 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Artificial Intelligence Assistance for Safe Laparoscopic Cholecystectomy: Early-Stage Clinical Evaluation
Dec 13, 2022
Artificial intelligence is set to be deployed in operating rooms to improve surgical care. This early-stage clinical evaluation shows the feasibility of concurrently attaining real-time, high-quality predictions from several deep neural networks for endoscopic video analysis deployed for assistance during three laparoscopic cholecystectomies.
Latent Graph Representations for Critical View of Safety Assessment
Dec 08, 2022



Assessing the critical view of safety in laparoscopic cholecystectomy requires accurate identification and localization of key anatomical structures, reasoning about their geometric relationships to one another, and determining the quality of their exposure. In this work, we propose to capture each of these aspects by modeling the surgical scene with a disentangled latent scene graph representation, which we can then process using a graph neural network. Unlike previous approaches using graph representations, we explicitly encode in our graphs semantic information such as object locations and shapes, class probabilities and visual features. We also incorporate an auxiliary image reconstruction objective to help train the latent graph representations. We demonstrate the value of these components through comprehensive ablation studies and achieve state-of-the-art results for critical view of safety prediction across multiple experimental settings.
Rendezvous in Time: An Attention-based Temporal Fusion approach for Surgical Triplet Recognition
Nov 30, 2022One of the recent advances in surgical AI is the recognition of surgical activities as triplets of (instrument, verb, target). Albeit providing detailed information for computer-assisted intervention, current triplet recognition approaches rely only on single frame features. Exploiting the temporal cues from earlier frames would improve the recognition of surgical action triplets from videos. In this paper, we propose Rendezvous in Time (RiT) - a deep learning model that extends the state-of-the-art model, Rendezvous, with temporal modeling. Focusing more on the verbs, our RiT explores the connectedness of current and past frames to learn temporal attention-based features for enhanced triplet recognition. We validate our proposal on the challenging surgical triplet dataset, CholecT45, demonstrating an improved recognition of the verb and triplet along with other interactions involving the verb such as (instrument, verb). Qualitative results show that the RiT produces smoother predictions for most triplet instances than the state-of-the-arts. We present a novel attention-based approach that leverages the temporal fusion of video frames to model the evolution of surgical actions and exploit their benefits for surgical triplet recognition.
CholecTriplet2021: A benchmark challenge for surgical action triplet recognition
Apr 10, 2022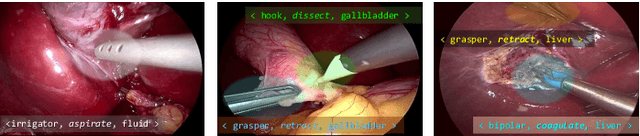

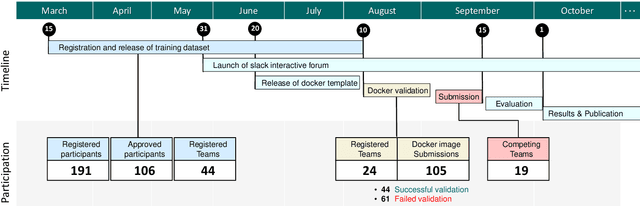
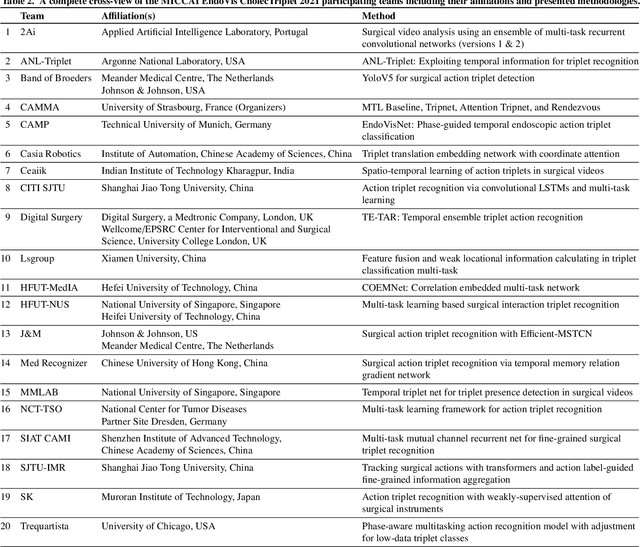
