 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Performance and Low-Resource Annotation with Many-Shot In-Context Learning for Named Entity Recognition
Jun 20, 2026In-context learning (ICL) with large language models (LLMs) has emerged as a powerful alternative to fine-tuning for Named Entity Recognition (NER), achieving strong performance with minimal annotation and no additional training. However, prior work has shown that despite their adaptability, LLMs still lag behind fully supervised models such as fine-tuned BERT in structured tasks like NER. While existing studies on ICL for NER have mainly explored few-shot settings, the potential of scaling to hundreds of demonstrations has not been thoroughly investigated. To address this gap, we conduct a comprehensive investigation of many-shot ICL for NER and further explore its effectiveness in annotating and refining data for low-resource NER tasks. Specifically, we evaluate various LLMs across multiple domains using hundreds of ICL examples and then assess the feasibility of using many-shot ICL as a data annotation framework. Our experiments demonstrate that: (1) scaling to hundreds of in-context examples enables LLMs to match or even surpass the performance of fully supervised BERT models; and (2) using about one hundred human-labeled examples as demonstrations, many-shot in-context annotation can generate high-quality labeled data, leading to approximately 10% absolute F1 improvement over existing state-of-the-art approaches when used to fine-tune BERT on low-resource NER.
The Overlooked Repetitive Lengthening Form in Sentiment Analysis
Apr 01, 2026Individuals engaging in online communication frequently express personal opinions with informal styles (e.g., memes and emojis). While Language Models (LMs) with informal communications have been widely discussed, a unique and emphatic style, the Repetitive Lengthening Form (RLF), has been overlooked for years. In this paper, we explore answers to two research questions: 1) Is RLF important for sentiment analysis (SA)? 2) Can LMs understand RLF? Inspired by previous linguistic research, we curate \textbf{Lengthening}, the first multi-domain dataset with 850k samples focused on RLF for SA. Moreover, we introduce \textbf{Exp}lainable \textbf{Instruct}ion Tuning (\textbf{ExpInstruct}), a two-stage instruction tuning framework aimed to improve both performance and explainability of LLMs for RLF. We further propose a novel unified approach to quantify LMs' understanding of informal expressions. We show that RLF sentences are expressive expressions and can serve as signatures of document-level sentiment. Additionally, RLF has potential value for online content analysis. Our results show that fine-tuned Pre-trained Language Models (PLMs) can surpass zero-shot GPT-4 in performance but not in explanation for RLF. Finally, we show ExpInstruct can improve the open-sourced LLMs to match zero-shot GPT-4 in performance and explainability for RLF with limited samples. Code and sample data are available at https://github.com/Tom-Owl/OverlookedRLF
* Findings of EMNLP 2024
DanceHA: A Multi-Agent Framework for Document-Level Aspect-Based Sentiment Analysis
Mar 17, 2026Aspect-Based Sentiment Intensity Analysis (ABSIA) has garnered increasing attention, though research largely focuses on domain-specific, sentence-level settings. In contrast, document-level ABSIA--particularly in addressing complex tasks like extracting Aspect-Category-Opinion-Sentiment-Intensity (ACOSI) tuples--remains underexplored. In this work, we introduce DanceHA, a multi-agent framework designed for open-ended, document-level ABSIA with informal writing styles. DanceHA has two main components: Dance, which employs a divide-and-conquer strategy to decompose the long-context ABSIA task into smaller, manageable sub-tasks for collaboration among specialized agents; and HA, Human-AI collaboration for annotation. We release Inf-ABSIA, a multi-domain document-level ABSIA dataset featuring fine-grained and high-accuracy labels from DanceHA. Extensive experiments demonstrate the effectiveness of our agentic framework and show that the multi-agent knowledge in DanceHA can be effectively transferred into student models. Our results highlight the importance of the overlooked informal styles in ABSIA, as they often intensify opinions tied to specific aspects.
DynClean: Training Dynamics-based Label Cleaning for Distantly-Supervised Named Entity Recognition
Apr 06, 2025Distantly Supervised Named Entity Recognition (DS-NER) has attracted attention due to its scalability and ability to automatically generate labeled data. However, distant annotation introduces many mislabeled instances, limiting its performance. Most of the existing work attempt to solve this problem by developing intricate models to learn from the noisy labels. An alternative approach is to attempt to clean the labeled data, thus increasing the quality of distant labels. This approach has received little attention for NER. In this paper, we propose a training dynamics-based label cleaning approach, which leverages the behavior of a model as training progresses to characterize the distantly annotated samples. We also introduce an automatic threshold estimation strategy to locate the errors in distant labels. Extensive experimental results demonstrate that: (1) models trained on our cleaned DS-NER datasets, which were refined by directly removing identified erroneous annotations, achieve significant improvements in F1-score, ranging from 3.18% to 8.95%; and (2) our method outperforms numerous advanced DS-NER approaches across four datasets.
