 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFAIR AI Models in High Energy Physics
Dec 21, 2022The findable, accessible, interoperable, and reusable (FAIR) data principles have provided a framework for examining, evaluating, and improving how we share data with the aim of facilitating scientific discovery. Efforts have been made to generalize these principles to research software and other digital products. Artificial intelligence (AI) models -- algorithms that have been trained on data rather than explicitly programmed -- are an important target for this because of the ever-increasing pace with which AI is transforming scientific and engineering domains. In this paper, we propose a practical definition of FAIR principles for AI models and create a FAIR AI project template that promotes adherence to these principles. We demonstrate how to implement these principles using a concrete example from experimental high energy physics: a graph neural network for identifying Higgs bosons decaying to bottom quarks. We study the robustness of these FAIR AI models and their portability across hardware architectures and software frameworks, and report new insights on the interpretability of AI predictions by studying the interplay between FAIR datasets and AI models. Enabled by publishing FAIR AI models, these studies pave the way toward reliable and automated AI-driven scientific discovery.
End-to-end AI Framework for Hyperparameter Optimization, Model Training, and Interpretable Inference for Molecules and Crystals
Dec 21, 2022We introduce an end-to-end computational framework that enables hyperparameter optimization with the DeepHyper library, accelerated training, and interpretable AI inference with a suite of state-of-the-art AI models, including CGCNN, PhysNet, SchNet, MPNN, MPNN-transformer, and TorchMD-Net. We use these AI models and the benchmark QM9, hMOF, and MD17 datasets to showcase the prediction of user-specified materials properties in modern computing environments, and to demonstrate translational applications for the modeling of small molecules, crystals and metal organic frameworks with a unified, stand-alone framework. We deployed and tested this framework in the ThetaGPU supercomputer at the Argonne Leadership Computing Facility, and the Delta supercomputer at the National Center for Supercomputing Applications to provide researchers with modern tools to conduct accelerated AI-driven discovery in leadership class computing environments.
MLGWSC-1: The first Machine Learning Gravitational-Wave Search Mock Data Challenge
Sep 22, 2022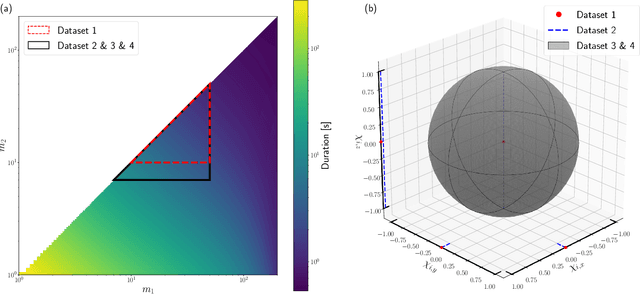
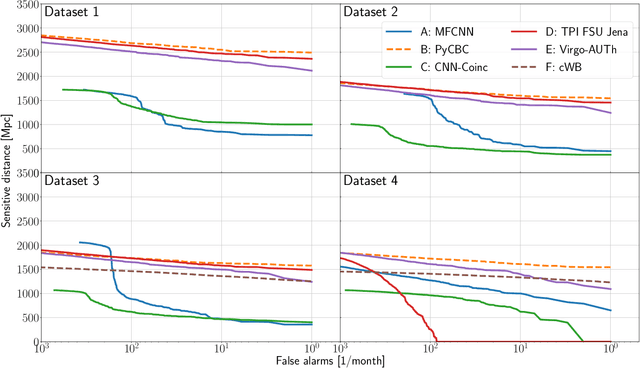
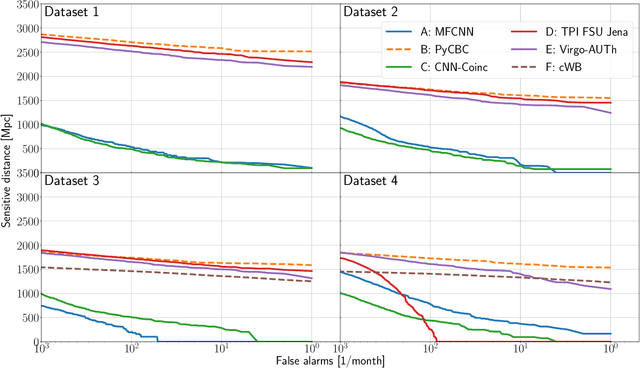
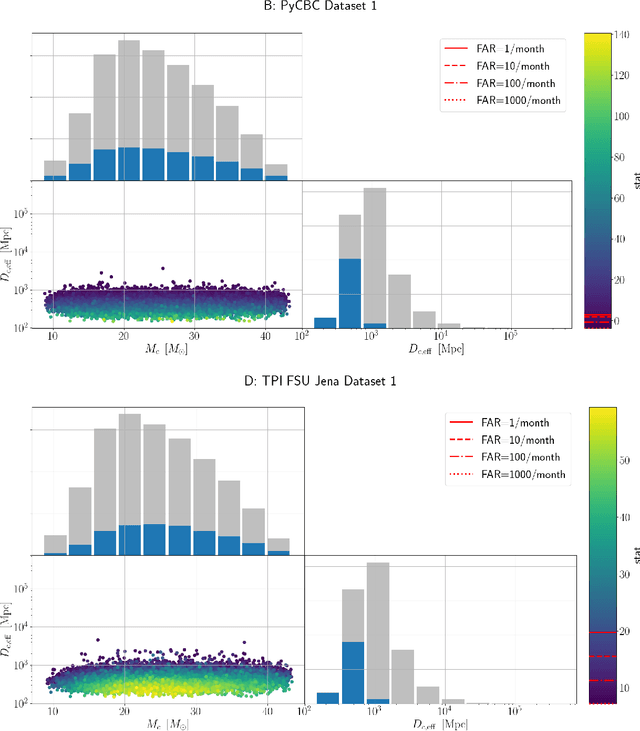
