 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre we pretraining it right? Digging deeper into visio-linguistic pretraining
Apr 19, 2020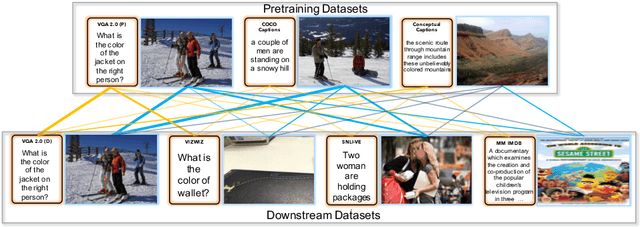
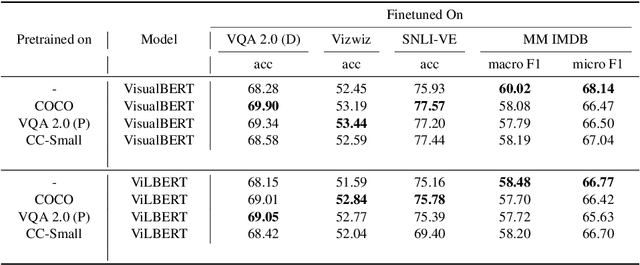
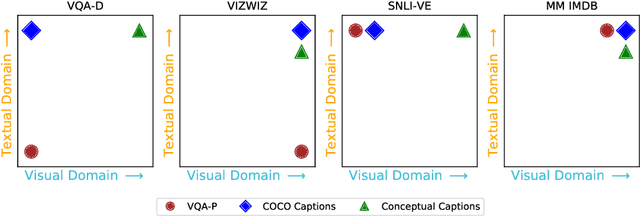
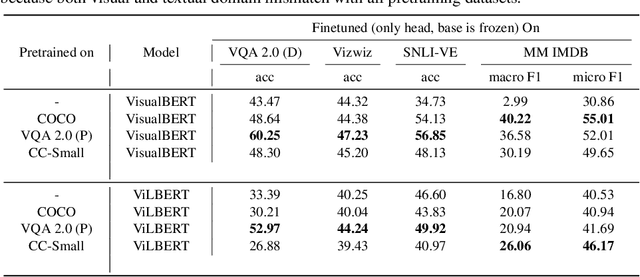
Numerous recent works have proposed pretraining generic visio-linguistic representations and then finetuning them for downstream vision and language tasks. While architecture and objective function design choices have received attention, the choice of pretraining datasets has received little attention. In this work, we question some of the default choices made in literature. For instance, we systematically study how varying similarity between the pretraining dataset domain (textual and visual) and the downstream domain affects performance. Surprisingly, we show that automatically generated data in a domain closer to the downstream task (e.g., VQA v2) is a better choice for pretraining than "natural" data but of a slightly different domain (e.g., Conceptual Captions). On the other hand, some seemingly reasonable choices of pretraining datasets were found to be entirely ineffective for some downstream tasks. This suggests that despite the numerous recent efforts, vision & language pretraining does not quite work "out of the box" yet. Overall, as a by-product of our study, we find that simple design choices in pretraining can help us achieve close to state-of-art results on downstream tasks without any architectural changes.
