 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComputing the Dirichlet-Multinomial Log-Likelihood Function
Jul 17, 2020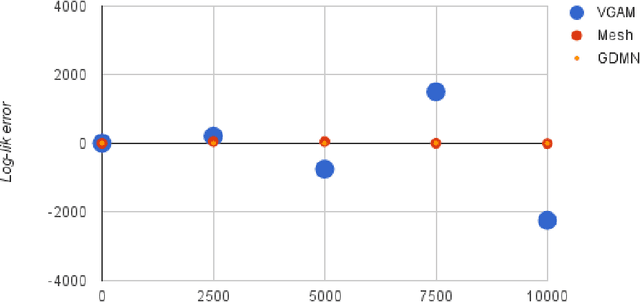
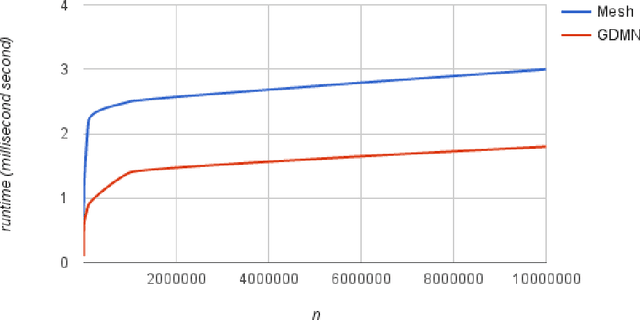
Dirichlet-multinomial (DMN) distribution is commonly used to model over-dispersion in count data. Precise and fast numerical computation of the DMN log-likelihood function is important for performing statistical inference using this distribution, and remains a challenge. To address this, we use mathematical properties of the gamma function to derive a closed form expression for the DMN log-likelihood function. Compared to existing methods, calculation of the closed form has a lower computational complexity, hence is much faster without comprimising computational accuracy.
Solving Constrained CASH Problems with ADMM
Jul 11, 2020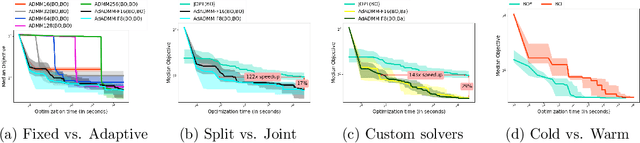
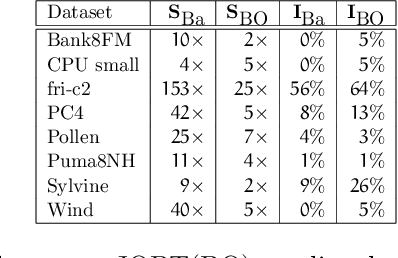
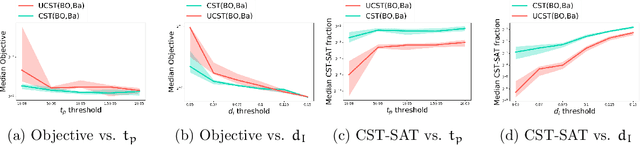
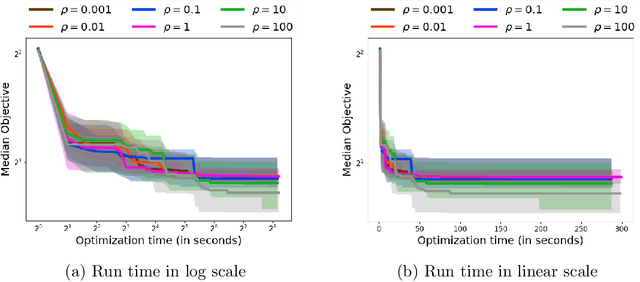
The CASH problem has been widely studied in the context of automated configurations of machine learning (ML) pipelines and various solvers and toolkits are available. However, CASH solvers do not directly handle black-box constraints such as fairness, robustness or other domain-specific custom constraints. We present our recent approach [Liu, et al., 2020] that leverages the ADMM optimization framework to decompose CASH into multiple small problems and demonstrate how ADMM facilitates incorporation of black-box constraints.
