 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferent Set Domain Adaptation for Brain-Computer Interfaces: A Label Alignment Approach
Dec 29, 2019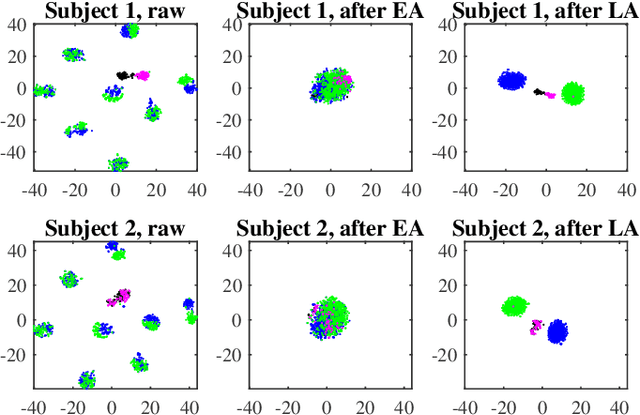
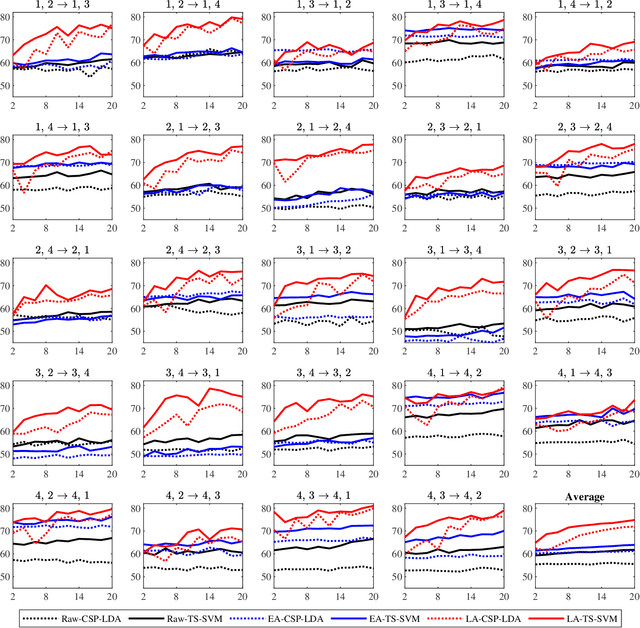
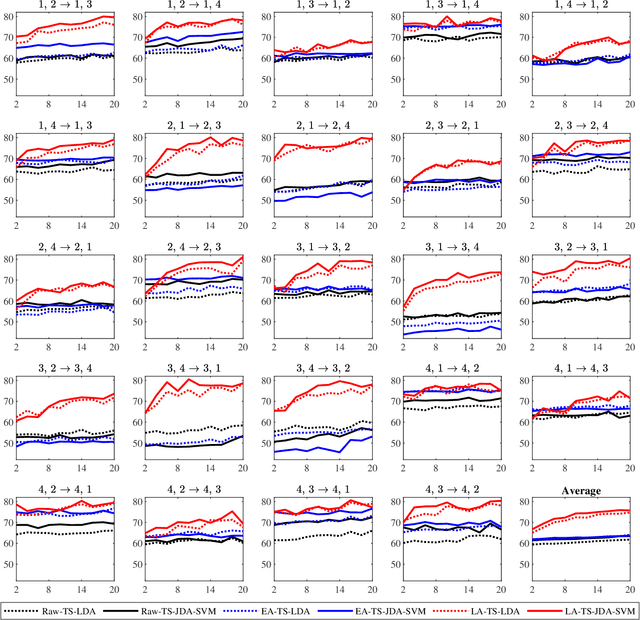
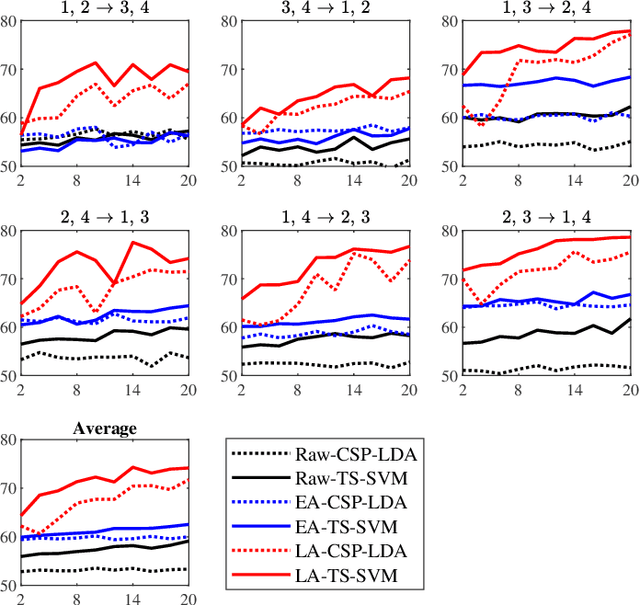
A brain-computer interface (BCI) system usually needs a long calibration session for each new subject/task to adjust its parameters, which impedes its transition from the laboratory to real-world applications. Domain adaptation, which leverages labeled data from auxiliary subjects/tasks (source domains), has demonstrated its effectiveness in reducing such calibration effort. Currently, most domain adaptation approaches require the source domains to have the same feature space and label space as the target domain, which limits their applications, as the auxiliary data may have different feature spaces and/or different label spaces. This paper considers different set domain adaptation for BCIs, i.e., the source and target domains have different label spaces. We introduce a practical setting of different label sets for BCIs, and propose a novel label alignment (LA) approach to align the source label space with the target label space. It has three desirable properties: 1) LA only needs as few as one labeled sample from each class of the target subject; 2) LA can be used as a preprocessing step before different feature extraction and classification algorithms; and, 3) LA can be integrated with other domain adaptation approaches to achieve even better performance. Experiments on two motor imagery datasets demonstrated the effectiveness of LA.