Predicting A Creator's Preferences In, and From, Interactive Generative Art
Mar 03, 2020

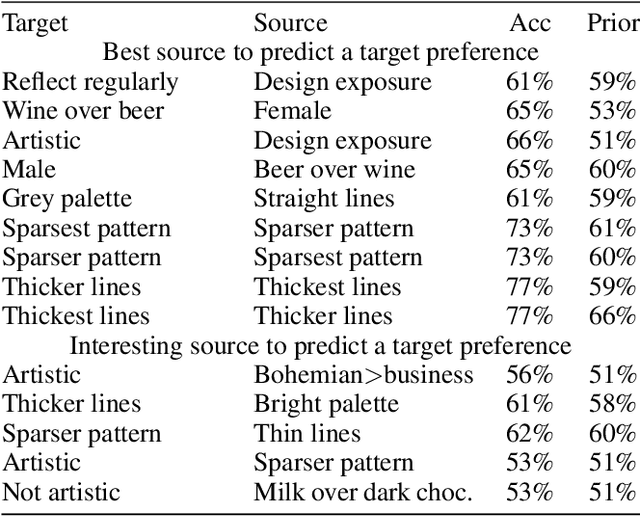
As a lay user creates an art piece using an interactive generative art tool, what, if anything, do the choices they make tell us about them and their preferences? These preferences could be in the specific generative art form (e.g., color palettes, density of the piece, thickness or curvatures of any lines in the piece); predicting them could lead to a smarter interactive tool. Or they could be preferences in other walks of life (e.g., music, fashion, food, interior design, paintings) or attributes of the person (e.g., personality type, gender, artistic inclinations); predicting them could lead to improved personalized recommendations for products or experiences. To study this research question, we collect preferences from 311 subjects, both in a specific generative art form and in other walks of life. We analyze the preferences and train machine learning models to predict a subset of preferences from the remaining. We find that preferences in the generative art form we studied cannot predict preferences in other walks of life better than chance (and vice versa). However, preferences within the generative art form are reliably predictive of each other.
SQuINTing at VQA Models: Interrogating VQA Models with Sub-Questions
Jan 20, 2020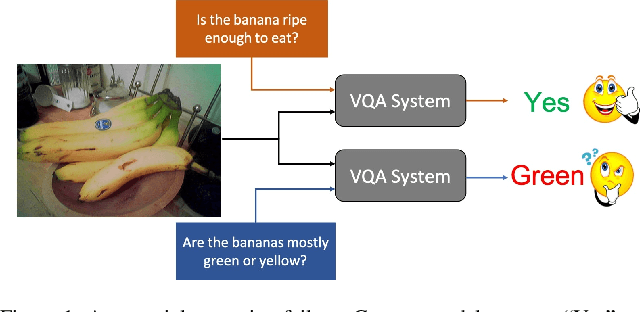

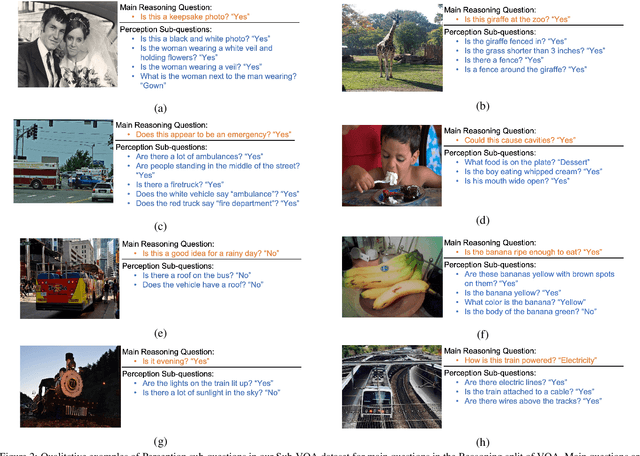
Existing VQA datasets contain questions with varying levels of complexity. While the majority of questions in these datasets require perception for recognizing existence, properties, and spatial relationships of entities, a significant portion of questions pose challenges that correspond to reasoning tasks -- tasks that can only be answered through a synthesis of perception and knowledge about the world, logic and / or reasoning. This distinction allows us to notice when existing VQA models have consistency issues -- they answer the reasoning question correctly but fail on associated low-level perception questions. For example, models answer the complex reasoning question "Is the banana ripe enough to eat?" correctly, but fail on the associated perception question "Are the bananas mostly green or yellow?" indicating that the model likely answered the reasoning question correctly but for the wrong reason. We quantify the extent to which this phenomenon occurs by creating a new Reasoning split of the VQA dataset and collecting Sub-VQA, a new dataset consisting of 200K new perception questions which serve as sub questions corresponding to the set of perceptual tasks needed to effectively answer the complex reasoning questions in the Reasoning split. Additionally, we propose an approach called Sub-Question Importance-aware Network Tuning (SQuINT), which encourages the model to attend do the same parts of the image when answering the reasoning question and the perception sub questions. We show that SQuINT improves model consistency by 7.8%, also marginally improving its performance on the Reasoning questions in VQA, while also displaying qualitatively better attention maps.
