 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeData Selection Effects on Self-Supervised Learning of Audio Representations for French Audiovisual Broadcasts
Apr 10, 2026Audio and speech self-supervised encoder models are now widely used for a lot of different tasks. Many of these models are often trained on clean segmented speech content such as LibriSpeech. In this paper, we look into how the pretraining datasets of such SSL (Self-Supervised Learning) models impact their downstream results. We build a large pretraining corpus of highly diverse TV and Radio broadcast audio content, which we describe with automatic tools. We use these annotations to build smaller subsets, which we use to train audio SSL models. Then, we evaluate the models on multiple downstream tasks such as automatic speech recognition, voice activity and music detection, or speaker recognition. The results show the potential of pretraining SSL models on diverse audio content without restricting it to speech. We also perform a membership inference attack to evaluate the encoder ability to memorize their training datasets, which highlight the importance of data deduplication. This unified training could bridge speech and music machine learning communities.
spINAch: A Diachronic Corpus of French Broadcast Speech Controlled for Speakers' Age and Gender
Mar 16, 2026We present spINAch, a large diachronic corpus of French speech from radio and television archives, balanced by speakers' gender, age (20-95 years old), and spanning 60 years from 1955 to 2015. The dataset includes over 320 hours of recordings from more than two thousand speakers. The methodology for building the corpus is described, focusing on the quality of collected samples in acoustic terms. The data were automatically transcribed and phonetically aligned to allow studies at a phonemic level. More than 3 million oral vowels have been analyzed to propose their fundamental frequency and formants. The corpus, available to the community for research purposes, is valuable for describing the evolution of Parisian French through the representation of gender and age. The presented analyses also demonstrate that the diachronic nature of the corpus allows the observation of various phonetic phenomena, such as the evolution of voice pitch over time (which does not differ by gender in our data) and the neutralization of the /a/-/$a$/ opposition in Parisian French during this period.
Pantagruel: Unified Self-Supervised Encoders for French Text and Speech
Jan 09, 2026We release Pantagruel models, a new family of self-supervised encoder models for French text and speech. Instead of predicting modality-tailored targets such as textual tokens or speech units, Pantagruel learns contextualized target representations in the feature space, allowing modality-specific encoders to capture linguistic and acoustic regularities more effectively. Separate models are pre-trained on large-scale French corpora, including Wikipedia, OSCAR and CroissantLLM for text, together with MultilingualLibriSpeech, LeBenchmark, and INA-100k for speech. INA-100k is a newly introduced 100,000-hour corpus of French audio derived from the archives of the Institut National de l'Audiovisuel (INA), the national repository of French radio and television broadcasts, providing highly diverse audio data. We evaluate Pantagruel across a broad range of downstream tasks spanning both modalities, including those from the standard French benchmarks such as FLUE or LeBenchmark. Across these tasks, Pantagruel models show competitive or superior performance compared to strong French baselines such as CamemBERT, FlauBERT, and LeBenchmark2.0, while maintaining a shared architecture that can seamlessly handle either speech or text inputs. These results confirm the effectiveness of feature-space self-supervised objectives for French representation learning and highlight Pantagruel as a robust foundation for multimodal speech-text understanding.
Automatic Classification of News Subjects in Broadcast News: Application to a Gender Bias Representation Analysis
Jul 19, 2024This paper introduces a computational framework designed to delineate gender distribution biases in topics covered by French TV and radio news. We transcribe a dataset of 11.7k hours, broadcasted in 2023 on 21 French channels. A Large Language Model (LLM) is used in few-shot conversation mode to obtain a topic classification on those transcriptions. Using the generated LLM annotations, we explore the finetuning of a specialized smaller classification model, to reduce the computational cost. To evaluate the performances of these models, we construct and annotate a dataset of 804 dialogues. This dataset is made available free of charge for research purposes. We show that women are notably underrepresented in subjects such as sports, politics and conflicts. Conversely, on topics such as weather, commercials and health, women have more speaking time than their overall average across all subjects. We also observe representations differences between private and public service channels.
Gender Representation in TV and Radio: Automatic Information Extraction methods versus Manual Analyses
Jun 14, 2024



This study investigates the relationship between automatic information extraction descriptors and manual analyses to describe gender representation disparities in TV and Radio. Automatic descriptors, including speech time, facial categorization and speech transcriptions are compared with channel reports on a vast 32,000-hour corpus of French broadcasts from 2023. Findings reveal systemic gender imbalances, with women underrepresented compared to men across all descriptors. Notably, manual channel reports show higher women's presence than automatic estimates and references to women are lower than their speech time. Descriptors share common dynamics during high and low audiences, war coverage, or private versus public channels. While women are more visible than audible in French TV, this trend is inverted in news with unseen journalists depicting male protagonists. A statistical test shows 3 main effects influencing references to women: program category, channel and speaker gender.
