 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibration of Human Driving Behavior and Preference Using Naturalistic Traffic Data
May 05, 2021
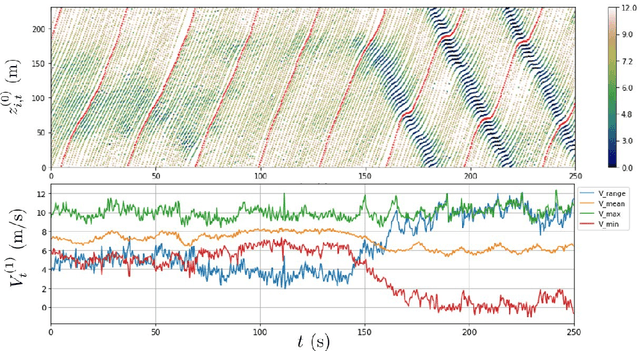
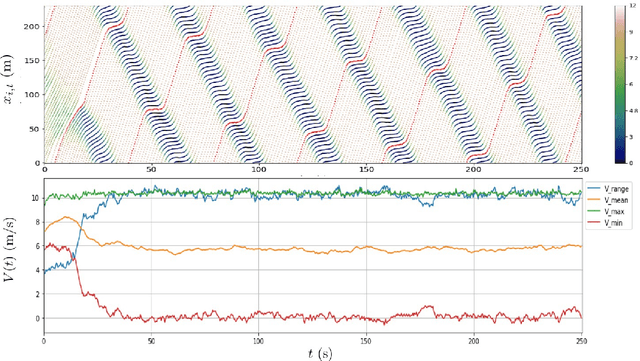
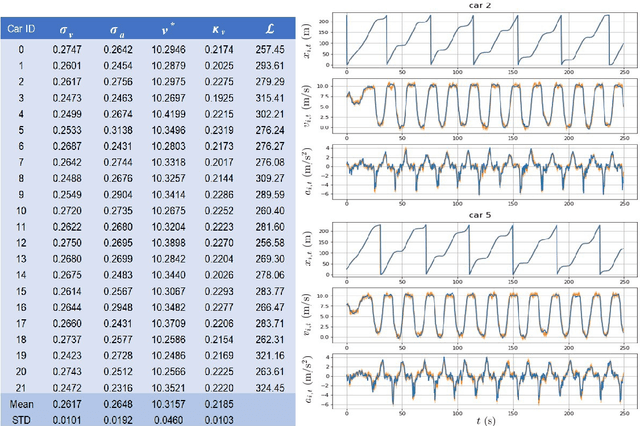
Understanding human driving behaviors quantitatively is critical even in the era when connected and autonomous vehicles and smart infrastructure are becoming ever more prevalent. This is particularly so as that mixed traffic settings, where autonomous vehicles and human driven vehicles co-exist, are expected to persist for quite some time. Towards this end it is necessary that we have a comprehensive modeling framework for decision-making within which human driving preferences can be inferred statistically from observed driving behaviors in realistic and naturalistic traffic settings. Leveraging a recently proposed computational framework for smart vehicles in a smart world using multi-agent based simulation and optimization, we first recapitulate how the forward problem of driving decision-making is modeled as a state space model. We then show how the model can be inverted to estimate driver preferences from naturalistic traffic data using the standard Kalman filter technique. We explicitly illustrate our approach using the vehicle trajectory data from Sugiyama experiment that was originally meant to demonstrate how stop-and-go shockwave can arise spontaneously without bottlenecks. Not only the estimated state filter can fit the observed data well for each individual vehicle, the inferred utility functions can also re-produce quantitatively similar pattern of the observed collective behaviors. One distinct advantage of our approach is the drastically reduced computational burden. This is possible because our forward model treats driving decision process, which is intrinsically dynamic with multi-agent interactions, as a sequence of independent static optimization problems contingent on the state with a finite look ahead anticipation. Consequently we can practically sidestep solving an interacting dynamic inversion problem that would have been much more computationally demanding.