We present the results of the first Machine Learning Gravitational-Wave Search Mock Data Challenge (MLGWSC-1). For this challenge, participating groups had to identify gravitational-wave signals from binary black hole mergers of increasing complexity and duration embedded in progressively more realistic noise. The final of the 4 provided datasets contained real noise from the O3a observing run and signals up to a duration of 20 seconds with the inclusion of precession effects and higher order modes. We present the average sensitivity distance and runtime for the 6 entered algorithms derived from 1 month of test data unknown to the participants prior to submission. Of these, 4 are machine learning algorithms. We find that the best machine learning based algorithms are able to achieve up to 95% of the sensitive distance of matched-filtering based production analyses for simulated Gaussian noise at a false-alarm rate (FAR) of one per month. In contrast, for real noise, the leading machine learning search achieved 70%. For higher FARs the differences in sensitive distance shrink to the point where select machine learning submissions outperform traditional search algorithms at FARs $\geq 200$ per month on some datasets. Our results show that current machine learning search algorithms may already be sensitive enough in limited parameter regions to be useful for some production settings. To improve the state-of-the-art, machine learning algorithms need to reduce the false-alarm rates at which they are capable of detecting signals and extend their validity to regions of parameter space where modeled searches are computationally expensive to run. Based on our findings we compile a list of research areas that we believe are the most important to elevate machine learning searches to an invaluable tool in gravitational-wave signal detection.
FAIR principles for AI models, with a practical application for accelerated high energy diffraction microscopy
Jul 14, 2022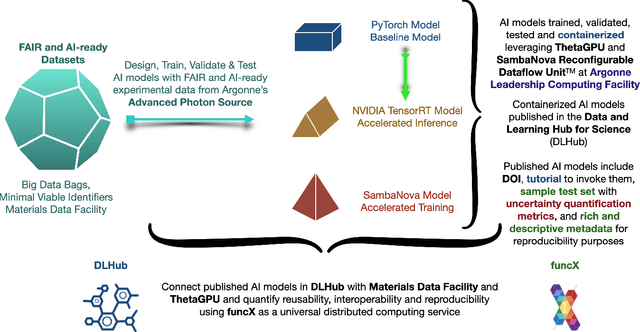
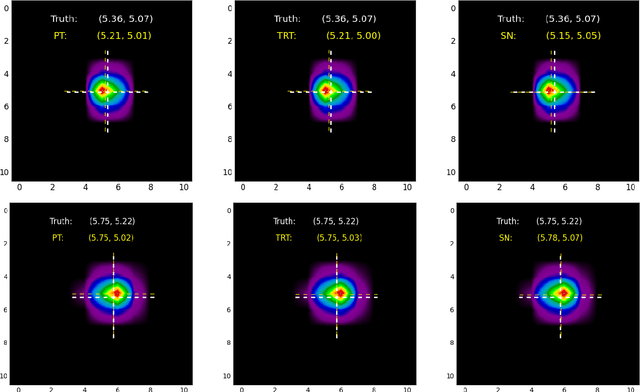
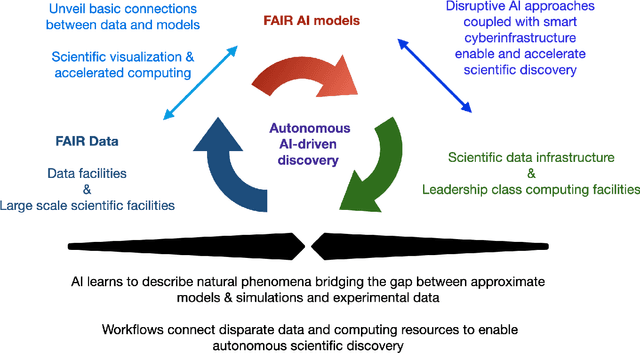
A concise and measurable set of FAIR (Findable, Accessible, Interoperable and Reusable) principles for scientific data is transforming the state-of-practice for data management and stewardship, supporting and enabling discovery and innovation. Learning from this initiative, and acknowledging the impact of artificial intelligence (AI) in the practice of science and engineering, we introduce a set of practical, concise, and measurable FAIR principles for AI models. We showcase how to create and share FAIR data and AI models within a unified computational framework combining the following elements: the Advanced Photon Source at Argonne National Laboratory, the Materials Data Facility, the Data and Learning Hub for Science, and funcX, and the Argonne Leadership Computing Facility (ALCF), in particular the ThetaGPU supercomputer and the SambaNova DataScale system at the ALCF AI Testbed. We describe how this domain-agnostic computational framework may be harnessed to enable autonomous AI-driven discovery.
