 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Few-Shot Image Classification: a Good Embedding Is All You Need?
Mar 25, 2020
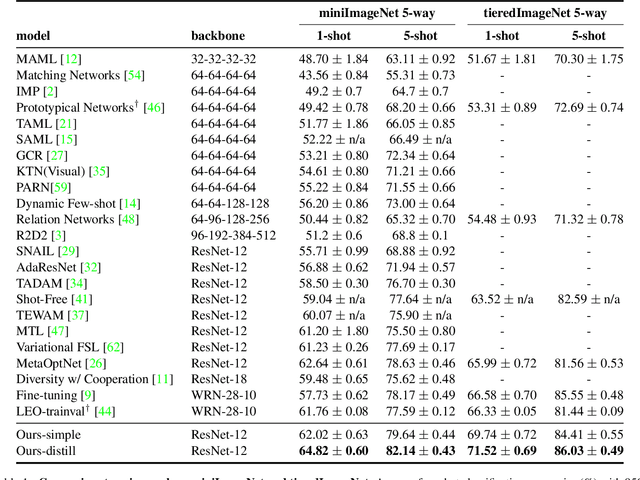
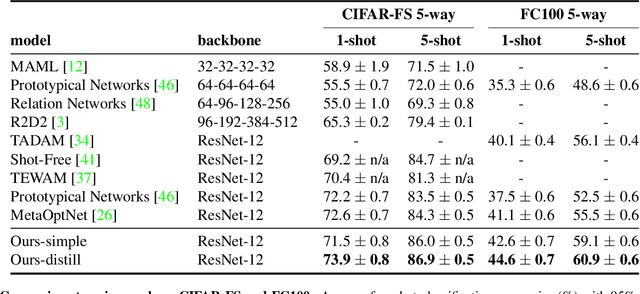
The focus of recent meta-learning research has been on the development of learning algorithms that can quickly adapt to test time tasks with limited data and low computational cost. Few-shot learning is widely used as one of the standard benchmarks in meta-learning. In this work, we show that a simple baseline: learning a supervised or self-supervised representation on the meta-training set, followed by training a linear classifier on top of this representation, outperforms state-of-the-art few-shot learning methods. An additional boost can be achieved through the use of self-distillation. This demonstrates that using a good learned embedding model can be more effective than sophisticated meta-learning algorithms. We believe that our findings motivate a rethinking of few-shot image classification benchmarks and the associated role of meta-learning algorithms. Code is available at: http://github.com/WangYueFt/rfs/.
Fantastic Generalization Measures and Where to Find Them
Dec 04, 2019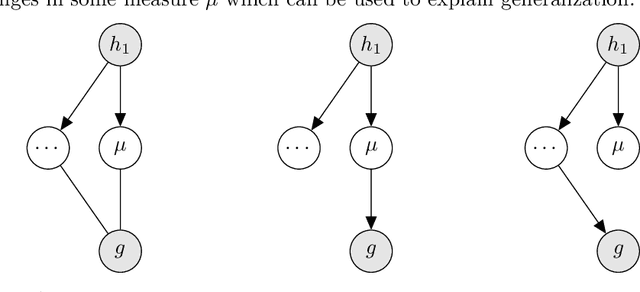
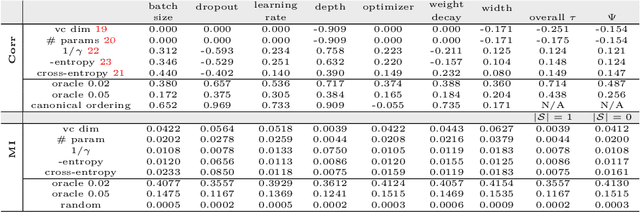
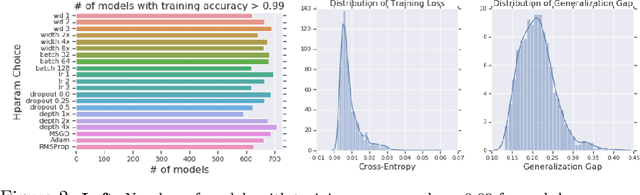
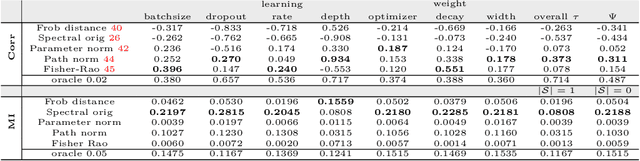
Generalization of deep networks has been of great interest in recent years, resulting in a number of theoretically and empirically motivated complexity measures. However, most papers proposing such measures study only a small set of models, leaving open the question of whether the conclusion drawn from those experiments would remain valid in other settings. We present the first large scale study of generalization in deep networks. We investigate more then 40 complexity measures taken from both theoretical bounds and empirical studies. We train over 10,000 convolutional networks by systematically varying commonly used hyperparameters. Hoping to uncover potentially causal relationships between each measure and generalization, we analyze carefully controlled experiments and show surprising failures of some measures as well as promising measures for further research.
