 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInstitutional Books 1.0: A 242B token dataset from Harvard Library's collections, refined for accuracy and usability
Jun 10, 2025



Large language models (LLMs) use data to learn about the world in order to produce meaningful correlations and predictions. As such, the nature, scale, quality, and diversity of the datasets used to train these models, or to support their work at inference time, have a direct impact on their quality. The rapid development and adoption of LLMs of varying quality has brought into focus the scarcity of publicly available, high-quality training data and revealed an urgent need to ground the stewardship of these datasets in sustainable practices with clear provenance chains. To that end, this technical report introduces Institutional Books 1.0, a large collection of public domain books originally digitized through Harvard Library's participation in the Google Books project, beginning in 2006. Working with Harvard Library, we extracted, analyzed, and processed these volumes into an extensively-documented dataset of historic texts. This analysis covers the entirety of Harvard Library's collection scanned as part of that project, originally spanning 1,075,899 volumes written in over 250 different languages for a total of approximately 250 billion tokens. As part of this initial release, the OCR-extracted text (original and post-processed) as well as the metadata (bibliographic, source, and generated) of the 983,004 volumes, or 242B tokens, identified as being in the public domain have been made available. This report describes this project's goals and methods as well as the results of the analyses we performed, all in service of making this historical collection more accessible and easier for humans and machines alike to filter, read and use.
14 Examples of How LLMs Can Transform Materials Science and Chemistry: A Reflection on a Large Language Model Hackathon
Jun 13, 2023



Chemistry and materials science are complex. Recently, there have been great successes in addressing this complexity using data-driven or computational techniques. Yet, the necessity of input structured in very specific forms and the fact that there is an ever-growing number of tools creates usability and accessibility challenges. Coupled with the reality that much data in these disciplines is unstructured, the effectiveness of these tools is limited. Motivated by recent works that indicated that large language models (LLMs) might help address some of these issues, we organized a hackathon event on the applications of LLMs in chemistry, materials science, and beyond. This article chronicles the projects built as part of this hackathon. Participants employed LLMs for various applications, including predicting properties of molecules and materials, designing novel interfaces for tools, extracting knowledge from unstructured data, and developing new educational applications. The diverse topics and the fact that working prototypes could be generated in less than two days highlight that LLMs will profoundly impact the future of our fields. The rich collection of ideas and projects also indicates that the applications of LLMs are not limited to materials science and chemistry but offer potential benefits to a wide range of scientific disciplines.
FAIR principles for AI models, with a practical application for accelerated high energy diffraction microscopy
Jul 14, 2022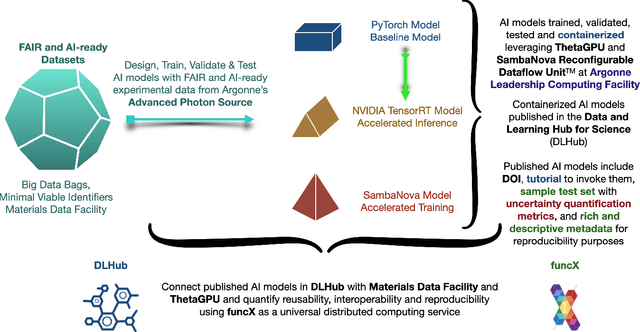
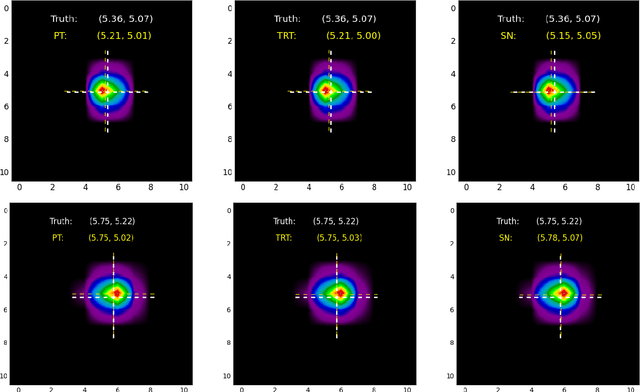
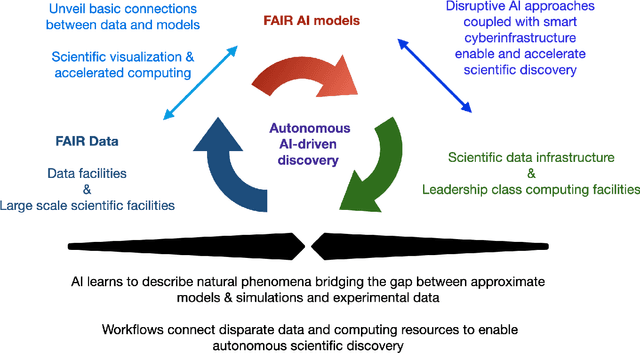
A concise and measurable set of FAIR (Findable, Accessible, Interoperable and Reusable) principles for scientific data is transforming the state-of-practice for data management and stewardship, supporting and enabling discovery and innovation. Learning from this initiative, and acknowledging the impact of artificial intelligence (AI) in the practice of science and engineering, we introduce a set of practical, concise, and measurable FAIR principles for AI models. We showcase how to create and share FAIR data and AI models within a unified computational framework combining the following elements: the Advanced Photon Source at Argonne National Laboratory, the Materials Data Facility, the Data and Learning Hub for Science, and funcX, and the Argonne Leadership Computing Facility (ALCF), in particular the ThetaGPU supercomputer and the SambaNova DataScale system at the ALCF AI Testbed. We describe how this domain-agnostic computational framework may be harnessed to enable autonomous AI-driven discovery.