SciER: An Entity and Relation Extraction Dataset for Datasets, Methods, and Tasks in Scientific Documents
Oct 28, 2024



Scientific information extraction (SciIE) is critical for converting unstructured knowledge from scholarly articles into structured data (entities and relations). Several datasets have been proposed for training and validating SciIE models. However, due to the high complexity and cost of annotating scientific texts, those datasets restrict their annotations to specific parts of paper, such as abstracts, resulting in the loss of diverse entity mentions and relations in context. In this paper, we release a new entity and relation extraction dataset for entities related to datasets, methods, and tasks in scientific articles. Our dataset contains 106 manually annotated full-text scientific publications with over 24k entities and 12k relations. To capture the intricate use and interactions among entities in full texts, our dataset contains a fine-grained tag set for relations. Additionally, we provide an out-of-distribution test set to offer a more realistic evaluation. We conduct comprehensive experiments, including state-of-the-art supervised models and our proposed LLM-based baselines, and highlight the challenges presented by our dataset, encouraging the development of innovative models to further the field of SciIE.
FlowLearn: Evaluating Large Vision-Language Models on Flowchart Understanding
Jul 09, 2024



Flowcharts are graphical tools for representing complex concepts in concise visual representations. This paper introduces the FlowLearn dataset, a resource tailored to enhance the understanding of flowcharts. FlowLearn contains complex scientific flowcharts and simulated flowcharts. The scientific subset contains 3,858 flowcharts sourced from scientific literature and the simulated subset contains 10,000 flowcharts created using a customizable script. The dataset is enriched with annotations for visual components, OCR, Mermaid code representation, and VQA question-answer pairs. Despite the proven capabilities of Large Vision-Language Models (LVLMs) in various visual understanding tasks, their effectiveness in decoding flowcharts - a crucial element of scientific communication - has yet to be thoroughly investigated. The FlowLearn test set is crafted to assess the performance of LVLMs in flowchart comprehension. Our study thoroughly evaluates state-of-the-art LVLMs, identifying existing limitations and establishing a foundation for future enhancements in this relatively underexplored domain. For instance, in tasks involving simulated flowcharts, GPT-4V achieved the highest accuracy (58%) in counting the number of nodes, while Claude recorded the highest accuracy (83%) in OCR tasks. Notably, no single model excels in all tasks within the FlowLearn framework, highlighting significant opportunities for further development.
SciDMT: A Large-Scale Corpus for Detecting Scientific Mentions
Jun 20, 2024



We present SciDMT, an enhanced and expanded corpus for scientific mention detection, offering a significant advancement over existing related resources. SciDMT contains annotated scientific documents for datasets (D), methods (M), and tasks (T). The corpus consists of two components: 1) the SciDMT main corpus, which includes 48 thousand scientific articles with over 1.8 million weakly annotated mention annotations in the format of in-text span, and 2) an evaluation set, which comprises 100 scientific articles manually annotated for evaluation purposes. To the best of our knowledge, SciDMT is the largest corpus for scientific entity mention detection. The corpus's scale and diversity are instrumental in developing and refining models for tasks such as indexing scientific papers, enhancing information retrieval, and improving the accessibility of scientific knowledge. We demonstrate the corpus's utility through experiments with advanced deep learning architectures like SciBERT and GPT-3.5. Our findings establish performance baselines and highlight unresolved challenges in scientific mention detection. SciDMT serves as a robust benchmark for the research community, encouraging the development of innovative models to further the field of scientific information extraction.
* LREC/COLING 2024
DMDD: A Large-Scale Dataset for Dataset Mentions Detection
May 19, 2023The recognition of dataset names is a critical task for automatic information extraction in scientific literature, enabling researchers to understand and identify research opportunities. However, existing corpora for dataset mention detection are limited in size and naming diversity. In this paper, we introduce the Dataset Mentions Detection Dataset (DMDD), the largest publicly available corpus for this task. DMDD consists of the DMDD main corpus, comprising 31,219 scientific articles with over 449,000 dataset mentions weakly annotated in the format of in-text spans, and an evaluation set, which comprises of 450 scientific articles manually annotated for evaluation purposes. We use DMDD to establish baseline performance for dataset mention detection and linking. By analyzing the performance of various models on DMDD, we are able to identify open problems in dataset mention detection. We invite the community to use our dataset as a challenge to develop novel dataset mention detection models.