Contrastive Representation Distillation
Oct 23, 2019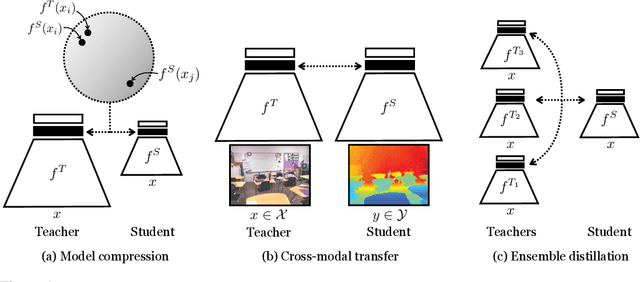
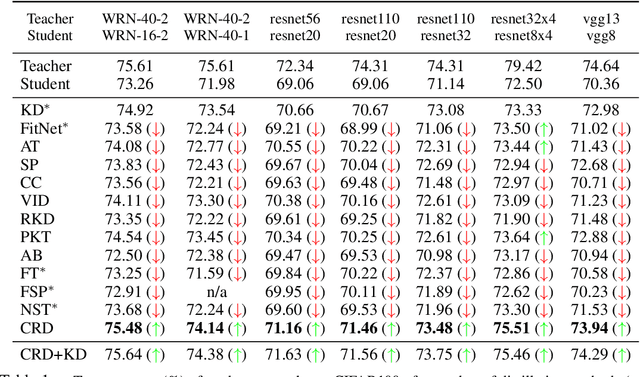
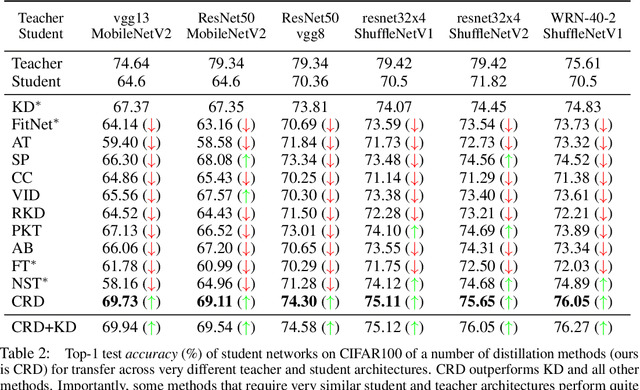
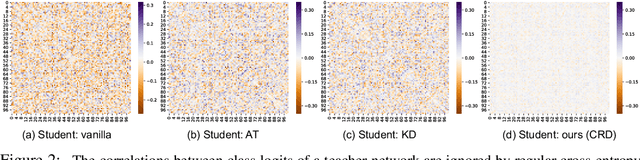
Often we wish to transfer representational knowledge from one neural network to another. Examples include distilling a large network into a smaller one, transferring knowledge from one sensory modality to a second, or ensembling a collection of models into a single estimator. Knowledge distillation, the standard approach to these problems, minimizes the KL divergence between the probabilistic outputs of a teacher and student network. We demonstrate that this objective ignores important structural knowledge of the teacher network. This motivates an alternative objective by which we train a student to capture significantly more information in the teacher's representation of the data. We formulate this objective as contrastive learning. Experiments demonstrate that our resulting new objective outperforms knowledge distillation and other cutting-edge distillers on a variety of knowledge transfer tasks, including single model compression, ensemble distillation, and cross-modal transfer. Our method sets a new state-of-the-art in many transfer tasks, and sometimes even outperforms the teacher network when combined with knowledge distillation. Code: http://github.com/HobbitLong/RepDistiller.