Applications of physics informed neural operators
Mar 23, 2022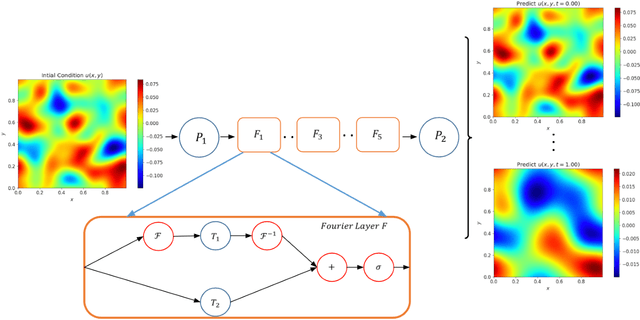
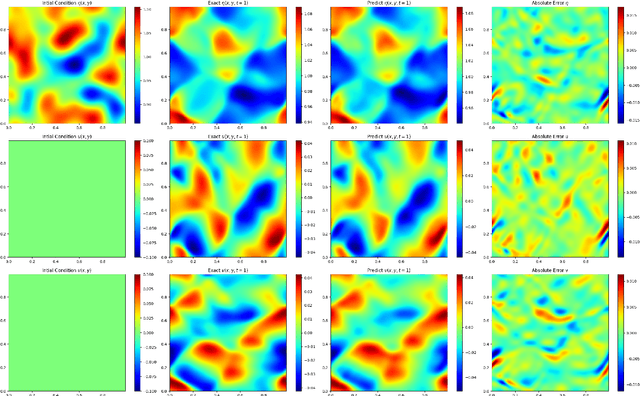
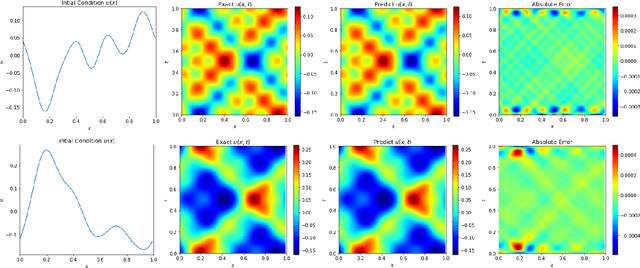
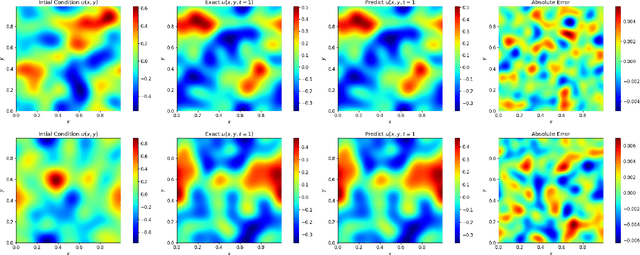
We present an end-to-end framework to learn partial differential equations that brings together initial data production, selection of boundary conditions, and the use of physics-informed neural operators to solve partial differential equations that are ubiquitous in the study and modeling of physics phenomena. We first demonstrate that our methods reproduce the accuracy and performance of other neural operators published elsewhere in the literature to learn the 1D wave equation and the 1D Burgers equation. Thereafter, we apply our physics-informed neural operators to learn new types of equations, including the 2D Burgers equation in the scalar, inviscid and vector types. Finally, we show that our approach is also applicable to learn the physics of the 2D linear and nonlinear shallow water equations, which involve three coupled partial differential equations. We release our artificial intelligence surrogates and scientific software to produce initial data and boundary conditions to study a broad range of physically motivated scenarios. We provide the source code, an interactive website to visualize the predictions of our physics informed neural operators, and a tutorial for their use at the Data and Learning Hub for Science.