Context-aware decision support in the operating room can foster surgical safety and efficiency by leveraging real-time feedback from surgical workflow analysis. Most existing works recognize surgical activities at a coarse-grained level, such as phases, steps or events, leaving out fine-grained interaction details about the surgical activity; yet those are needed for more helpful AI assistance in the operating room. Recognizing surgical actions as triplets of <instrument, verb, target> combination delivers comprehensive details about the activities taking place in surgical videos. This paper presents CholecTriplet2021: an endoscopic vision challenge organized at MICCAI 2021 for the recognition of surgical action triplets in laparoscopic videos. The challenge granted private access to the large-scale CholecT50 dataset, which is annotated with action triplet information. In this paper, we present the challenge setup and assessment of the state-of-the-art deep learning methods proposed by the participants during the challenge. A total of 4 baseline methods from the challenge organizers and 19 new deep learning algorithms by competing teams are presented to recognize surgical action triplets directly from surgical videos, achieving mean average precision (mAP) ranging from 4.2% to 38.1%. This study also analyzes the significance of the results obtained by the presented approaches, performs a thorough methodological comparison between them, in-depth result analysis, and proposes a novel ensemble method for enhanced recognition. Our analysis shows that surgical workflow analysis is not yet solved, and also highlights interesting directions for future research on fine-grained surgical activity recognition which is of utmost importance for the development of AI in surgery.
Live Laparoscopic Video Retrieval with Compressed Uncertainty
Mar 08, 2022Searching through large volumes of medical data to retrieve relevant information is a challenging yet crucial task for clinical care. However the primitive and most common approach to retrieval, involving text in the form of keywords, is severely limited when dealing with complex media formats. Content-based retrieval offers a way to overcome this limitation, by using rich media as the query itself. Surgical video-to-video retrieval in particular is a new and largely unexplored research problem with high clinical value, especially in the real-time case: using real-time video hashing, search can be achieved directly inside of the operating room. Indeed, the process of hashing converts large data entries into compact binary arrays or hashes, enabling large-scale search operations at a very fast rate. However, due to fluctuations over the course of a video, not all bits in a given hash are equally reliable. In this work, we propose a method capable of mitigating this uncertainty while maintaining a light computational footprint. We present superior retrieval results (3-4 % top 10 mean average precision) on a multi-task evaluation protocol for surgery, using cholecystectomy phases, bypass phases, and coming from an entirely new dataset introduced here, critical events across six different surgery types. Success on this multi-task benchmark shows the generalizability of our approach for surgical video retrieval.