Efficient data-driven encoding of scene motion using Eccentricity
Mar 03, 2021
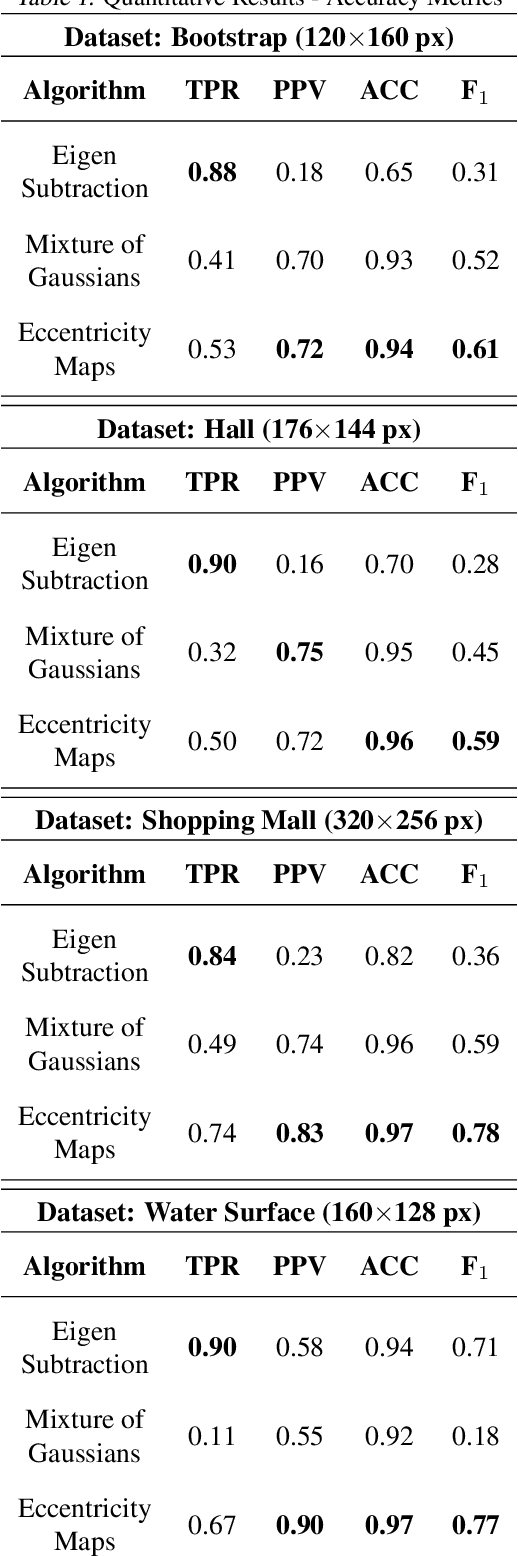

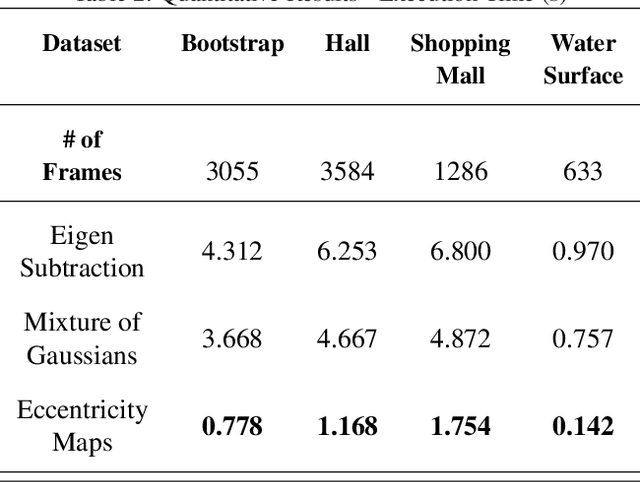
This paper presents a novel approach of representing dynamic visual scenes with static maps generated from video/image streams. Such representation allows easy visual assessment of motion in dynamic environments. These maps are 2D matrices calculated recursively, in a pixel-wise manner, that is based on the recently introduced concept of Eccentricity data analysis. Eccentricity works as a metric of a discrepancy between a particular pixel of an image and its normality model, calculated in terms of mean and variance of past readings of the same spatial region of the image. While Eccentricity maps carry temporal information about the scene, actual images do not need to be stored nor processed in batches. Rather, all the calculations are done recursively, based on a small amount of statistical information stored in memory, thus resulting in a very computationally efficient (processor- and memory-wise) method. The list of potential applications includes video-based activity recognition, intent recognition, object tracking, video description, and so on.