On the Use of Semantically-Aligned Speech Representations for Spoken Language Understanding
Oct 11, 2022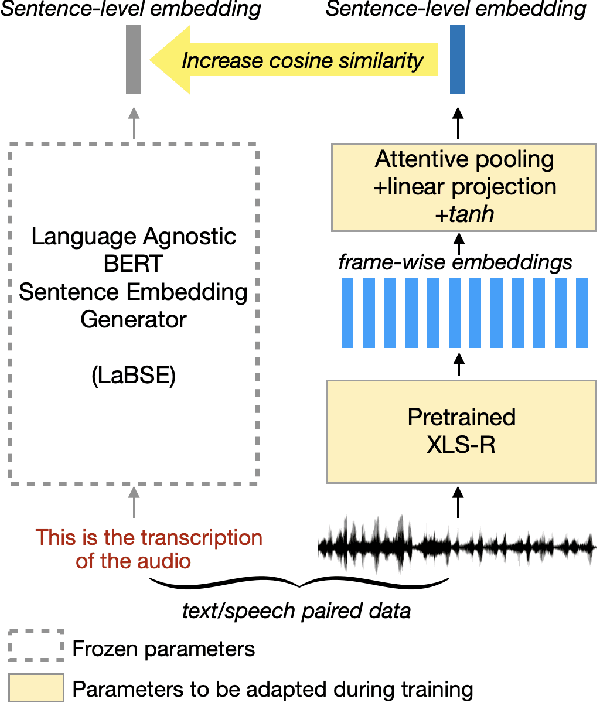
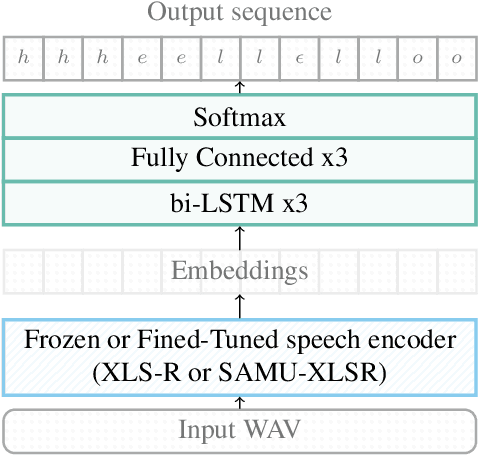
In this paper we examine the use of semantically-aligned speech representations for end-to-end spoken language understanding (SLU). We employ the recently-introduced SAMU-XLSR model, which is designed to generate a single embedding that captures the semantics at the utterance level, semantically aligned across different languages. This model combines the acoustic frame-level speech representation learning model (XLS-R) with the Language Agnostic BERT Sentence Embedding (LaBSE) model. We show that the use of the SAMU-XLSR model instead of the initial XLS-R model improves significantly the performance in the framework of end-to-end SLU. Finally, we present the benefits of using this model towards language portability in SLU.
ASR-Generated Text for Language Model Pre-training Applied to Speech Tasks
Jul 05, 2022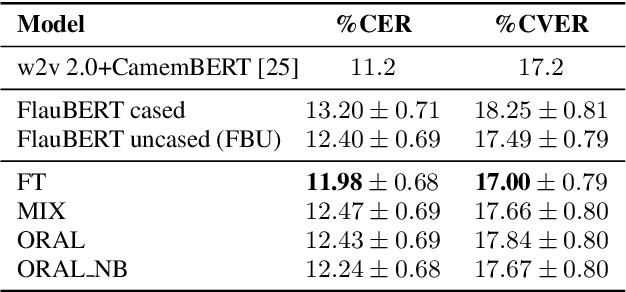
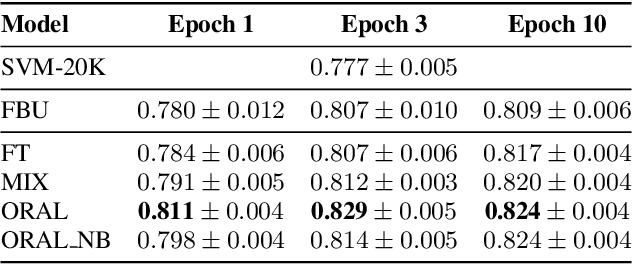
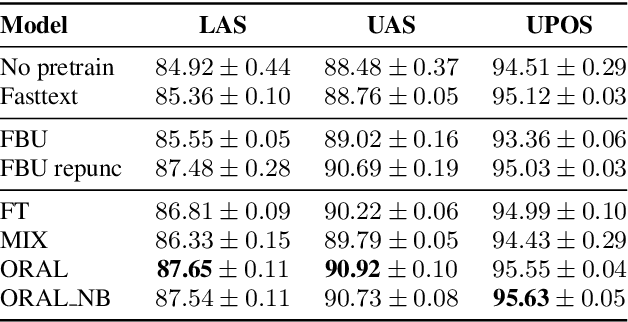
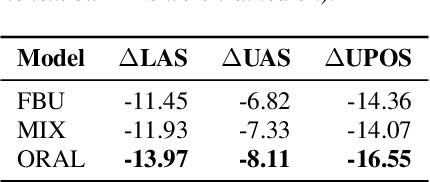
We aim at improving spoken language modeling (LM) using very large amount of automatically transcribed speech. We leverage the INA (French National Audiovisual Institute) collection and obtain 19GB of text after applying ASR on 350,000 hours of diverse TV shows. From this, spoken language models are trained either by fine-tuning an existing LM (FlauBERT) or through training a LM from scratch. New models (FlauBERT-Oral) are shared with the community and evaluated for 3 downstream tasks: spoken language understanding, classification of TV shows and speech syntactic parsing. Results show that FlauBERT-Oral can be beneficial compared to its initial FlauBERT version demonstrating that, despite its inherent noisy nature, ASR-generated text can be used to build spoken language models.
