 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Analytical Characterization of Sloppiness in Neural Networks: Insights from Linear Models
May 13, 2025



Recent experiments have shown that training trajectories of multiple deep neural networks with different architectures, optimization algorithms, hyper-parameter settings, and regularization methods evolve on a remarkably low-dimensional "hyper-ribbon-like" manifold in the space of probability distributions. Inspired by the similarities in the training trajectories of deep networks and linear networks, we analytically characterize this phenomenon for the latter. We show, using tools in dynamical systems theory, that the geometry of this low-dimensional manifold is controlled by (i) the decay rate of the eigenvalues of the input correlation matrix of the training data, (ii) the relative scale of the ground-truth output to the weights at the beginning of training, and (iii) the number of steps of gradient descent. By analytically computing and bounding the contributions of these quantities, we characterize phase boundaries of the region where hyper-ribbons are to be expected. We also extend our analysis to kernel machines and linear models that are trained with stochastic gradient descent.
Composable and adaptive design of machine learning interatomic potentials guided by Fisher-information analysis
Apr 27, 2025An adaptive physics-informed model design strategy for machine-learning interatomic potentials (MLIPs) is proposed. This strategy follows an iterative reconfiguration of composite models from single-term models, followed by a unified training procedure. A model evaluation method based on the Fisher information matrix (FIM) and multiple-property error metrics is proposed to guide model reconfiguration and hyperparameter optimization. Combining the model reconfiguration and the model evaluation subroutines, we provide an adaptive MLIP design strategy that balances flexibility and extensibility. In a case study of designing models against a structurally diverse niobium dataset, we managed to obtain an optimal configuration with 75 parameters generated by our framework that achieved a force RMSE of 0.172 eV/{\AA} and an energy RMSE of 0.013 eV/atom.
Comparing analytic and data-driven approaches to parameter identifiability: A power systems case study
Dec 24, 2024



Parameter identifiability refers to the capability of accurately inferring the parameter values of a model from its observations (data). Traditional analysis methods exploit analytical properties of the closed form model, in particular sensitivity analysis, to quantify the response of the model predictions to variations in parameters. Techniques developed to analyze data, specifically manifold learning methods, have the potential to complement, and even extend the scope of the traditional analytical approaches. We report on a study comparing and contrasting analytical and data-driven approaches to quantify parameter identifiability and, importantly, perform parameter reduction tasks. We use the infinite bus synchronous generator model, a well-understood model from the power systems domain, as our benchmark problem. Our traditional analysis methods use the Fisher Information Matrix to quantify parameter identifiability analysis, and the Manifold Boundary Approximation Method to perform parameter reduction. We compare these results to those arrived at through data-driven manifold learning schemes: Output - Diffusion Maps and Geometric Harmonics. For our test case, we find that the two suites of tools (analytical when a model is explicitly available, as well as data-driven when the model is lacking and only measurement data are available) give (correct) comparable results; these results are also in agreement with traditional analysis based on singular perturbation theory. We then discuss the prospects of using data-driven methods for such model analysis.
An information-matching approach to optimal experimental design and active learning
Nov 05, 2024The efficacy of mathematical models heavily depends on the quality of the training data, yet collecting sufficient data is often expensive and challenging. Many modeling applications require inferring parameters only as a means to predict other quantities of interest (QoI). Because models often contain many unidentifiable (sloppy) parameters, QoIs often depend on a relatively small number of parameter combinations. Therefore, we introduce an information-matching criterion based on the Fisher Information Matrix to select the most informative training data from a candidate pool. This method ensures that the selected data contain sufficient information to learn only those parameters that are needed to constrain downstream QoIs. It is formulated as a convex optimization problem, making it scalable to large models and datasets. We demonstrate the effectiveness of this approach across various modeling problems in diverse scientific fields, including power systems and underwater acoustics. Finally, we use information-matching as a query function within an Active Learning loop for material science applications. In all these applications, we find that a relatively small set of optimal training data can provide the necessary information for achieving precise predictions. These results are encouraging for diverse future applications, particularly active learning in large machine learning models.
Aliasing and Label-Independent Decomposition of Risk: Beyond the bias-variance trade-off
Aug 15, 2024



