 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Semi-Supervised Learning in Video Sequences for Urban Scene Segmentation
May 22, 2020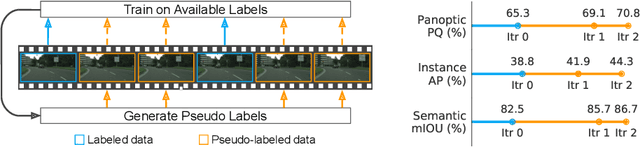

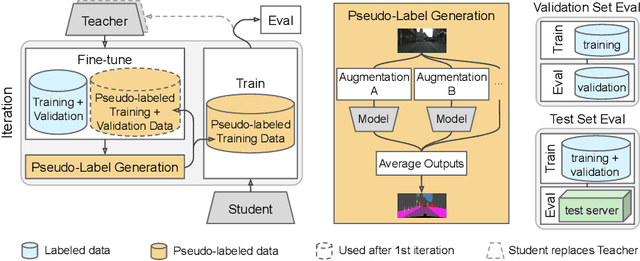
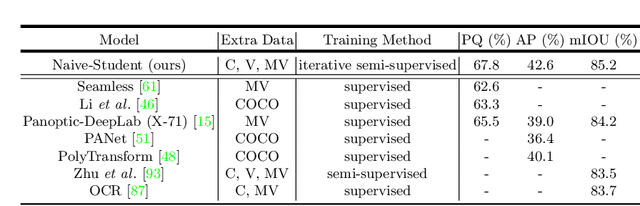
Supervised learning in large discriminative models is a mainstay for modern computer vision. Such an approach necessitates investing in large-scale human-annotated datasets for achieving state-of-the-art results. In turn, the efficacy of supervised learning may be limited by the size of the human annotated dataset. This limitation is particularly notable for image segmentation tasks, where the expense of human annotation is especially large, yet large amounts of unlabeled data may exist. In this work, we ask if we may leverage semi-supervised learning in unlabeled video sequences to improve the performance on urban scene segmentation, simultaneously tackling semantic, instance, and panoptic segmentation. The goal of this work is to avoid the construction of sophisticated, learned architectures specific to label propagation (e.g., patch matching and optical flow). Instead, we simply predict pseudo-labels for the unlabeled data and train subsequent models with both human-annotated and pseudo-labeled data. The procedure is iterated for several times. As a result, our Naive-Student model, trained with such simple yet effective iterative semi-supervised learning, attains state-of-the-art results at all three Cityscapes benchmarks, reaching the performance of 67.8% PQ, 42.6% AP, and 85.2% mIOU on the test set. We view this work as a notable step towards building a simple procedure to harness unlabeled video sequences to surpass state-of-the-art performance on core computer vision tasks.
Affinity and Diversity: Quantifying Mechanisms of Data Augmentation
Feb 20, 2020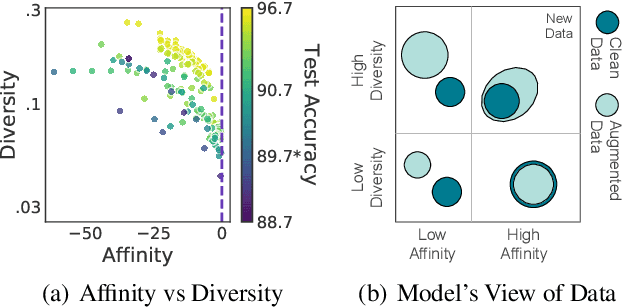
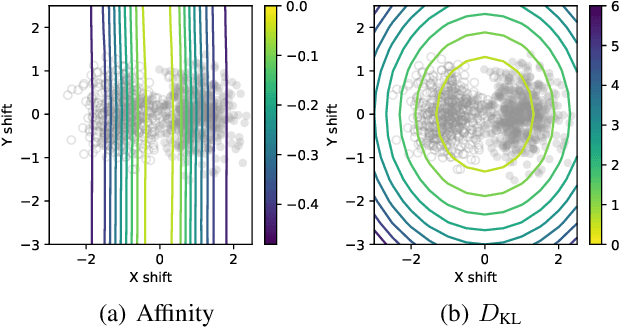
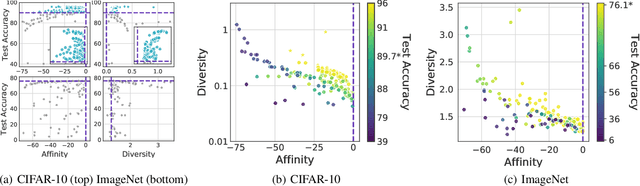
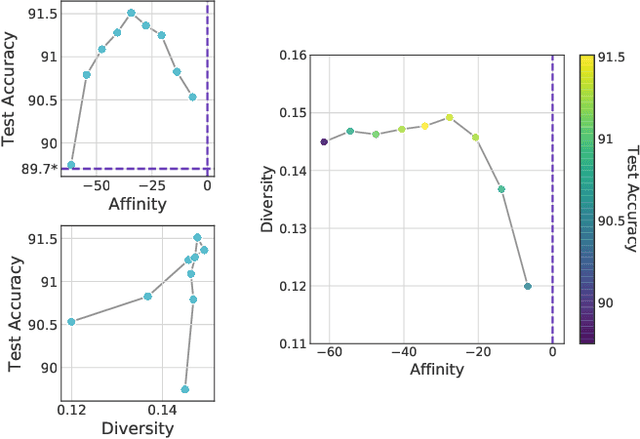
