 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAssessment of Treatment Effect Estimators for Heavy-Tailed Data
Dec 19, 2021



A central obstacle in the objective assessment of treatment effect (TE) estimators in randomized control trials (RCTs) is the lack of ground truth (or validation set) to test their performance. In this paper, we provide a novel cross-validation-like methodology to address this challenge. The key insight of our procedure is that the noisy (but unbiased) difference-of-means estimate can be used as a ground truth "label" on a portion of the RCT, to test the performance of an estimator trained on the other portion. We combine this insight with an aggregation scheme, which borrows statistical strength across a large collection of RCTs, to present an end-to-end methodology for judging an estimator's ability to recover the underlying treatment effect. We evaluate our methodology across 709 RCTs implemented in the Amazon supply chain. In the corpus of AB tests at Amazon, we highlight the unique difficulties associated with recovering the treatment effect due to the heavy-tailed nature of the response variables. In this heavy-tailed setting, our methodology suggests that procedures that aggressively downweight or truncate large values, while introducing bias, lower the variance enough to ensure that the treatment effect is more accurately estimated.
Variance Reduction in Training Forecasting Models with Subgroup Sampling
Mar 02, 2021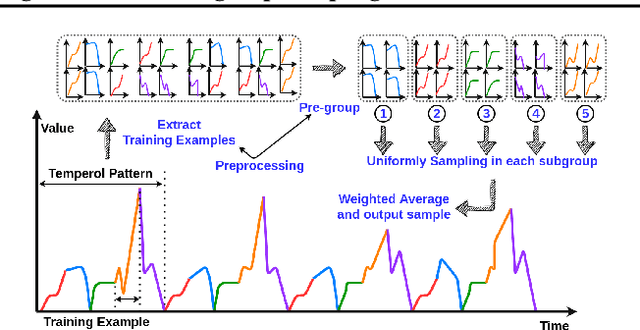
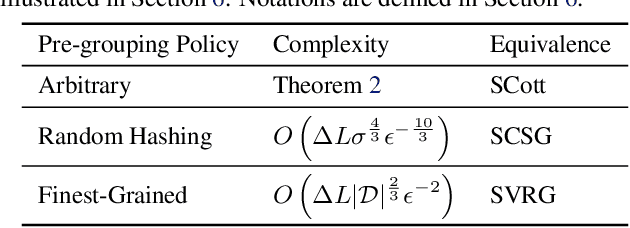
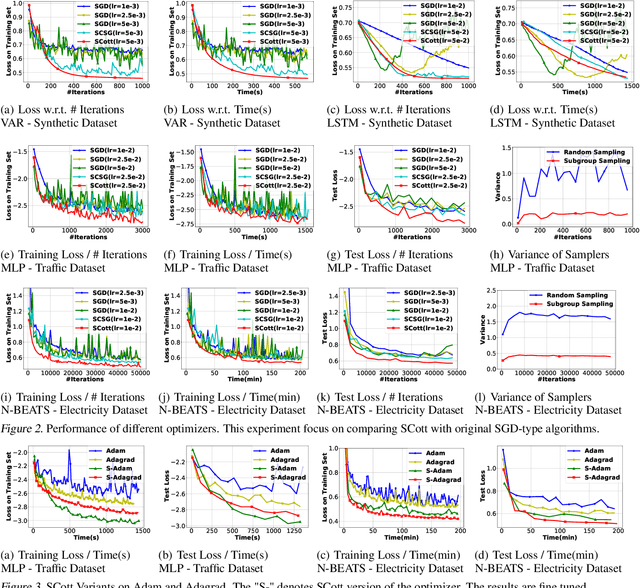
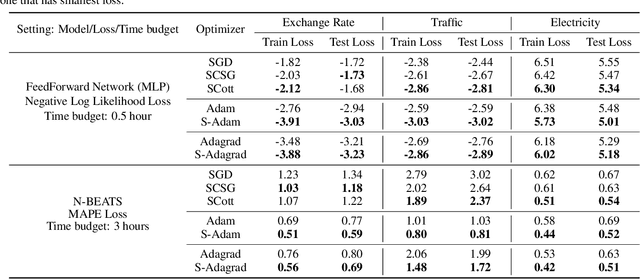
In real-world applications of large-scale time series, one often encounters the situation where the temporal patterns of time series, while drifting over time, differ from one another in the same dataset. In this paper, we provably show under such heterogeneity, training a forecasting model with commonly used stochastic optimizers (e.g. SGD) potentially suffers large gradient variance, and thus requires long time training. To alleviate this issue, we propose a sampling strategy named Subgroup Sampling, which mitigates the large variance via sampling over pre-grouped time series. We further introduce SCott, a variance reduced SGD-style optimizer that co-designs subgroup sampling with the control variate method. In theory, we provide the convergence guarantee of SCott on smooth non-convex objectives. Empirically, we evaluate SCott and other baseline optimizers on both synthetic and real-world time series forecasting problems, and show SCott converges faster with respect to both iterations and wall clock time. Additionally, we show two SCott variants that can speed up Adam and Adagrad without compromising generalization of forecasting models.
