 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeedy MASt3R
Mar 13, 2025Image matching is a key component of modern 3D vision algorithms, essential for accurate scene reconstruction and localization. MASt3R redefines image matching as a 3D task by leveraging DUSt3R and introducing a fast reciprocal matching scheme that accelerates matching by orders of magnitude while preserving theoretical guarantees. This approach has gained strong traction, with DUSt3R and MASt3R collectively cited over 250 times in a short span, underscoring their impact. However, despite its accuracy, MASt3R's inference speed remains a bottleneck. On an A40 GPU, latency per image pair is 198.16 ms, mainly due to computational overhead from the ViT encoder-decoder and Fast Reciprocal Nearest Neighbor (FastNN) matching. To address this, we introduce Speedy MASt3R, a post-training optimization framework that enhances inference efficiency while maintaining accuracy. It integrates multiple optimization techniques, including FlashMatch-an approach leveraging FlashAttention v2 with tiling strategies for improved efficiency, computation graph optimization via layer and tensor fusion having kernel auto-tuning with TensorRT (GraphFusion), and a streamlined FastNN pipeline that reduces memory access time from quadratic to linear while accelerating block-wise correlation scoring through vectorized computation (FastNN-Lite). Additionally, it employs mixed-precision inference with FP16/FP32 hybrid computations (HybridCast), achieving speedup while preserving numerical precision. Evaluated on Aachen Day-Night, InLoc, 7-Scenes, ScanNet1500, and MegaDepth1500, Speedy MASt3R achieves a 54% reduction in inference time (198 ms to 91 ms per image pair) without sacrificing accuracy. This advancement enables real-time 3D understanding, benefiting applications like mixed reality navigation and large-scale 3D scene reconstruction.
Hamming Attention Distillation: Binarizing Keys and Queries for Efficient Long-Context Transformers
Feb 03, 2025



Pre-trained transformer models with extended context windows are notoriously expensive to run at scale, often limiting real-world deployment due to their high computational and memory requirements. In this paper, we introduce Hamming Attention Distillation (HAD), a novel framework that binarizes keys and queries in the attention mechanism to achieve significant efficiency gains. By converting keys and queries into {-1, +1} vectors and replacing dot-product operations with efficient Hamming distance computations, our method drastically reduces computational overhead. Additionally, we incorporate attention matrix sparsification to prune low-impact activations, which further reduces the cost of processing long-context sequences. \par Despite these aggressive compression strategies, our distilled approach preserves a high degree of representational power, leading to substantially improved accuracy compared to prior transformer binarization methods. We evaluate HAD on a range of tasks and models, including the GLUE benchmark, ImageNet, and QuALITY, demonstrating state-of-the-art performance among binarized Transformers while drastically reducing the computational costs of long-context inference. \par We implement HAD in custom hardware simulations, demonstrating superior performance characteristics compared to a custom hardware implementation of standard attention. HAD achieves just $\mathbf{1.78}\%$ performance losses on GLUE compared to $9.08\%$ in state-of-the-art binarization work, and $\mathbf{2.5}\%$ performance losses on ImageNet compared to $12.14\%$, all while targeting custom hardware with a $\mathbf{79}\%$ area reduction and $\mathbf{87}\%$ power reduction compared to its standard attention counterpart.
LP-3DGS: Learning to Prune 3D Gaussian Splatting
May 29, 2024



Recently, 3D Gaussian Splatting (3DGS) has become one of the mainstream methodologies for novel view synthesis (NVS) due to its high quality and fast rendering speed. However, as a point-based scene representation, 3DGS potentially generates a large number of Gaussians to fit the scene, leading to high memory usage. Improvements that have been proposed require either an empirical and preset pruning ratio or importance score threshold to prune the point cloud. Such hyperparamter requires multiple rounds of training to optimize and achieve the maximum pruning ratio, while maintaining the rendering quality for each scene. In this work, we propose learning-to-prune 3DGS (LP-3DGS), where a trainable binary mask is applied to the importance score that can find optimal pruning ratio automatically. Instead of using the traditional straight-through estimator (STE) method to approximate the binary mask gradient, we redesign the masking function to leverage the Gumbel-Sigmoid method, making it differentiable and compatible with the existing training process of 3DGS. Extensive experiments have shown that LP-3DGS consistently produces a good balance that is both efficient and high quality.