Though data augmentation has become a standard component of deep neural network training, the underlying mechanism behind the effectiveness of these techniques remains poorly understood. In practice, augmentation policies are often chosen using heuristics of either distribution shift or augmentation diversity. Inspired by these, we seek to quantify how data augmentation improves model generalization. To this end, we introduce interpretable and easy-to-compute measures: Affinity and Diversity. We find that augmentation performance is predicted not by either of these alone but by jointly optimizing the two.
FixMatch: Simplifying Semi-Supervised Learning with Consistency and Confidence
Jan 21, 2020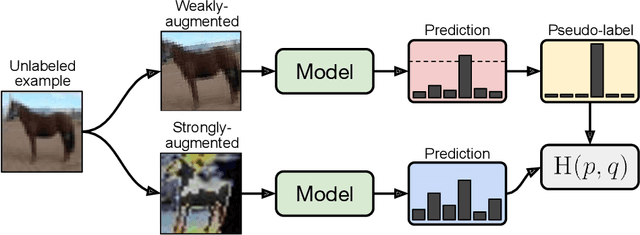
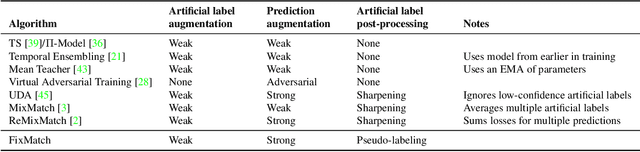
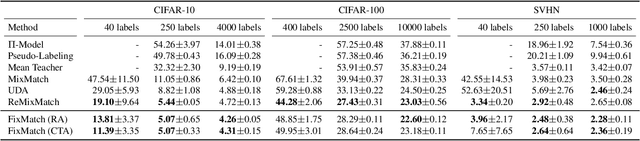

Semi-supervised learning (SSL) provides an effective means of leveraging unlabeled data to improve a model's performance. In this paper, we demonstrate the power of a simple combination of two common SSL methods: consistency regularization and pseudo-labeling. Our algorithm, FixMatch, first generates pseudo-labels using the model's predictions on weakly-augmented unlabeled images. For a given image, the pseudo-label is only retained if the model produces a high-confidence prediction. The model is then trained to predict the pseudo-label when fed a strongly-augmented version of the same image. Despite its simplicity, we show that FixMatch achieves state-of-the-art performance across a variety of standard semi-supervised learning benchmarks, including 94.93% accuracy on CIFAR-10 with 250 labels and 88.61% accuracy with 40 -- just 4 labels per class. Since FixMatch bears many similarities to existing SSL methods that achieve worse performance, we carry out an extensive ablation study to tease apart the experimental factors that are most important to FixMatch's success. We make our code available at https://github.com/google-research/fixmatch.