Boundless: Generative Adversarial Networks for Image Extension
Aug 19, 2019
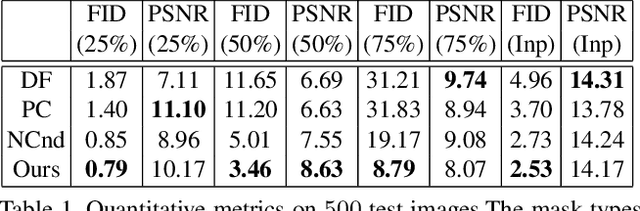
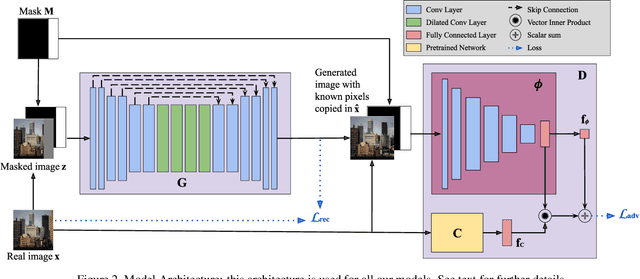
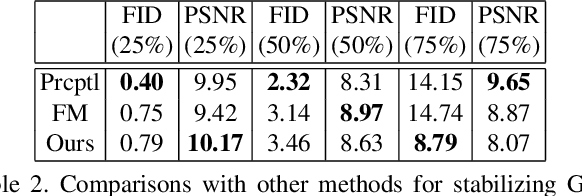
Image extension models have broad applications in image editing, computational photography and computer graphics. While image inpainting has been extensively studied in the literature, it is challenging to directly apply the state-of-the-art inpainting methods to image extension as they tend to generate blurry or repetitive pixels with inconsistent semantics. We introduce semantic conditioning to the discriminator of a generative adversarial network (GAN), and achieve strong results on image extension with coherent semantics and visually pleasing colors and textures. We also show promising results in extreme extensions, such as panorama generation.
Adversarial Robustness through Local Linearization
Jul 04, 2019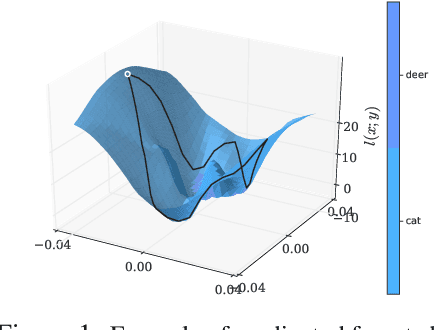
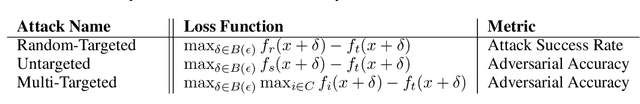
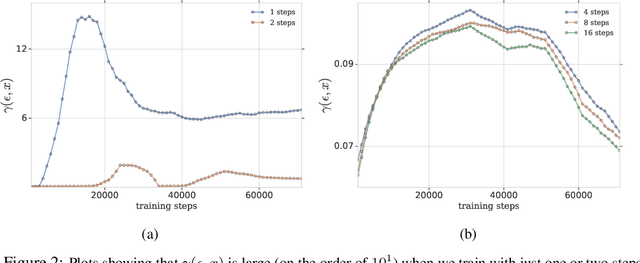
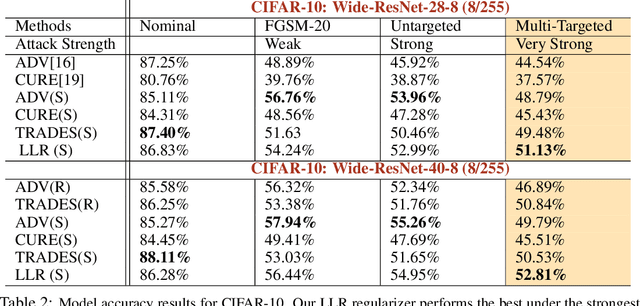
Adversarial training is an effective methodology for training deep neural networks that are robust against adversarial, norm-bounded perturbations. However, the computational cost of adversarial training grows prohibitively as the size of the model and number of input dimensions increase. Further, training against less expensive and therefore weaker adversaries produces models that are robust against weak attacks but break down under attacks that are stronger. This is often attributed to the phenomenon of gradient obfuscation; such models have a highly non-linear loss surface in the vicinity of training examples, making it hard for gradient-based attacks to