 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbing Cultural Signals in Large Language Models through Author Profiling
Mar 17, 2026Large language models (LLMs) are increasingly deployed in applications with societal impact, raising concerns about the cultural biases they encode. We probe these representations by evaluating whether LLMs can perform author profiling from song lyrics in a zero-shot setting, inferring singers' gender and ethnicity without task-specific fine-tuning. Across several open-source models evaluated on more than 10,000 lyrics, we find that LLMs achieve non-trivial profiling performance but demonstrate systematic cultural alignment: most models default toward North American ethnicity, while DeepSeek-1.5B aligns more strongly with Asian ethnicity. This finding emerges from both the models' prediction distributions and an analysis of their generated rationales. To quantify these disparities, we introduce two fairness metrics, Modality Accuracy Divergence (MAD) and Recall Divergence (RD), and show that Ministral-8B displays the strongest ethnicity bias among the evaluated models, whereas Gemma-12B shows the most balanced behavior. Our code is available on GitHub (https://github.com/ValentinLafargue/CulturalProbingLLM).
Exposing the Illusion of Fairness: Auditing Vulnerabilities to Distributional Manipulation Attacks
Jul 28, 2025Proving the compliance of AI algorithms has become an important challenge with the growing deployment of such algorithms for real-life applications. Inspecting possible biased behaviors is mandatory to satisfy the constraints of the regulations of the EU Artificial Intelligence's Act. Regulation-driven audits increasingly rely on global fairness metrics, with Disparate Impact being the most widely used. Yet such global measures depend highly on the distribution of the sample on which the measures are computed. We investigate first how to manipulate data samples to artificially satisfy fairness criteria, creating minimally perturbed datasets that remain statistically indistinguishable from the original distribution while satisfying prescribed fairness constraints. Then we study how to detect such manipulation. Our analysis (i) introduces mathematically sound methods for modifying empirical distributions under fairness constraints using entropic or optimal transport projections, (ii) examines how an auditee could potentially circumvent fairness inspections, and (iii) offers recommendations to help auditors detect such data manipulations. These results are validated through experiments on classical tabular datasets in bias detection.
Hyper-parameter Tuning for the Contextual Bandit
May 04, 2020
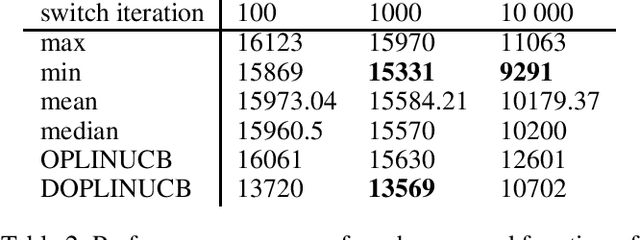
We study here the problem of learning the exploration exploitation trade-off in the contextual bandit problem with linear reward function setting. In the traditional algorithms that solve the contextual bandit problem, the exploration is a parameter that is tuned by the user. However, our proposed algorithm learn to choose the right exploration parameters in an online manner based on the observed context, and the immediate reward received for the chosen action. We have presented here two algorithms that uses a bandit to find the optimal exploration of the contextual bandit algorithm, which we hope is the first step toward the automation of the multi-armed bandit algorithm.