Temporally Constrained Neural Networks (TCNN): A framework for semi-supervised video semantic segmentation
Dec 27, 2021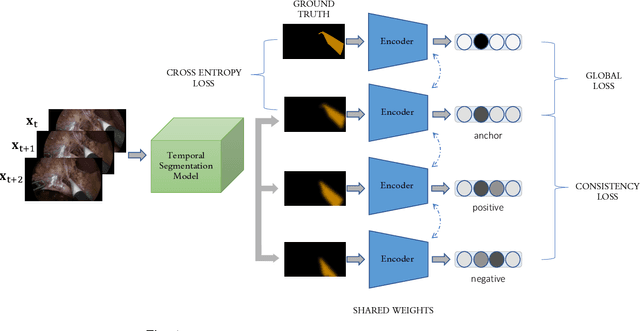
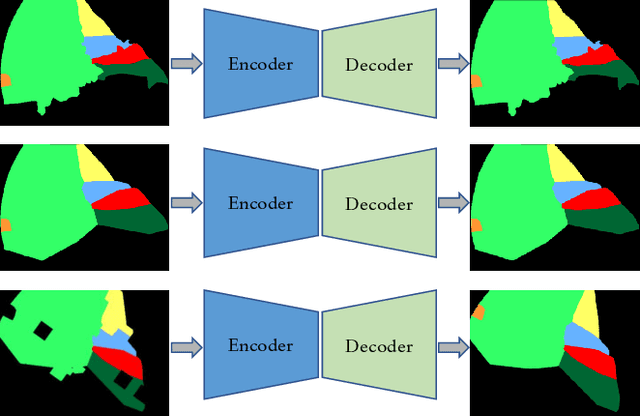
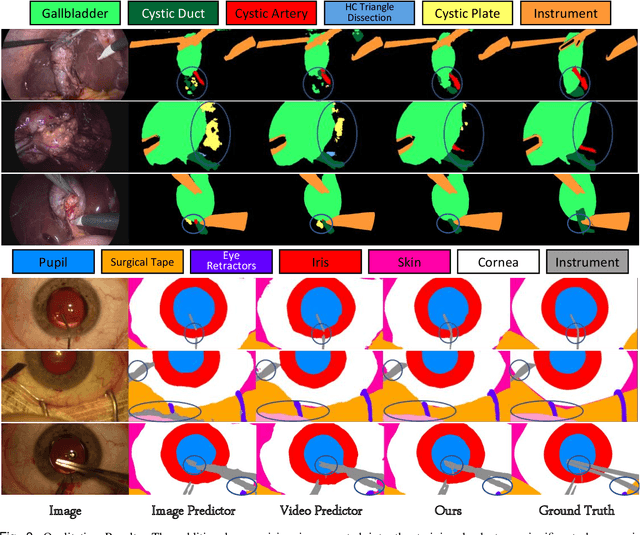
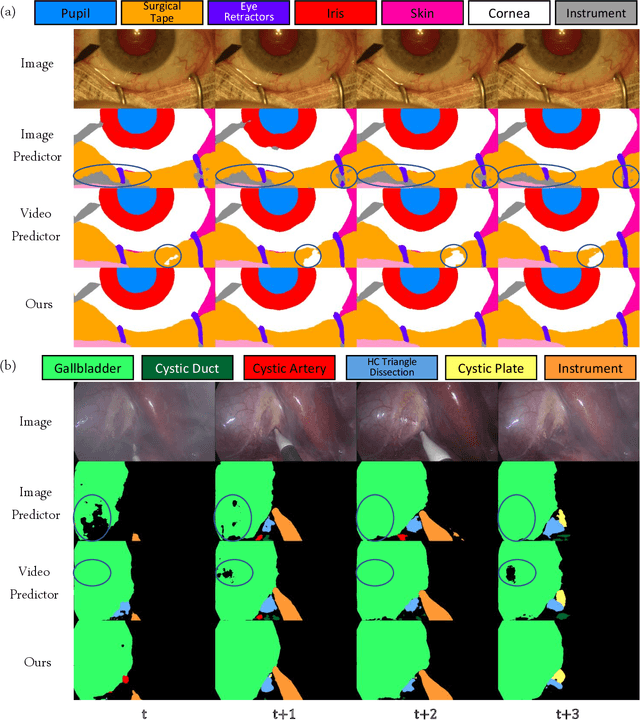
A major obstacle to building models for effective semantic segmentation, and particularly video semantic segmentation, is a lack of large and well annotated datasets. This bottleneck is particularly prohibitive in highly specialized and regulated fields such as medicine and surgery, where video semantic segmentation could have important applications but data and expert annotations are scarce. In these settings, temporal clues and anatomical constraints could be leveraged during training to improve performance. Here, we present Temporally Constrained Neural Networks (TCNN), a semi-supervised framework used for video semantic segmentation of surgical videos. In this work, we show that autoencoder networks can be used to efficiently provide both spatial and temporal supervisory signals to train deep learning models. We test our method on a newly introduced video dataset of laparoscopic cholecystectomy procedures, Endoscapes, and an adaptation of a public dataset of cataract surgeries, CaDIS. We demonstrate that lower-dimensional representations of predicted masks can be leveraged to provide a consistent improvement on both sparsely labeled datasets with no additional computational cost at inference time. Further, the TCNN framework is model-agnostic and can be used in conjunction with other model design choices with minimal additional complexity.