succeed even though adversarial examples still exist. In this work, we introduce a novel regularizer that encourages the loss to behave linearly in the vicinity of the training data, thereby penalizing gradient obfuscation while encouraging robustness. We show via extensive experiments on CIFAR-10 and ImageNet, that models trained with our regularizer avoid gradient obfuscation and can be trained significantly faster than adversarial training. Using this regularizer, we exceed current state of the art and achieve 47% adversarial accuracy for ImageNet with l-infinity adversarial perturbations of radius 4/255 under an untargeted, strong, white-box attack. Additionally, we match state of the art results for CIFAR-10 at 8/255.
Contrastive Multiview Coding
Jun 23, 2019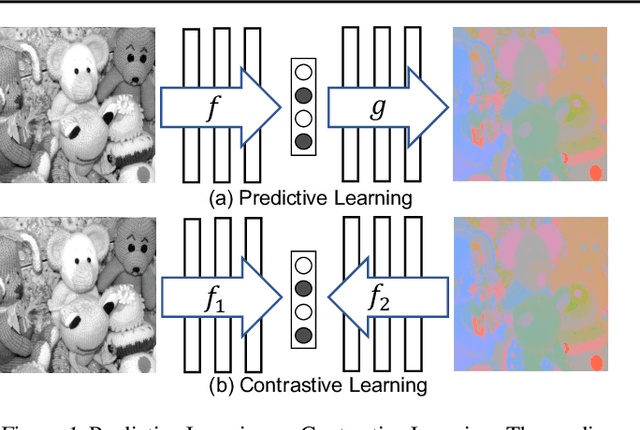
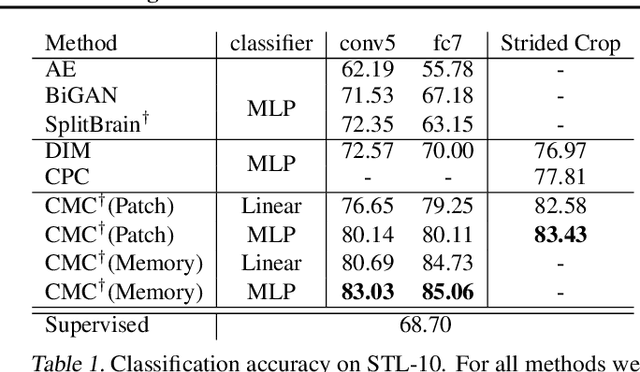
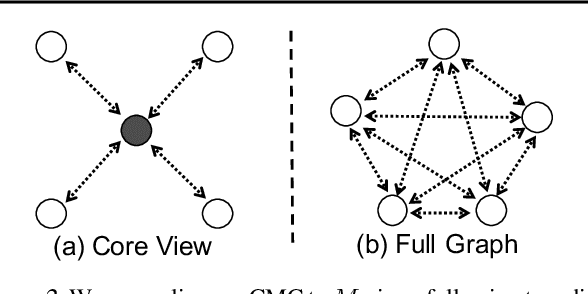
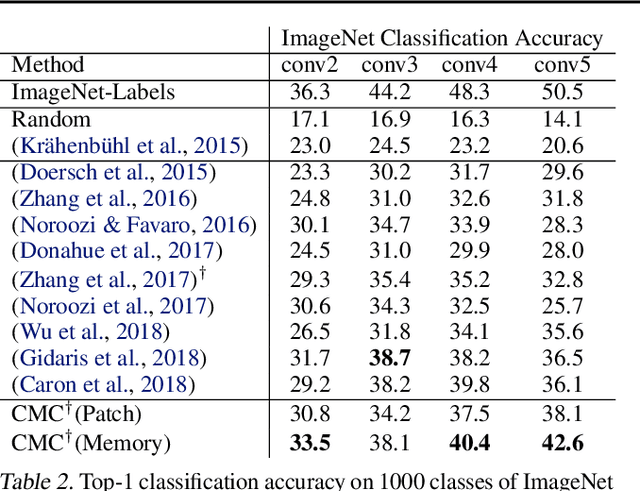
Humans view the world through many sensory channels, e.g., the long-wavelength light channel, viewed by the left eye, or the high-frequency vibrations channel, viewed by the right ear. Each view is noisy and incomplete, but important factors, such as physics, geometry, and semantics, tend to be shared between all views (e.g., a "dog" can be seen, heard, and felt). We hypothesize that a powerful representation is one that models view-invariant factors. Based on this hypothesis, we investigate a contrastive coding scheme, in which a representation is learned that aims to maximize mutual information between different views but is otherwise compact. Our approach scales to any number of views, and is view-agnostic. The resulting learned representations perform above the state of the art for downstream tasks such as object classification, compared to formulations based on predictive learning or single view reconstruction, and improve as more views are added. Code and reference implementations are released on our project page: http://github.com/HobbitLong/CMC/.
