 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistributed Gradient Descent for Functional Learning
May 12, 2023In recent years, different types of distributed learning schemes have received increasing attention for their strong advantages in handling large-scale data information. In the information era, to face the big data challenges which stem from functional data analysis very recently, we propose a novel distributed gradient descent functional learning (DGDFL) algorithm to tackle functional data across numerous local machines (processors) in the framework of reproducing kernel Hilbert space. Based on integral operator approaches, we provide the first theoretical understanding of the DGDFL algorithm in many different aspects in the literature. On the way of understanding DGDFL, firstly, a data-based gradient descent functional learning (GDFL) algorithm associated with a single-machine model is proposed and comprehensively studied. Under mild conditions, confidence-based optimal learning rates of DGDFL are obtained without the saturation boundary on the regularity index suffered in previous works in functional regression. We further provide a semi-supervised DGDFL approach to weaken the restriction on the maximal number of local machines to ensure optimal rates. To our best knowledge, the DGDFL provides the first distributed iterative training approach to functional learning and enriches the stage of functional data analysis.
Approximation of Nonlinear Functionals Using Deep ReLU Networks
Apr 10, 2023In recent years, functional neural networks have been proposed and studied in order to approximate nonlinear continuous functionals defined on $L^p([-1, 1]^s)$ for integers $s\ge1$ and $1\le p<\infty$. However, their theoretical properties are largely unknown beyond universality of approximation or the existing analysis does not apply to the rectified linear unit (ReLU) activation function. To fill in this void, we investigate here the approximation power of functional deep neural networks associated with the ReLU activation function by constructing a continuous piecewise linear interpolation under a simple triangulation. In addition, we establish rates of approximation of the proposed functional deep ReLU networks under mild regularity conditions. Finally, our study may also shed some light on the understanding of functional data learning algorithms.
Optimal rates of approximation by shallow ReLU$^k$ neural networks and applications to nonparametric regression
Apr 04, 2023We study the approximation capacity of some variation spaces corresponding to shallow ReLU$^k$ neural networks. It is shown that sufficiently smooth functions are contained in these spaces with finite variation norms. For functions with less smoothness, the approximation rates in terms of the variation norm are established. Using these results, we are able to prove the optimal approximation rates in terms of the number of neurons for shallow ReLU$^k$ neural networks. It is also shown how these results can be used to derive approximation bounds for deep neural networks and convolutional neural networks (CNNs). As applications, we study convergence rates for nonparametric regression using three ReLU neural network models: shallow neural network, over-parameterized neural network, and CNN. In particular, we show that shallow neural networks can achieve the minimax optimal rates for learning H\"older functions, which complements recent results for deep neural networks. It is also proven that over-parameterized (deep or shallow) neural networks can achieve nearly optimal rates for nonparametric regression.
Sketching with Spherical Designs for Noisy Data Fitting on Spheres
Mar 08, 2023This paper proposes a sketching strategy based on spherical designs, which is applied to the classical spherical basis function approach for massive spherical data fitting. We conduct theoretical analysis and numerical verifications to demonstrate the feasibility of the proposed { sketching} strategy. From the theoretical side, we prove that sketching based on spherical designs can reduce the computational burden of the spherical basis function approach without sacrificing its approximation capability. In particular, we provide upper and lower bounds for the proposed { sketching} strategy to fit noisy data on spheres. From the experimental side, we numerically illustrate the feasibility of the sketching strategy by showing its comparable fitting performance with the spherical basis function approach. These interesting findings show that the proposed sketching strategy is capable of fitting massive and noisy data on spheres.
Generalization Analysis for Contrastive Representation Learning
Feb 28, 2023Recently, contrastive learning has found impressive success in advancing the state of the art in solving various machine learning tasks. However, the existing generalization analysis is very limited or even not meaningful. In particular, the existing generalization error bounds depend linearly on the number $k$ of negative examples while it was widely shown in practice that choosing a large $k$ is necessary to guarantee good generalization of contrastive learning in downstream tasks. In this paper, we establish novel generalization bounds for contrastive learning which do not depend on $k$, up to logarithmic terms. Our analysis uses structural results on empirical covering numbers and Rademacher complexities to exploit the Lipschitz continuity of loss functions. For self-bounding Lipschitz loss functions, we further improve our results by developing optimistic bounds which imply fast rates in a low noise condition. We apply our results to learning with both linear representation and nonlinear representation by deep neural networks, for both of which we derive Rademacher complexity bounds to get improved generalization bounds.