Rendezvous: Attention Mechanisms for the Recognition of Surgical Action Triplets in Endoscopic Videos
Sep 07, 2021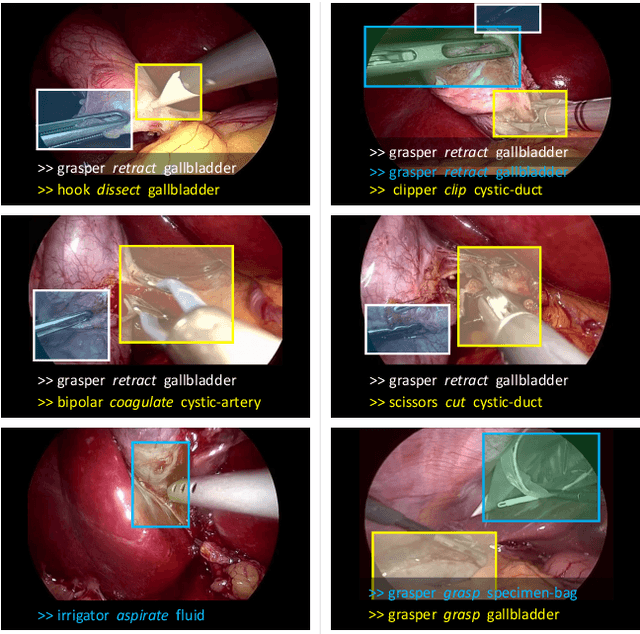
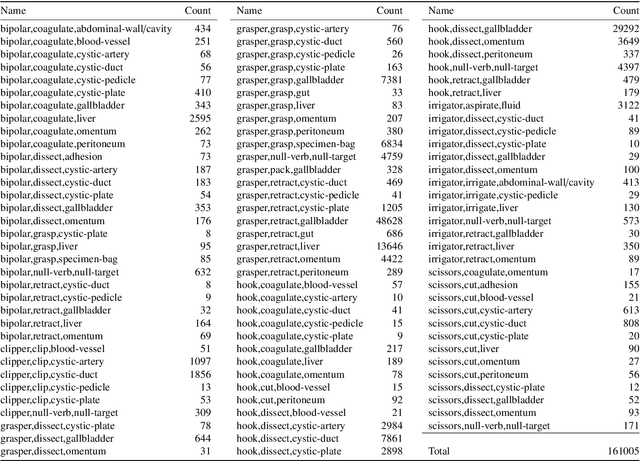
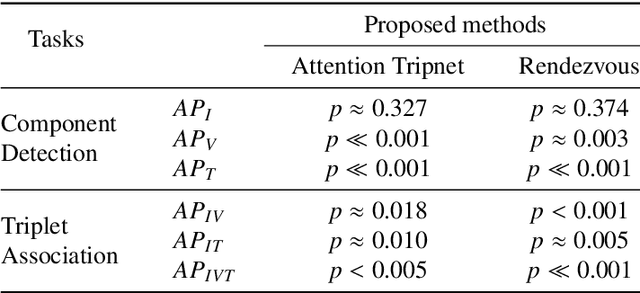
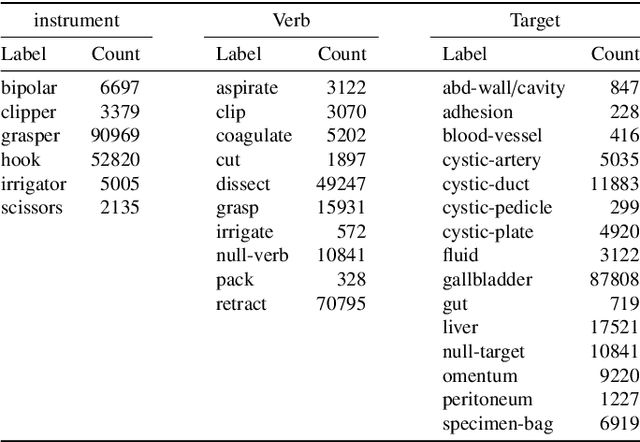
Out of all existing frameworks for surgical workflow analysis in endoscopic videos, action triplet recognition stands out as the only one aiming to provide truly fine-grained and comprehensive information on surgical activities. This information, presented as <instrument, verb, target> combinations, is highly challenging to be accurately identified. Triplet components can be difficult to recognize individually; in this task, it requires not only performing recognition simultaneously for all three triplet components, but also correctly establishing the data association between them. To achieve this task, we introduce our new model, the Rendezvous (RDV), which recognizes triplets directly from surgical videos by leveraging attention at two different levels. We first introduce a new form of spatial attention to capture individual action triplet components in a scene; called the Class Activation Guided Attention Mechanism (CAGAM). This technique focuses on the recognition of verbs and targets using activations resulting from instruments. To solve the association problem, our RDV model adds a new form of semantic attention inspired by Transformer networks. Using multiple heads of cross and self attentions, RDV is able to effectively capture relationships between instruments, verbs, and targets. We also introduce CholecT50 - a dataset of 50 endoscopic videos in which every frame has been annotated with labels from 100 triplet classes. Our proposed RDV model significantly improves the triplet prediction mAP by over 9% compared to the state-of-the-art methods on this dataset.
