 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnergy-Based Transformers as Predictors of Reading Difficulty
Jun 22, 2026Transformer language models have become established tools for modeling human sentence processing, with measures such as surprisal and attention entropy serving as effective predictors of reading difficulty that together capture complementary aspects of processing load. Here, we explore a related class of transformer models: energy-based transformers, which provide a principled formal link to associative memory models, bringing processing research into direct contact with the broader literature on Hopfield networks and dense associative memory. To our knowledge, this is the first exploration of an energy-based transformer measure in computational psycholinguistics. Across reading-time corpora (Natural Stories, UCL eye-tracking, UCL self-paced reading), the energy measure is a robust predictor of reading times, providing significant fit beyond surprisal in all three. In a controlled experiment on relative clause processing, energy at a single layer captures the well-known object/subject asymmetry. We find evidence that it subsumes effects attributable to both attention entropy and surprisal, suggesting that energy may serve as a single unified predictor where multiple complementary measures have previously been required.
When Context Misleads: Surprisal, Energy and Attention Entropy as Metrics of Coherence Illusions in LLMs
Jun 19, 2026Psycholinguistics studies show that human readers fall for coherence illusions: an incoherent discourse can seem coherent simply because a distractor matches what comes next. We investigate whether Dutch language models (6 monolingual and 4 multilingual) show the same behavior on texts that link back to earlier context with words such as 'again' and 'too'. First, we find that surprisal at the critical word tracks human acceptability judgments and eye-tracking data. Models are more surprised by incoherent continuations, but a matching distractor in the prior context reduces this surprisal. Second, attention entropy at the critical position identifies heads that behave differently under coherence vs. incoherence. We find that ablating these heads shows transfer effects across experiments, suggesting a shared mechanism. Third, we introduce energy from the associative-memory literature as a metric to quantify discourse coherence. Taken together, our results show that coherence illusions arise in Dutch LLMs, with entropy and energy exposing mechanisms that operate across settings.
Model Merging to Maintain Language-Only Performance in Developmentally Plausible Multimodal Models
Oct 02, 2025



State-of-the-art vision-and-language models consist of many parameters and learn from enormous datasets, surpassing the amounts of linguistic data that children are exposed to as they acquire a language. This paper presents our approach to the multimodal track of the BabyLM challenge addressing this discrepancy. We develop language-only and multimodal models in low-resource settings using developmentally plausible datasets, with our multimodal models outperforming previous BabyLM baselines. One finding in the multimodal language model literature is that these models tend to underperform in \textit{language-only} tasks. Therefore, we focus on maintaining language-only abilities in multimodal models. To this end, we experiment with \textit{model merging}, where we fuse the parameters of multimodal models with those of language-only models using weighted linear interpolation. Our results corroborate the findings that multimodal models underperform in language-only benchmarks that focus on grammar, and model merging with text-only models can help alleviate this problem to some extent, while maintaining multimodal performance.
LLMs instead of Human Judges? A Large Scale Empirical Study across 20 NLP Evaluation Tasks
Jun 26, 2024



There is an increasing trend towards evaluating NLP models with LLM-generated judgments instead of human judgments. In the absence of a comparison against human data, this raises concerns about the validity of these evaluations; in case they are conducted with proprietary models, this also raises concerns over reproducibility. We provide JUDGE-BENCH, a collection of 20 NLP datasets with human annotations, and comprehensively evaluate 11 current LLMs, covering both open-weight and proprietary models, for their ability to replicate the annotations. Our evaluations show that each LLM exhibits a large variance across datasets in its correlation to human judgments. We conclude that LLMs are not yet ready to systematically replace human judges in NLP.
Decoding Emotions in Abstract Art: Cognitive Plausibility of CLIP in Recognizing Color-Emotion Associations
May 10, 2024