Interpreting a Machine Learning Model for Detecting Gravitational Waves
Feb 15, 2022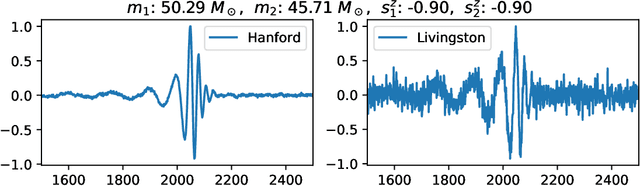
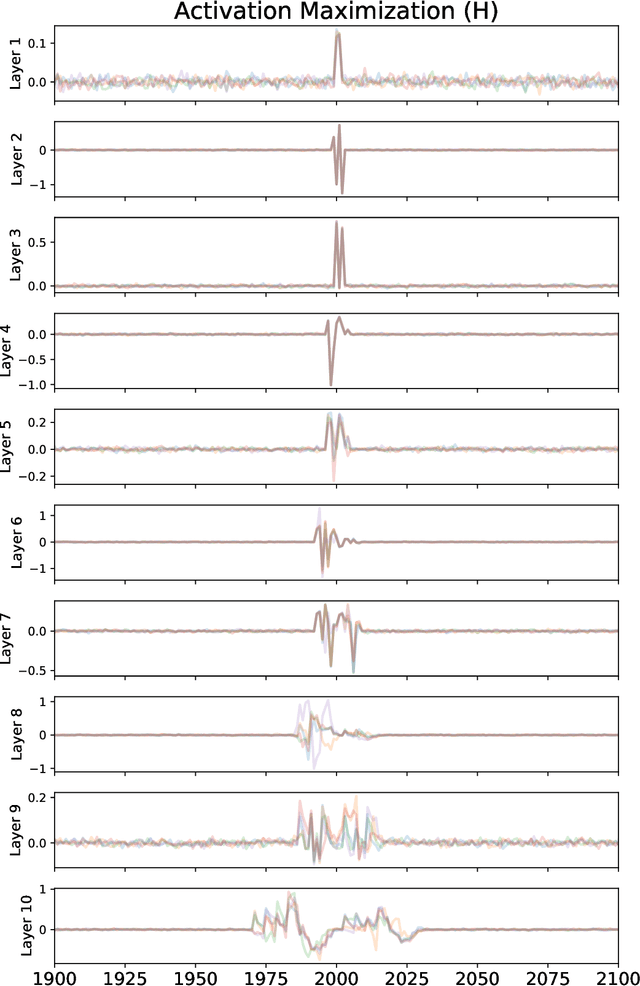
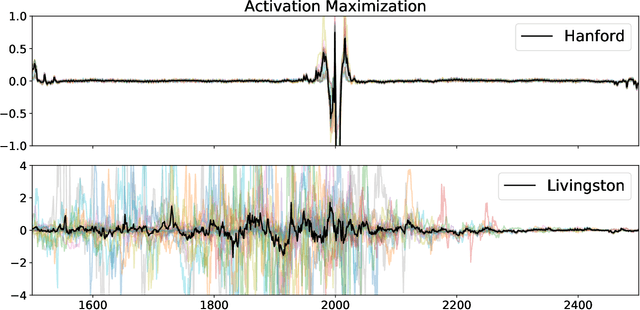
We describe a case study of translational research, applying interpretability techniques developed for computer vision to machine learning models used to search for and find gravitational waves. The models we study are trained to detect black hole merger events in non-Gaussian and non-stationary advanced Laser Interferometer Gravitational-wave Observatory (LIGO) data. We produced visualizations of the response of machine learning models when they process advanced LIGO data that contains real gravitational wave signals, noise anomalies, and pure advanced LIGO noise. Our findings shed light on the responses of individual neurons in these machine learning models. Further analysis suggests that different parts of the network appear to specialize in local versus global features, and that this difference appears to be rooted in the branched architecture of the network as well as noise characteristics of the LIGO detectors. We believe efforts to whiten these "black box" models can suggest future avenues for research and help inform the design of interpretable machine learning models for gravitational wave astrophysics.
Inference-optimized AI and high performance computing for gravitational wave detection at scale
Jan 26, 2022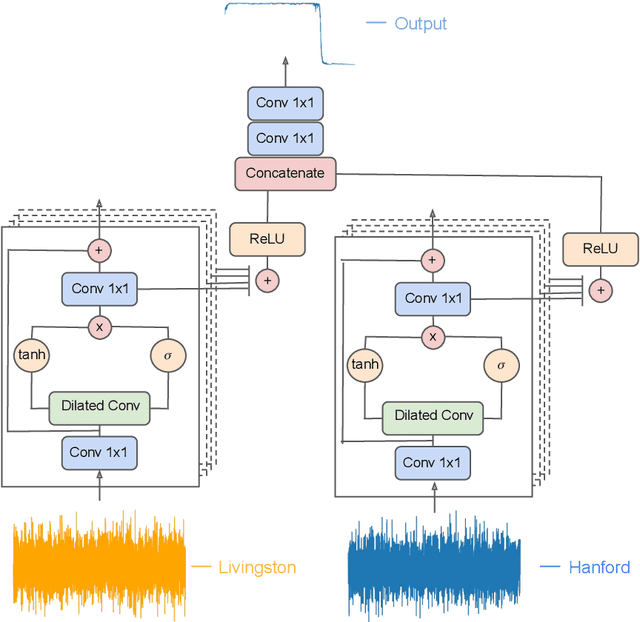
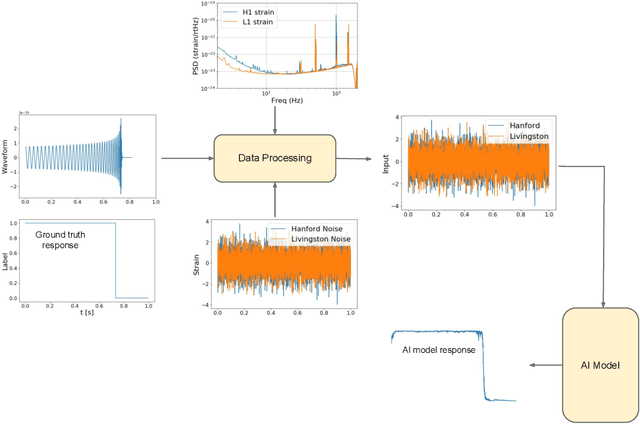
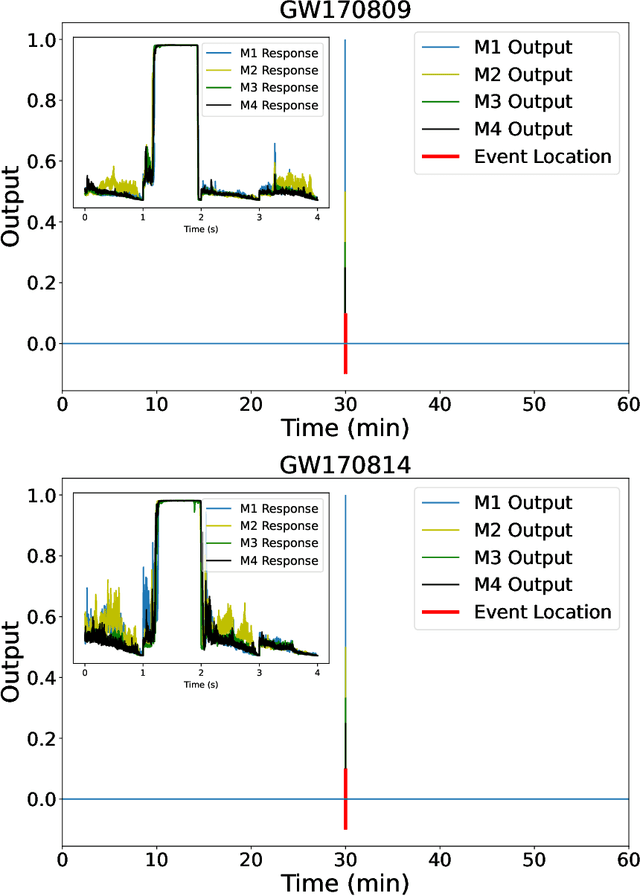
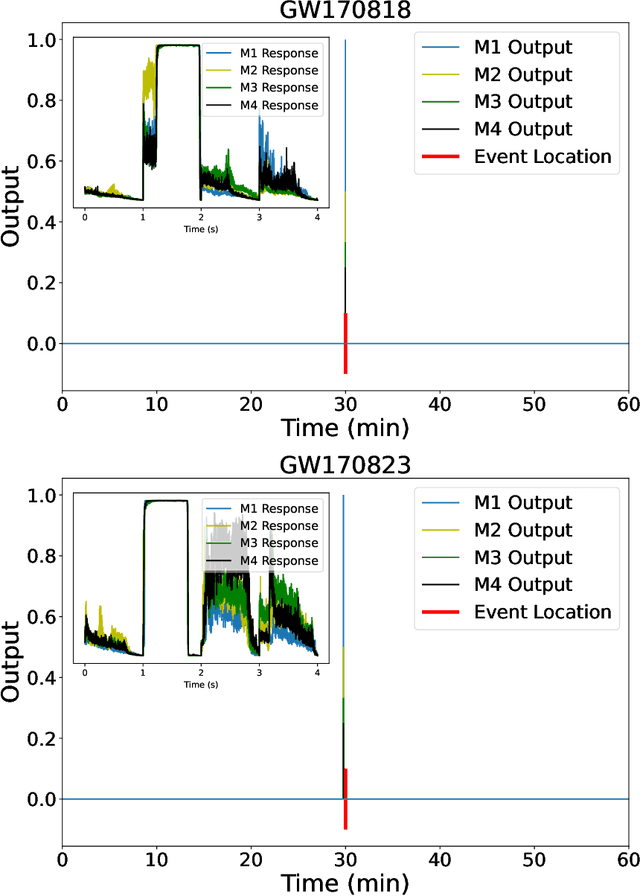