A Closed-Form Learned Pooling for Deep Classification Networks
Jun 10, 2019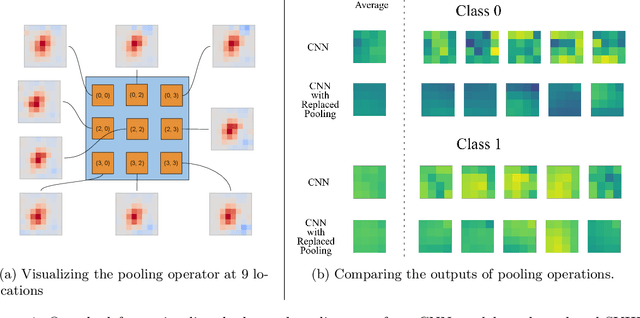
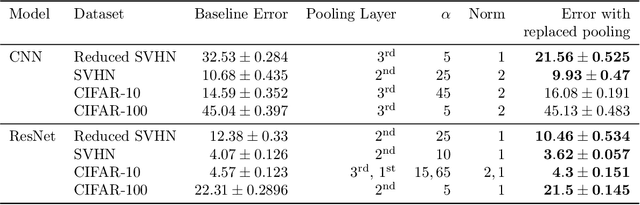
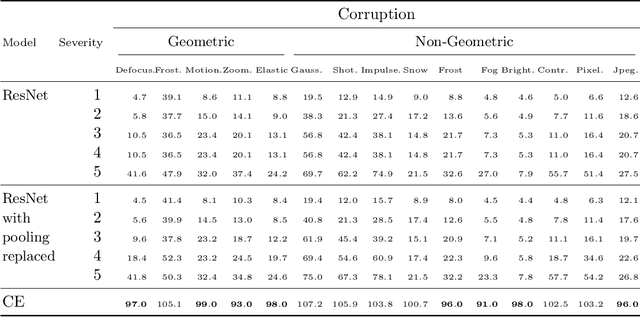
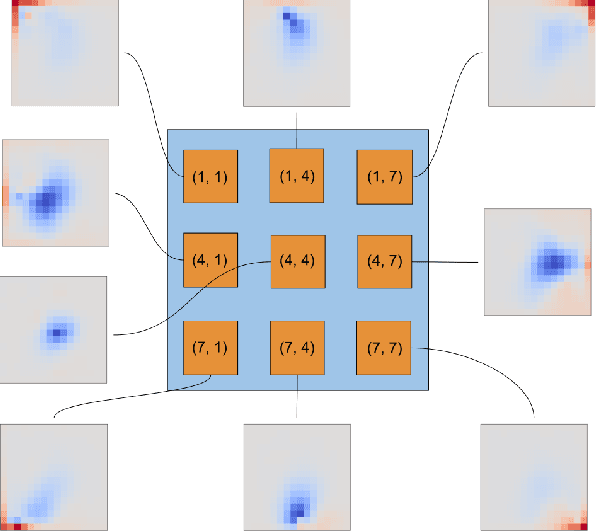
In modern computer vision tasks, convolutional neural networks (CNNs) are indispensable for image classification tasks due to their efficiency and effectiveness. Part of their superiority compared to other architectures, comes from the fact that a single, local filter is shared across the entire image. However, there are scenarios where we may need to treat spatial locations in non-uniform manner. We see this in nature when considering how humans have evolved foveation to process different areas in their field of vision with varying levels of detail. In this paper we propose a way to enable CNNs to learn different pooling weights for each pixel location. We do so by introducing an extended definition of a pooling operator. This operator can learn a strict super-set of what can be learned by average pooling or convolutions. It has the benefit of being shared across feature maps and can be encouraged to be local or diffuse depending on the data. We show that for fixed network weights, our pooling operator can be computed in closed-form by spectral decomposition of matrices associated with class separability. Through experiments, we show that this operator benefits generalization for ResNets and CNNs on the CIFAR-10, CIFAR-100 and SVHN datasets and improves robustness to geometric corruptions and perturbations on the CIFAR-10-C and CIFAR-10-P test sets.