SafeguardGS: 3D Gaussian Primitive Pruning While Avoiding Catastrophic Scene Destruction
May 28, 20243D Gaussian Splatting (3DGS) has made a significant stride in novel view synthesis, demonstrating top-notch rendering quality while achieving real-time rendering speed. However, the excessively large number of Gaussian primitives resulting from 3DGS' suboptimal densification process poses a major challenge, slowing down frame-per-second (FPS) and demanding considerable memory cost, making it unfavorable for low-end devices. To cope with this issue, many follow-up studies have suggested various pruning techniques, often in combination with different score functions, to optimize rendering performance. Nonetheless, a comprehensive discussion regarding their effectiveness and implications across all techniques is missing. In this paper, we first categorize 3DGS pruning techniques into two types: Cross-view pruning and pixel-wise pruning, which differ in their approaches to rank primitives. Our subsequent experiments reveal that while cross-view pruning leads to disastrous quality drops under extreme Gaussian primitives decimation, the pixel-wise pruning technique not only sustains relatively high rendering quality with minuscule performance degradation but also provides a reasonable minimum boundary for pruning. Building on this observation, we further propose multiple variations of score functions and empirically discover that the color-weighted score function outperforms others for discriminating insignificant primitives for rendering. We believe our research provides valuable insights for optimizing 3DGS pruning strategies for future works.
MF-NeRF: Memory Efficient NeRF with Mixed-Feature Hash Table
Apr 27, 2023Neural radiance field (NeRF) has shown remarkable performance in generating photo-realistic novel views. Since the emergence of NeRF, many studies have been conducted, among which managing features with explicit structures such as grids has achieved exceptionally fast training by reducing the complexity of multilayer perceptron (MLP) networks. However, storing features in dense grids requires significantly large memory space, which leads to memory bottleneck in computer systems and thus large training time. To address this issue, in this work, we propose MF-NeRF, a memory-efficient NeRF framework that employs a mixed-feature hash table to improve memory efficiency and reduce training time while maintaining reconstruction quality. We first design a mixed-feature hash table to adaptively mix part of multi-level feature grids into one and map it to a single hash table. Following that, in order to obtain the correct index of a grid point, we further design an index transformation method that transforms indices of an arbitrary level grid to those of a canonical grid. Extensive experiments benchmarking with state-of-the-art Instant-NGP, TensoRF, and DVGO, indicate our MF-NeRF could achieve the fastest training time on the same GPU hardware with similar or even higher reconstruction quality. Source code is available at https://github.com/nfyfamr/MF-NeRF.
Model Extraction Attacks on Split Federated Learning
Mar 13, 2023



Federated Learning (FL) is a popular collaborative learning scheme involving multiple clients and a server. FL focuses on protecting clients' data but turns out to be highly vulnerable to Intellectual Property (IP) threats. Since FL periodically collects and distributes the model parameters, a free-rider can download the latest model and thus steal model IP. Split Federated Learning (SFL), a recent variant of FL that supports training with resource-constrained clients, splits the model into two, giving one part of the model to clients (client-side model), and the remaining part to the server (server-side model). Thus SFL prevents model leakage by design. Moreover, by blocking prediction queries, it can be made resistant to advanced IP threats such as traditional Model Extraction (ME) attacks. While SFL is better than FL in terms of providing IP protection, it is still vulnerable. In this paper, we expose the vulnerability of SFL and show how malicious clients can launch ME attacks by querying the gradient information from the server side. We propose five variants of ME attack which differs in the gradient usage as well as in the data assumptions. We show that under practical cases, the proposed ME attacks work exceptionally well for SFL. For instance, when the server-side model has five layers, our proposed ME attack can achieve over 90% accuracy with less than 2% accuracy degradation with VGG-11 on CIFAR-10.