Safe Reinforcement Learning Using Robust Action Governor
Feb 21, 2021
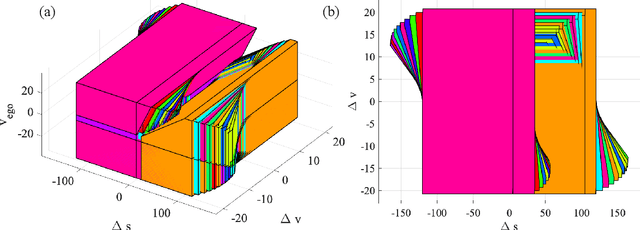
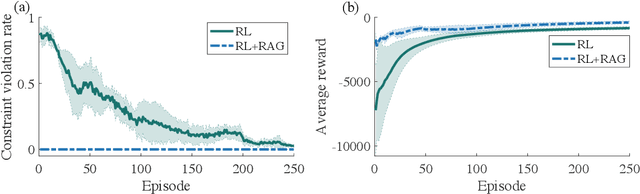
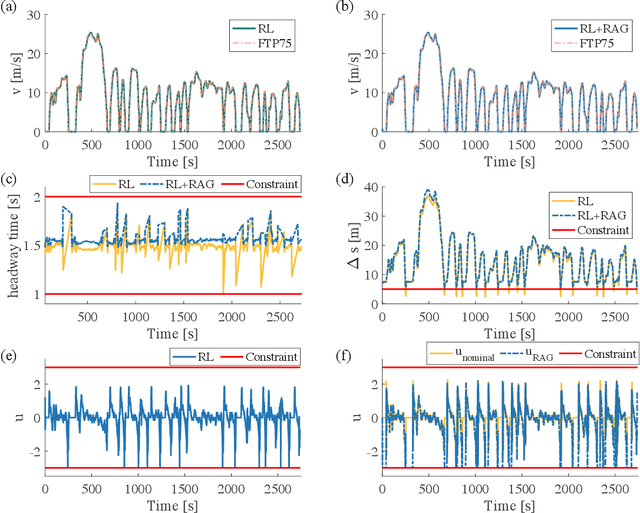
Reinforcement Learning (RL) is essentially a trial-and-error learning procedure which may cause unsafe behavior during the exploration-and-exploitation process. This hinders the applications of RL to real-world control problems, especially to those for safety-critical systems. In this paper, we introduce a framework for safe RL that is based on integration of an RL algorithm with an add-on safety supervision module, called the Robust Action Governor (RAG), which exploits set-theoretic techniques and online optimization to manage safety-related requirements during learning. We illustrate this proposed safe RL framework through an application to automotive adaptive cruise control.
Towards a Systematic Computational Framework for Modeling Multi-Agent Decision-Making at Micro Level for Smart Vehicles in a Smart World
Sep 25, 2020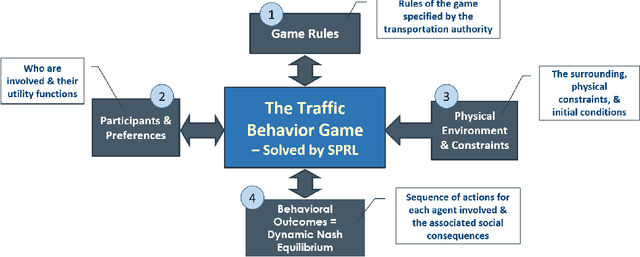
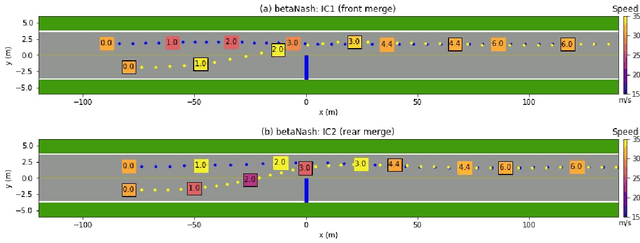
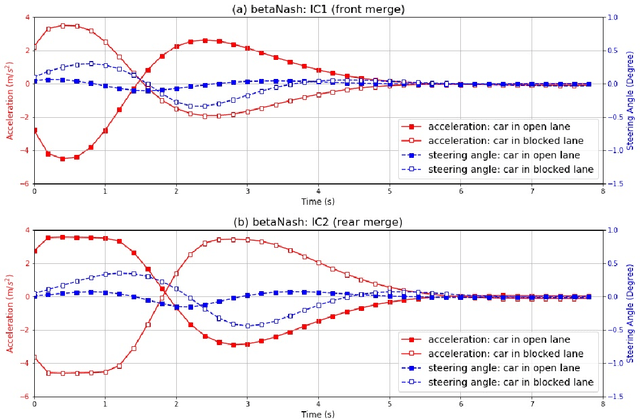
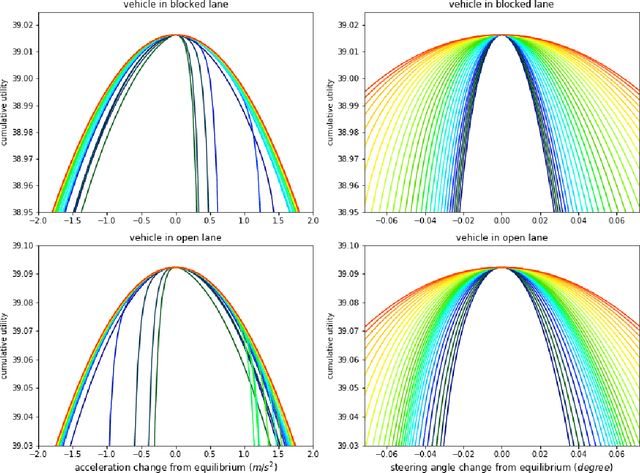
We propose a multi-agent based computational framework for modeling decision-making and strategic interaction at micro level for smart vehicles in a smart world. The concepts of Markov game and best response dynamics are heavily leveraged. Our aim is to make the framework conceptually sound and computationally practical for a range of realistic applications, including micro path planning for autonomous vehicles. To this end, we first convert the would-be stochastic game problem into a closely related deterministic one by introducing risk premium in the utility function for each individual agent. We show how the sub-game perfect Nash equilibrium of the simplified deterministic game can be solved by an algorithm based on best response dynamics. In order to better model human driving behaviors with bounded rationality, we seek to further simplify the solution concept by replacing the Nash equilibrium condition with a heuristic and adaptive optimization with finite look-ahead anticipation. In addition, the algorithm corresponding to the new solution concept drastically improves the computational efficiency. To demonstrate how our approach can be applied to realistic traffic settings, we conduct a simulation experiment: to derive merging and yielding behaviors on a double-lane highway with an unexpected barrier. Despite assumption differences