Multi-Task Temporal Convolutional Networks for Joint Recognition of Surgical Phases and Steps in Gastric Bypass Procedures
Feb 24, 2021
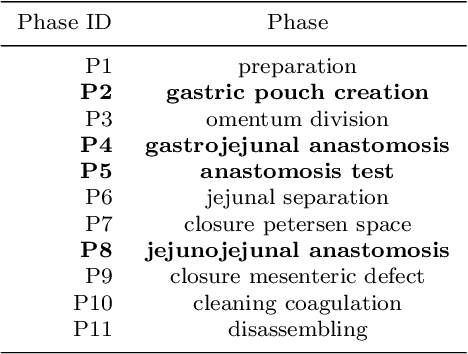
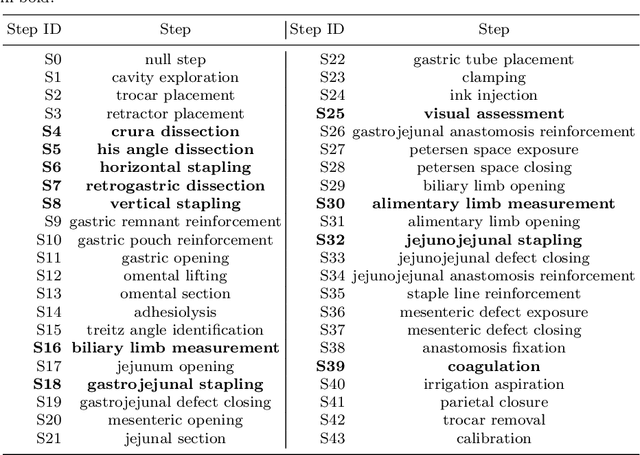
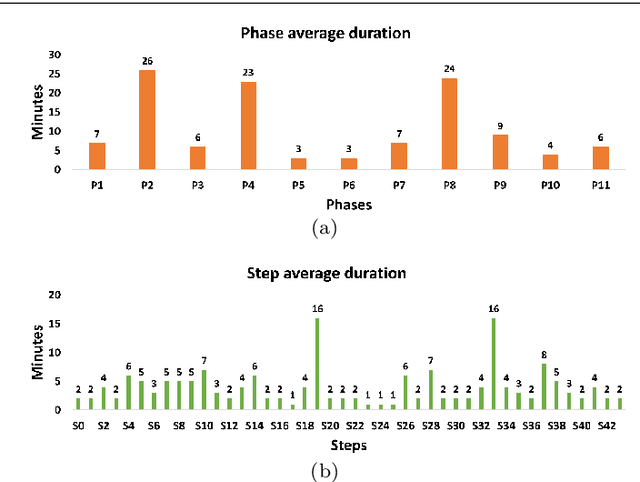
Purpose: Automatic segmentation and classification of surgical activity is crucial for providing advanced support in computer-assisted interventions and autonomous functionalities in robot-assisted surgeries. Prior works have focused on recognizing either coarse activities, such as phases, or fine-grained activities, such as gestures. This work aims at jointly recognizing two complementary levels of granularity directly from videos, namely phases and steps. Method: We introduce two correlated surgical activities, phases and steps, for the laparoscopic gastric bypass procedure. We propose a Multi-task Multi-Stage Temporal Convolutional Network (MTMS-TCN) along with a multi-task Convolutional Neural Network (CNN) training setup to jointly predict the phases and steps and benefit from their complementarity to better evaluate the execution of the procedure. We evaluate the proposed method on a large video dataset consisting of 40 surgical procedures (Bypass40). Results: We present experimental results from several baseline models for both phase and step recognition on the Bypass40 dataset. The proposed MTMS-TCN method outperforms in both phase and step recognition by 1-2% in accuracy, precision and recall, compared to single-task methods. Furthermore, for step recognition, MTMS-TCN achieves a superior performance of 3-6% compared