Efficient Self-supervised Continual Learning with Progressive Task-correlated Layer Freezing
Mar 13, 2023Inspired by the success of Self-supervised learning (SSL) in learning visual representations from unlabeled data, a few recent works have studied SSL in the context of continual learning (CL), where multiple tasks are learned sequentially, giving rise to a new paradigm, namely self-supervised continual learning (SSCL). It has been shown that the SSCL outperforms supervised continual learning (SCL) as the learned representations are more informative and robust to catastrophic forgetting. However, if not designed intelligently, the training complexity of SSCL may be prohibitively high due to the inherent training cost of SSL. In this work, by investigating the task correlations in SSCL setup first, we discover an interesting phenomenon that, with the SSL-learned background model, the intermediate features are highly correlated between tasks. Based on this new finding, we propose a new SSCL method with layer-wise freezing which progressively freezes partial layers with the highest correlation ratios for each task to improve training computation efficiency and memory efficiency. Extensive experiments across multiple datasets are performed, where our proposed method shows superior performance against the SoTA SSCL methods under various SSL frameworks. For example, compared to LUMP, our method achieves 12\%/14\%/12\% GPU training time reduction, 23\%/26\%/24\% memory reduction, 35\%/34\%/33\% backward FLOPs reduction, and 1.31\%/1.98\%/1.21\% forgetting reduction without accuracy degradation on three datasets, respectively.
Beyond Not-Forgetting: Continual Learning with Backward Knowledge Transfer
Nov 01, 2022



By learning a sequence of tasks continually, an agent in continual learning (CL) can improve the learning performance of both a new task and `old' tasks by leveraging the forward knowledge transfer and the backward knowledge transfer, respectively. However, most existing CL methods focus on addressing catastrophic forgetting in neural networks by minimizing the modification of the learnt model for old tasks. This inevitably limits the backward knowledge transfer from the new task to the old tasks, because judicious model updates could possibly improve the learning performance of the old tasks as well. To tackle this problem, we first theoretically analyze the conditions under which updating the learnt model of old tasks could be beneficial for CL and also lead to backward knowledge transfer, based on the gradient projection onto the input subspaces of old tasks. Building on the theoretical analysis, we next develop a ContinUal learning method with Backward knowlEdge tRansfer (CUBER), for a fixed capacity neural network without data replay. In particular, CUBER first characterizes the task correlation to identify the positively correlated old tasks in a layer-wise manner, and then selectively modifies the learnt model of the old tasks when learning the new task. Experimental studies show that CUBER can even achieve positive backward knowledge transfer on several existing CL benchmarks for the first time without data replay, where the related baselines still suffer from catastrophic forgetting (negative backward knowledge transfer). The superior performance of CUBER on the backward knowledge transfer also leads to higher accuracy accordingly.