Large-scale Pretraining for Visual Dialog: A Simple State-of-the-Art Baseline
Dec 05, 2019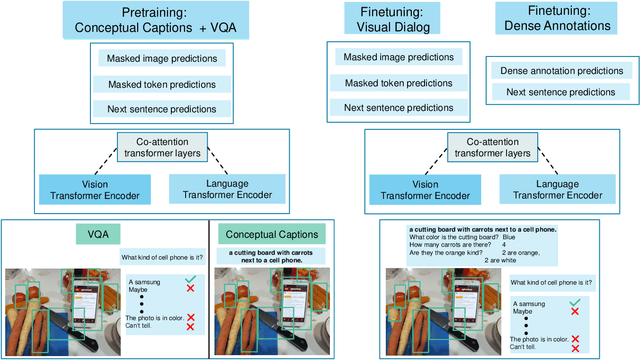

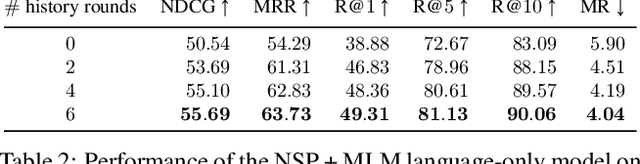
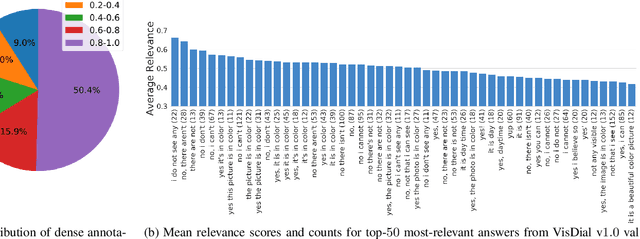
Prior work in visual dialog has focused on training deep neural models on the VisDial dataset in isolation, which has led to great progress, but is limiting and wasteful. In this work, following recent trends in representation learning for language, we introduce an approach to leverage pretraining on related large-scale vision-language datasets before transferring to visual dialog. Specifically, we adapt the recently proposed ViLBERT (Lu et al., 2019) model for multi-turn visually-grounded conversation sequences. Our model is pretrained on the Conceptual Captions and Visual Question Answering datasets, and finetuned on VisDial with a VisDial-specific input representation and the masked language modeling and next sentence prediction objectives (as in BERT). Our best single model achieves state-of-the-art on Visual Dialog, outperforming prior published work (including model ensembles) by more than 1% absolute on NDCG and MRR. Next, we carefully analyse our model and find that additional finetuning using 'dense' annotations i.e. relevance scores for all 100 answer options corresponding to each question on a subset of the training set, leads to even higher NDCG -- more than 10% over our base model -- but hurts MRR -- more than 17% below our base model! This highlights a stark trade-off between the two primary metrics for this task -- NDCG and MRR. We find that this is because dense annotations in the dataset do not correlate well with the original ground-truth answers to questions, often rewarding the model for generic responses (e.g. "can't tell").
