 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Street to Orbit: Training-Free Cross-View Retrieval via Location Semantics and LLM Guidance
Nov 12, 2025Cross-view image retrieval, particularly street-to-satellite matching, is a critical task for applications such as autonomous navigation, urban planning, and localization in GPS-denied environments. However, existing approaches often require supervised training on curated datasets and rely on panoramic or UAV-based images, which limits real-world deployment. In this paper, we present a simple yet effective cross-view image retrieval framework that leverages a pretrained vision encoder and a large language model (LLM), requiring no additional training. Given a monocular street-view image, our method extracts geographic cues through web-based image search and LLM-based location inference, generates a satellite query via geocoding API, and retrieves matching tiles using a pretrained vision encoder (e.g., DINOv2) with PCA-based whitening feature refinement. Despite using no ground-truth supervision or finetuning, our proposed method outperforms prior learning-based approaches on the benchmark dataset under zero-shot settings. Moreover, our pipeline enables automatic construction of semantically aligned street-to-satellite datasets, which is offering a scalable and cost-efficient alternative to manual annotation. All source codes will be made publicly available at https://jeonghomin.github.io/street2orbit.github.io/.
Dual-Stream Diffusion for World-Model Augmented Vision-Language-Action Model
Oct 31, 2025Recently, augmenting Vision-Language-Action models (VLAs) with world modeling has shown promise in improving robotic policy learning. However, it remains challenging to jointly predict next-state observations and action sequences because of the inherent difference between the two modalities. To address this, we propose DUal-STream diffusion (DUST), a world-model augmented VLA framework that handles the modality conflict and enhances the performance of VLAs across diverse tasks. Specifically, we propose a multimodal diffusion transformer architecture that explicitly maintains separate modality streams while still enabling cross-modal knowledge sharing. In addition, we introduce independent noise perturbations for each modality and a decoupled flow-matching loss. This design enables the model to learn the joint distribution in a bidirectional manner while avoiding the need for a unified latent space. Based on the decoupling of modalities during training, we also introduce a joint sampling method that supports test-time scaling, where action and vision tokens evolve asynchronously at different rates. Through experiments on simulated benchmarks such as RoboCasa and GR-1, DUST achieves up to 6% gains over baseline methods, while our test-time scaling approach provides an additional 2-5% boost. On real-world tasks with the Franka Research 3, DUST improves success rates by 13%, confirming its effectiveness beyond simulation. Furthermore, pre-training on action-free videos from BridgeV2 yields significant transfer gains on RoboCasa, underscoring DUST's potential for large-scale VLA pretraining.
Contrastive Representation Regularization for Vision-Language-Action Models
Oct 02, 2025Vision-Language-Action (VLA) models have shown its capabilities in robot manipulation by leveraging rich representations from pre-trained Vision-Language Models (VLMs). However, their representations arguably remain suboptimal, lacking sensitivity to robotic signals such as control actions and proprioceptive states. To address the issue, we introduce Robot State-aware Contrastive Loss (RS-CL), a simple and effective representation regularization for VLA models, designed to bridge the gap between VLM representations and robotic signals. In particular, RS-CL aligns the representations more closely with the robot's proprioceptive states, by using relative distances between the states as soft supervision. Complementing the original action prediction objective, RS-CL effectively enhances control-relevant representation learning, while being lightweight and fully compatible with standard VLA training pipeline. Our empirical results demonstrate that RS-CL substantially improves the manipulation performance of state-of-the-art VLA models; it pushes the prior art from 30.8% to 41.5% on pick-and-place tasks in RoboCasa-Kitchen, through more accurate positioning during grasping and placing, and boosts success rates from 45.0% to 58.3% on challenging real-robot manipulation tasks.
Collaborative LLM Inference via Planning for Efficient Reasoning
Jun 13, 2025