A new activation for neural networks and its approximation
Oct 19, 2022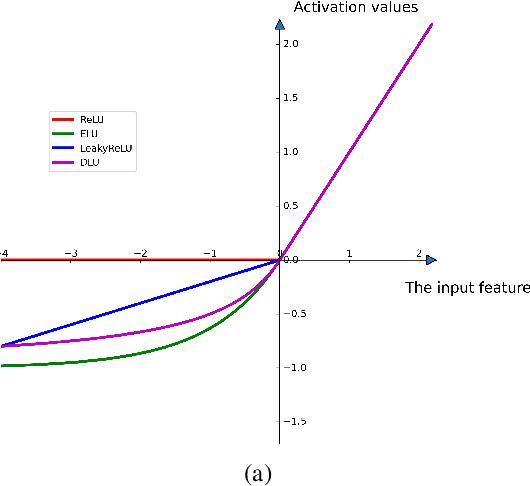
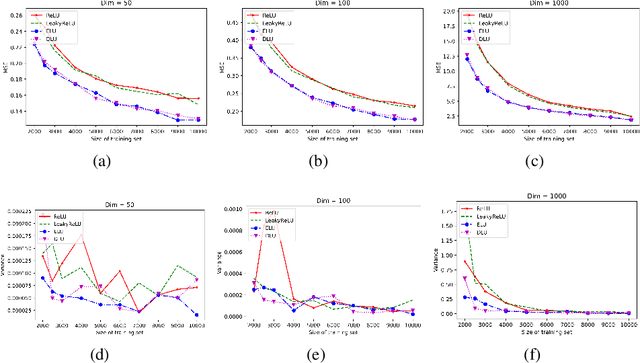
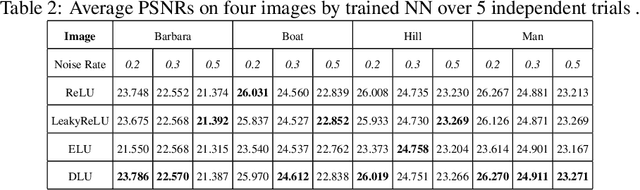
Deep learning with deep neural networks (DNNs) has attracted tremendous attention from various fields of science and technology recently. Activation functions for a DNN define the output of a neuron given an input or set of inputs. They are essential and inevitable in learning non-linear transformations and performing diverse computations among successive neuron layers. Thus, the design of activation functions is still an important topic in deep learning research. Meanwhile, theoretical studies on the approximation ability of DNNs with activation functions have been investigated within the last few years. In this paper, we propose a new activation function, named as "DLU", and investigate its approximation ability for functions with various smoothness and structures. Our theoretical results show that DLU networks can process competitive approximation performance with rational and ReLU networks, and have some advantages. Numerical experiments are conducted comparing DLU with the existing activations-ReLU, Leaky ReLU, and ELU, which illustrate the good practical performance of DLU.