We introduce an ensemble of artificial intelligence models for gravitational wave detection that we trained in the Summit supercomputer using 32 nodes, equivalent to 192 NVIDIA V100 GPUs, within 2 hours. Once fully trained, we optimized these models for accelerated inference using NVIDIA TensorRT. We deployed our inference-optimized AI ensemble in the ThetaGPU supercomputer at Argonne Leadership Computer Facility to conduct distributed inference. Using the entire ThetaGPU supercomputer, consisting of 20 nodes each of which has 8 NVIDIA A100 Tensor Core GPUs and 2 AMD Rome CPUs, our NVIDIA TensorRT-optimized AI ensemble porcessed an entire month of advanced LIGO data (including Hanford and Livingston data streams) within 50 seconds. Our inference-optimized AI ensemble retains the same sensitivity of traditional AI models, namely, it identifies all known binary black hole mergers previously identified in this advanced LIGO dataset and reports no misclassifications, while also providing a 3X inference speedup compared to traditional artificial intelligence models. We used time slides to quantify the performance of our AI ensemble to process up to 5 years worth of advanced LIGO data. In this synthetically enhanced dataset, our AI ensemble reports an average of one misclassification for every month of searched advanced LIGO data. We also present the receiver operating characteristic curve of our AI ensemble using this 5 year long advanced LIGO dataset. This approach provides the required tools to conduct accelerated, AI-driven gravitational wave detection at scale.
