0 dataset has greatly boosted the research on dialogue state tracking (DST). However, substantial noise has been discovered in its state annotations. Such noise brings about huge challenges for training DST models robustly. Although several refined versions, including MultiWOZ 2.1-2.4, have been published recently, there are still lots of noisy labels, especially in the training set. Besides, it is costly to rectify all the problematic annotations. In this paper, instead of improving the annotation quality further, we propose a general framework, named ASSIST (lAbel noiSe-robuSt dIalogue State Tracking), to train DST models robustly from noisy labels. ASSIST first generates pseudo labels for each sample in the training set by using an auxiliary model trained on a small clean dataset, then puts the generated pseudo labels and vanilla noisy labels together to train the primary model. We show the validity of ASSIST theoretically. Experimental results also demonstrate that ASSIST improves the joint goal accuracy of DST by up to $28.16\%$ on MultiWOZ 2.0 and $8.41\%$ on MultiWOZ 2.4, compared to using only the vanilla noisy labels.
Watch Less and Uncover More: Could Navigation Tools Help Users Search and Explore Videos?
Jan 10, 2022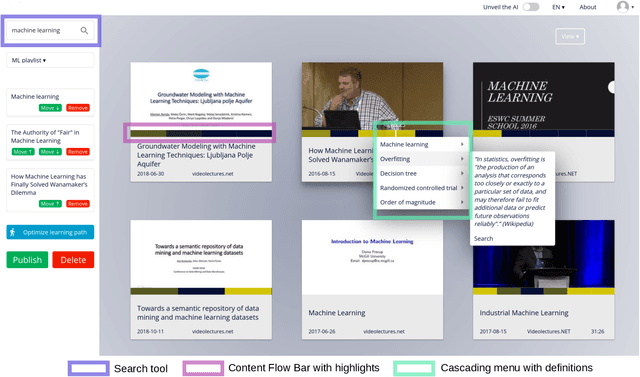
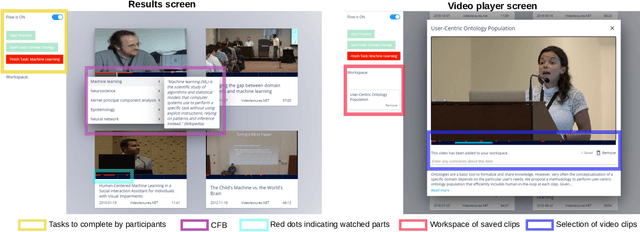
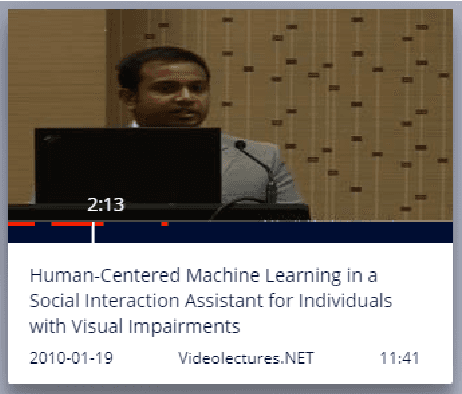
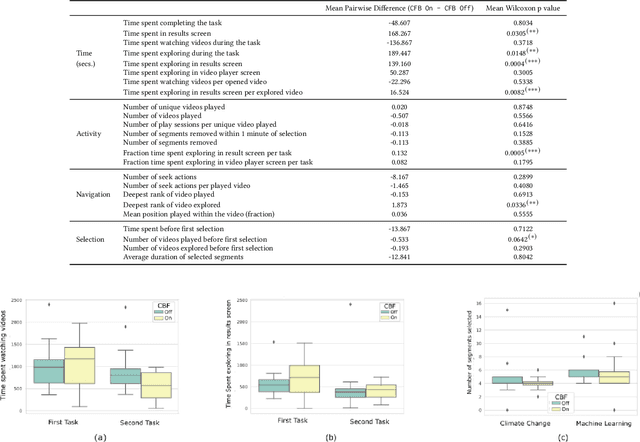
Prior research has shown how 'content preview tools' improve speed and accuracy of user relevance judgements across different information retrieval tasks. This paper describes a novel user interface tool, the Content Flow Bar, designed to allow users to quickly identify relevant fragments within informational videos to facilitate browsing, through a cognitively augmented form of navigation. It achieves this by providing semantic "snippets" that enable the user to rapidly scan through video content. The tool provides visually-appealing pop-ups that appear in a time series bar at the bottom of each video, allowing to see in advance and at a glance how topics evolve in the content. We conducted a user study to evaluate how the tool changes the users search experience in video retrieval, as well as how it supports exploration and information seeking. The user questionnaire revealed that participants found the Content Flow Bar helpful and enjoyable for finding relevant information in videos. The interaction logs of the user study, where participants interacted with the tool for completing two informational tasks, showed that it holds promise for enhancing discoverability of content both across and within videos. This discovered potential could leverage a new generation of navigation tools in search and information retrieval.