Universal Adversarial Perturbations for CNN Classifiers in EEG-Based BCIs
Dec 03, 2019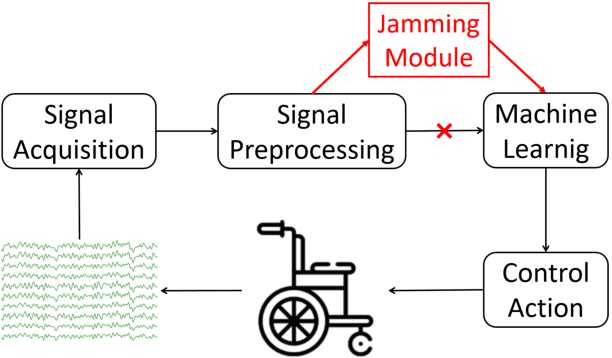
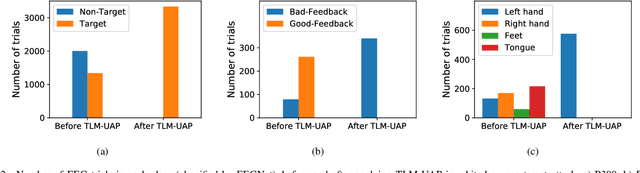
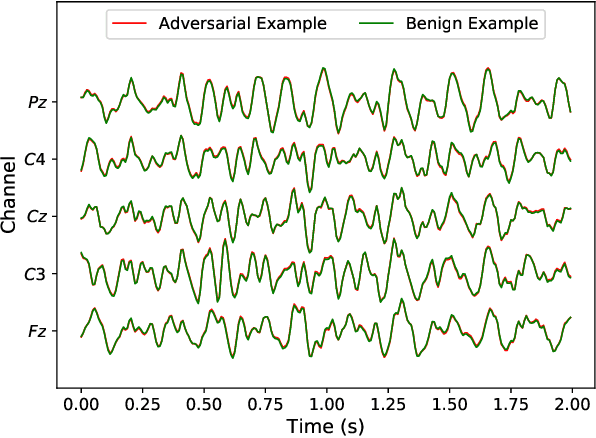
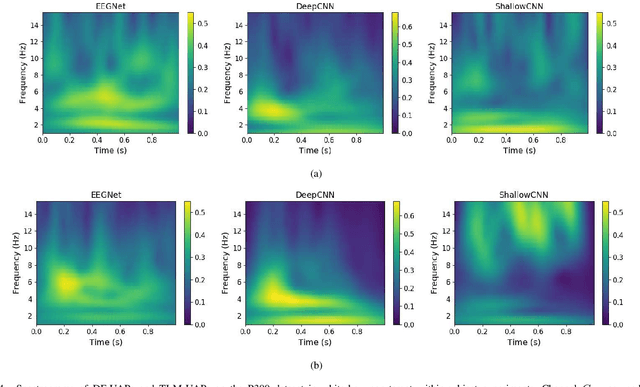
Multiple convolutional neural network (CNN) classifiers have been proposed for electroencephalogram (EEG) based brain-computer interfaces (BCIs). However, CNN models have been found vulnerable to universal adversarial perturbations (UAPs), which are small and example-independent, yet powerful enough to degrade the performance of a CNN model, when added to a benign example. This paper proposes a novel total loss minimization (TLM) approach to generate UAPs for EEG-based BCIs. Experimental results demonstrate the effectiveness of TLM on three popular CNN classifiers for both target and non-target attacks. We also verify the transferability of UAPs in EEG-based BCI systems. To our knowledge, this is the first study on UAPs of CNN classifiers in EEG-based BCIs, and also the first study on UAPs for target attacks. UAPs are easy to construct, and can attack BCIs in real-time, exposing a critical security concern of BCIs.
In Vitro Fertilization (IVF) Cumulative Pregnancy Rate Prediction from Basic Patient Characteristics
Nov 10, 2019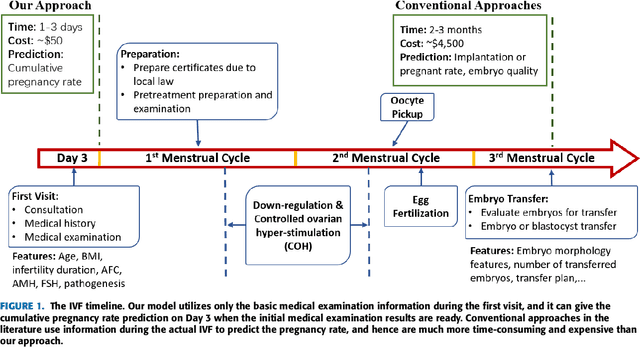
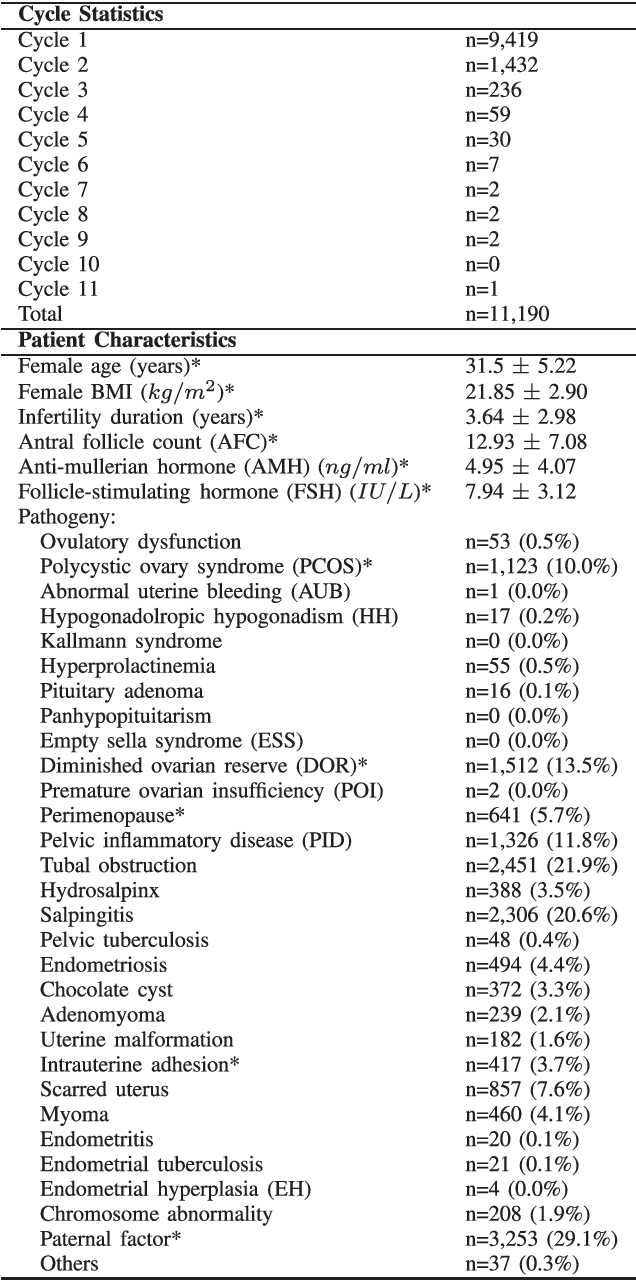
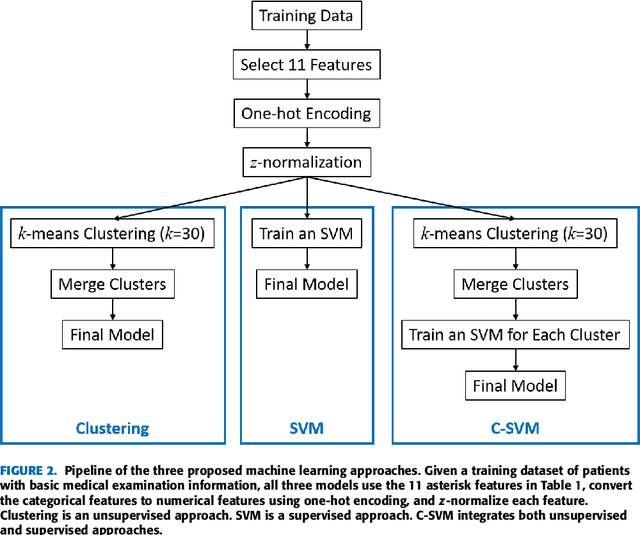

Tens of millions of women suffer from infertility worldwide each year. In vitro fertilization (IVF) is the best choice for many such patients. However, IVF is expensive, time-consuming, and both physically and emotionally demanding. The first question that a patient usually asks before the IVF is how likely she will conceive, given her basic medical examination information. This paper proposes three approaches to predict the cumulative pregnancy rate after multiple oocyte