 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Transport with Tempered Exponential Measures
Sep 07, 2023In the field of optimal transport, two prominent subfields face each other: (i) unregularized optimal transport, ``\`a-la-Kantorovich'', which leads to extremely sparse plans but with algorithms that scale poorly, and (ii) entropic-regularized optimal transport, ``\`a-la-Sinkhorn-Cuturi'', which gets near-linear approximation algorithms but leads to maximally un-sparse plans. In this paper, we show that a generalization of the latter to tempered exponential measures, a generalization of exponential families with indirect measure normalization, gets to a very convenient middle ground, with both very fast approximation algorithms and sparsity which is under control up to sparsity patterns. In addition, it fits naturally in the unbalanced optimal transport problem setting as well.
Benchmarking Neural Network Training Algorithms
Jun 12, 2023



Training algorithms, broadly construed, are an essential part of every deep learning pipeline. Training algorithm improvements that speed up training across a wide variety of workloads (e.g., better update rules, tuning protocols, learning rate schedules, or data selection schemes) could save time, save computational resources, and lead to better, more accurate, models. Unfortunately, as a community, we are currently unable to reliably identify training algorithm improvements, or even determine the state-of-the-art training algorithm. In this work, using concrete experiments, we argue that real progress in speeding up training requires new benchmarks that resolve three basic challenges faced by empirical comparisons of training algorithms: (1) how to decide when training is complete and precisely measure training time, (2) how to handle the sensitivity of measurements to exact workload details, and (3) how to fairly compare algorithms that require hyperparameter tuning. In order to address these challenges, we introduce a new, competitive, time-to-result benchmark using multiple workloads running on fixed hardware, the AlgoPerf: Training Algorithms benchmark. Our benchmark includes a set of workload variants that make it possible to detect benchmark submissions that are more robust to workload changes than current widely-used methods. Finally, we evaluate baseline submissions constructed using various optimizers that represent current practice, as well as other optimizers that have recently received attention in the literature. These baseline results collectively demonstrate the feasibility of our benchmark, show that non-trivial gaps between methods exist, and set a provisional state-of-the-art for future benchmark submissions to try and surpass.
Boosting with Tempered Exponential Measures
Jun 08, 2023



One of the most popular ML algorithms, AdaBoost, can be derived from the dual of a relative entropy minimization problem subject to the fact that the positive weights on the examples sum to one. Essentially, harder examples receive higher probabilities. We generalize this setup to the recently introduced {\it tempered exponential measure}s (TEMs) where normalization is enforced on a specific power of the measure and not the measure itself. TEMs are indexed by a parameter $t$ and generalize exponential families ($t=1$). Our algorithm, $t$-AdaBoost, recovers AdaBoost~as a special case ($t=1$). We show that $t$-AdaBoost retains AdaBoost's celebrated exponential convergence rate when $t\in [0,1)$ while allowing a slight improvement of the rate's hidden constant compared to $t=1$. $t$-AdaBoost partially computes on a generalization of classical arithmetic over the reals and brings notable properties like guaranteed bounded leveraging coefficients for $t\in [0,1)$. From the loss that $t$-AdaBoost minimizes (a generalization of the exponential loss), we show how to derive a new family of {\it tempered} losses for the induction of domain-partitioning classifiers like decision trees. Crucially, strict properness is ensured for all while their boosting rates span the full known spectrum. Experiments using $t$-AdaBoost+trees display that significant leverage can be achieved by tuning $t$.