12-in-1: Multi-Task Vision and Language Representation Learning
Dec 05, 2019
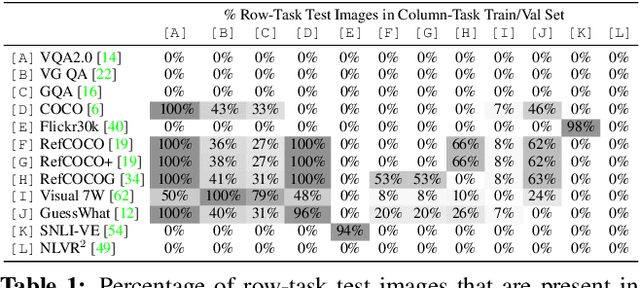
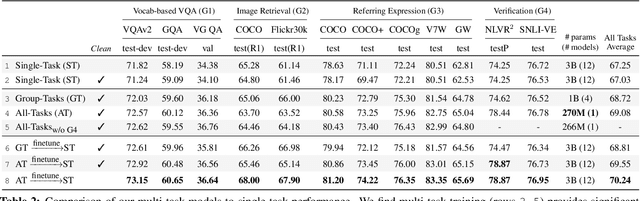
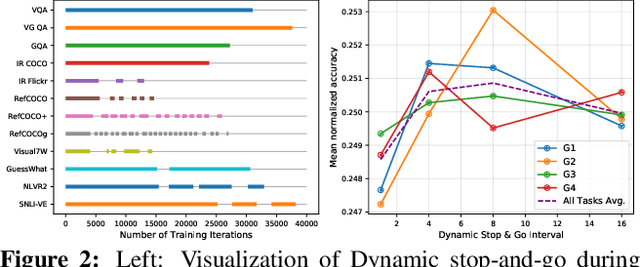
Much of vision-and-language research focuses on a small but diverse set of independent tasks and supporting datasets often studied in isolation; however, the visually-grounded language understanding skills required for success at these tasks overlap significantly. In this work, we investigate these relationships between vision-and-language tasks by developing a large-scale, multi-task training regime. Our approach culminates in a single model on 12 datasets from four broad categories of task including visual question answering, caption-based image retrieval, grounding referring expressions, and multi-modal verification. Compared to independently trained single-task models, this represents a reduction from approximately 3 billion parameters to 270 million while simultaneously improving performance by 2.05 points on average across tasks. We use our multi-task framework to perform in-depth analysis of the effect of joint training diverse tasks. Further, we show that finetuning task-specific models from our single multi-task model can lead to further improvements, achieving performance at or above the state-of-the-art.
Decentralized Distributed PPO: Solving PointGoal Navigation
Nov 01, 2019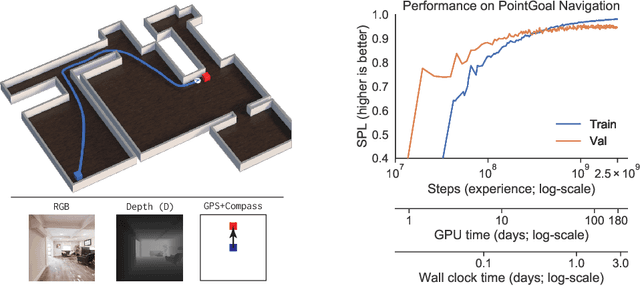

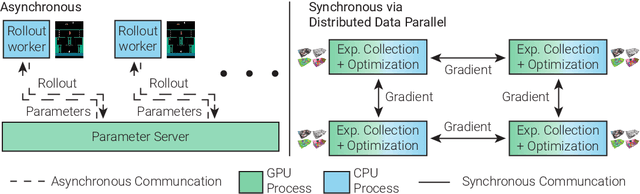
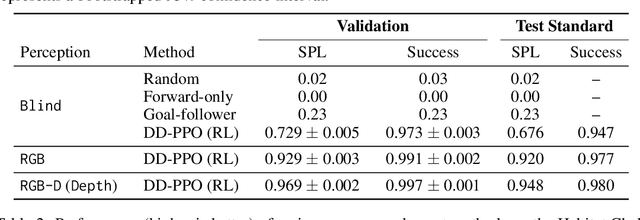
We present Decentralized Distributed Proximal Policy Optimization (DD-PPO), a method for distributed reinforcement learning in resource-intensive simulated environments. DD-PPO is distributed (uses multiple machines), decentralized (lacks a centralized server), and synchronous (no computation is ever "stale"), making it conceptually simple and easy to implement. In our experiments on training virtual robots to navigate in Habitat-Sim, DD-PPO exhibits near-linear scaling -- achieving a speedup of 107x on 128 GPUs over a serial implementation. We leverage this scaling to train an agent for 2.5 Billion steps of experience (the equivalent of 80 years of human experience) -- over 6 months of GPU-time training in under 3 