This study investigates the cognitive plausibility of a pretrained multimodal model, CLIP, in recognizing emotions evoked by abstract visual art. We employ a dataset comprising images with associated emotion labels and textual rationales of these labels provided by human annotators. We perform linguistic analyses of rationales, zero-shot emotion classification of images and rationales, apply similarity-based prediction of emotion, and investigate color-emotion associations. The relatively low, yet above baseline, accuracy in recognizing emotion for abstract images and rationales suggests that CLIP decodes emotional complexities in a manner not well aligned with human cognitive processes. Furthermore, we explore color-emotion interactions in images and rationales. Expected color-emotion associations, such as red relating to anger, are identified in images and texts annotated with emotion labels by both humans and CLIP, with the latter showing even stronger interactions. Our results highlight the disparity between human processing and machine processing when connecting image features and emotions.
Describing Images $\textit{Fast and Slow}$: Quantifying and Predicting the Variation in Human Signals during Visuo-Linguistic Processes
Feb 02, 2024



There is an intricate relation between the properties of an image and how humans behave while describing the image. This behavior shows ample variation, as manifested in human signals such as eye movements and when humans start to describe the image. Despite the value of such signals of visuo-linguistic variation, they are virtually disregarded in the training of current pretrained models, which motivates further investigation. Using a corpus of Dutch image descriptions with concurrently collected eye-tracking data, we explore the nature of the variation in visuo-linguistic signals, and find that they correlate with each other. Given this result, we hypothesize that variation stems partly from the properties of the images, and explore whether image representations encoded by pretrained vision encoders can capture such variation. Our results indicate that pretrained models do so to a weak-to-moderate degree, suggesting that the models lack biases about what makes a stimulus complex for humans and what leads to variations in human outputs.
Speaking the Language of Your Listener: Audience-Aware Adaptation via Plug-and-Play Theory of Mind
May 31, 2023



Dialogue participants may have varying levels of knowledge about the topic under discussion. In such cases, it is essential for speakers to adapt their utterances by taking their audience into account. Yet, it is an open question how such adaptation can be modelled in computational agents. In this paper, we model a visually grounded referential game between a knowledgeable speaker and a listener with more limited visual and linguistic experience. Inspired by psycholinguistic theories, we endow our speaker with the ability to adapt its referring expressions via a simulation module that monitors the effectiveness of planned utterances from the listener's perspective. We propose an adaptation mechanism building on plug-and-play approaches to controlled language generation, where utterance generation is steered on the fly by the simulator without finetuning the speaker's underlying language model. Our results and analyses show that our approach is effective: the speaker's utterances become closer to the listener's domain of expertise, which leads to higher communicative success.
Generating Image Descriptions via Sequential Cross-Modal Alignment Guided by Human Gaze
Nov 09, 2020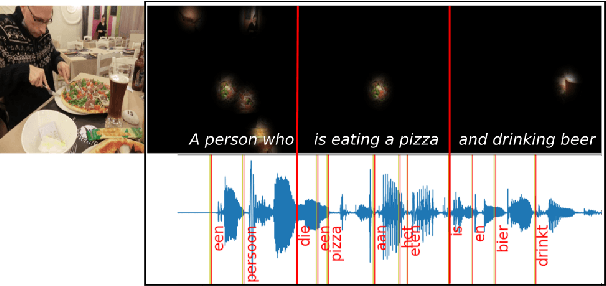
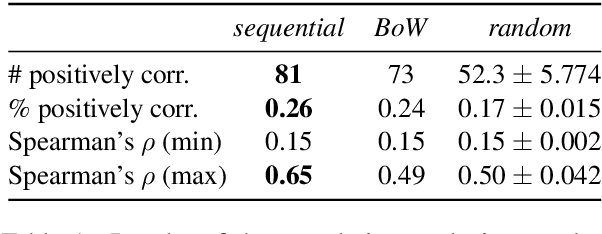

When speakers describe an image, they tend to look at objects before mentioning them. In this paper, we investigate such sequential cross-modal alignment by modelling the image description generation process computationally. We take as our starting point a state-of-the-art image captioning system and develop several model variants that exploit information from human gaze patterns recorded during language production. In particular, we propose the first approach to image description generation where visual processing is modelled $\textit{sequentially}$. Our experiments and analyses confirm that better descriptions can be obtained by exploiting gaze-driven attention and shed light on human cognitive processes by comparing different ways of aligning the gaze modality with language production. We find that processing gaze data sequentially leads to descriptions that are better aligned to those produced by speakers, more diverse, and more natural${-}$particularly when gaze is encoded with a dedicated recurrent component.
Refer, Reuse, Reduce: Generating Subsequent References in Visual and Conversational Contexts
Nov 09, 2020