Large language models (LLMs) excel at complex reasoning tasks, but those with strong capabilities (e.g., whose numbers of parameters are larger than 100B) are often accessible only through paid APIs, making them too costly for applications of frequent use. In contrast, smaller open-sourced LLMs (e.g., whose numbers of parameters are less than 3B) are freely available and easy to deploy locally (e.g., under a single GPU having 8G VRAM), but lack suff icient reasoning ability. This trade-off raises a natural question: can small (free) and large (costly) models collaborate at test time to combine their strengths? We propose a test-time collaboration framework in which a planner model first generates a plan, defined as a distilled and high-level abstraction of the problem. This plan serves as a lightweight intermediate that guides a reasoner model, which generates a complete solution. Small and large models take turns acting as planner and reasoner, exchanging plans in a multi-round cascade to collaboratively solve complex tasks. Our method achieves accuracy comparable to strong proprietary models alone, while significantly reducing reliance on paid inference. These results highlight planning as an effective prior for orchestrating cost-aware, cross-model inference under real-world deployment constraints.
ORIDa: Object-centric Real-world Image Composition Dataset
Jun 10, 2025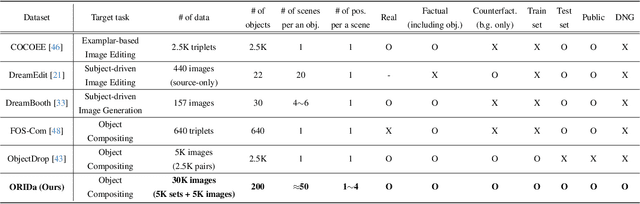



Object compositing, the task of placing and harmonizing objects in images of diverse visual scenes, has become an important task in computer vision with the rise of generative models. However, existing datasets lack the diversity and scale required to comprehensively explore real-world scenarios. We introduce ORIDa (Object-centric Real-world Image Composition Dataset), a large-scale, real-captured dataset containing over 30,000 images featuring 200 unique objects, each of which is presented across varied positions and scenes. ORIDa has two types of data: factual-counterfactual sets and factual-only scenes. The factual-counterfactual sets consist of four factual images showing an object in different positions within a scene and a single counterfactual (or background) image of the scene without the object, resulting in five images per scene. The factual-only scenes include a single image containing an object in a specific context, expanding the variety of environments. To our knowledge, ORIDa is the first publicly available dataset with its scale and complexity for real-world image composition. Extensive analysis and experiments highlight the value of ORIDa as a resource for advancing further research in object compositing.
CCMNet: Leveraging Calibrated Color Correction Matrices for Cross-Camera Color Constancy
Apr 10, 2025



Computational color constancy, or white balancing, is a key module in a camera's image signal processor (ISP) that corrects color casts from scene lighting. Because this operation occurs in the camera-specific raw color space, white balance algorithms must adapt to different cameras. This paper introduces a learning-based method for cross-camera color constancy that generalizes to new cameras without retraining. Our method leverages pre-calibrated color correction matrices (CCMs) available on ISPs that map the camera's raw color space to a standard space (e.g., CIE XYZ). Our method uses these CCMs to transform predefined illumination colors (i.e., along the Planckian locus) into the test camera's raw space. The mapped illuminants are encoded into a compact camera fingerprint embedding (CFE) that enables the network to adapt to unseen cameras. To prevent overfitting due to limited cameras and CCMs during training, we introduce a data augmentation technique that interpolates between cameras and their CCMs. Experimental results across multiple datasets and backbones show that our method achieves state-of-the-art cross-camera color constancy while remaining lightweight and relying only on data readily available in camera ISPs.
Learning to Correct for QA Reasoning with Black-box LLMs
Jun 26, 2024