Semantic TrueLearn: Using Semantic Knowledge Graphs in Recommendation Systems
Dec 08, 2021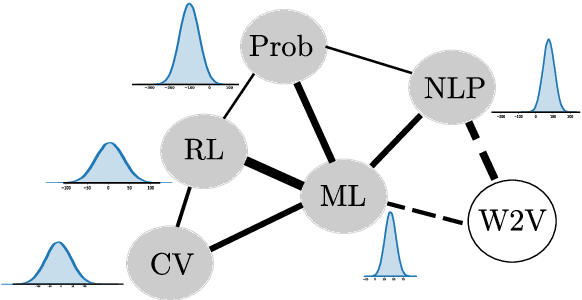
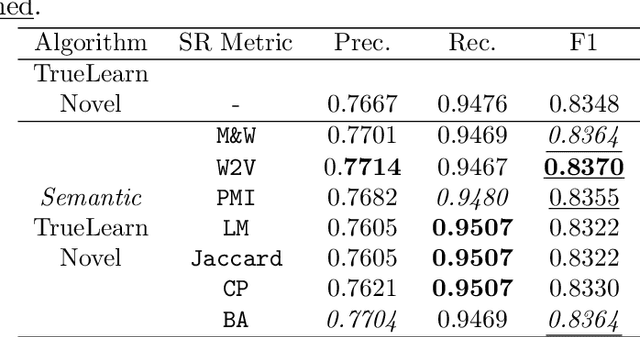
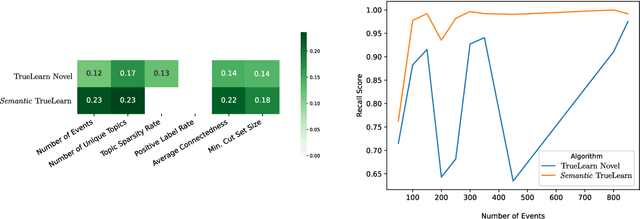

In informational recommenders, many challenges arise from the need to handle the semantic and hierarchical structure between knowledge areas. This work aims to advance towards building a state-aware educational recommendation system that incorporates semantic relatedness between knowledge topics, propagating latent information across semantically related topics. We introduce a novel learner model that exploits this semantic relatedness between knowledge components in learning resources using the Wikipedia link graph, with the aim to better predict learner engagement and latent knowledge in a lifelong learning scenario. In this sense, Semantic TrueLearn builds a humanly intuitive knowledge representation while leveraging Bayesian machine learning to improve the predictive performance of the educational engagement. Our experiments with a large dataset demonstrate that this new semantic version of TrueLearn algorithm achieves statistically significant improvements in terms of predictive performance with a simple extension that adds semantic awareness to the model.
Towards More Accountable Search Engines: Online Evaluation of Representation Bias
Oct 17, 2021
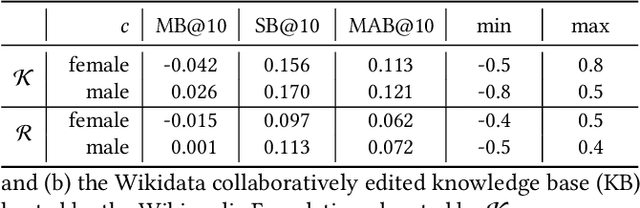
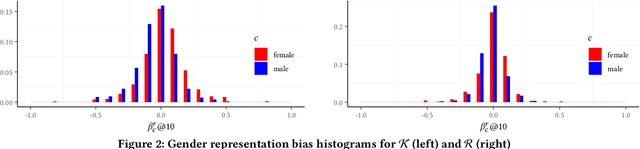
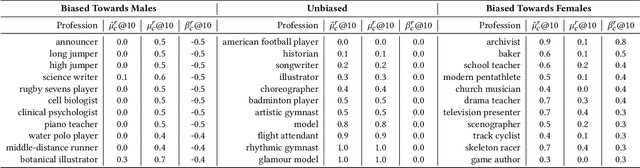
Information availability affects people's behavior and perception of the world. Notably, people rely on search engines to satisfy their need for information. Search engines deliver results relevant to user requests usually without being or making themselves accountable for the information they deliver, which may harm people's lives and, in turn, society. This potential risk urges the development of evaluation mechanisms of bias in order to empower the user in judging the results of search engines. In this paper, we give a possible solution to measuring representation bias with respect to societal features for search engines and apply it to evaluating the gender representation bias for Google's Knowledge Graph Carousel for listing occupations.