pickup cycles. Experiments on 11,190 patients showed that first clustering the patients into different groups and then building a support vector machine model for each group can achieve the best overall performance. Our model could be a quick and economic approach for reliably estimating the cumulative pregnancy rate for a patient, given only her basic medical examination information, well before starting the actual IVF procedure. The predictions can help the patient make optimal decisions on whether to use her own oocyte or donor oocyte, how many oocyte pickup cycles she may need, whether to use embryo frozen, etc. They will also reduce the patient's cost and time to pregnancy, and improve her quality of life.
Active Learning for Black-Box Adversarial Attacks in EEG-Based Brain-Computer Interfaces
Nov 07, 2019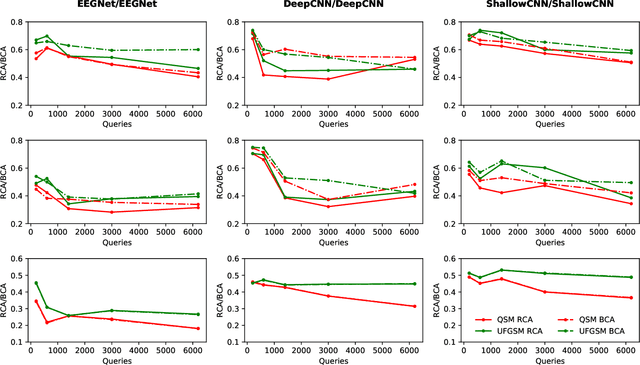
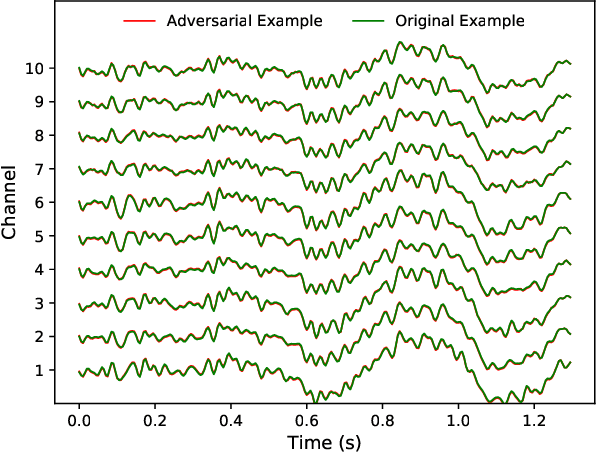
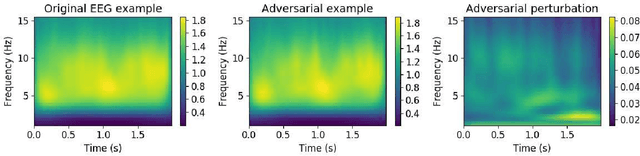
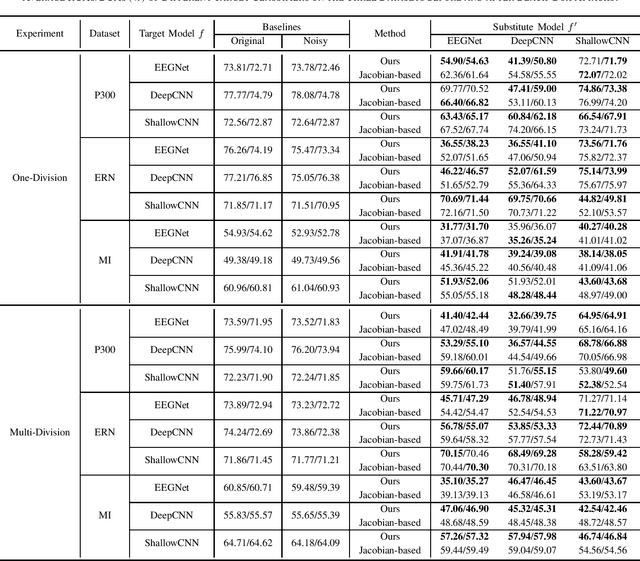
Deep learning has made significant breakthroughs in many fields, including electroencephalogram (EEG) based brain-computer interfaces (BCIs). However, deep learning models are vulnerable to adversarial attacks, in which deliberately designed small perturbations are added to the benign input samples to fool the deep learning model and degrade its performance. This paper considers transferability-based black-box attacks, where the attacker trains a substitute model to approximate the target model, and then generates adversarial examples from the substitute model to attack the target model. Learning a good substitute model is critical to the success of these attacks, but it requires a large number of queries to the target model. We propose a novel framework which uses query synthesis based active learning to improve the query efficiency in training the substitute model. Experiments on three