days of wall-clock time with 64 GPUs. This massive-scale training not only sets the state of art on Habitat Autonomous Navigation Challenge 2019, but essentially "solves" the task -- near-perfect autonomous navigation in an unseen environment without access to a map, directly from an RGB-D camera and a GPS+Compass sensor. Fortuitously, error vs computation exhibits a power-law-like distribution; thus, 90% of peak performance is obtained relatively early (at 100 million steps) and relatively cheaply (under 1 day with 8 GPUs). Finally, we show that the scene understanding and navigation policies learned can be transferred to other navigation tasks -- the analog of "ImageNet pre-training + task-specific fine-tuning" for embodied AI. Our model outperforms ImageNet pre-trained CNNs on these transfer tasks and can serve as a universal resource (all models + code will be publicly available).
Improving Generative Visual Dialog by Answering Diverse Questions
Oct 03, 2019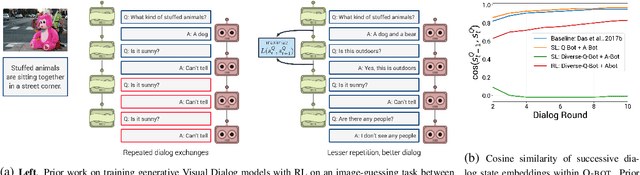

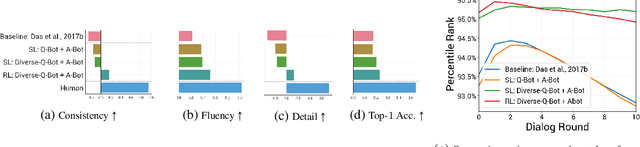

Prior work on training generative Visual Dialog models with reinforcement learning(Das et al.) has explored a Qbot-Abot image-guessing game and shown that this 'self-talk' approach can lead to improved performance at the downstream dialog-conditioned image-guessing task. However, this improvement saturates and starts degrading after a few rounds of interaction, and does not lead to a better Visual Dialog model. We find that this is due in part to repeated interactions between Qbot and Abot during self-talk, which are not informative with respect to the image. To improve this, we devise a simple auxiliary objective that incentivizes Qbot to ask diverse questions, thus reducing repetitions and in turn enabling Abot to explore a larger state space during RL ie. be exposed to more visual concepts to talk about, and varied questions to answer. We evaluate our approach via a host of automatic metrics and human studies, and demonstrate that it leads to better dialog, ie. dialog that is more diverse (ie. less repetitive), consistent (ie. has fewer conflicting exchanges), fluent (ie. more human-like),and detailed, while still being comparably image-relevant as prior work and ablations.