Stay on Topic, Please: Aligning User Comments to the Content of a News Article
Mar 03, 2021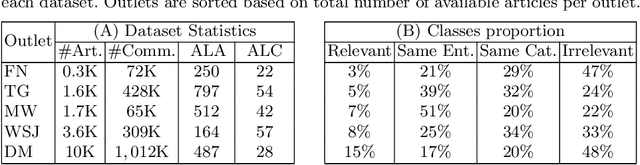

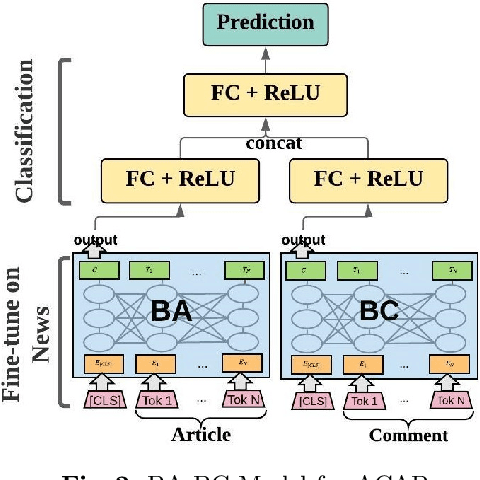
Social scientists have shown that up to 50% if the content posted to a news article have no relation to its journalistic content. In this study we propose a classification algorithm to categorize user comments posted to a new article base don their alignment to its content. The alignment seek to match user comments to an article based on similarity off content, entities in discussion, and topic. We proposed a BERTAC, BAERT-based approach that learn jointly article-comment embeddings and infers the relevance class of comments. We introduce an ordinal classification loss that penalizes the difference between the predicted and true label. We conduct a thorough study to show influence of the proposed loss on the learning process. The results on five representative news outlets show that our approach can learn the comment class with up to 36% average accuracy improvement compering to the baselines, and up to 25% compering to the BA-BC model. BA-BC is out approach that consists of two models aimed to capture dis-jointly the formal language of news articles and the informal language of comments. We also conduct a user study to evaluate human labeling performance to understand the difficulty of the classification task. The user agreement on comment-article alignment is "moderate" per Krippendorff's alpha score, which suggests that the classification task is difficult.
Birds of a Feather Flock Together: Satirical News Detection via Language Model Differentiation
Jul 04, 2020
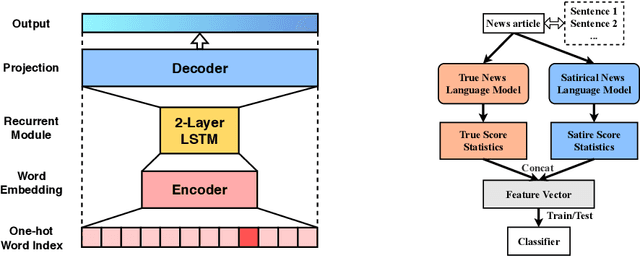
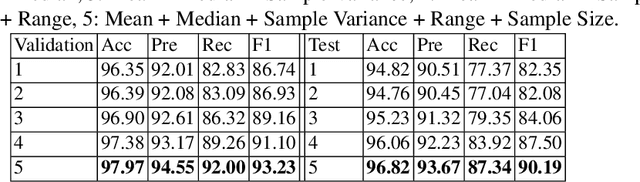
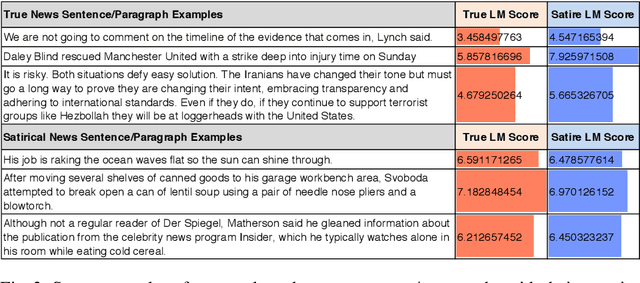
Satirical news is regularly shared in modern social media because it is entertaining with smartly embedded humor. However, it can be harmful to society because it can sometimes be mistaken as factual news, due to its deceptive character. We found that in satirical news, the lexical and pragmatical attributes of the context are the key factors in amusing the readers. In this work, we propose a method that differentiates the satirical news and true news. It takes advantage of satirical writing evidence by leveraging the difference between the prediction loss of two language models, one trained on true news and the other on satirical news, when given a new news article. We compute several statistical metrics of language model prediction loss as features, which are then used to conduct downstream classification. The proposed method is computationally effective because the language models capture the language usage differences between satirical news documents and traditional news documents, and are sensitive when applied to documents outside their domains.