involved in the two solution concepts, the derived numerical solutions show that the endogenized driving behaviors are very similar. We also briefly comment on how the proposed framework can be further extended in a number of directions in our forthcoming work, such as behavioral calibration using real traffic video data, computational mechanism design for traffic policy optimization, and so on.
Interpretable-AI Policies using Evolutionary Nonlinear Decision Trees for Discrete Action Systems
Sep 20, 2020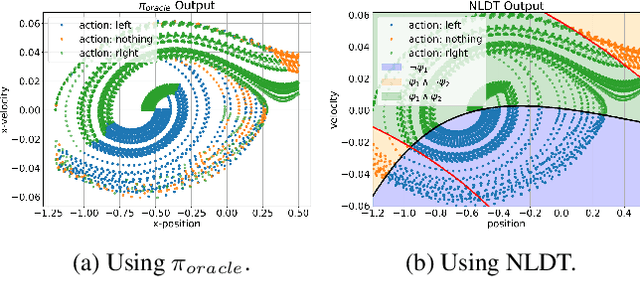

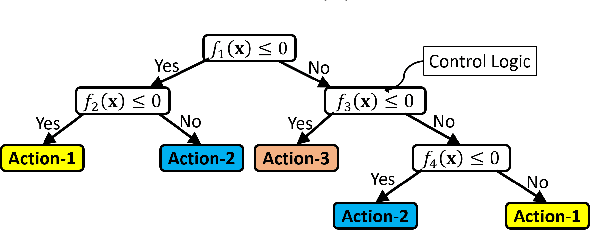
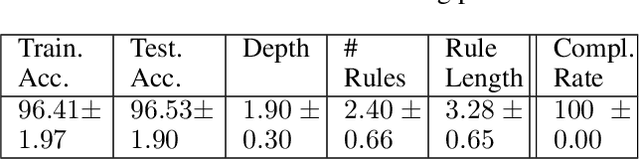
Black-box artificial intelligence (AI) induction methods such as deep reinforcement learning (DRL) are increasingly being used to find optimal policies for a given control task. Although policies represented using a black-box AI are capable of efficiently executing the underlying control task and achieving optimal closed-loop performance -- controlling the agent from initial time step until the successful termination of an episode, the developed control rules are often complex and neither interpretable nor explainable. In this paper, we use a recently proposed nonlinear decision-tree (NLDT) approach to find a hierarchical set of control rules in an attempt to maximize the open-loop performance for approximating and explaining the pre-trained black-box DRL (oracle) agent using the labelled state-action dataset. Recent advances in nonlinear optimization approaches using evolutionary computation facilitates finding a hierarchical set of nonlinear control rules as a function of state variables using a computationally fast bilevel optimization procedure at each node of the proposed NLDT. Additionally, we propose a re-optimization procedure for enhancing closed-loop performance of an already derived NLDT. We evaluate our proposed methodologies on four different control problems having two to four discrete actions. In all these problems our proposed approach is able to find simple and interpretable rules involving one to four non-linear terms per rule, while simultaneously achieving on par closed-loop performance when compared to a trained black-box DRL agent. The obtained results are inspiring as they suggest the replacement of complicated black-box DRL policies involving thousands of parameters (making them non-interpretable) with simple interpretable policies. Results are encouraging and motivating to pursue further applications of proposed approach in solving more complex control tasks.