Online learning with Corrupted context: Corrupted Contextual Bandits
Jun 26, 2020
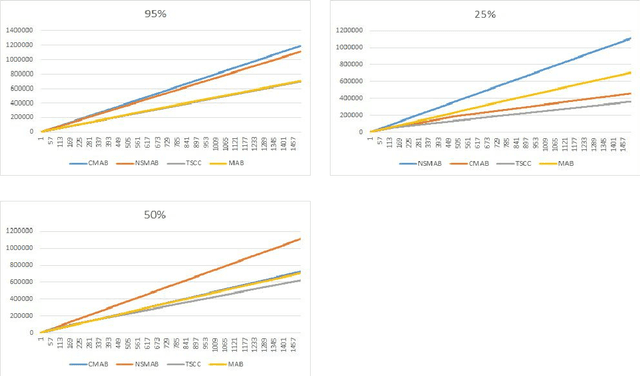
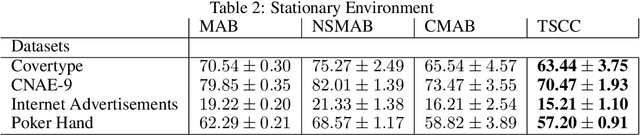
We consider a novel variant of the contextual bandit problem (i.e., the multi-armed bandit with side-information, or context, available to a decision-maker) where the context used at each decision may be corrupted ("useless context"). This new problem is motivated by certain on-line settings including clinical trial and ad recommendation applications. In order to address the corrupted-context setting,we propose to combine the standard contextual bandit approach with a classical multi-armed bandit mechanism. Unlike standard contextual bandit methods, we are able to learn from all iteration, even those with corrupted context, by improving the computing of the expectation for each arm. Promising empirical results are obtained on several real-life datasets.
Online Learning in Iterated Prisoner's Dilemma to Mimic Human Behavior
Jun 09, 2020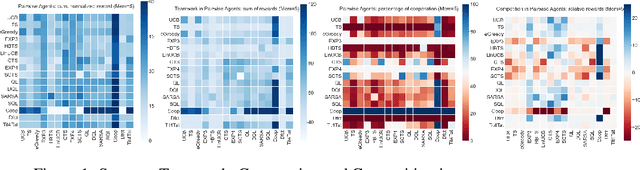
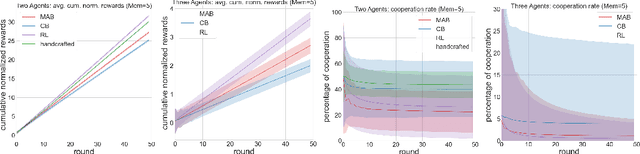
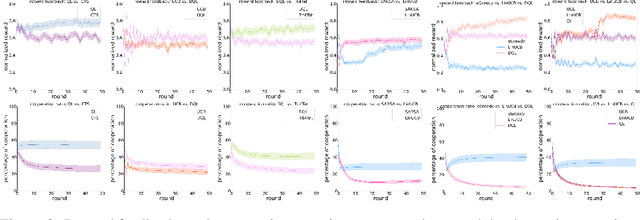
Prisoner's Dilemma mainly treat the choice to cooperate or defect as an atomic action. We propose to study online learning algorithm behavior in the Iterated Prisoner's Dilemma (IPD) game, where we explored the full spectrum of reinforcement learning agents: multi-armed bandits, contextual bandits and reinforcement learning. We have evaluate them based on a tournament of iterated prisoner's dilemma where multiple agents can compete in a sequential fashion. This allows us to analyze the dynamics of policies learned by multiple self-interested independent reward-driven agents, and also allows us study the capacity of these algorithms to fit the human behaviors. Results suggest that considering the current situation to make decision is the worst in this kind of social dilemma game. Multiples discoveries on online learning behaviors and clinical validations are stated.