Predicting the Generalization Gap in Deep Networks with Margin Distributions
Sep 28, 2018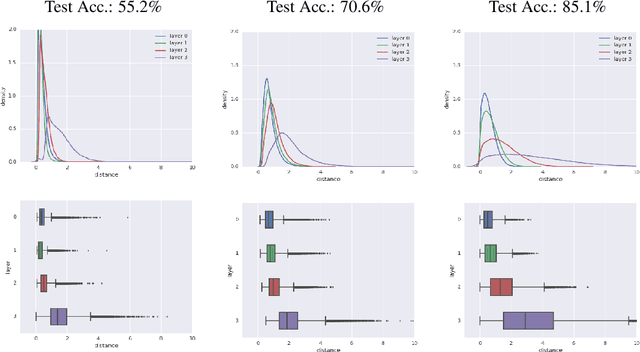
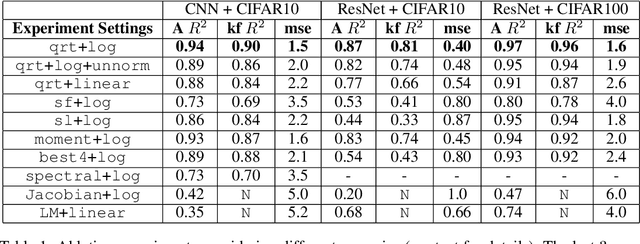
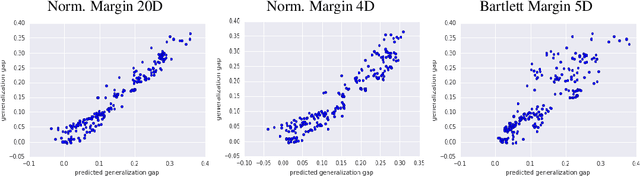
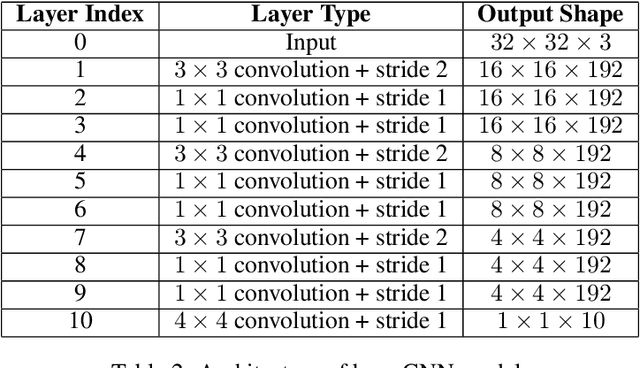
As shown in recent research, deep neural networks can perfectly fit randomly labeled data, but with very poor accuracy on held out data. This phenomenon indicates that loss functions such as cross-entropy are not a reliable indicator of generalization. This leads to the crucial question of how generalization gap should be predicted from the training data and network parameters. In this paper, we propose such a measure, and conduct extensive empirical studies on how well it can predict the generalization gap. Our measure is based on the concept of margin distribution, which are the distances of training points to the decision boundary. We find that it is necessary to use margin distributions at multiple layers of a deep network. On the CIFAR-10 and the CIFAR-100 datasets, our proposed measure correlates very strongly with the generalization gap. In addition, we find the following other factors to be of importance: normalizing margin values for scale independence, using characterizations of margin distribution rather than just the margin (closest distance to decision boundary), and working in log space instead of linear space (effectively using a product of margins rather than a sum). Our measure can be easily applied to feedforward deep networks with any architecture and may point towards new training loss functions that could enable better generalization.