to LSTM based models in accuracy, precision, and recall. Conclusion: In this work, we present a multi-task multi-stage temporal convolutional network for surgical activity recognition, which shows improved results compared to single-task models on the Bypass40 gastric bypass dataset with multi-level annotations. The proposed method shows that the joint modeling of phases and steps is beneficial to improve the overall recognition of each type of activity.
Recognition of Instrument-Tissue Interactions in Endoscopic Videos via Action Triplets
Jul 10, 2020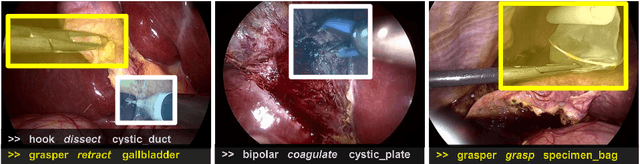
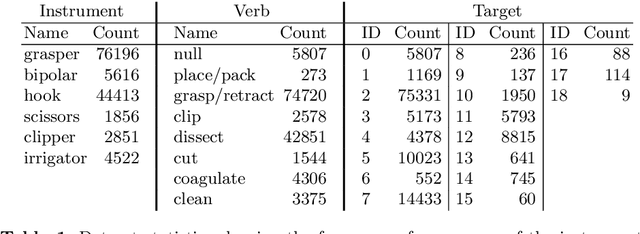
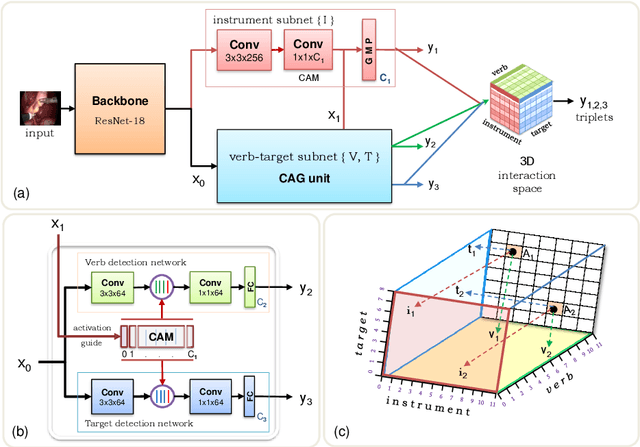
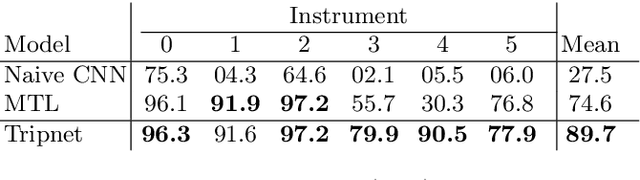
Recognition of surgical activity is an essential component to develop context-aware decision support for the operating room. In this work, we tackle the recognition of fine-grained activities, modeled as action triplets <instrument, verb, target> representing the tool activity. To this end, we introduce a new laparoscopic dataset, CholecT40, consisting of 40 videos from the public dataset Cholec80 in which all frames have been annotated using 128 triplet classes. Furthermore, we present an approach to recognize these triplets directly from the video data. It relies on a module called Class Activation Guide (CAG), which uses the instrument activation maps to guide the verb and target recognition. To model the recognition of multiple triplets in the same frame, we also propose a trainable 3D Interaction Space, which captures the associations between the triplet components. Finally, we demonstrate the significance of these contributions via several ablation studies and comparisons to baselines on CholecT40.