A Game Theoretic Approach for Parking Spot Search with Limited Parking Lot Information
May 11, 2020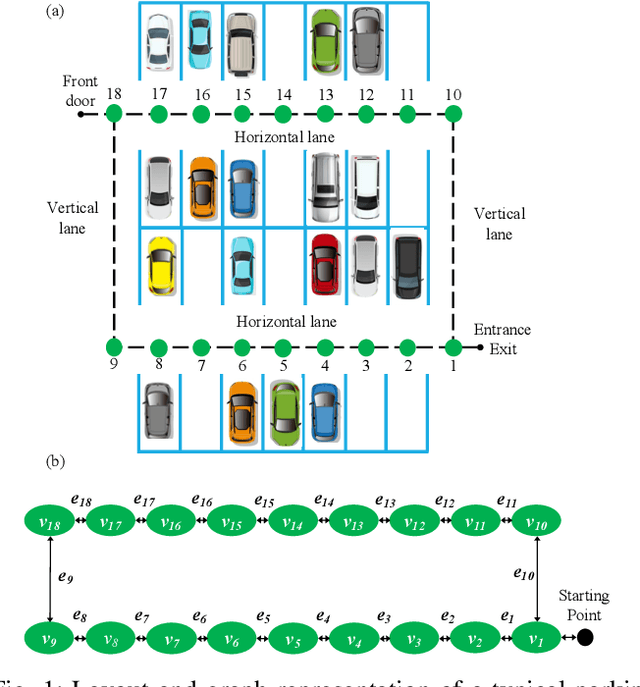
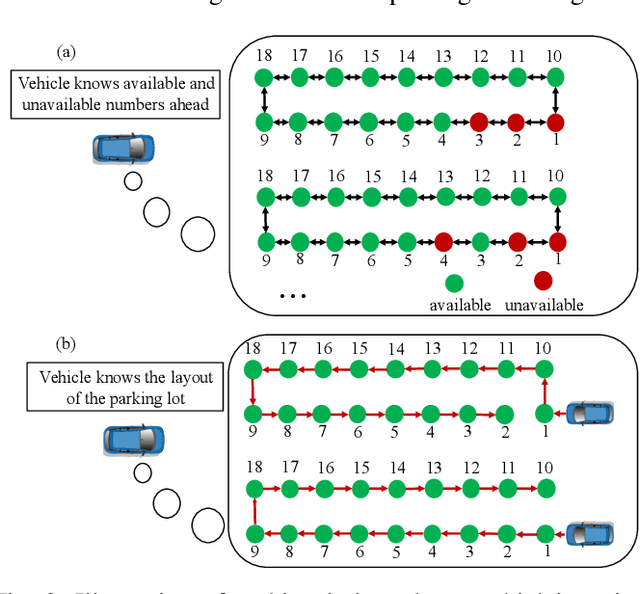


We propose a game theoretic approach to address the problem of searching for available parking spots in a parking lot and picking the ``optimal'' one to park. The approach exploits limited information provided by the parking lot, i.e., its layout and the current number of cars in it. Considering the fact that such information is or can be easily made available for many structured parking lots, the proposed approach can be applicable without requiring major updates to existing parking facilities. For large parking lots, a sampling-based strategy is integrated with the proposed approach to overcome the associated computational challenge. The proposed approach is compared against a state-of-the-art heuristic-based parking spot search strategy in the literature through simulation studies and demonstrates its advantage in terms of achieving lower cost function values.