Approximation analysis of CNNs from feature extraction view
Oct 14, 2022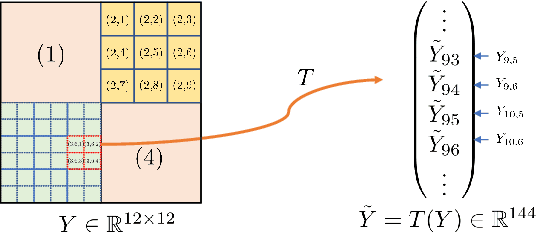
Deep learning based on deep neural networks has been very successful in many practical applications, but it lacks enough theoretical understanding due to the network architectures and structures. In this paper, we establish the analysis for linear feature extraction by deep multi-channel convolutional neural networks(CNNs), which demonstrates the power of deep learning over traditional linear transformations, like Fourier, Wavelets, and Redundant dictionary coding methods. Moreover, we give an exact construction presenting how linear features extraction can be conducted efficiently with multi-channel CNNs. It can be applied to lower the essential dimension for approximating a high-dimensional function. Rates of function approximation by such deep networks implemented with channels and followed by fully-connected layers are investigated as well. Harmonic analysis for factorizing linear features into multi-resolution convolutions plays an essential role in our work. Nevertheless, a dedicate vectorization of matrices is constructed, which bridges 1D CNN and 2D CNN and allows us have corresponding 2D analysis.
Stability and Generalization for Markov Chain Stochastic Gradient Methods
Sep 16, 2022Recently there is a large amount of work devoted to the study of Markov chain stochastic gradient methods (MC-SGMs) which mainly focus on their convergence analysis for solving minimization problems. In this paper, we provide a comprehensive generalization analysis of MC-SGMs for both minimization and minimax problems through the lens of algorithmic stability in the framework of statistical learning theory. For empirical risk minimization (ERM) problems, we establish the optimal excess population risk bounds for both smooth and non-smooth cases by introducing on-average argument stability. For minimax problems, we develop a quantitative connection between on-average argument stability and generalization error which extends the existing results for uniform stability \cite{lei2021stability}. We further develop the first nearly optimal convergence rates for convex-concave problems both in expectation and with high probability, which, combined with our stability results, show that the optimal generalization bounds can be attained for both smooth and non-smooth cases. To the best of our knowledge, this is the first generalization analysis of SGMs when the gradients are sampled from a Markov process.
Differentially Private Stochastic Gradient Descent with Low-Noise
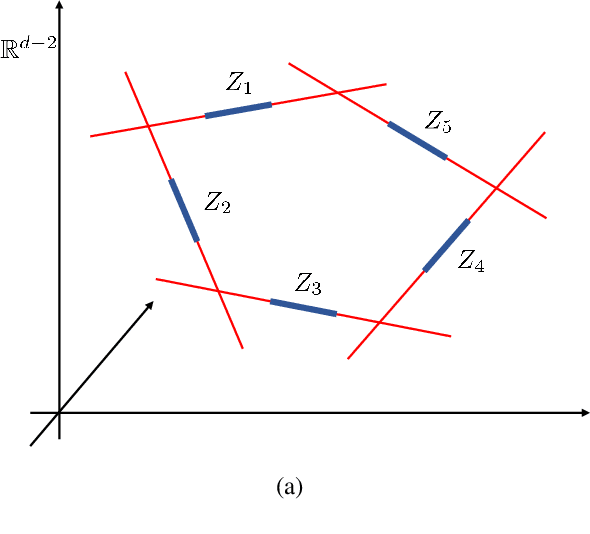
Sep 09, 2022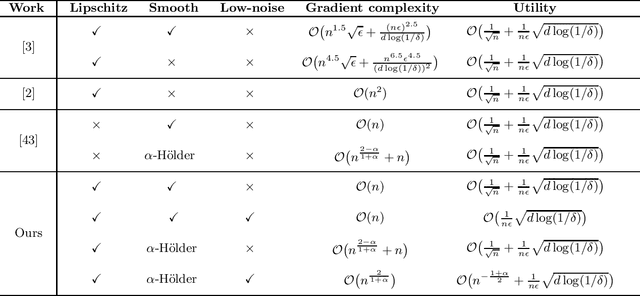