JAX, M.D.: End-to-End Differentiable, Hardware Accelerated, Molecular Dynamics in Pure Python
Dec 09, 2019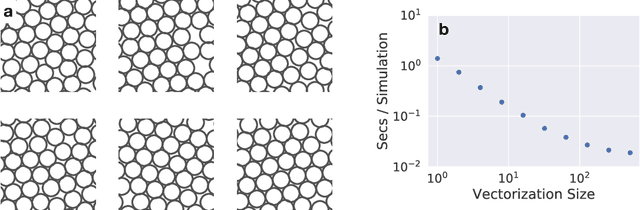
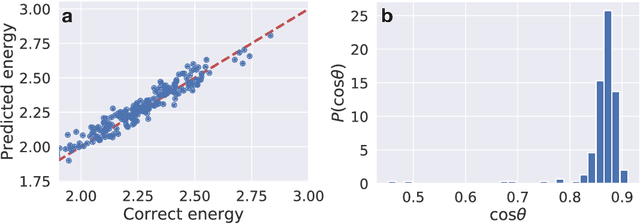
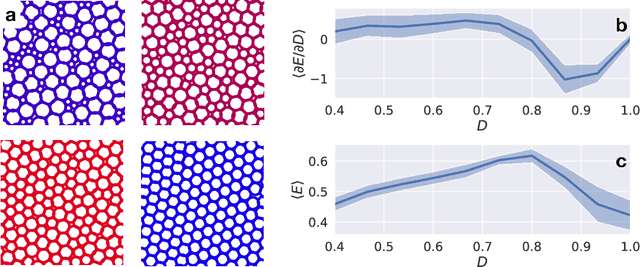

A large fraction of computational science involves simulating the dynamics of particles that interact via pairwise or many-body interactions. These simulations, called Molecular Dynamics (MD), span a vast range of subjects from physics and materials science to biochemistry and drug discovery. Most MD software involves significant use of handwritten derivatives and code reuse across C++, FORTRAN, and CUDA. This is reminiscent of the state of machine learning before automatic differentiation became popular. In this work we bring the substantial advances in software that have taken place in machine learning to MD with JAX, M.D. (JAX MD). JAX MD is an end-to-end differentiable MD package written entirely in Python that can be just-in-time compiled to CPU, GPU, or TPU. JAX MD allows researchers to iterate extremely quickly and lets researchers easily incorporate machine learning models into their workflows. Finally, since all of the simulation code is written in Python, researchers can have unprecedented flexibility in setting up experiments without having to edit any low-level C++ or CUDA code. In addition to making existing workloads easier, JAX MD allows researchers to take derivatives through whole-simulations as well as seamlessly incorporate neural networks into simulations. This paper explores the architecture of JAX MD and its capabilities through several vignettes. Code is available at www.github.com/google/jax-md. We also provide an interactive Colab notebook that goes through all of the experiments discussed in the paper.
AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty
Dec 05, 2019
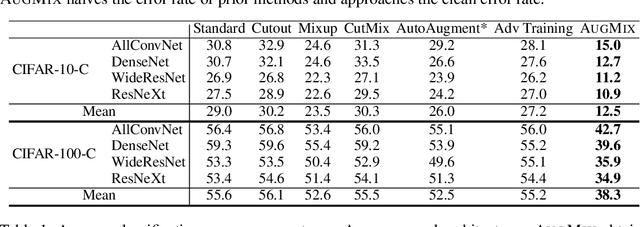

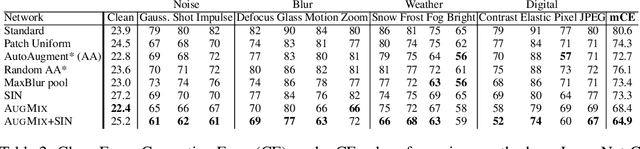
Modern deep neural networks can achieve high accuracy when the training distribution and test distribution are identically distributed, but this assumption is frequently violated in practice. When the train and test distributions are mismatched, accuracy can plummet. Currently there are few techniques that improve robustness to unforeseen data shifts encountered during deployment. In this work, we propose a technique to improve the robustness and uncertainty estimates of image classifiers. We propose AugMix, a data processing technique that is simple to implement, adds limited computational overhead, and helps models withstand unforeseen corruptions. AugMix significantly improves robustness and uncertainty measures on challenging image classification benchmarks, closing the gap between previous methods and the best possible performance in some cases by more than half.