Unified Models of Human Behavioral Agents in Bandits, Contextual Bandits and RL
May 12, 2020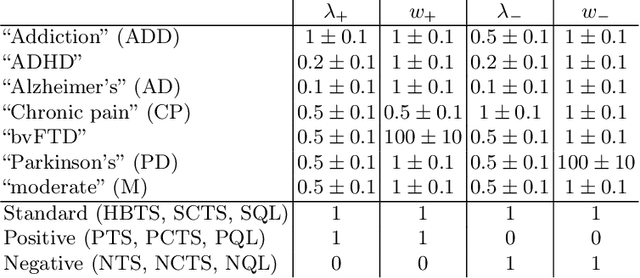
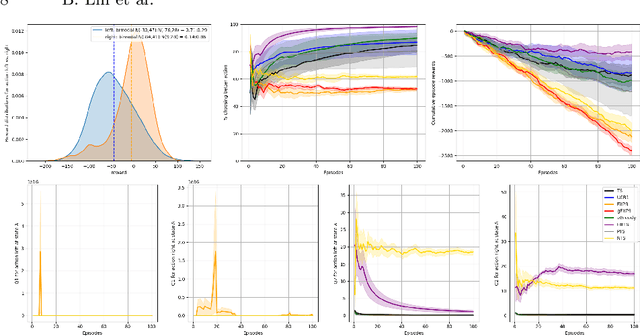
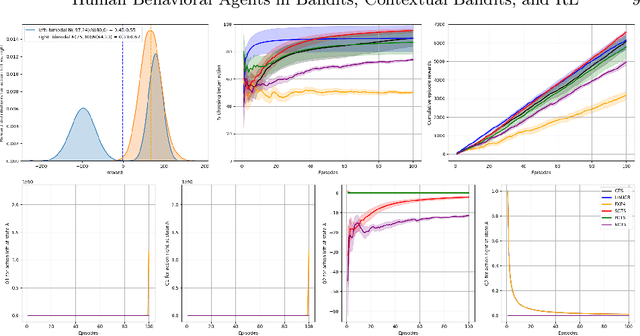
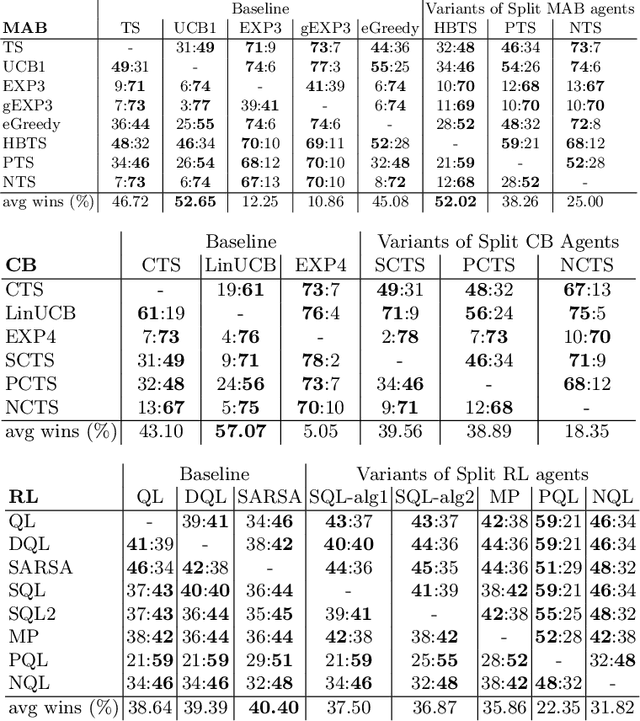
Artificial behavioral agents are often evaluated based on their consistent behaviors and performance to take sequential actions in an environment to maximize some notion of cumulative reward. However, human decision making in real life usually involves different strategies and behavioral trajectories that lead to the same empirical outcome. Motivated by clinical literature of a wide range of neurological and psychiatric disorders, we propose here a more general and flexible parametric framework for sequential decision making that involves a two-stream reward processing mechanism. We demonstrated that this framework is flexible and unified enough to incorporate a family of problems spanning multi-armed bandits (MAB), contextual bandits (CB) and reinforcement learning (RL), which decompose the sequential decision making process in different levels. Inspired by the known reward processing abnormalities of many mental disorders, our clinically-inspired agents demonstrated interesting behavioral trajectories and comparable performance on simulated tasks with particular reward distributions, a real-world dataset capturing human decision-making in gambling tasks, and the PacMan game across different reward stationarities in a lifelong learning setting.