convolutional neural network (CNN) classifiers and three EEG datasets demonstrated that our method can improve the attack success rate with the same number of queries, or, in other words, our method requires fewer queries to achieve a desired attack performance. To our knowledge, this is the first work that integrates active learning and adversarial attacks for EEG-based BCIs.
White-Box Target Attack for EEG-Based BCI Regression Problems
Nov 07, 2019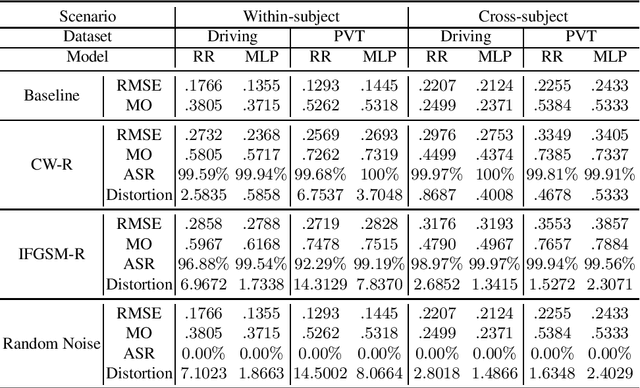
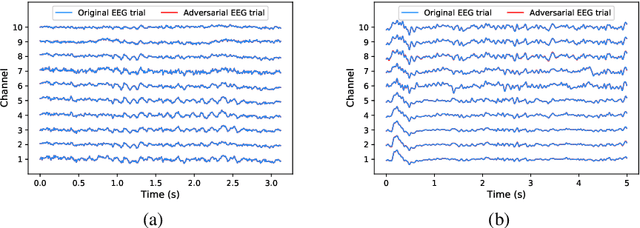
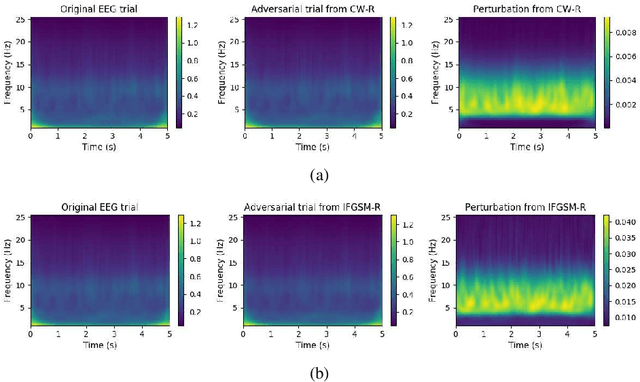
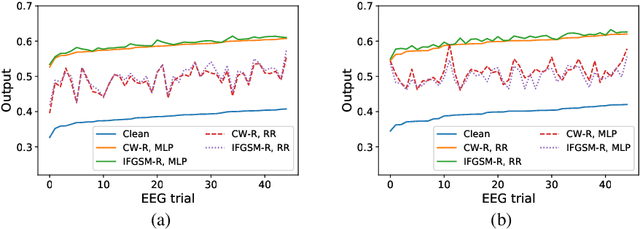
Machine learning has achieved great success in many applications, including electroencephalogram (EEG) based brain-computer interfaces (BCIs). Unfortunately, many machine learning models are vulnerable to adversarial examples, which are crafted by adding deliberately designed perturbations to the original inputs. Many adversarial attack approaches for classification problems have been proposed, but few have considered target adversarial attacks for regression problems. This paper proposes two such approaches. More specifically, we consider white-box target attacks for regression problems, where we know all information about the regression model to be attacked, and want to design small perturbations to change the regression output by a pre-determined amount. Experiments on two BCI regression problems verified that both approaches are effective. Moreover, adversarial examples generated from both approaches are also transferable, which means that we can use adversarial examples generated from one known regression model to attack an unknown regression model, i.e., to perform black-box attacks. To our knowledge, this is the first study on adversarial attacks for EEG-based BCI regression problems, which calls for more attention on the security of BCI systems.