In this paper, by introducing a low-noise condition, we study privacy and utility (generalization) performances of differentially private stochastic gradient descent (SGD) algorithms in a setting of stochastic convex optimization (SCO) for both pointwise and pairwise learning problems. For pointwise learning, we establish sharper excess risk bounds of order $\mathcal{O}\Big( \frac{\sqrt{d\log(1/\delta)}}{n\epsilon} \Big)$ and $\mathcal{O}\Big( {n^{- \frac{1+\alpha}{2}}}+\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}\Big)$ for the $(\epsilon,\delta)$-differentially private SGD algorithm for strongly smooth and $\alpha$-H\"older smooth losses, respectively, where $n$ is the sample size and $d$ is the dimensionality. For pairwise learning, inspired by \cite{lei2020sharper,lei2021generalization}, we propose a simple private SGD algorithm based on gradient perturbation which satisfies $(\epsilon,\delta)$-differential privacy, and develop novel utility bounds for the proposed algorithm. In particular, we prove that our algorithm can achieve excess risk rates $\mathcal{O}\Big(\frac{1}{\sqrt{n}}+\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}\Big)$ with gradient complexity $\mathcal{O}(n)$ and $\mathcal{O}\big(n^{\frac{2-\alpha}{1+\alpha}}+n\big)$ for strongly smooth and $\alpha$-H\"older smooth losses, respectively. Further, faster learning rates are established in a low-noise setting for both smooth and non-smooth losses. To the best of our knowledge, this is the first utility analysis which provides excess population bounds better than $\mathcal{O}\Big(\frac{1}{\sqrt{n}}+\frac{\sqrt{d\log(1/\delta)}}{n\epsilon}\Big)$ for privacy-preserving pairwise learning.
Attention Enables Zero Approximation Error
Feb 24, 2022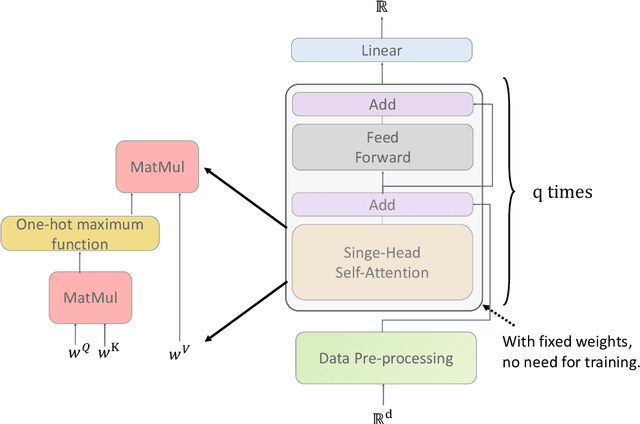

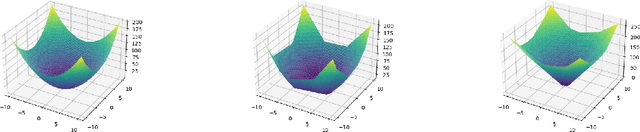
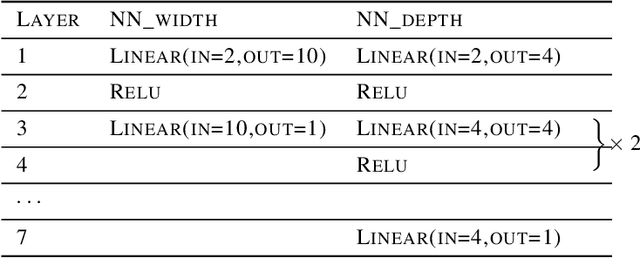
Deep learning models have been widely applied in various aspects of daily life. Many variant models based on deep learning structures have achieved even better performances. Attention-based architectures have become almost ubiquitous in deep learning structures. Especially, the transformer model has now defeated the convolutional neural network in image classification tasks to become the most widely used tool. However, the theoretical properties of attention-based models are seldom considered. In this work, we show that with suitable adaptations, the single-head self-attention transformer with a fixed number of transformer encoder blocks and free parameters is able to generate any desired polynomial of the input with no error. The number of transformer encoder blocks is the same as the degree of the target polynomial. Even more exciting, we find that these transformer encoder blocks in this model do not need to be trained. As a direct consequence, we show that the single-head self-attention transformer with increasing numbers of free parameters is universal. These surprising theoretical results clearly explain the outstanding performances of the transformer model and may shed light on future modifications in real applications. We also provide some experiments to verify our theoretical result.