Hyper-parameter Tuning for the Contextual Bandit
May 04, 2020
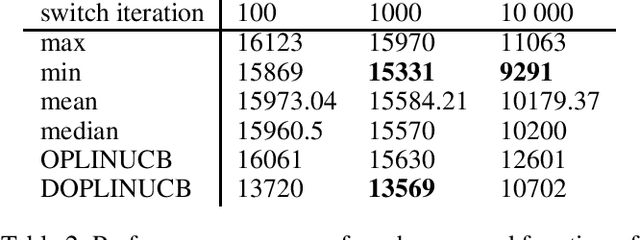
We study here the problem of learning the exploration exploitation trade-off in the contextual bandit problem with linear reward function setting. In the traditional algorithms that solve the contextual bandit problem, the exploration is a parameter that is tuned by the user. However, our proposed algorithm learn to choose the right exploration parameters in an online manner based on the observed context, and the immediate reward received for the chosen action. We have presented here two algorithms that uses a bandit to find the optimal exploration of the contextual bandit algorithm, which we hope is the first step toward the automation of the multi-armed bandit algorithm.
How can AI Automate End-to-End Data Science?
Oct 22, 2019
Data science is labor-intensive and human experts are scarce but heavily involved in every aspect of it. This makes data science time consuming and restricted to experts with the resulting quality heavily dependent on their experience and skills. To make data science more accessible and scalable, we need its democratization. Automated Data Science (AutoDS) is aimed towards that goal and is emerging as an important research and business topic. We introduce and define the AutoDS challenge, followed by a proposal of a general AutoDS framework that covers existing approaches but also provides guidance for the development of new methods. We categorize and review the existing literature from multiple aspects of the problem setup and employed techniques. Then we provide several views on how AI could succeed in automating end-to-end AutoDS. We hope this survey can serve as insightful guideline for the AutoDS field and provide inspiration for future research.
Reinforcement Learning Models of Human Behavior: Reward Processing in Mental Disorders
Jun 28, 2019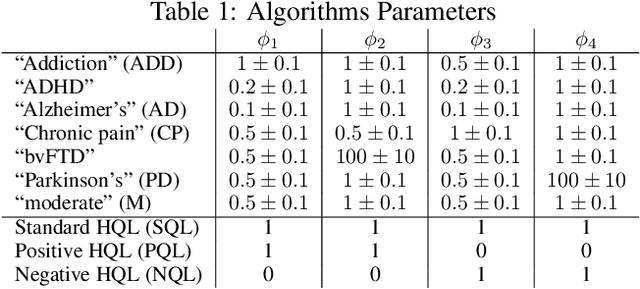
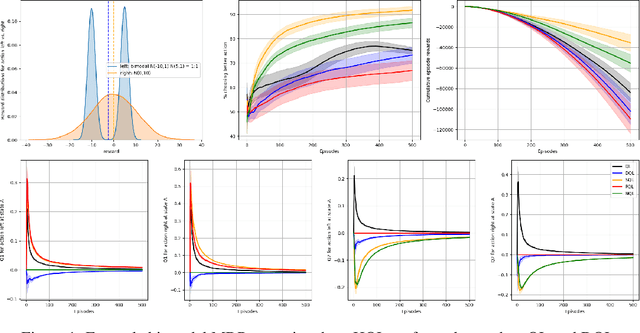


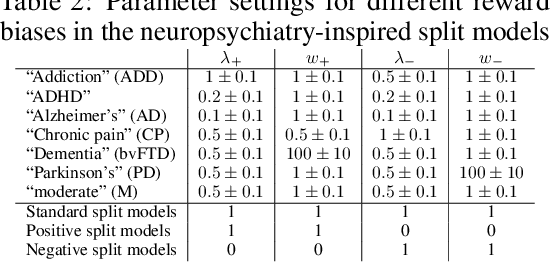
Drawing an inspiration from behavioral studies of human decision making, we propose here a general parametric framework for a reinforcement learning problem, which extends the standard Q-learning approach to incorporate a two-stream framework of reward processing with biases biologically associated with several neurological and psychiatric conditions, including Parkinson's and Alzheimer's diseases, attention-deficit/hyperactivity disorder (ADHD), addiction, and chronic pain. For AI community, the development of agents that react differently to different types of rewards can enable us to understand a wide spectrum of multi-agent interactions in complex real-world socioeconomic