Manifold Embedded Knowledge Transfer for Brain-Computer Interfaces
Oct 14, 2019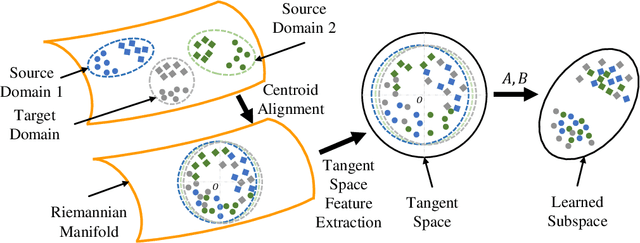
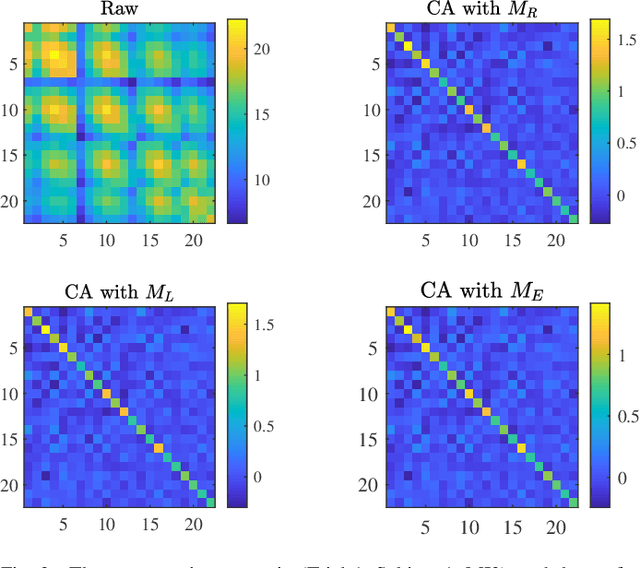
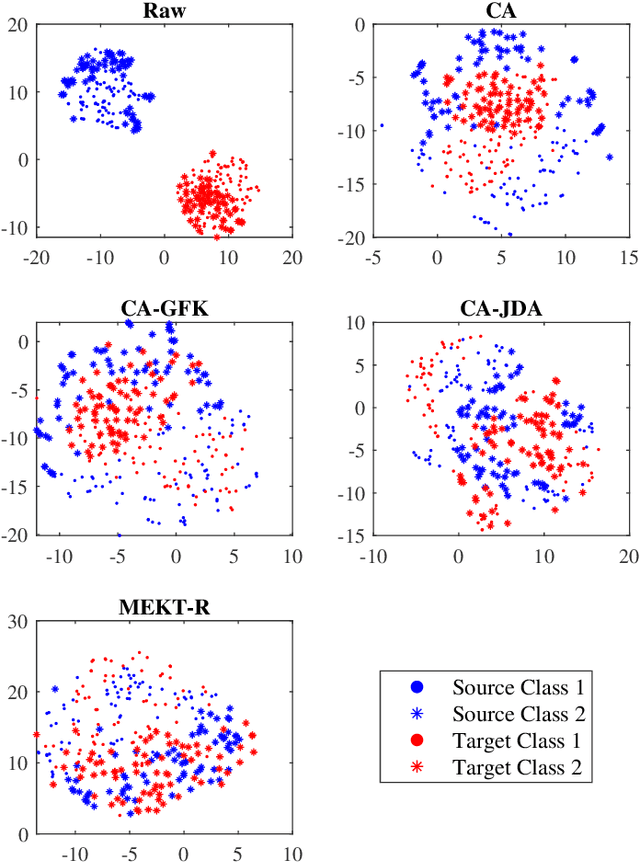
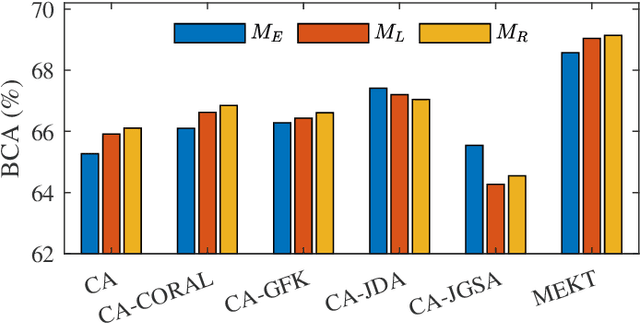
Transfer learning makes use of data or knowledge in one problem to help solve a different, yet related, problem. It is particularly useful in brain-computer interfaces (BCIs), for coping with variations among different subjects and/or tasks. This paper considers offline unsupervised cross-subject electroencephalogram (EEG) classification, i.e., we have labeled EEG trials from one or more source subjects, but only unlabeled EEG trials from the target subject. We propose a novel manifold embedded knowledge transfer (MEKT) approach, which first aligns the covariance matrices of the EEG trials in the Riemannian manifold, extracts features in the tangent space, and then performs domain adaptation by minimizing the joint probability distribution shift between the source and the target domains, while preserving their geometric structures. MEKT can cope with one or multiple source domains, and can be computed efficiently. We also propose a domain transferability estimation (DTE) approach to identify the most beneficial source domains, in case there are a large number of source domains. Experiments on four EEG datasets from two different BCI paradigms demonstrated that MEKT outperformed several state-of-the-art transfer learning approaches, and DTE can reduce more than half of the computational cost when the number of source subjects is large, with little sacrifice of classification accuracy.