Top-$k$ eXtreme Contextual Bandits with Arm Hierarchy
Feb 15, 2021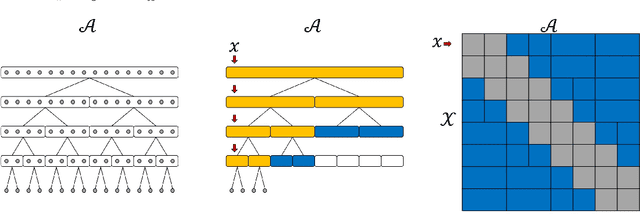
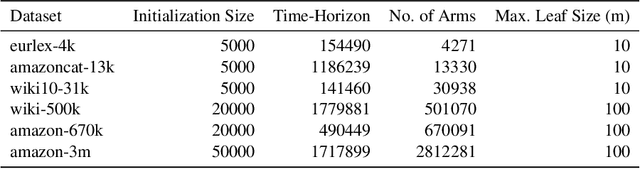
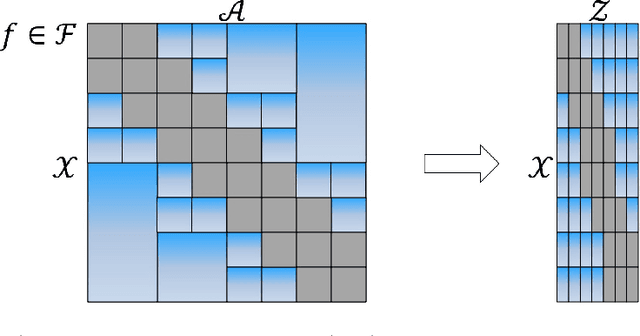
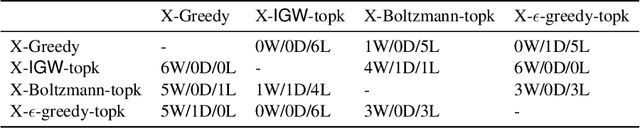
Motivated by modern applications, such as online advertisement and recommender systems, we study the top-$k$ extreme contextual bandits problem, where the total number of arms can be enormous, and the learner is allowed to select $k$ arms and observe all or some of the rewards for the chosen arms. We first propose an algorithm for the non-extreme realizable setting, utilizing the Inverse Gap Weighting strategy for selecting multiple arms. We show that our algorithm has a regret guarantee of $O(k\sqrt{(A-k+1)T \log (|\mathcal{F}|T)})$, where $A$ is the total number of arms and $\mathcal{F}$ is the class containing the regression function, while only requiring $\tilde{O}(A)$ computation per time step. In the extreme setting, where the total number of arms can be in the millions, we propose a practically-motivated arm hierarchy model that induces a certain structure in mean rewards to ensure statistical and computational efficiency. The hierarchical structure allows for an exponential reduction in the number of relevant arms for each context, thus resulting in a regret guarantee of $O(k\sqrt{(\log A-k+1)T \log (|\mathcal{F}|T)})$. Finally, we implement our algorithm using a hierarchical linear function class and show superior performance with respect to well-known benchmarks on simulated bandit feedback experiments using extreme multi-label classification datasets. On a dataset with three million arms, our reduction scheme has an average inference time of only 7.9 milliseconds, which is a 100x improvement.