AI and extreme scale computing to learn and infer the physics of higher order gravitational wave modes of quasi-circular, spinning, non-precessing binary black hole mergers
Dec 13, 2021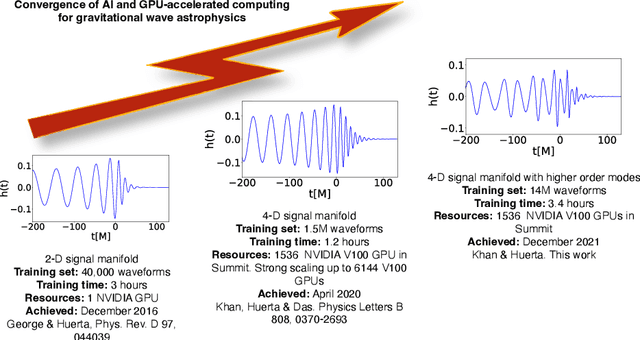
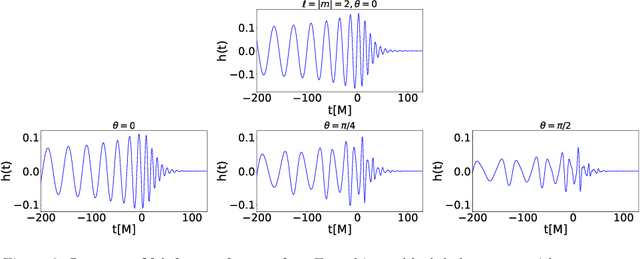
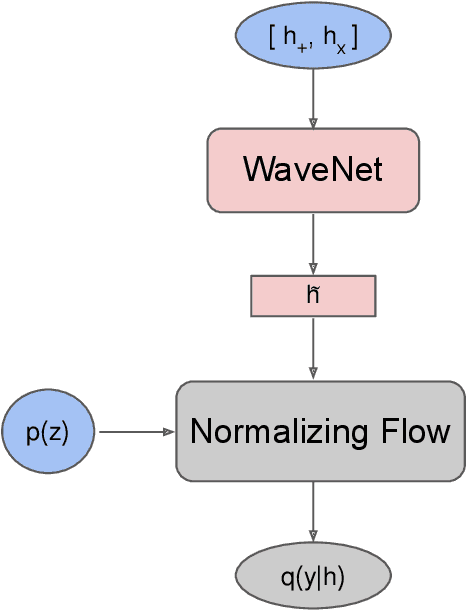
We use artificial intelligence (AI) to learn and infer the physics of higher order gravitational wave modes of quasi-circular, spinning, non precessing binary black hole mergers. We trained AI models using 14 million waveforms, produced with the surrogate model NRHybSur3dq8, that include modes up to $\ell \leq 4$ and $(5,5)$, except for $(4,0)$ and $(4,1)$, that describe binaries with mass-ratios $q\leq8$ and individual spins $s^z_{\{1,2\}}\in[-0.8, 0.8]$. We use our AI models to obtain deterministic and probabilistic estimates of the mass-ratio, individual spins, effective spin, and inclination angle of numerical relativity waveforms that describe such signal manifold. Our studies indicate that AI provides informative estimates for these physical parameters. This work marks the first time AI is capable of characterizing this high-dimensional signal manifold. Our AI models were trained within 3.4 hours using distributed training on 256 nodes (1,536 NVIDIA V100 GPUs) in the Summit supercomputer.
Interpretable AI forecasting for numerical relativity waveforms of quasi-circular, spinning, non-precessing binary black hole mergers
Oct 13, 2021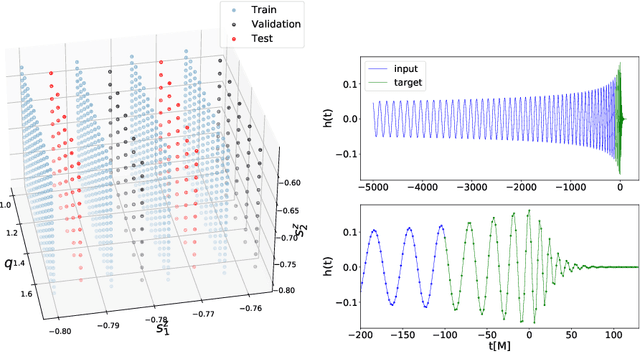
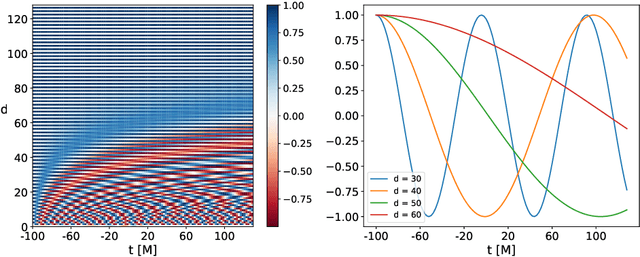
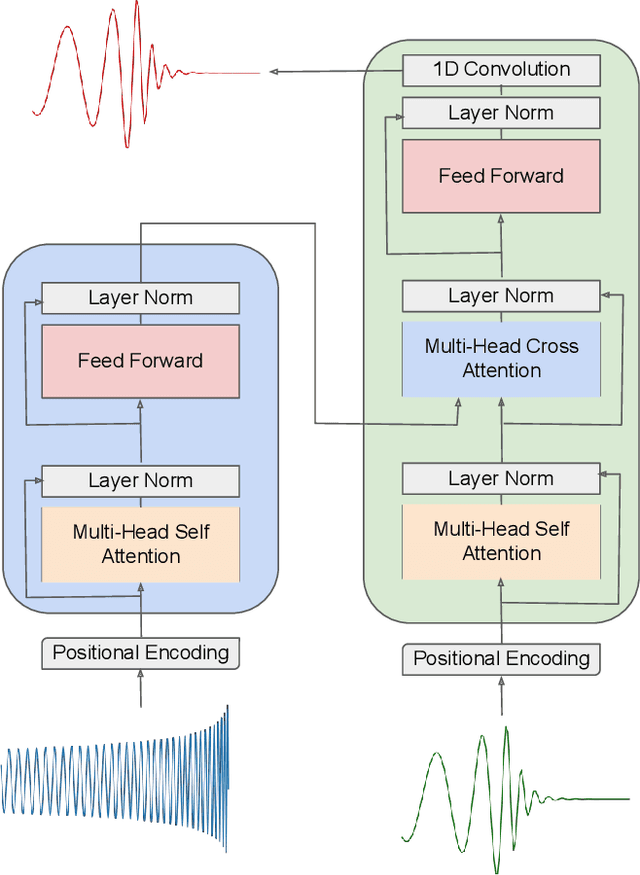
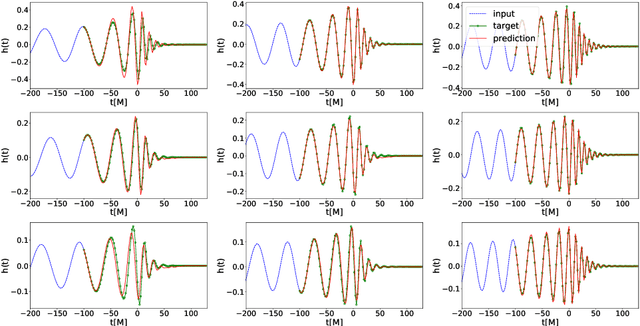
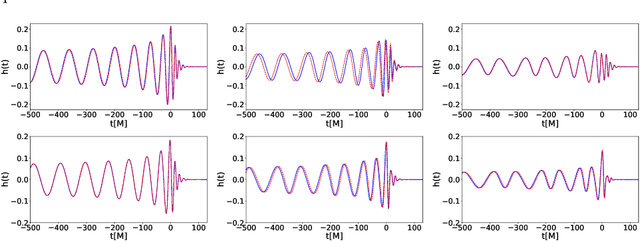