Weakly Supervised Convolutional LSTM Approach for Tool Tracking in Laparoscopic Videos
Dec 04, 2018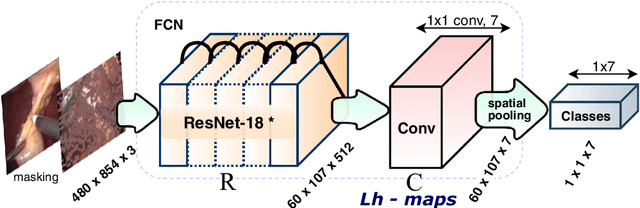
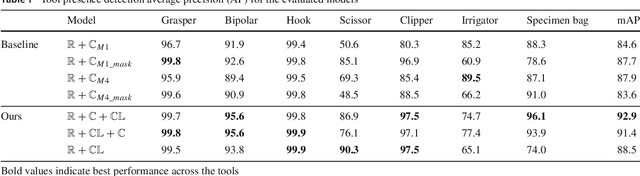
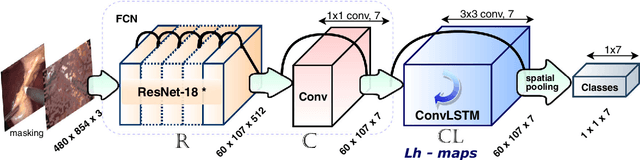
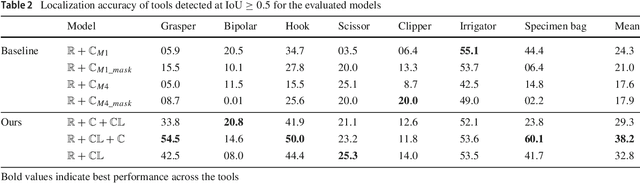
Purpose: Real-time surgical tool tracking is a core component of the future intelligent operating room (OR), because it is highly instrumental to analyze and understand the surgical activities. Current methods for surgical tool tracking in videos need to be trained on data in which the spatial position of the tools is manually annotated. Generating such training data is difficult and time-consuming. Instead, we propose to use solely binary presence annotations to train a tool tracker for laparoscopic videos. Methods: The proposed approach is composed of a CNN + Convolutional LSTM (ConvLSTM) neural network trained end-to-end, but weakly supervised on tool binary presence labels only. We use the ConvLSTM to model the temporal dependencies in the motion of the surgical tools and leverage its spatio-temporal ability to smooth the class peak activations in the localization heat maps (Lh-maps). Results: We build a baseline tracker on top of the CNN model and demonstrate that our approach based on the ConvLSTM outperforms the baseline in tool presence detection, spatial localization, and motion tracking by over 5.0%, 13.9%, and 12.6%, respectively. Conclusions: In this paper, we demonstrate that binary presence labels are sufficient for training a deep learning tracking model using our proposed method. We also show that the ConvLSTM can leverage the spatio-temporal coherence of consecutive image frames across a surgical video to improve tool presence detection, spatial localization, and motion tracking.