Dynamic Local Regret for Non-convex Online Forecasting
Oct 25, 2019
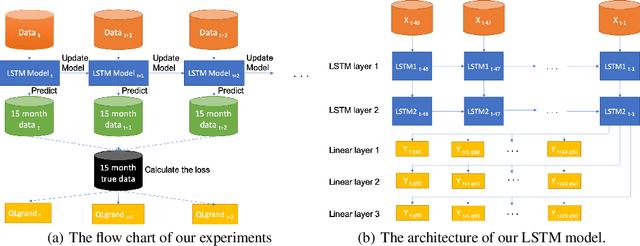
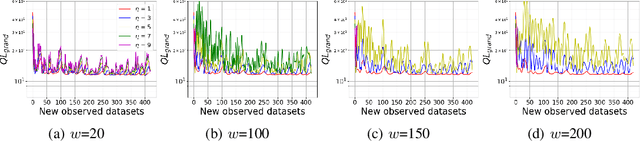
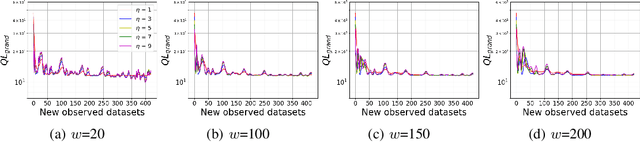
We consider online forecasting problems for non-convex machine learning models. Forecasting introduces several challenges such as (i) frequent updates are necessary to deal with concept drift issues since the dynamics of the environment change over time, and (ii) the state of the art models are non-convex models. We address these challenges with a novel regret framework. Standard regret measures commonly do not consider both dynamic environment and non-convex models. We introduce a local regret for non-convex models in a dynamic environment. We present an update rule incurring a cost, according to our proposed local regret, which is sublinear in time T. Our update uses time-smoothed gradients. Using a real-world dataset we show that our time-smoothed approach yields several benefits when compared with state-of-the-art competitors: results are more stable against new data; training is more robust to hyperparameter selection; and our approach is more computationally efficient than the alternatives.
Deep Factors for Forecasting
May 28, 2019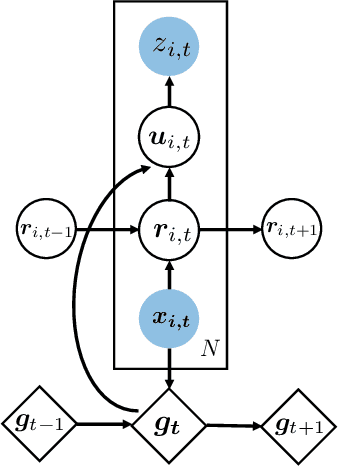
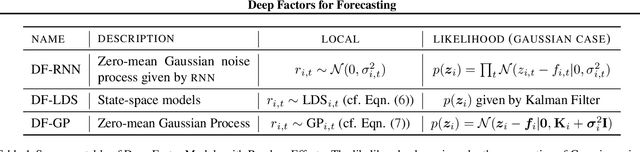
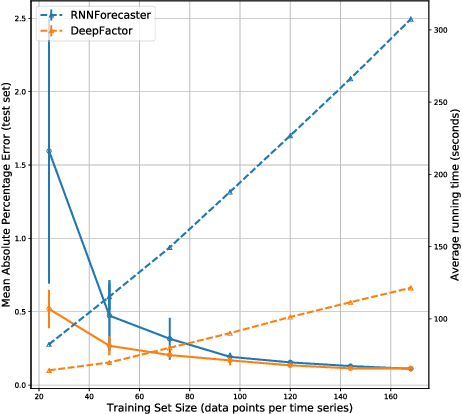
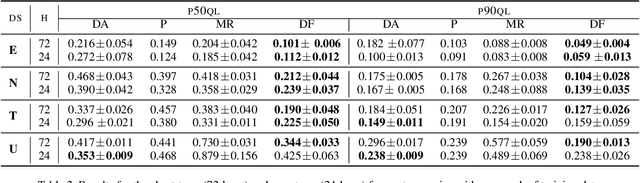