Harnessing Simulation for Molecular Embeddings
Feb 04, 2023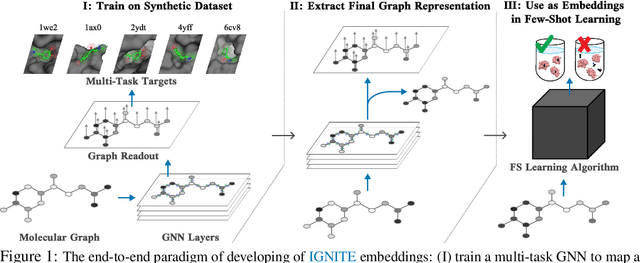

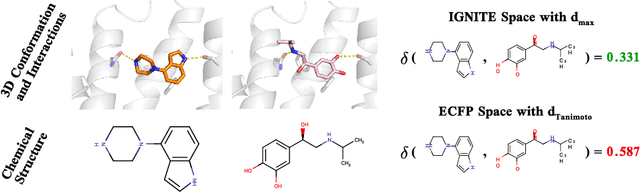
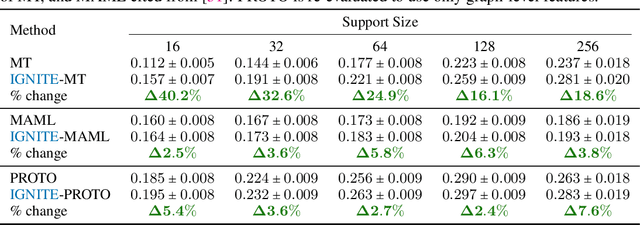
While deep learning has unlocked advances in computational biology once thought to be decades away, extending deep learning techniques to the molecular domain has proven challenging, as labeled data is scarce and the benefit from self-supervised learning can be negligible in many cases. In this work, we explore a different approach. Inspired by methods in deep reinforcement learning and robotics, we explore harnessing physics-based molecular simulation to develop molecular embeddings. By fitting a Graph Neural Network to simulation data, molecules that display similar interactions with biological targets under simulation develop similar representations in the embedding space. These embeddings can then be used to initialize the feature space of down-stream models trained on real-world data to encode information learned during simulation into a molecular prediction task. Our experimental findings indicate this approach improves the performance of existing deep learning models on real-world molecular prediction tasks by as much as 38% with minimal modification to the downstream model and no hyperparameter tuning.
Clustering above Exponential Families with Tempered Exponential Measures
Nov 04, 2022The link with exponential families has allowed $k$-means clustering to be generalized to a wide variety of data generating distributions in exponential families and clustering distortions among Bregman divergences. Getting the framework to work above exponential families is important to lift roadblocks like the lack of robustness of some population minimizers carved in their axiomatization. Current generalisations of exponential families like $q$-exponential families or even deformed exponential families fail at achieving the goal. In this paper, we provide a new attempt at getting the complete framework, grounded in a new generalisation of exponential families that we introduce, tempered exponential measures (TEM). TEMs keep the maximum entropy axiomatization framework of $q$-exponential families, but instead of normalizing the measure, normalize a dual called a co-distribution. Numerous interesting properties arise for clustering such as improved and controllable robustness for population minimizers, that keep a simple analytic form.
Layerwise Bregman Representation Learning with Applications to Knowledge Distillation
Sep 15, 2022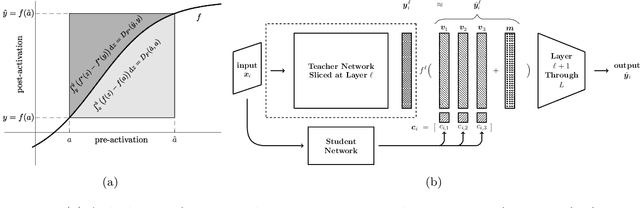
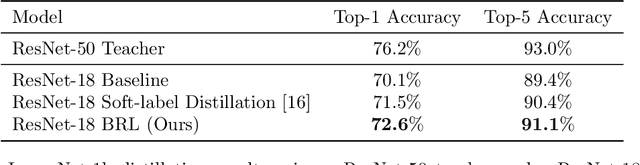
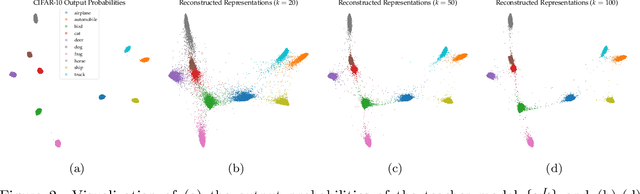
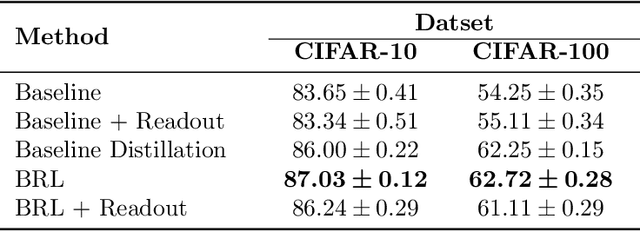
In this work, we propose a novel approach for layerwise representation learning of a trained neural network. In particular, we form a Bregman divergence based on the layer's transfer function and construct an extension of the original Bregman PCA formulation by incorporating a mean vector and normalizing the principal directions with respect to the geometry of the local convex function around the mean. This generalization allows exporting the learned representation as a fixed layer with a non-linearity. As an application to knowledge distillation, we cast the learning problem for the student network as predicting the compression coefficients of the teacher's representations, which are passed as the input to the imported layer. Our empirical findings indicate that our approach is substantially more effective for transferring information between networks than typical teacher-student training using the teacher's penultimate layer representations and soft labels.
