 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention Enables Zero Approximation Error
Paper and Code
Feb 24, 2022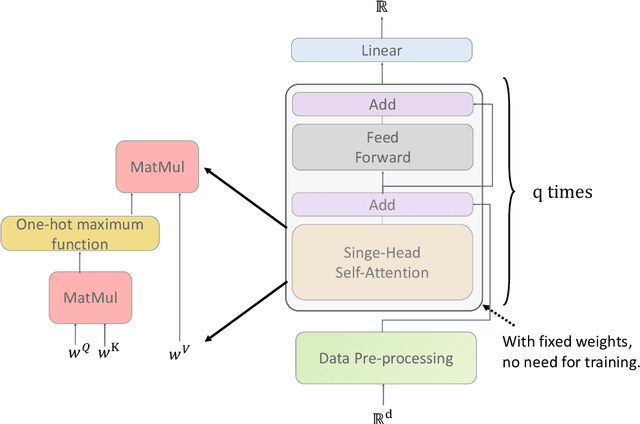

Deep learning models have been widely applied in various aspects of daily life. Many variant models based on deep learning structures have achieved even better performances. Attention-based architectures have become almost ubiquitous in deep learning structures. Especially, the transformer model has now defeated the convolutional neural network in image classification tasks to become the most widely used tool. However, the theoretical properties of attention-based models are seldom considered. In this work, we show that with suitable adaptations, the single-head self-attention transformer with a fixed number of transformer encoder blocks and free parameters is able to generate any desired polynomial of the input with no error. The number of transformer encoder blocks is the same as the degree of the target polynomial. Even more exciting, we find that these transformer encoder blocks in this model do not need to be trained. As a direct consequence, we show that the single-head self-attention transformer with increasing numbers of free parameters is universal. These surprising theoretical results clearly explain the outstanding performances of the transformer model and may shed light on future modifications in real applications. We also provide some experiments to verify our theoretical result.