Unsupervised Discovery of Decision States for Transfer in Reinforcement Learning
Aug 15, 2019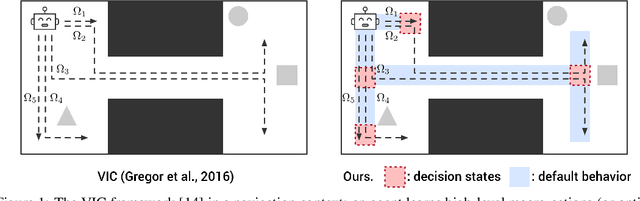
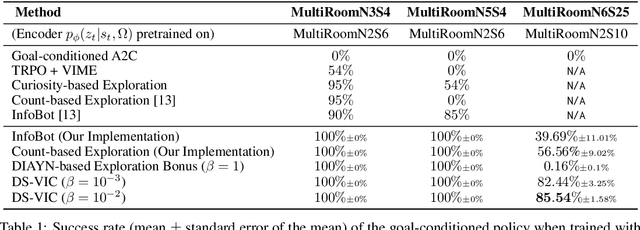
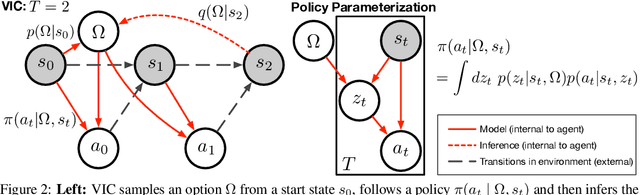
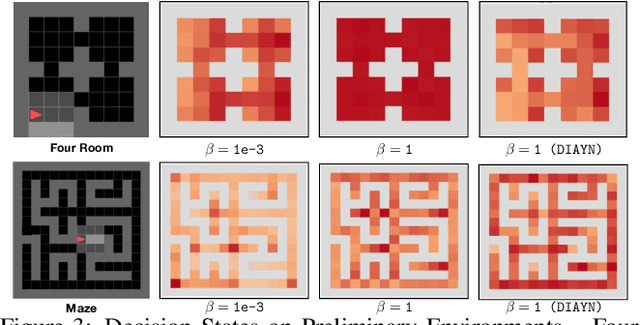
We present a hierarchical reinforcement learning (HRL) or options framework for identifying decision states. Informally speaking, these are states considered important by the agent's policy e.g. , for navigation, decision states would be crossroads or doors where an agent needs to make strategic decisions. While previous work (most notably Goyal et. al., 2019) discovers decision states in a task/goal specific (or 'supervised') manner, we do so in a goal-independent (or 'unsupervised') manner, i.e. entirely without any goal or extrinsic rewards. Our approach combines two hitherto disparate ideas - 1) \emph{intrinsic control} (Gregor et. al., 2016, Eysenbach et. al., 2018): learning a set of options that allow an agent to reliably reach a diverse set of states, and 2) \emph{information bottleneck} (Tishby et. al., 2000): penalizing mutual information between the option $\Omega$ and the states $s_t$ visited in the trajectory. The former encourages an agent to reliably explore the environment; the latter allows identification of decision states as the ones with high mutual information $I(\Omega; a_t | s_t)$ despite the bottleneck. Our results demonstrate that 1) our model learns interpretable decision states in an unsupervised manner, and 2) these learned decision states transfer to goal-driven tasks in new environments, effectively guide exploration, and improve performance.
ViLBERT: Pretraining Task-Agnostic Visiolinguistic Representations for Vision-and-Language Tasks
Aug 06, 2019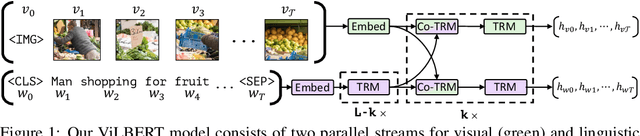
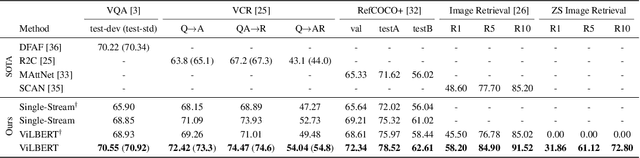
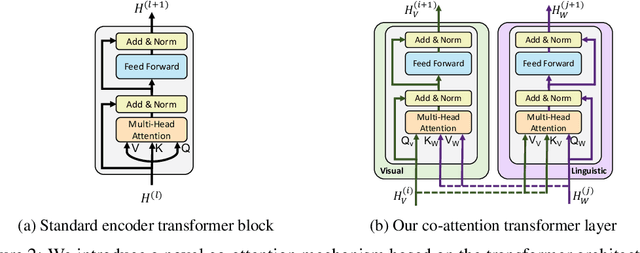

We present ViLBERT (short for Vision-and-Language BERT), a model for learning task-agnostic joint representations of image content and natural language. We extend the popular BERT architecture to a multi-modal two-stream model, pro-cessing both visual and textual inputs in separate streams that interact through co-attentional transformer layers. We pretrain our model through two proxy tasks on the large, automatically collected Conceptual Captions dataset and then transfer it to multiple established vision-and-language tasks -- visual question answering, visual commonsense reasoning, referring expressions, and caption-based image retrieval -- by making only minor additions to the base architecture. We observe significant improvements across tasks compared to existing task-specific models -- achieving state-of-the-art on all four tasks. Our work represents a shift away from learning groundings between vision and language only as part of task training and towards treating visual grounding as a pretrainable and transferable capability.