To Aggregate or Not? Learning with Separate Noisy Labels
Jun 14, 2022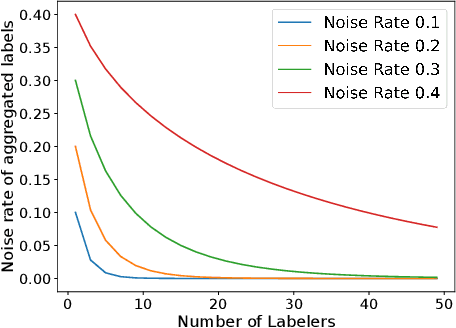
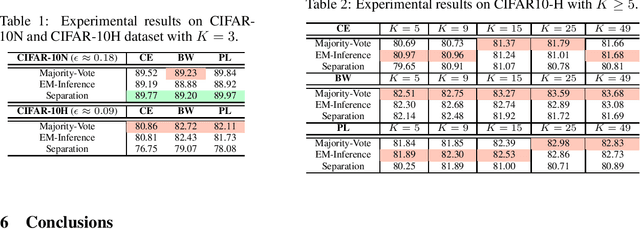
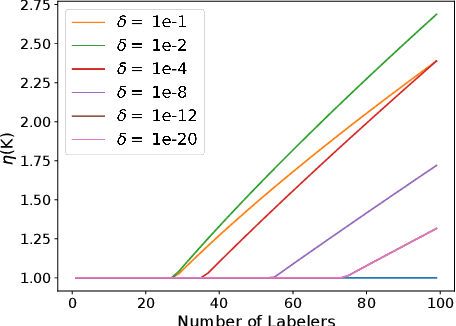
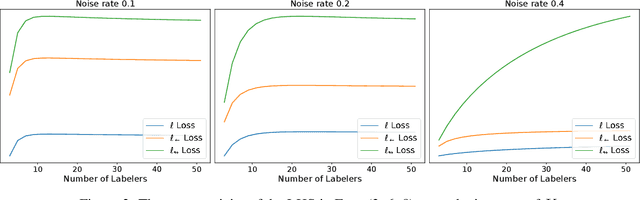
The rawly collected training data often comes with separate noisy labels collected from multiple imperfect annotators (e.g., via crowdsourcing). Typically one would first aggregate the separate noisy labels into one and apply standard training methods. The literature has also studied extensively on effective aggregation approaches. This paper revisits this choice and aims to provide an answer to the question of whether one should aggregate separate noisy labels into single ones or use them separately as given. We theoretically analyze the performance of both approaches under the empirical risk minimization framework for a number of popular loss functions, including the ones designed specifically for the problem of learning with noisy labels. Our theorems conclude that label separation is preferred over label aggregation when the noise rates are high, or the number of labelers/annotations is insufficient. Extensive empirical results validate our conclusion.