Producing probabilistic forecasts for large collections of similar and/or dependent time series is a practically relevant and challenging task. Classical time series models fail to capture complex patterns in the data, and multivariate techniques struggle to scale to large problem sizes. Their reliance on strong structural assumptions makes them data-efficient, and allows them to provide uncertainty estimates. The converse is true for models based on deep neural networks, which can learn complex patterns and dependencies given enough data. In this paper, we propose a hybrid model that incorporates the benefits of both approaches. Our new method is data-driven and scalable via a latent, global, deep component. It also handles uncertainty through a local classical model. We provide both theoretical and empirical evidence for the soundness of our approach through a necessary and sufficient decomposition of exchangeable time series into a global and a local part. Our experiments demonstrate the advantages of our model both in term of data efficiency, accuracy and computational complexity.
* http://proceedings.mlr.press/v97/wang19k/wang19k.pdf. arXiv admin note: substantial text overlap with arXiv:1812.00098
A Local Regret in Nonconvex Online Learning
Nov 28, 2018We consider an online learning process to forecast a sequence of outcomes for nonconvex models. A typical measure to evaluate online learning algorithms is regret but such standard definition of regret is intractable for nonconvex models even in offline settings. Hence, gradient based definition of regrets are common for both offline and online nonconvex problems. Recently, a notion of local gradient based regret was introduced. Inspired by the concept of calibration and a local gradient based regret, we introduce another definition of regret and we discuss why our definition is more interpretable for forecasting problems. We also provide bound analysis for our regret under certain assumptions.
Invariances and Data Augmentation for Supervised Music Transcription
Nov 13, 2017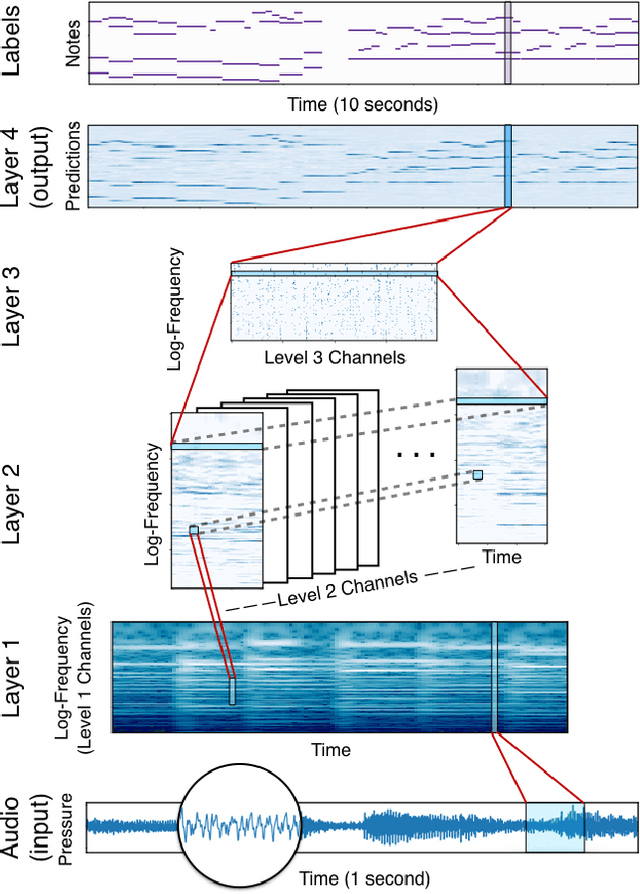
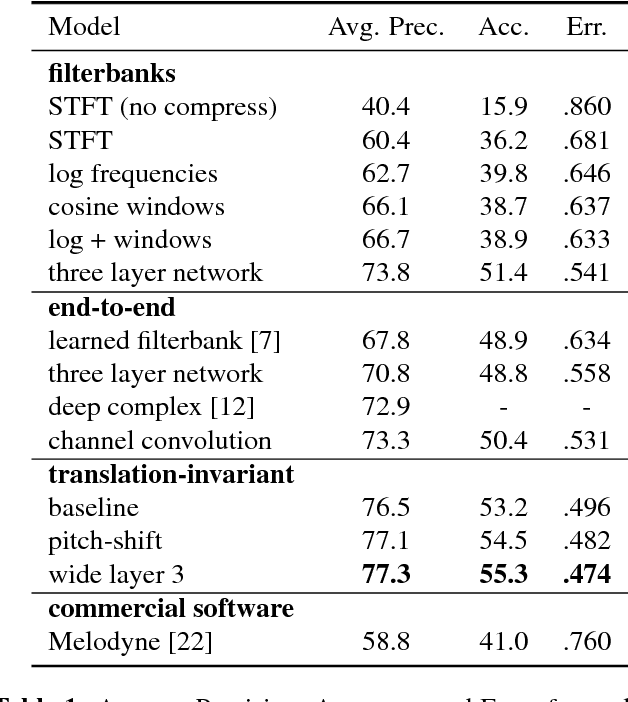
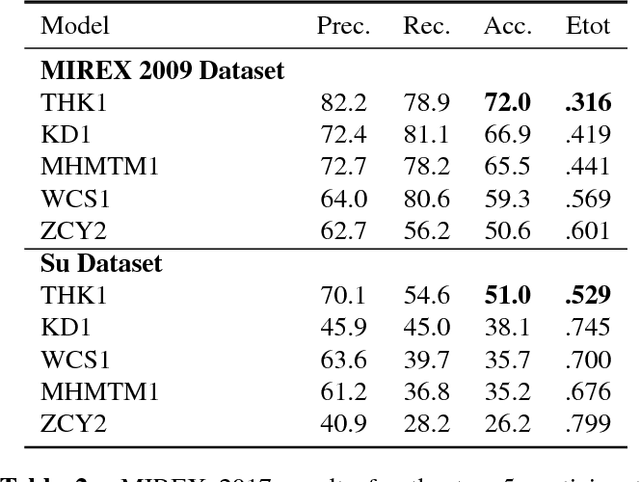
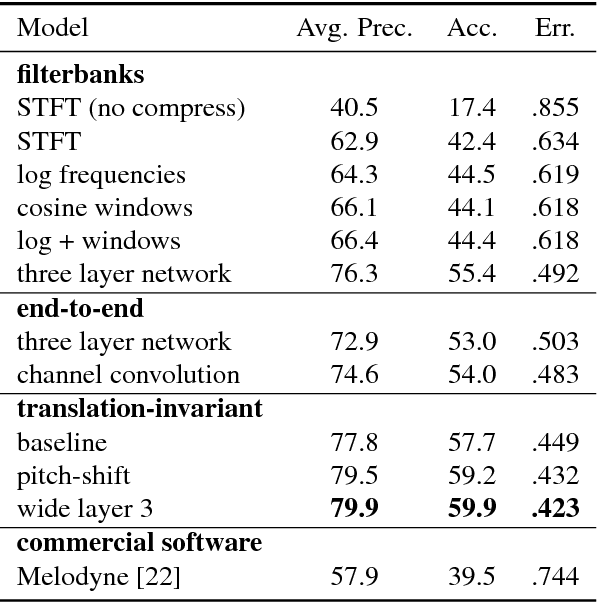
This paper explores a variety of models for frame-based music transcription, with an emphasis on the methods needed to reach state-of-the-art on human recordings. The translation-invariant network discussed in this paper, which combines a traditional filterbank with a convolutional neural network, was the top-performing model in the 2017 MIREX Multiple Fundamental Frequency Estimation evaluation. This class of models shares parameters in the log-frequency domain, which exploits the frequency invariance of music to reduce the number of model parameters and avoid overfitting to the training data. All models in this paper were trained with supervision by labeled data from the MusicNet dataset, augmented by random label-preserving pitch-shift transformations.