A central problem in data science is to use potentially noisy samples of an unknown function to predict function values for unseen inputs. In classical statistics, the predictive error is understood as a trade-off between the bias and the variance that balances model simplicity with its ability to fit complex functions. However, over-parameterized models exhibit counter-intuitive behaviors, such as "double descent" in which models of increasing complexity exhibit decreasing generalization error. We introduce an alternative paradigm called the generalized aliasing decomposition. We explain the asymptotically small error of complex models as a systematic "de-aliasing" that occurs in the over-parameterized regime. In the limit of large models, the contribution due to aliasing vanishes, leaving an expression for the asymptotic total error we call the invertibility failure of very large models on few training points. Because the generalized aliasing decomposition can be explicitly calculated from the relationship between model class and samples without seeing any data labels, it can answer questions related to experimental design and model selection before collecting data or performing experiments. We demonstrate this approach using several examples, including classical regression problems and a cluster expansion model used in materials science.
The Training Process of Many Deep Networks Explores the Same Low-Dimensional Manifold
May 02, 2023We develop information-geometric techniques to analyze the trajectories of the predictions of deep networks during training. By examining the underlying high-dimensional probabilistic models, we reveal that the training process explores an effectively low-dimensional manifold. Networks with a wide range of architectures, sizes, trained using different optimization methods, regularization techniques, data augmentation techniques, and weight initializations lie on the same manifold in the prediction space. We study the details of this manifold to find that networks with different architectures follow distinguishable trajectories but other factors have a minimal influence; larger networks train along a similar manifold as that of smaller networks, just faster; and networks initialized at very different parts of the prediction space converge to the solution along a similar manifold.
Maximizing the information learned from finite data selects a simple model
Feb 14, 2018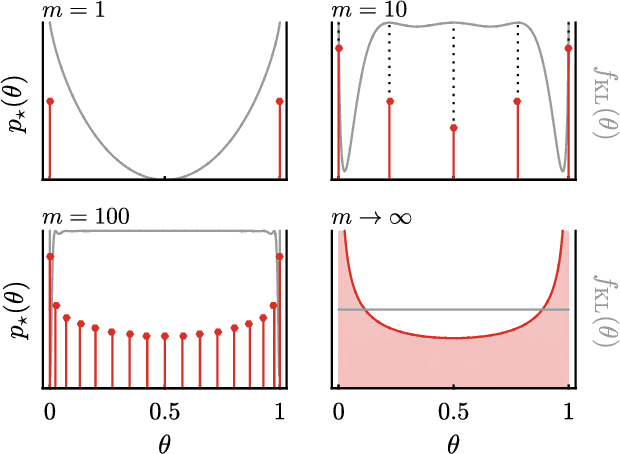
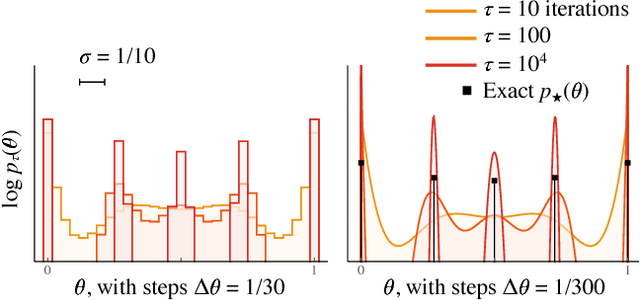
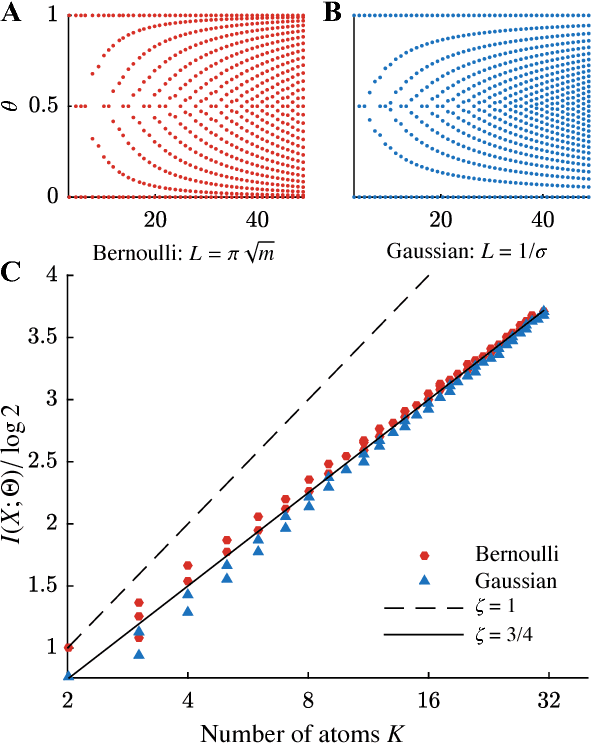
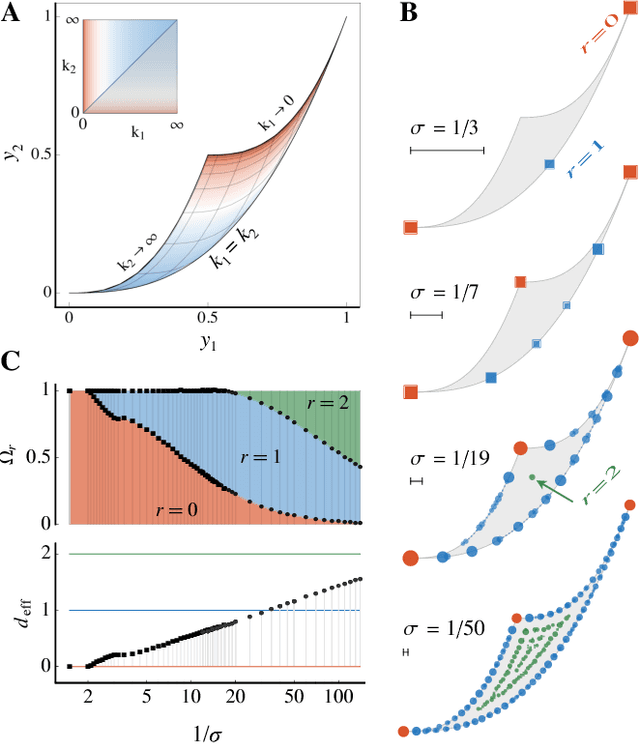
We use the language of uninformative Bayesian prior choice to study the selection of appropriately simple effective models. We advocate for the prior which maximizes the mutual information between parameters and predictions, learning as much as possible from limited data. When many parameters are poorly constrained by the available data, we find that this prior puts weight only on boundaries of the parameter manifold. Thus it selects a lower-dimensional effective theory in a principled way, ignoring irrelevant parameter directions. In the limit where there is sufficient data to tightly constrain any number of parameters, this reduces to Jeffreys prior. But we argue that this limit is pathological when applied to the hyper-ribbon parameter manifolds generic in science, because it leads to dramatic dependence on effects invisible to experiment.
* 9 pages, 8 figures. v3 has improved discussion and adds an appendix about MDL and Bayes factors, and matches version to appear in PNAS (modulo comma placement). Title changed from "Rational Ignorance: Simpler Models Learn More Information from Finite Data"