systems. Empirically, the proposed model outperforms Q-Learning and Double Q-Learning in artificial scenarios with certain reward distributions and real-world human decision making gambling tasks. Moreover, from the behavioral modeling perspective, our parametric framework can be viewed as a first step towards a unifying computational model capturing reward processing abnormalities across multiple mental conditions and user preferences in long-term recommendation systems.
Split Q Learning: Reinforcement Learning with Two-Stream Rewards
Jun 21, 2019
Drawing an inspiration from behavioral studies of human decision making, we propose here a general parametric framework for a reinforcement learning problem, which extends the standard Q-learning approach to incorporate a two-stream framework of reward processing with biases biologically associated with several neurological and psychiatric conditions, including Parkinson's and Alzheimer's diseases, attention-deficit/hyperactivity disorder (ADHD), addiction, and chronic pain. For AI community, the development of agents that react differently to different types of rewards can enable us to understand a wide spectrum of multi-agent interactions in complex real-world socioeconomic systems. Moreover, from the behavioral modeling perspective, our parametric framework can be viewed as a first step towards a unifying computational model capturing reward processing abnormalities across multiple mental conditions and user preferences in long-term recommendation systems.
Optimal Exploitation of Clustering and History Information in Multi-Armed Bandit
May 31, 2019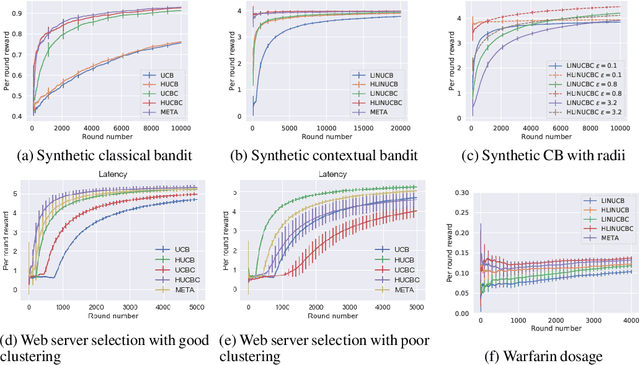
We consider the stochastic multi-armed bandit problem and the contextual bandit problem with historical observations and pre-clustered arms. The historical observations can contain any number of instances for each arm, and the pre-clustering information is a fixed clustering of arms provided as part of the input. We develop a variety of algorithms which incorporate this offline information effectively during the online exploration phase and derive their regret bounds. In particular, we develop the META algorithm which effectively hedges between two other algorithms: one which uses both historical observations and clustering, and another which uses only the historical observations. The former outperforms the latter when the clustering quality is good, and vice-versa. Extensive experiments on synthetic and real world datasets on Warafin drug dosage and web server selection for latency minimization validate our theoretical insights and demonstrate that META is a robust strategy for optimally exploiting the pre-clustering information.