ResSFL: A Resistance Transfer Framework for Defending Model Inversion Attack in Split Federated Learning
May 09, 2022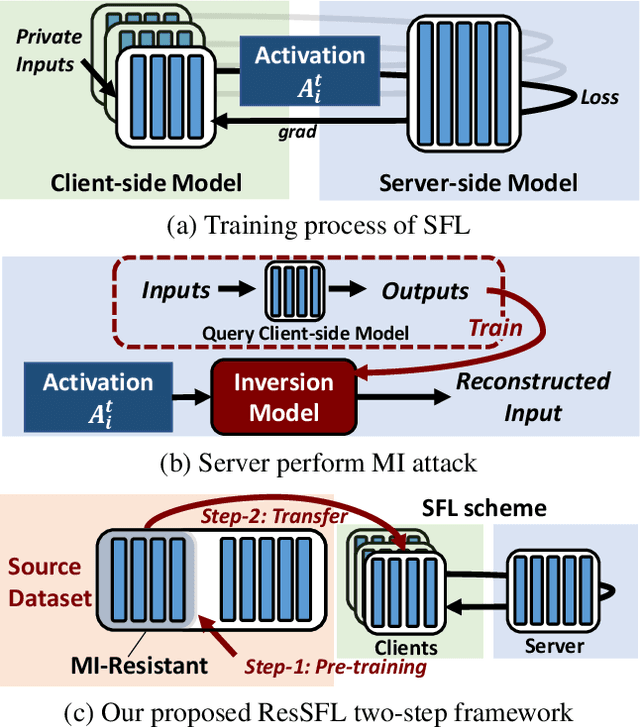
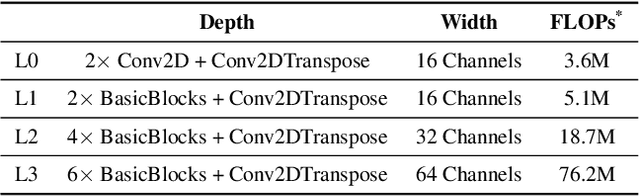
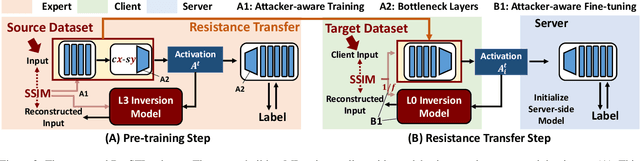
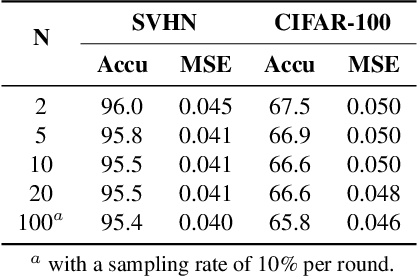
This work aims to tackle Model Inversion (MI) attack on Split Federated Learning (SFL). SFL is a recent distributed training scheme where multiple clients send intermediate activations (i.e., feature map), instead of raw data, to a central server. While such a scheme helps reduce the computational load at the client end, it opens itself to reconstruction of raw data from intermediate activation by the server. Existing works on protecting SFL only consider inference and do not handle attacks during training. So we propose ResSFL, a Split Federated Learning Framework that is designed to be MI-resistant during training. It is based on deriving a resistant feature extractor via attacker-aware training, and using this extractor to initialize the client-side model prior to standard SFL training. Such a method helps in reducing the computational complexity due to use of strong inversion model in client-side adversarial training as well as vulnerability of attacks launched in early training epochs. On CIFAR-100 dataset, our proposed framework successfully mitigates MI attack on a VGG-11 model with a high reconstruction Mean-Square-Error of 0.050 compared to 0.005 obtained by the baseline system. The framework achieves 67.5% accuracy (only 1% accuracy drop) with very low computation overhead. Code is released at: https://github.com/zlijingtao/ResSFL.
TRGP: Trust Region Gradient Projection for Continual Learning
Feb 07, 2022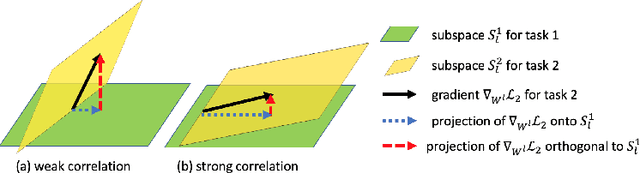
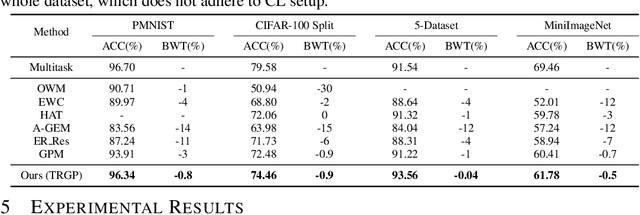

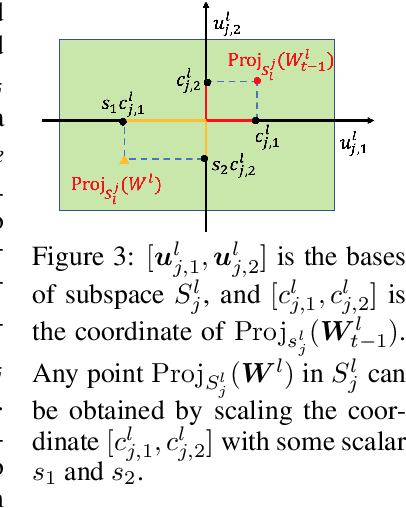
Catastrophic forgetting is one of the major challenges in continual learning. To address this issue, some existing methods put restrictive constraints on the optimization space of the new task for minimizing the interference to old tasks. However, this may lead to unsatisfactory performance for the new task, especially when the new task is strongly correlated with old tasks. To tackle this challenge, we propose Trust Region Gradient Projection (TRGP) for continual learning to facilitate the forward knowledge transfer based on an efficient characterization of task correlation. Particularly, we introduce a notion of `trust region' to select the most related old tasks for the new task in a layer-wise and single-shot manner, using the norm of gradient projection onto the subspace spanned by task inputs. Then, a scaled weight projection is proposed to cleverly reuse the frozen weights of the selected old tasks in the trust region through a layer-wise scaling matrix. By jointly optimizing the scaling matrices and the model, where the model is updated along the directions orthogonal to the subspaces of old tasks, TRGP can effectively prompt knowledge transfer without forgetting. Extensive experiments show that our approach achieves significant improvement over related state-of-the-art methods.