Deep Reinforcement Learning with Enhanced Safety for Autonomous Highway Driving
Oct 28, 2019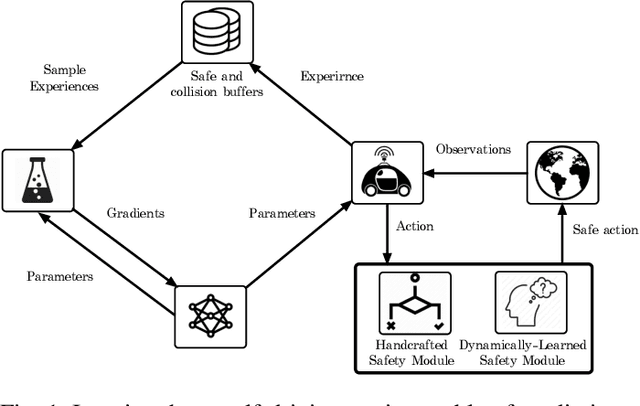
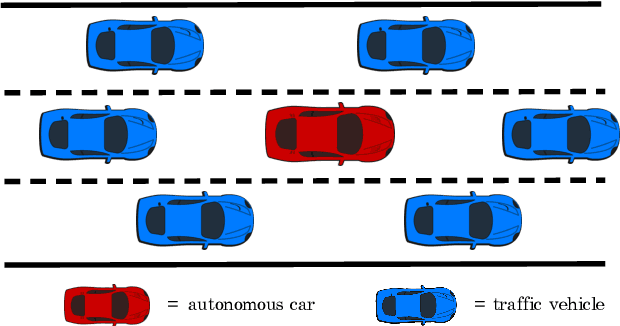
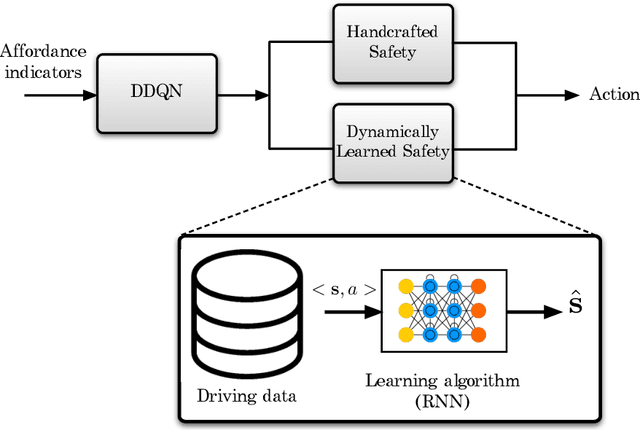
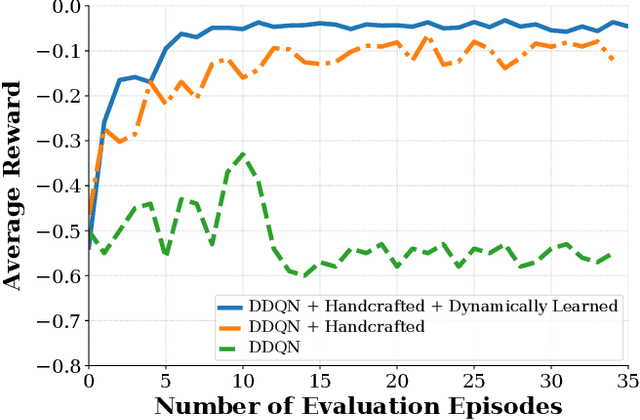
In this paper, we present a safe deep reinforcement learning system for automated driving. The proposed framework leverages merits of both rule-based and learning-based approaches for safety assurance. Our safety system consists of two modules namely handcrafted safety and dynamically-learned safety. The handcrafted safety module is a heuristic safety rule based on common driving practice that ensure a minimum relative gap to a traffic vehicle. On the other hand, the dynamically-learned safety module is a data-driven safety rule that learns safety patterns from driving data. Specifically, the dynamically-leaned safety module incorporates a model lookahead beyond the immediate reward of reinforcement learning to predict safety longer into the future. If one of the future states leads to a near-miss or collision, then a negative reward will be assigned to the reward function to avoid collision and accelerate the learning process. We demonstrate the capability of the proposed framework in a simulation environment with varying traffic density. Our results show the superior capabilities of the policy enhanced with dynamically-learned safety module.