Smart, Sparse Contours to Represent and Edit Images
Apr 09, 2018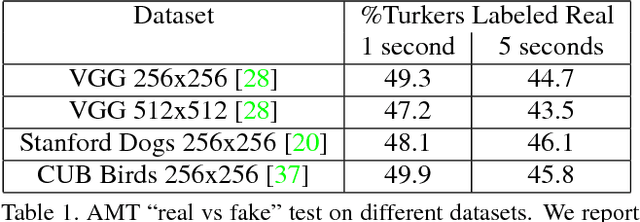

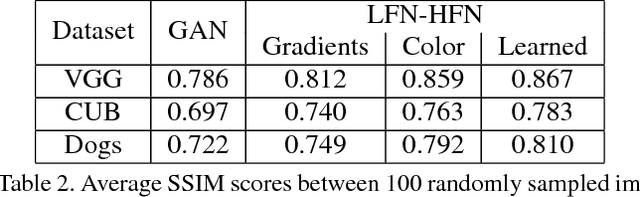
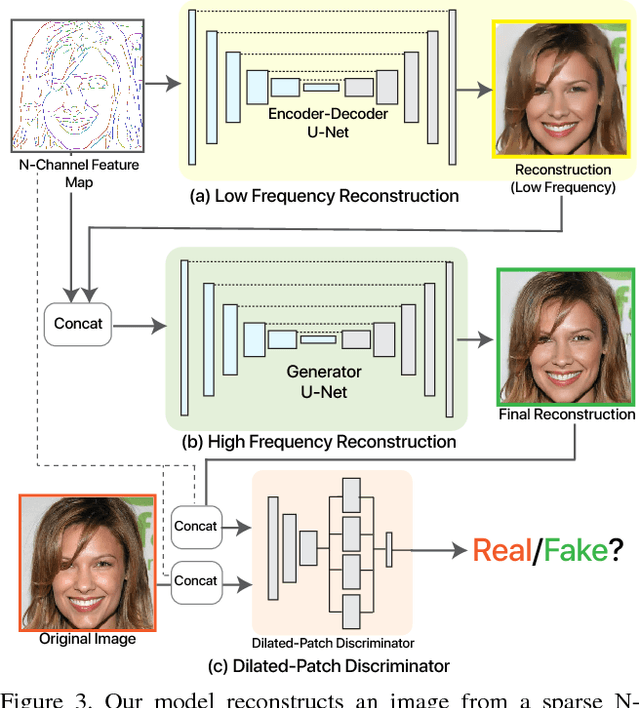
We study the problem of reconstructing an image from information stored at contour locations. We show that high-quality reconstructions with high fidelity to the source image can be obtained from sparse input, e.g., comprising less than $6\%$ of image pixels. This is a significant improvement over existing contour-based reconstruction methods that require much denser input to capture subtle texture information and to ensure image quality. Our model, based on generative adversarial networks, synthesizes texture and details in regions where no input information is provided. The semantic knowledge encoded into our model and the sparsity of the input allows to use contours as an intuitive interface for semantically-aware image manipulation: local edits in contour domain translate to long-range and coherent changes in pixel space. We can perform complex structural changes such as changing facial expression by simple edits of contours. Our experiments demonstrate that humans as well as a face recognition system mostly cannot distinguish between our reconstructions and the source images.