EEG-Based Driver Drowsiness Estimation Using Feature Weighted Episodic Training
Sep 25, 2019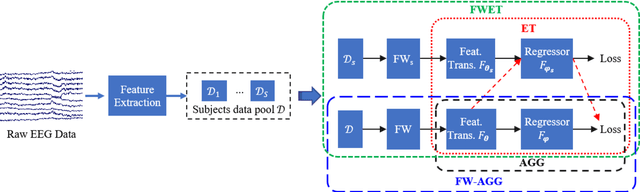
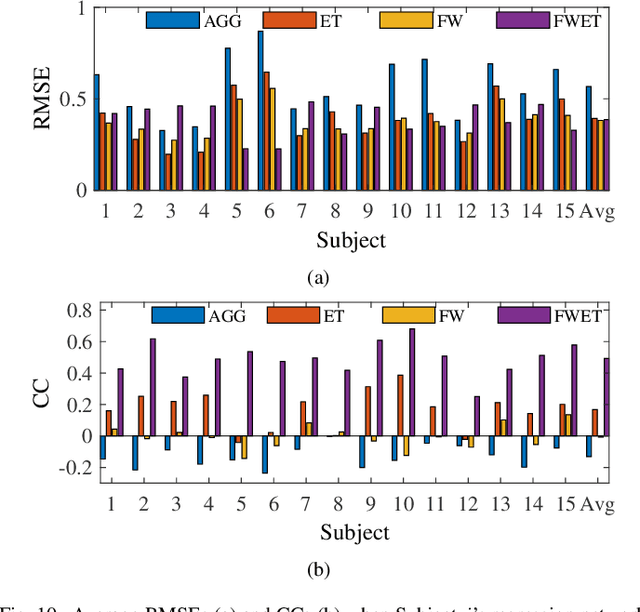
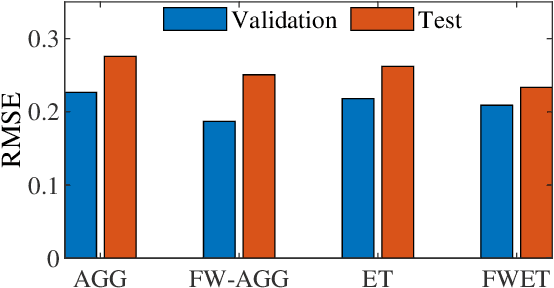
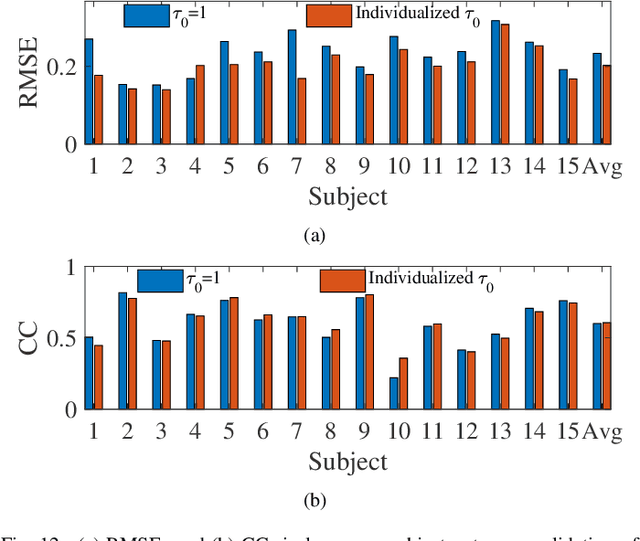
Drowsy driving is pervasive, and also a major cause of traffic accidents. Estimating a driver's drowsiness level by monitoring the electroencephalogram (EEG) signal and taking preventative actions accordingly may improve driving safety. However, individual differences among different drivers make this task very challenging. A calibration session is usually required to collect some subject-specific data and tune the model parameters before applying it to a new subject, which is very inconvenient and not user-friendly. Many approaches have been proposed to reduce the calibration effort, but few can completely eliminate it. This paper proposes a novel approach, feature weighted episodic training (FWET), to completely eliminate the calibration requirement. It integrates two techniques: feature weighting to learn the importance of different features, and episodic training for domain generalization. Experiments on EEG-based driver drowsiness estimation demonstrated that both feature weighting and episodic training are effective, and their integration can further improve the generalization performance. FWET does not need any labelled or unlabelled calibration data from the new subject, and hence could be very useful in plug-and-play brain-computer interfaces.
Multi-Task Deep Learning with Dynamic Programming for Embryo Early Development Stage Classification from Time-Lapse Videos
Aug 22, 2019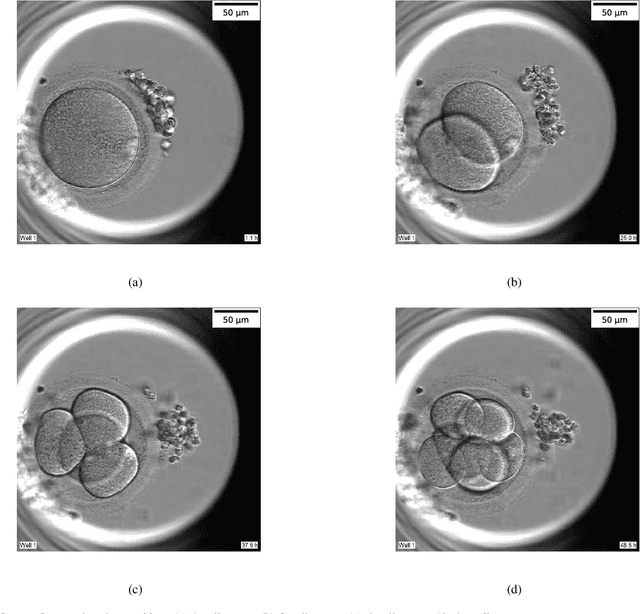
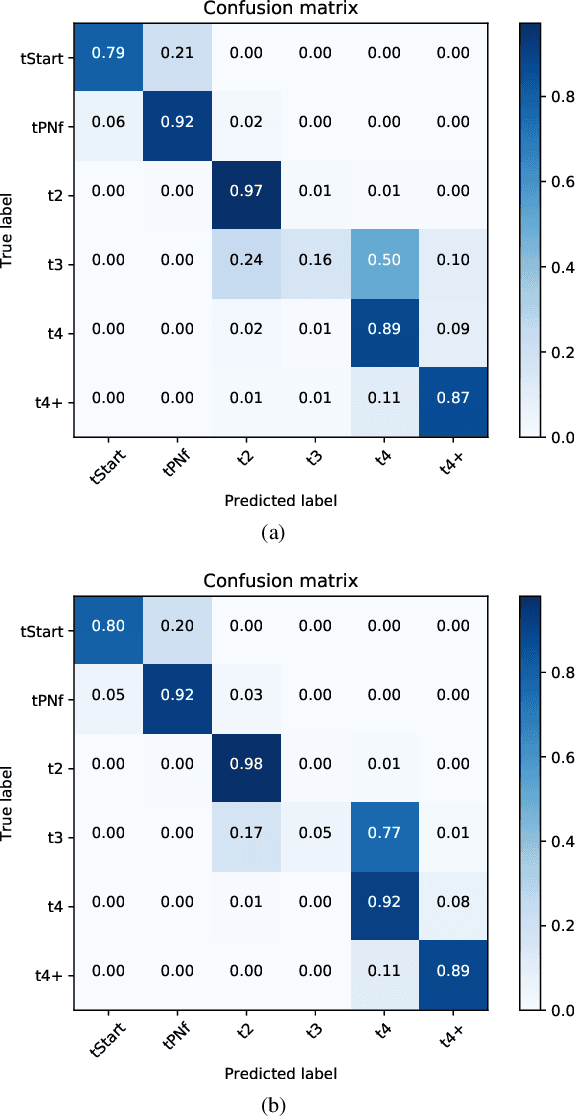
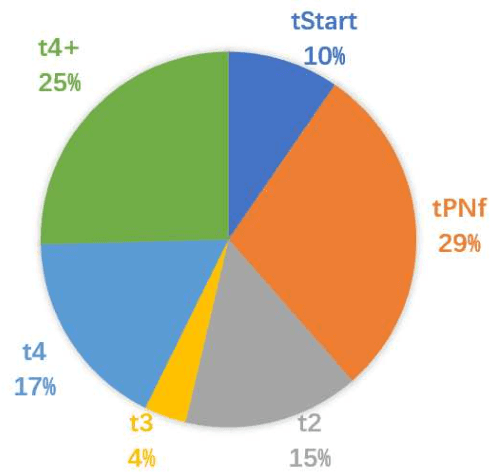
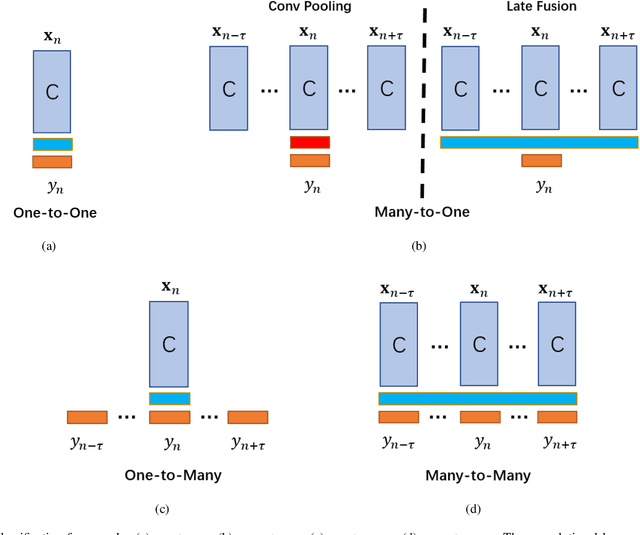