An Online Evolving Framework for Modeling the Safe Autonomous Vehicle Control System via Online Recognition of Latent Risks
Aug 28, 2019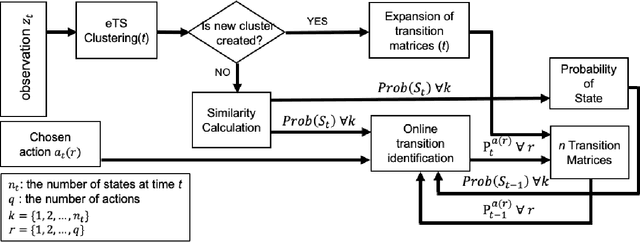
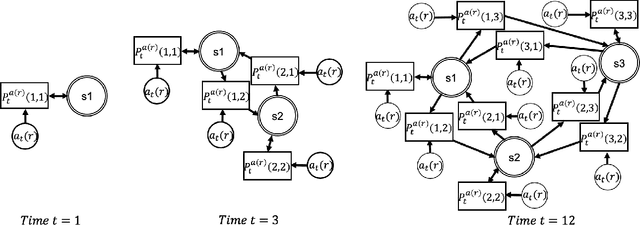
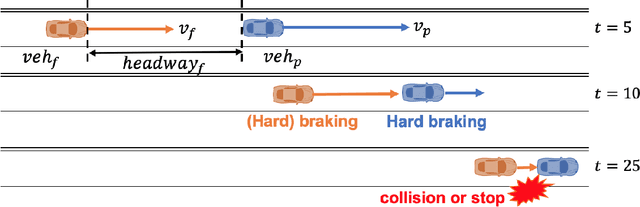
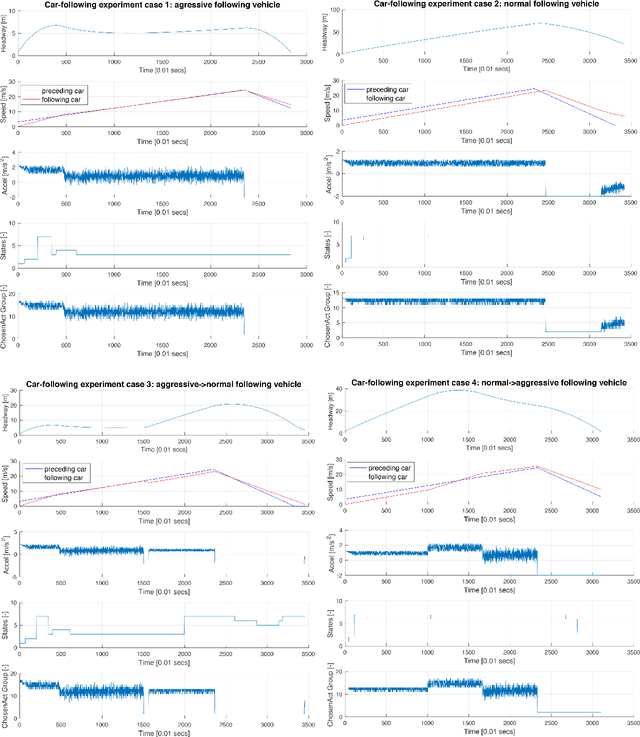
An online evolving framework is proposed to support modeling the safe Automated Vehicle (AV) control system by making the controller able to recognize unexpected situations and react appropriately by choosing a better action. Within the framework, the evolving Finite State Machine (e-FSM), which is an online model able to (1) determine states uniquely as needed, (2) recognize states, and (3) identify state-transitions, is introduced. In this study, the e-FSM's capabilities are explained and illustrated by simulating a simple car-following scenario. As a vehicle controller, the Intelligent Driver Model (IDM) is implemented, and different sets of IDM parameters are assigned to the following vehicle for simulating various situations (including the collision). While simulating the car-following scenario, e-FSM recognizes and determines the states and identifies the transition matrices by suggested methods. To verify if e-FSM can recognize and determine states uniquely, we analyze whether the same state is recognized under the identical situation. The difference between probability distributions of predicted and recognized states is measured by the Jensen-Shannon divergence (JSD) method to validate the accuracy of identified transition-matrices. As shown in the results, the Dead-End state which has latent-risk of the collision is uniquely determined and consistently recognized. Also, the probability distributions of the predicted state are significantly similar to the recognized state, declaring that the state-transitions are precisely identified.