ReMixMatch: Semi-Supervised Learning with Distribution Alignment and Augmentation Anchoring
Nov 21, 2019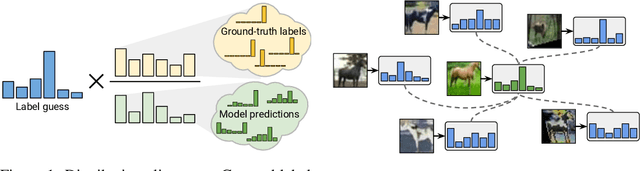
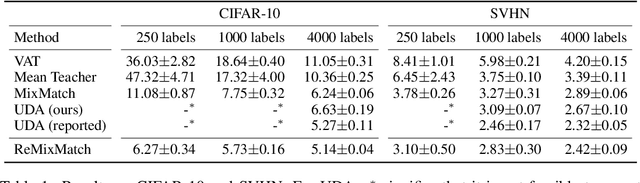
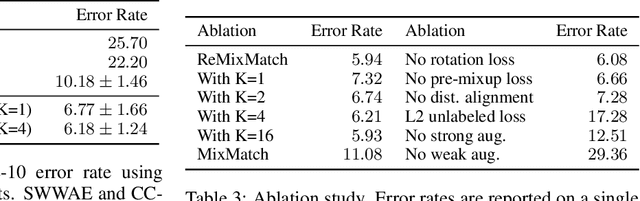
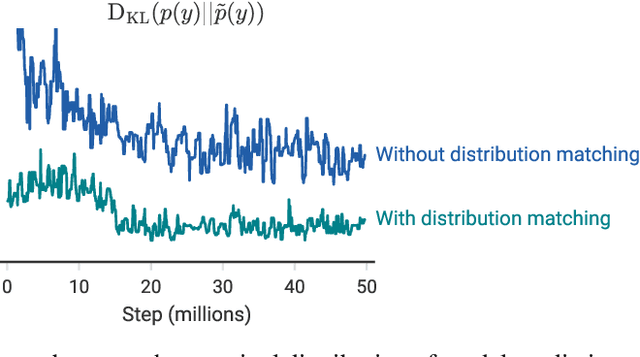
We improve the recently-proposed "MixMatch" semi-supervised learning algorithm by introducing two new techniques: distribution alignment and augmentation anchoring. Distribution alignment encourages the marginal distribution of predictions on unlabeled data to be close to the marginal distribution of ground-truth labels. Augmentation anchoring feeds multiple strongly augmented versions of an input into the model and encourages each output to be close to the prediction for a weakly-augmented version of the same input. To produce strong augmentations, we propose a variant of AutoAugment which learns the augmentation policy while the model is being trained. Our new algorithm, dubbed ReMixMatch, is significantly more data-efficient than prior work, requiring between $5\times$ and $16\times$ less data to reach the same accuracy. For example, on CIFAR-10 with 250 labeled examples we reach $93.73\%$ accuracy (compared to MixMatch's accuracy of $93.58\%$ with $4{,}000$ examples) and a median accuracy of $84.92\%$ with just four labels per class. We make our code and data open-source at https://github.com/google-research/remixmatch.
RandAugment: Practical automated data augmentation with a reduced search space
Nov 14, 2019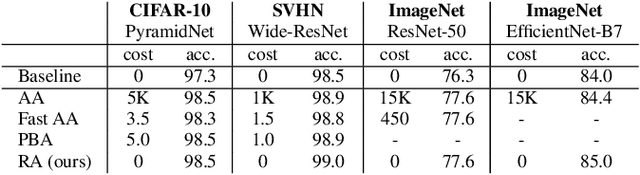


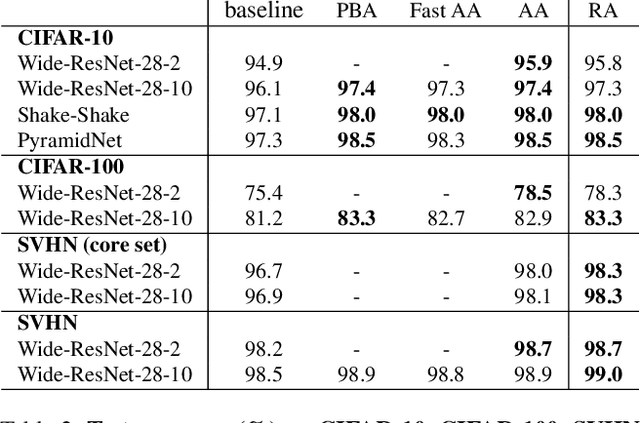
Recent work has shown that data augmentation has the potential to significantly improve the generalization of deep learning models. Recently, automated augmentation strategies have led to state-of-the-art results in image classification and object detection. While these strategies were optimized for improving validation accuracy, they also led to state-of-the-art results in semi-supervised learning and improved robustness to common corruptions of images. An obstacle to a large-scale adoption of these methods is a separate search phase which increases the training complexity and may substantially increase the computational cost. Additionally, due to the separate search phase, these approaches are unable to adjust the regularization strength based on model or dataset size. Automated augmentation policies are often found by training small models on small datasets and subsequently applied to train larger models. In this work, we remove both of these obstacles. RandAugment has a significantly reduced search space which allows it to be trained on the target task with no need for a separate proxy task. Furthermore, due to the parameterization, the regularization strength may be tailored to different model and dataset sizes. RandAugment can be used uniformly across different tasks and datasets and works out of the box, matching or surpassing all previous automated augmentation approaches on CIFAR-10/100, SVHN, and ImageNet. On the ImageNet dataset we achieve 85.0% accuracy, a 0.6% increase over the previous state-of-the-art and 1.0% increase over baseline augmentation. On object detection, RandAugment leads to 1.0-1.3% improvement over baseline augmentation, and is within 0.3% mAP of AutoAugment on COCO. Finally, due to its interpretable hyperparameter, RandAugment may be used to investigate the role of data augmentation with varying model and dataset size. Code is available online.