Time-lapse is a technology used to record the development of embryos during in-vitro fertilization (IVF). Accurate classification of embryo early development stages can provide embryologists valuable information for assessing the embryo quality, and hence is critical to the success of IVF. This paper proposes a multi-task deep learning with dynamic programming (MTDL-DP) approach for this purpose. It first uses MTDL to pre-classify each frame in the time-lapse video to an embryo development stage, and then DP to optimize the stage sequence so that the stage number is monotonically non-decreasing, which usually holds in practice. Different MTDL frameworks, e.g., one-to-many, many-to-one, and many-to-many, are investigated. It is shown that the one-to-many MTDL framework achieved the best compromise between performance and computational cost. To our knowledge, this is the first study that applies MTDL to embryo early development stage classification from time-lapse videos.
Multi-View Broad Learning System for Primate Oculomotor Decision Decoding
Aug 16, 2019
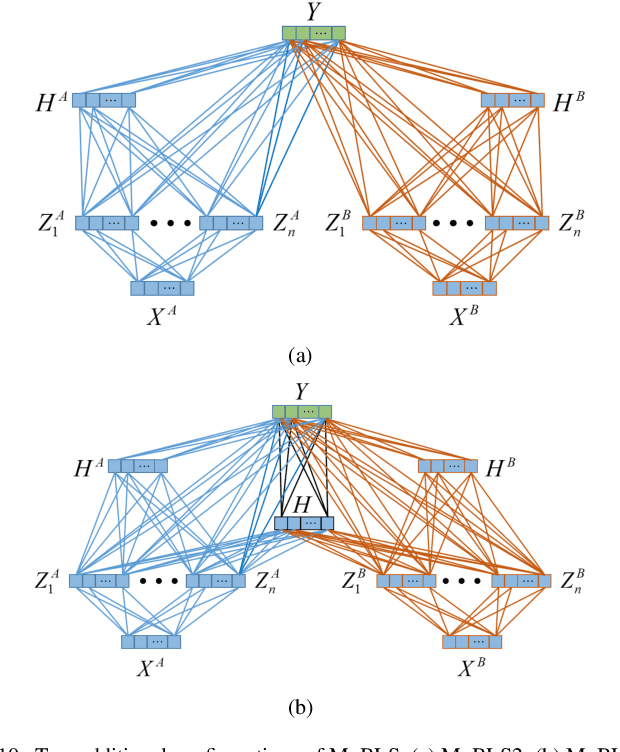
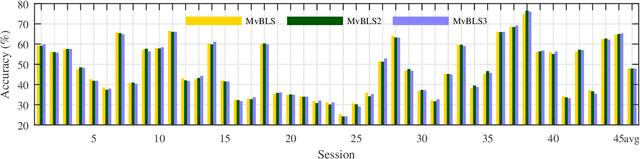
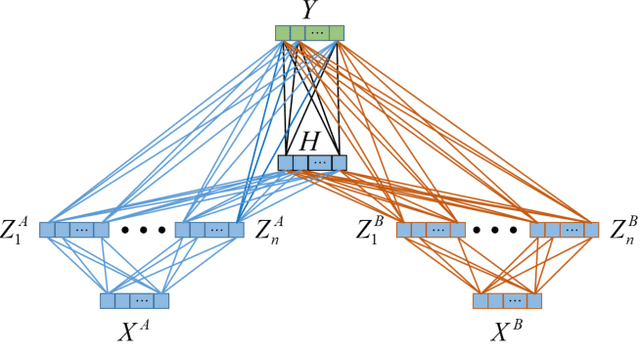
Multi-view learning improves the learning performance by utilizing multi-view data: data collected from multiple sources, or feature sets extracted from the same data source. This approach is suitable for primate brain state decoding using cortical neural signals. This is because the complementary components of simultaneously recorded neural signals, local field potentials (LFPs) and action potentials (spikes), can be treated as two views. In this paper, we extended broad learning system (BLS), a recently proposed wide neural network architecture, from single-view learning to multi-view learning, and validated its performance in monkey oculomotor decision decoding from medial frontal LFPs and spikes. We demonstrated that medial frontal LFPs and spikes in non-human primate do contain complementary information about the oculomotor decision, and that the proposed multi-view BLS is a more effective approach to classify the oculomotor decision, than several classical and state-of-the-art single-view and multi-view learning approaches.