We present a deep-learning artificial intelligence model that is capable of learning and forecasting the late-inspiral, merger and ringdown of numerical relativity waveforms that describe quasi-circular, spinning, non-precessing binary black hole mergers. We used the NRHybSur3dq8 surrogate model to produce train, validation and test sets of $\ell=|m|=2$ waveforms that cover the parameter space of binary black hole mergers with mass-ratios $q\leq8$ and individual spins $|s^z_{\{1,2\}}| \leq 0.8$. These waveforms cover the time range $t\in[-5000\textrm{M}, 130\textrm{M}]$, where $t=0M$ marks the merger event, defined as the maximum value of the waveform amplitude. We harnessed the ThetaGPU supercomputer at the Argonne Leadership Computing Facility to train our AI model using a training set of 1.5 million waveforms. We used 16 NVIDIA DGX A100 nodes, each consisting of 8 NVIDIA A100 Tensor Core GPUs and 2 AMD Rome CPUs, to fully train our model within 3.5 hours. Our findings show that artificial intelligence can accurately forecast the dynamical evolution of numerical relativity waveforms in the time range $t\in[-100\textrm{M}, 130\textrm{M}]$. Sampling a test set of 190,000 waveforms, we find that the average overlap between target and predicted waveforms is $\gtrsim99\%$ over the entire parameter space under consideration. We also combined scientific visualization and accelerated computing to identify what components of our model take in knowledge from the early and late-time waveform evolution to accurately forecast the latter part of numerical relativity waveforms. This work aims to accelerate the creation of scalable, computationally efficient and interpretable artificial intelligence models for gravitational wave astrophysics.