Learning Data Augmentation Strategies for Object Detection
Jun 26, 2019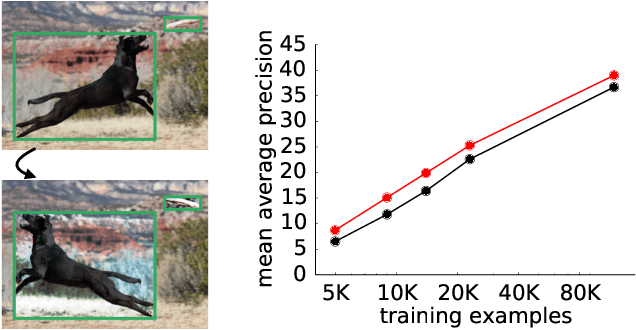
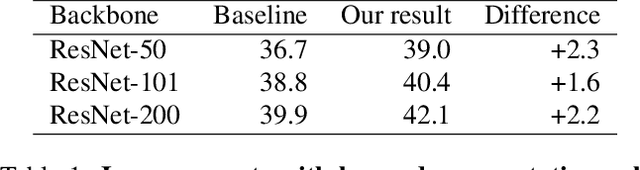


Data augmentation is a critical component of training deep learning models. Although data augmentation has been shown to significantly improve image classification, its potential has not been thoroughly investigated for object detection. Given the additional cost for annotating images for object detection, data augmentation may be of even greater importance for this computer vision task. In this work, we study the impact of data augmentation on object detection. We first demonstrate that data augmentation operations borrowed from image classification may be helpful for training detection models, but the improvement is limited. Thus, we investigate how learned, specialized data augmentation policies improve generalization performance for detection models. Importantly, these augmentation policies only affect training and leave a trained model unchanged during evaluation. Experiments on the COCO dataset indicate that an optimized data augmentation policy improves detection accuracy by more than +2.3 mAP, and allow a single inference model to achieve a state-of-the-art accuracy of 50.7 mAP. Importantly, the best policy found on COCO may be transferred unchanged to other detection datasets and models to improve predictive accuracy. For example, the best augmentation policy identified with COCO improves a strong baseline on PASCAL-VOC by +2.7 mAP. Our results also reveal that a learned augmentation policy is superior to state-of-the-art architecture regularization methods for object detection, even when considering strong baselines. Code for training with the learned policy is available online at https://github.com/tensorflow/tpu/tree/master/models/official/detection
A Fourier Perspective on Model Robustness in Computer Vision
Jun 21, 2019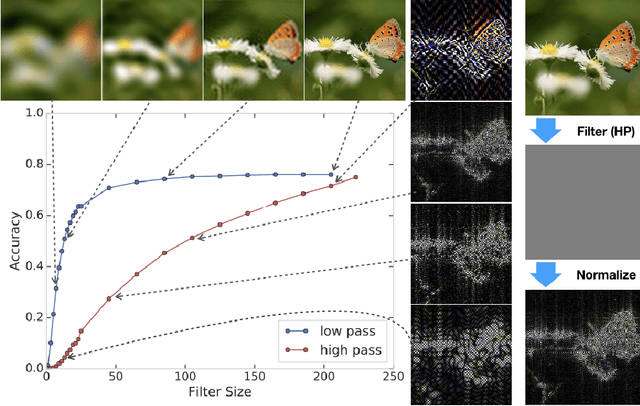

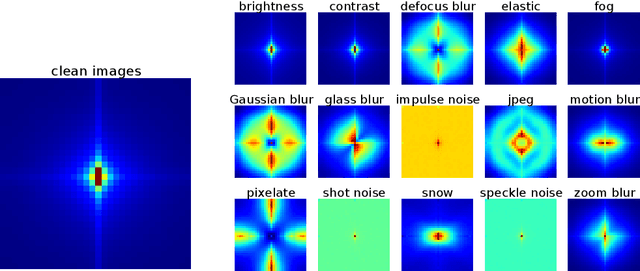
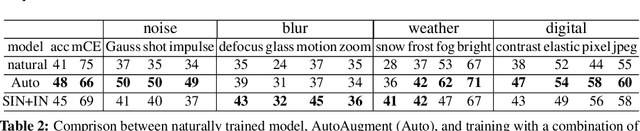