End2End Acoustic to Semantic Transduction
Feb 01, 2021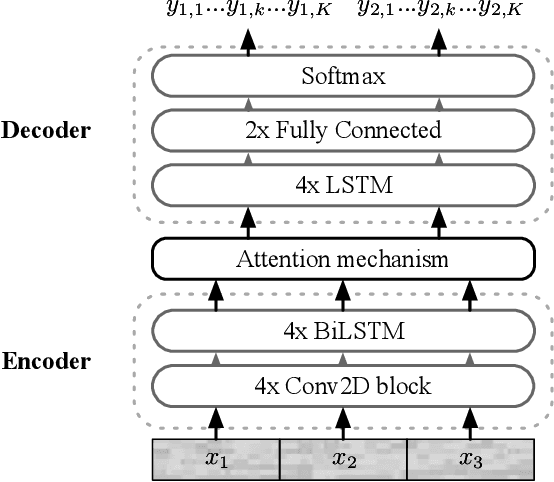

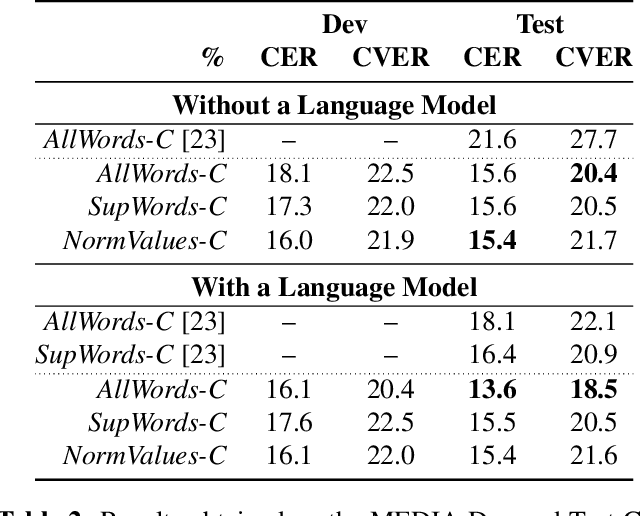
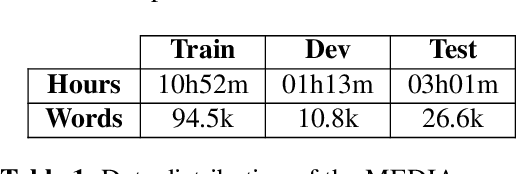
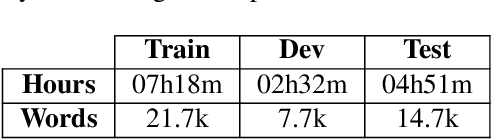
In this paper, we propose a novel end-to-end sequence-to-sequence spoken language understanding model using an attention mechanism. It reliably selects contextual acoustic features in order to hypothesize semantic contents. An initial architecture capable of extracting all pronounced words and concepts from acoustic spans is designed and tested. With a shallow fusion language model, this system reaches a 13.6 concept error rate (CER) and an 18.5 concept value error rate (CVER) on the French MEDIA corpus, achieving an absolute 2.8 points reduction compared to the state-of-the-art. Then, an original model is proposed for hypothesizing concepts and their values. This transduction reaches a 15.4 CER and a 21.6 CVER without any new type of context.