An open challenge in recent machine learning is about how to improve the reasoning capability of large language models (LLMs) in a black-box setting, i.e., without access to detailed information such as output token probabilities. Existing approaches either rely on accessibility (which is often unrealistic) or involve significantly increased train- and inference-time costs. This paper addresses those limitations or shortcomings by proposing a novel approach, namely CoBB (Correct for improving QA reasoning of Black-Box LLMs). It uses a trained adaptation model to perform a seq2seq mapping from the often-imperfect reasonings of the original black-box LLM to the correct or improved reasonings. Specifically, the adaptation model is initialized with a relatively small open-source LLM and adapted over a collection of sub-sampled training pairs. To select the representative pairs of correct and incorrect reasonings, we formulated the dataset construction as an optimization problem that minimizes the statistical divergence between the sampled subset and the entire collection, and solved it via a genetic algorithm. We then train the adaptation model over the sampled pairs by contrasting the likelihoods of correct and incorrect reasonings. Our experimental results demonstrate that CoBB significantly improves reasoning accuracy across various QA benchmarks, compared to the best-performing adaptation baselines.
Aligning Large Language Models with Self-generated Preference Data
Jun 06, 2024



Aligning large language models (LLMs) with human preferences becomes a key component to obtaining state-of-the-art performance, but it yields a huge cost to construct a large human-annotated preference dataset. To tackle this problem, we propose a new framework that boosts the alignment of LLMs through Self-generated Preference data (Selfie) using only a very small amount of human-annotated preference data. Our key idea is leveraging the human prior knowledge within the small (seed) data and progressively improving the alignment of LLM, by iteratively generating the responses and learning from them with the self-annotated preference data. To be specific, we propose to derive the preference label from the logits of LLM to explicitly extract the model's inherent preference. Compared to the previous approaches using external reward models or implicit in-context learning, we observe that the proposed approach is significantly more effective. In addition, we introduce a noise-aware preference learning algorithm to mitigate the risk of low quality within generated preference data. Our experimental results demonstrate that the proposed framework significantly boosts the alignment of LLMs. For example, we achieve superior alignment performance on AlpacaEval 2.0 with only 3.3\% of the ground-truth preference labels in the Ultrafeedback data compared to the cases using the entire data or state-of-the-art baselines.
CLIP-Guided Attribute Aware Pretraining for Generalizable Image Quality Assessment
Jun 03, 2024In no-reference image quality assessment (NR-IQA), the challenge of limited dataset sizes hampers the development of robust and generalizable models. Conventional methods address this issue by utilizing large datasets to extract rich representations for IQA. Also, some approaches propose vision language models (VLM) based IQA, but the domain gap between generic VLM and IQA constrains their scalability. In this work, we propose a novel pretraining framework that constructs a generalizable representation for IQA by selectively extracting quality-related knowledge from VLM and leveraging the scalability of large datasets. Specifically, we carefully select optimal text prompts for five representative image quality attributes and use VLM to generate pseudo-labels. Numerous attribute-aware pseudo-labels can be generated with large image datasets, allowing our IQA model to learn rich representations about image quality. Our approach achieves state-of-the-art performance on multiple IQA datasets and exhibits remarkable generalization capabilities. Leveraging these strengths, we propose several applications, such as evaluating image generation models and training image enhancement models, demonstrating our model's real-world applicability. We will make the code available for access.
Attentive Illumination Decomposition Model for Multi-Illuminant White Balancing
Feb 28, 2024



White balance (WB) algorithms in many commercial cameras assume single and uniform illumination, leading to undesirable results when multiple lighting sources with different chromaticities exist in the scene. Prior research on multi-illuminant WB typically predicts illumination at the pixel level without fully grasping the scene's actual lighting conditions, including the number and color of light sources. This often results in unnatural outcomes lacking in overall consistency. To handle this problem, we present a deep white balancing model that leverages the slot attention, where each slot is in charge of representing individual illuminants. This design enables the model to generate chromaticities and weight maps for individual illuminants, which are then fused to compose the final illumination map. Furthermore, we propose the centroid-matching loss, which regulates the activation of each slot based on the color range, thereby enhancing the model to separate illumination more effectively. Our method achieves the state-of-the-art performance on both single- and multi-illuminant WB benchmarks, and also offers additional information such as the number of illuminants in the scene and their chromaticity. This capability allows for illumination editing, an application not feasible with prior methods.