Achieving robustness to distributional shift is a longstanding and challenging goal of computer vision. Data augmentation is a commonly used approach for improving robustness, however robustness gains are typically not uniform across corruption types. Indeed increasing performance in the presence of random noise is often met with reduced performance on other corruptions such as contrast change. Understanding when and why these sorts of trade-offs occur is a crucial step towards mitigating them. Towards this end, we investigate recently observed trade-offs caused by Gaussian data augmentation and adversarial training. We find that both methods improve robustness to corruptions that are concentrated in the high frequency domain while reducing robustness to corruptions that are concentrated in the low frequency domain. This suggests that one way to mitigate these trade-offs via data augmentation is to use a more diverse set of augmentations. Towards this end we observe that AutoAugment, a recently proposed data augmentation policy optimized for clean accuracy, achieves state-of-the-art robustness on the CIFAR-10-C and ImageNet-C benchmarks.
Using learned optimizers to make models robust to input noise
Jun 08, 2019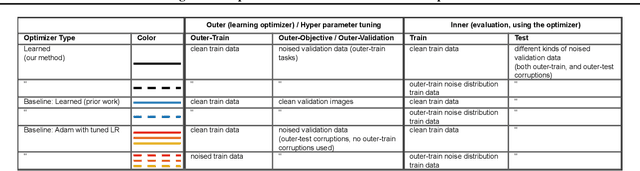
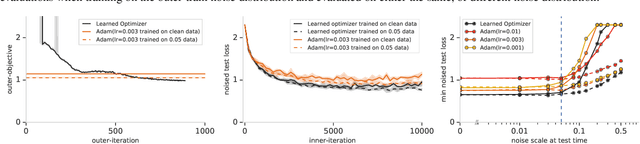
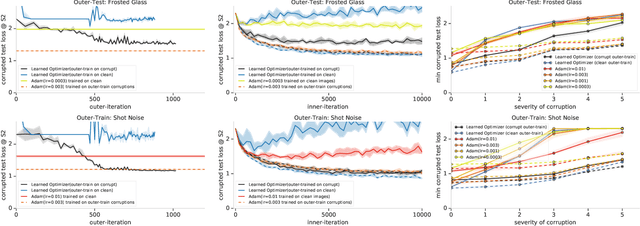
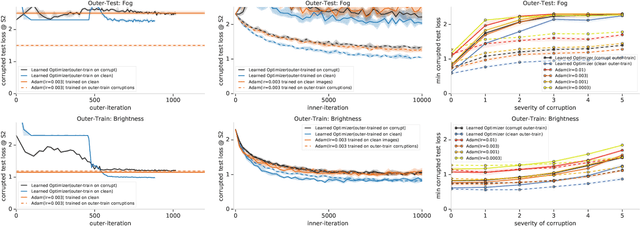
State-of-the art vision models can achieve superhuman performance on image classification tasks when testing and training data come from the same distribution. However, when models are tested on corrupted images (e.g. due to scale changes, translations, or shifts in brightness or contrast), performance degrades significantly. Here, we explore the possibility of meta-training a learned optimizer that can train image classification models such that they are robust to common image corruptions. Specifically, we are interested training models that are more robust to noise distributions not present in the training data. We find that a learned optimizer meta-trained to produce models which are robust to Gaussian noise trains models that are more robust to Gaussian noise at other scales compared to traditional optimizers like Adam. The effect of meta-training is more complicated when targeting a more general set of noise distributions, but led to improved performance on half of held-out corruption tasks. Our results suggest that meta-learning provides a novel approach for studying and improving the robustness of deep learning models.