Optimize TSK Fuzzy Systems for Big Data Classification Problems: Bag of Tricks
Aug 01, 2019
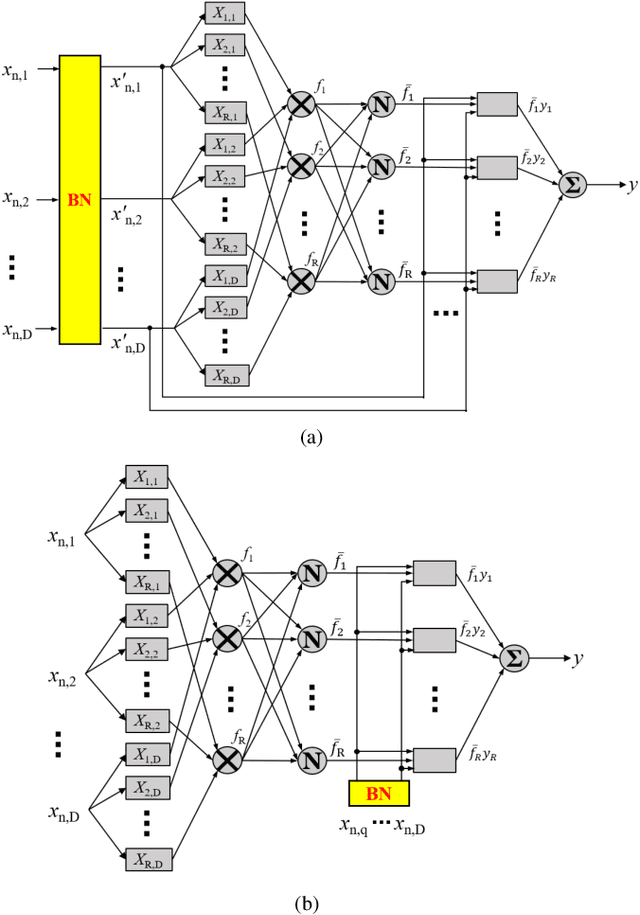
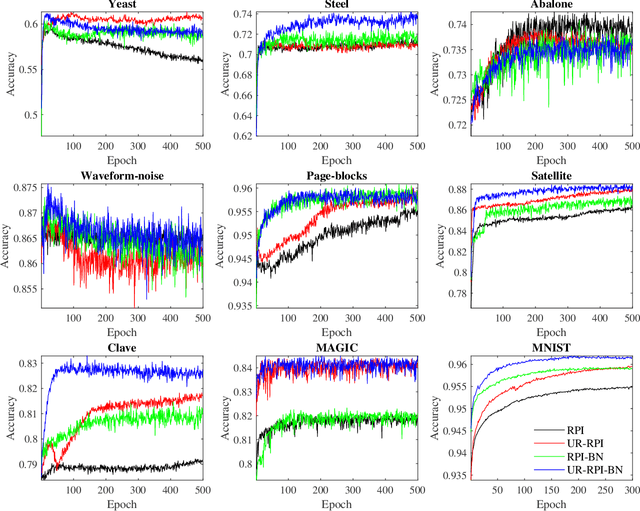
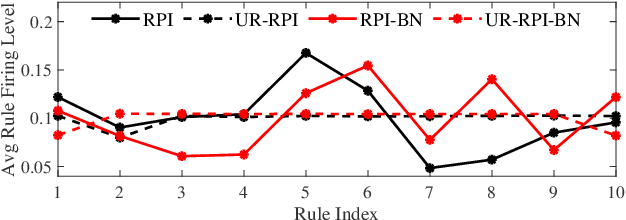
Takagi-Sugeno-Kang (TSK) fuzzy systems are flexible and interpretable machine learning models; however, they may not be easily applicable to big data problems, especially when the size and the dimensionality of the data are both large. This paper proposes a mini-batch gradient descent (MBGD) based algorithm to efficiently and effectively train TSK fuzzy systems for big data classification problems. It integrates three novel techniques: 1) uniform regularization (UR), which is a regularization term added to the loss function to make sure the rules have similar average firing levels, and hence better generalization performance; 2) random percentile initialization (RPI), which initializes the membership function parameters efficiently and reliably; and, 3) batch normalization (BN), which extends BN from deep neural networks to TSK fuzzy systems to speedup the convergence and improve generalization. Experiments on nine datasets from various application domains, with varying size and feature dimensionality, demonstrated that each of UR, RPI and BN has its own unique advantages, and integrating all three together can achieve the best classification performance.