A FAIR and AI-ready Higgs Boson Decay Dataset
Aug 04, 2021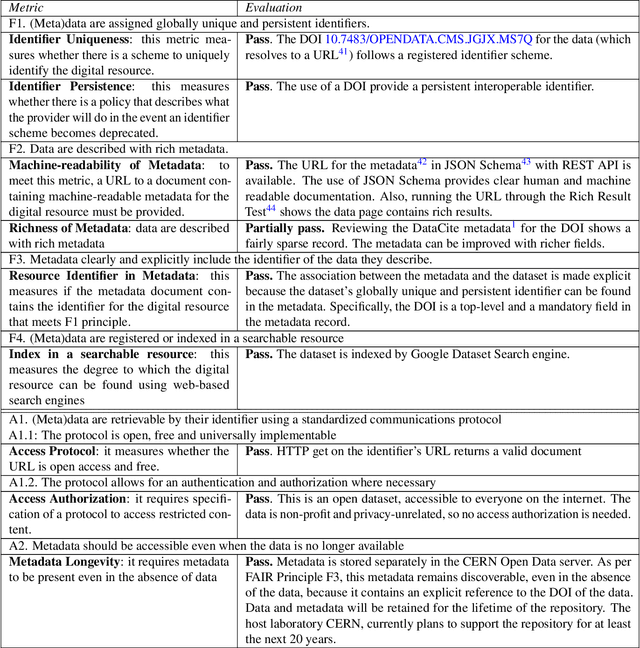
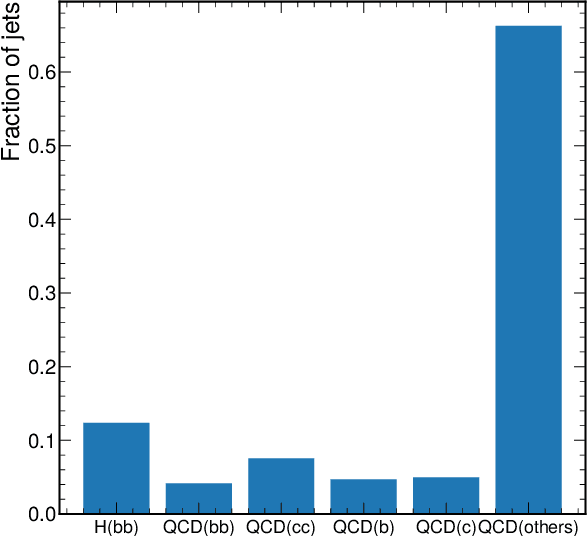
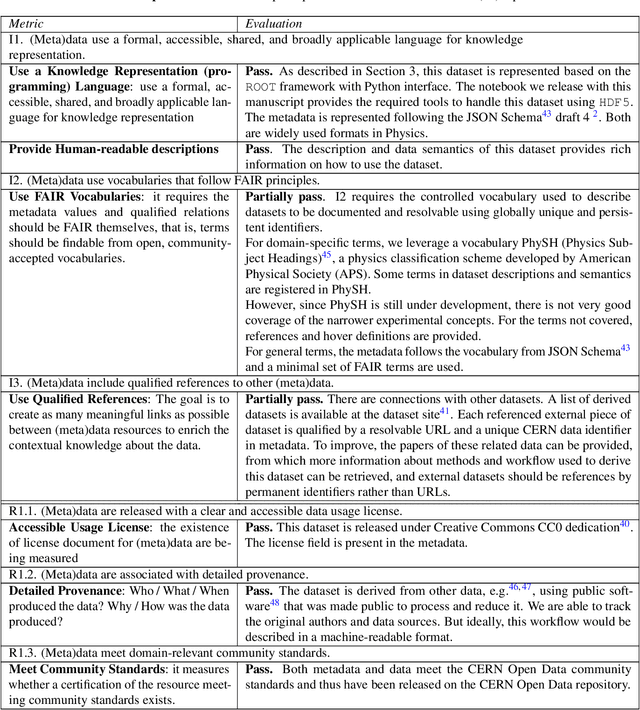
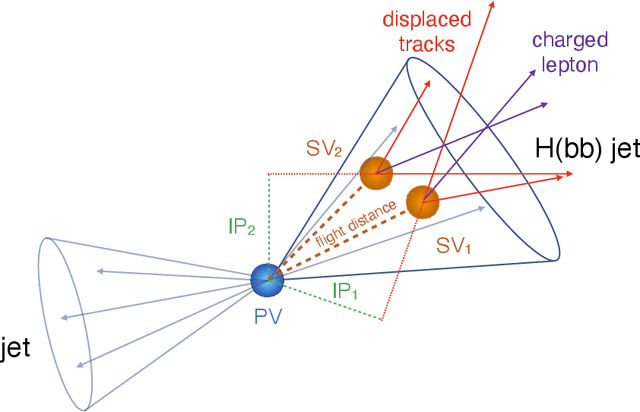
To enable the reusability of massive scientific datasets by humans and machines, researchers aim to create scientific datasets that adhere to the principles of findability, accessibility, interoperability, and reusability (FAIR) for data and artificial intelligence (AI) models. This article provides a domain-agnostic, step-by-step assessment guide to evaluate whether or not a given dataset meets each FAIR principle. We then demonstrate how to use this guide to evaluate the FAIRness of an open simulated dataset produced by the CMS Collaboration at the CERN Large Hadron Collider. This dataset consists of Higgs boson decays and quark and gluon background, and is available through the CERN Open Data Portal. We also use other available tools to assess the FAIRness of this dataset, and incorporate feedback from members of the FAIR community to validate our results. This article is accompanied by a Jupyter notebook to facilitate an understanding and exploration of the dataset, including visualization of its elements. This study marks the first in a planned series of articles that will guide scientists in the creation and quantification of FAIRness in high energy particle physics datasets and AI models.