Autonomous Highway Driving using Deep Reinforcement Learning
Mar 29, 2019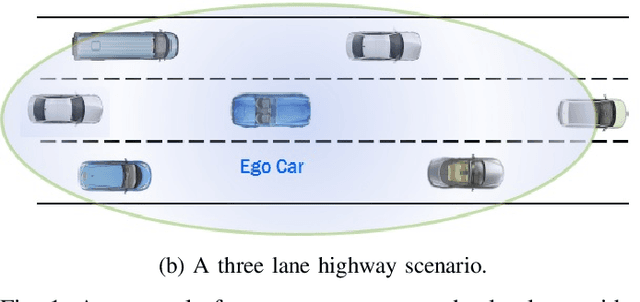
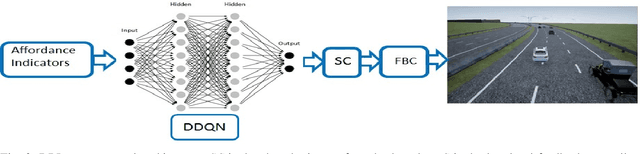

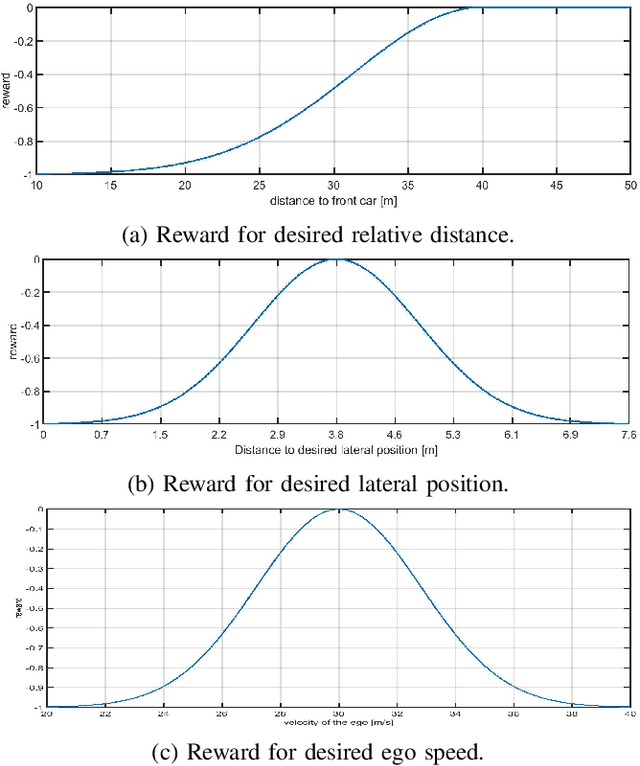
The operational space of an autonomous vehicle (AV) can be diverse and vary significantly. This may lead to a scenario that was not postulated in the design phase. Due to this, formulating a rule based decision maker for selecting maneuvers may not be ideal. Similarly, it may not be effective to design an a-priori cost function and then solve the optimal control problem in real-time. In order to address these issues and to avoid peculiar behaviors when encountering unforeseen scenario, we propose a reinforcement learning (RL) based method, where the ego car, i.e., an autonomous vehicle, learns to make decisions by directly interacting with simulated traffic. The decision maker for AV is implemented as a deep neural network providing an action choice for a given system state. In a critical application such as driving, an RL agent without explicit notion of safety may not converge or it may need extremely large number of samples before finding a reliable policy. To best address the issue, this paper incorporates reinforcement learning with an additional short horizon safety check (SC). In a critical scenario, the safety check will also provide an alternate safe action to the agent provided if it exists. This leads to two novel contributions. First, it generalizes the states that could lead to undesirable "near-misses" or "collisions ". Second, inclusion of safety check can provide a safe and stable training environment. This significantly enhances learning efficiency without inhibiting meaningful exploration to ensure safe and optimal learned behavior. We demonstrate the performance of the developed algorithm in highway driving scenario where the trained AV encounters varying traffic density in a highway setting.