Chasing Ghosts: Instruction Following as Bayesian State Tracking
Jul 03, 2019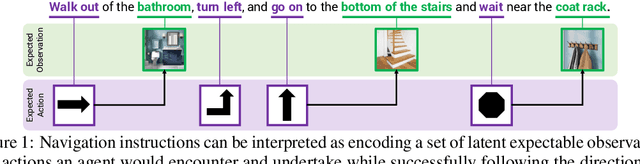
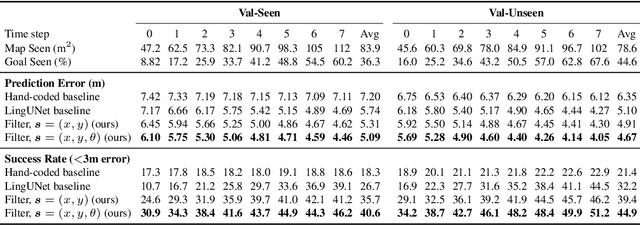
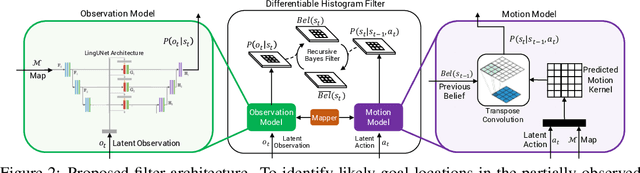
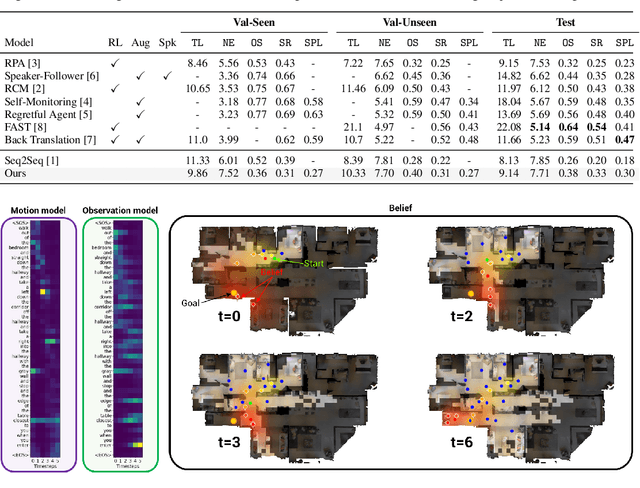
A visually-grounded navigation instruction can be interpreted as a sequence of expected observations and actions an agent following the correct trajectory would encounter and perform. Based on this intuition, we formulate the problem of finding the goal location in Vision-And-Language Navigation (VLN) within the framework of Bayesian state tracking - learning observation and motion models conditioned on these expectable events. Together with a mapper that constructs a semantic spatial map on-the-fly during navigation, we formulate an end-to-end differentiable Bayes filter and train it to identify the goal by predicting the most likely trajectory through the map according to the instructions. The resulting navigation policy constitutes a new approach to instruction following that explicitly models a probability distribution over states, encoding strong geometric and algorithmic priors while enabling greater explainability. Our experiments show that our approach outperforms strong baselines when predicting the goal location in VLN.