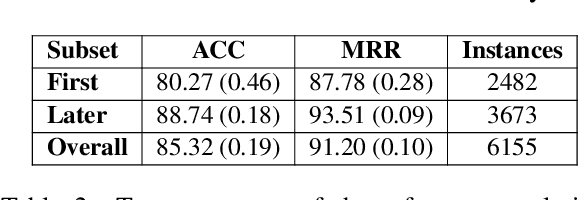
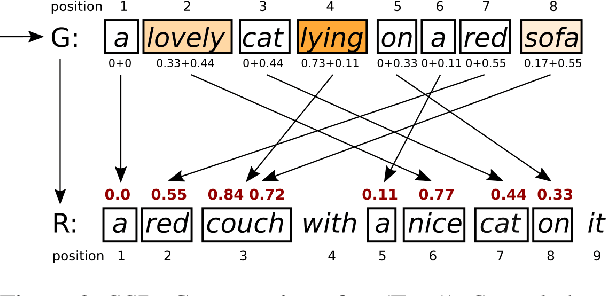
Dialogue participants often refer to entities or situations repeatedly within a conversation, which contributes to its cohesiveness. Subsequent references exploit the common ground accumulated by the interlocutors and hence have several interesting properties, namely, they tend to be shorter and reuse expressions that were effective in previous mentions. In this paper, we tackle the generation of first and subsequent references in visually grounded dialogue. We propose a generation model that produces referring utterances grounded in both the visual and the conversational context. To assess the referring effectiveness of its output, we also implement a reference resolution system. Our experiments and analyses show that the model produces better, more effective referring utterances than a model not grounded in the dialogue context, and generates subsequent references that exhibit linguistic patterns akin to humans.
The PhotoBook Dataset: Building Common Ground through Visually-Grounded Dialogue
Jun 04, 2019
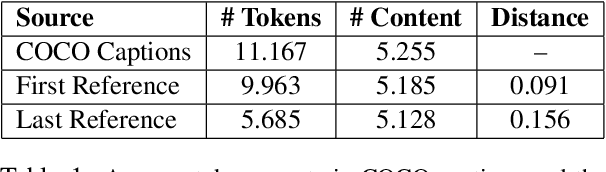
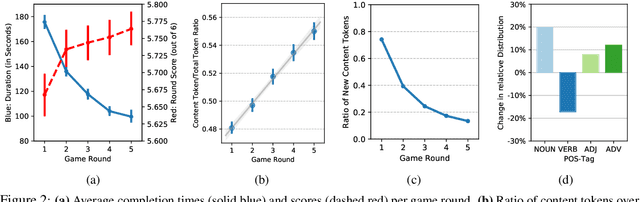
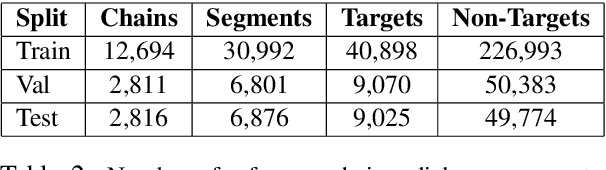
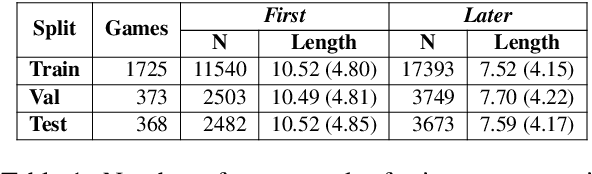
This paper introduces the PhotoBook dataset, a large-scale collection of visually-grounded, task-oriented dialogues in English designed to investigate shared dialogue history accumulating during conversation. Taking inspiration from seminal work on dialogue analysis, we propose a data-collection task formulated as a collaborative game prompting two online participants to refer to images utilising both their visual context as well as previously established referring expressions. We provide a detailed description of the task setup and a thorough analysis of the 2,500 dialogues collected. To further illustrate the novel features of the dataset, we propose a baseline model for reference resolution which uses a simple method to take into account shared information accumulated in a reference chain. Our results show that this information is particularly important to resolve later descriptions and underline the need to develop more sophisticated models of common ground in dialogue interaction.