Large Margin Deep Networks for Classification
Mar 15, 2018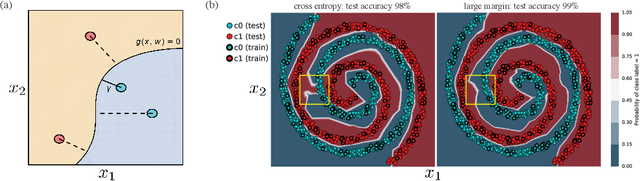
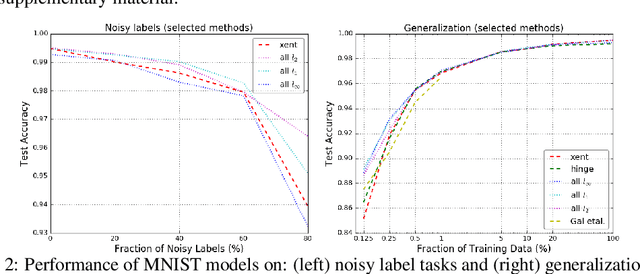
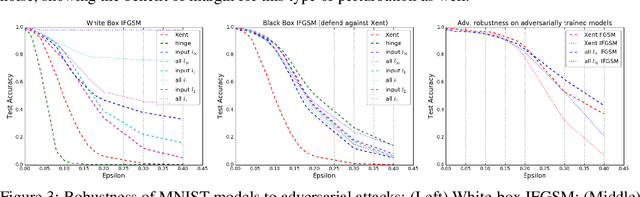
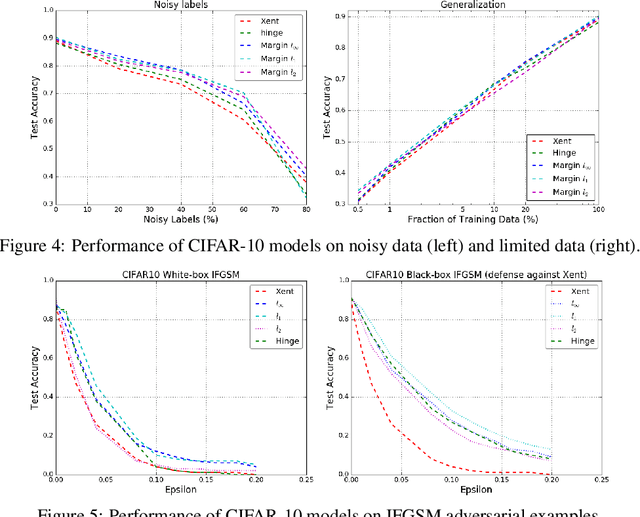
We present a formulation of deep learning that aims at producing a large margin classifier. The notion of margin, minimum distance to a decision boundary, has served as the foundation of several theoretically profound and empirically successful results for both classification and regression tasks. However, most large margin algorithms are applicable only to shallow models with a preset feature representation; and conventional margin methods for neural networks only enforce margin at the output layer. Such methods are therefore not well suited for deep networks. In this work, we propose a novel loss function to impose a margin on any chosen set of layers of a deep network (including input and hidden layers). Our formulation allows choosing any norm on the metric measuring the margin. We demonstrate that the decision boundary obtained by our loss has nice properties compared to standard classification loss functions. Specifically, we show improved empirical results on the MNIST, CIFAR-10 and ImageNet datasets on multiple tasks: generalization from small training sets, corrupted labels, and robustness against adversarial perturbations. The resulting loss is general and complementary to existing data augmentation (such as random/adversarial input transform) and regularization techniques (such as weight decay, dropout, and batch norm).