Extracting Targeted Training Data from ASR Models, and How to Mitigate It
Apr 18, 2022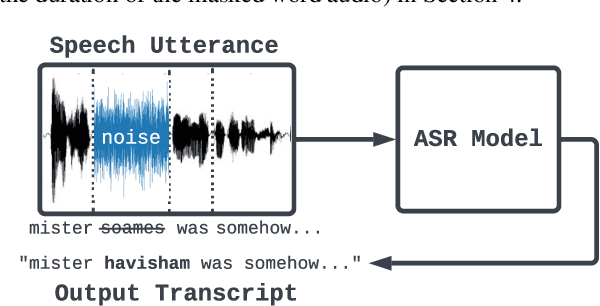
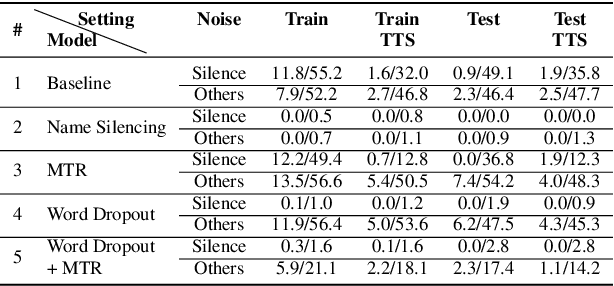
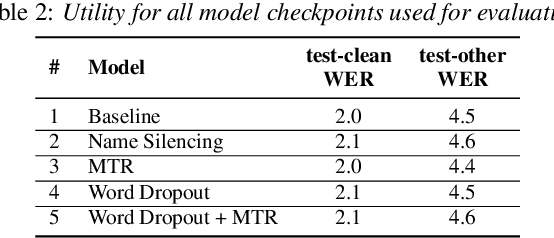
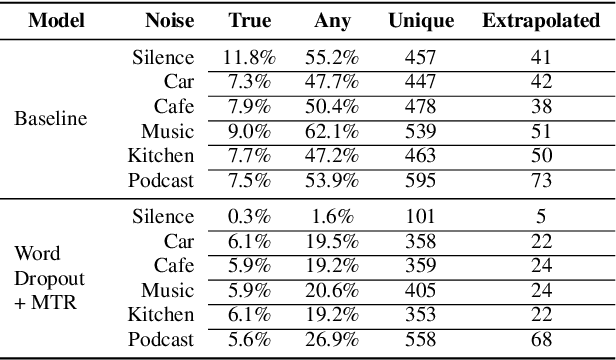
Recent work has designed methods to demonstrate that model updates in ASR training can leak potentially sensitive attributes of the utterances used in computing the updates. In this work, we design the first method to demonstrate information leakage about training data from trained ASR models. We design Noise Masking, a fill-in-the-blank style method for extracting targeted parts of training data from trained ASR models. We demonstrate the success of Noise Masking by using it in four settings for extracting names from the LibriSpeech dataset used for training a SOTA Conformer model. In particular, we show that we are able to extract the correct names from masked training utterances with 11.8% accuracy, while the model outputs some name from the train set 55.2% of the time. Further, we show that even in a setting that uses synthetic audio and partial transcripts from the test set, our method achieves 2.5% correct name accuracy (47.7% any name success rate). Lastly, we design Word Dropout, a data augmentation method that we show when used in training along with MTR, provides comparable utility as the baseline, along with significantly mitigating extraction via Noise Masking across the four evaluated settings.
Learning from Randomly Initialized Neural Network Features
Feb 13, 2022



We present the surprising result that randomly initialized neural networks are good feature extractors in expectation. These random features correspond to finite-sample realizations of what we call Neural Network Prior Kernel (NNPK), which is inherently infinite-dimensional. We conduct ablations across multiple architectures of varying sizes as well as initializations and activation functions. Our analysis suggests that certain structures that manifest in a trained model are already present at initialization. Therefore, NNPK may provide further insight into why neural networks are so effective in learning such structures.
Step-size Adaptation Using Exponentiated Gradient Updates
Jan 31, 2022

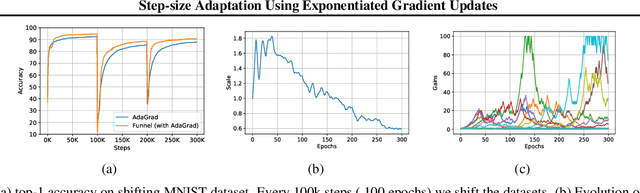
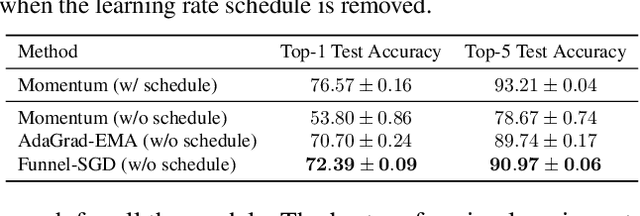
Optimizers like Adam and AdaGrad have been very successful in training large-scale neural networks. Yet, the performance of these methods is heavily dependent on a carefully tuned learning rate schedule. We show that in many large-scale applications, augmenting a given optimizer with an adaptive tuning method of the step-size greatly improves the performance. More precisely, we maintain a global step-size scale for the update as well as a gain factor for each coordinate. We adjust the global scale based on the alignment of the average gradient and the current gradient vectors. A similar approach is used for updating the local gain factors. This type of step-size scale tuning has been done before with gradient descent updates. In this paper, we update the step-size scale and the gain variables with exponentiated gradient updates instead. Experimentally, we show that our approach can achieve compelling accuracy on standard models without using any specially tuned learning rate schedule. We also show the effectiveness of our approach for quickly adapting to distribution shifts in the data during training.