Online Sparse Linear Regression
Mar 07, 2016We consider the online sparse linear regression problem, which is the problem of sequentially making predictions observing only a limited number of features in each round, to minimize regret with respect to the best sparse linear regressor, where prediction accuracy is measured by square loss. We give an inefficient algorithm that obtains regret bounded by $\tilde{O}(\sqrt{T})$ after $T$ prediction rounds. We complement this result by showing that no algorithm running in polynomial time per iteration can achieve regret bounded by $O(T^{1-\delta})$ for any constant $\delta > 0$ unless $\text{NP} \subseteq \text{BPP}$. This computational hardness result resolves an open problem presented in COLT 2014 (Kale, 2014) and also posed by Zolghadr et al. (2013). This hardness result holds even if the algorithm is allowed to access more features than the best sparse linear regressor up to a logarithmic factor in the dimension.
Semantic Word Clusters Using Signed Normalized Graph Cuts
Jan 20, 2016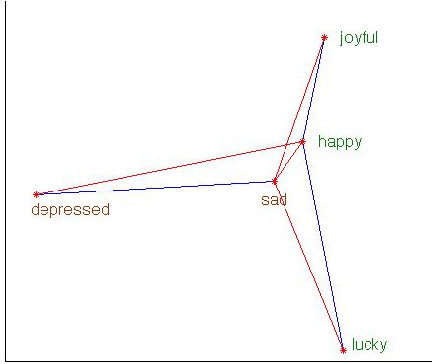
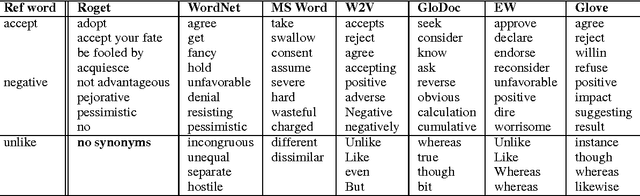
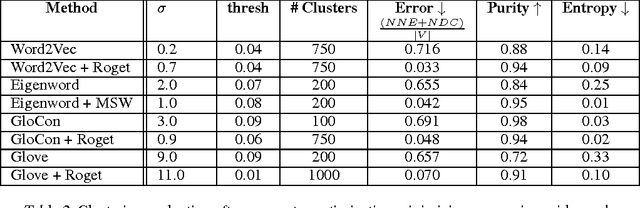
Vector space representations of words capture many aspects of word similarity, but such methods tend to make vector spaces in which antonyms (as well as synonyms) are close to each other. We present a new signed spectral normalized graph cut algorithm, signed clustering, that overlays existing thesauri upon distributionally derived vector representations of words, so that antonym relationships between word pairs are represented by negative weights. Our signed clustering algorithm produces clusters of words which simultaneously capture distributional and synonym relations. We evaluate these clusters against the SimLex-999 dataset (Hill et al.,2014) of human judgments of word pair similarities, and also show the benefit of using our clusters to predict the sentiment of a given text.
Finding Linear Structure in Large Datasets with Scalable Canonical Correlation Analysis
Jun 26, 2015
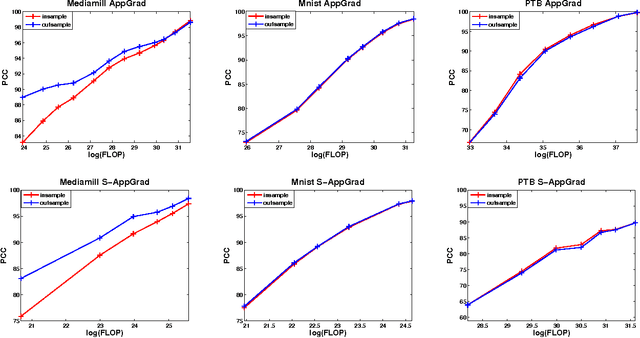
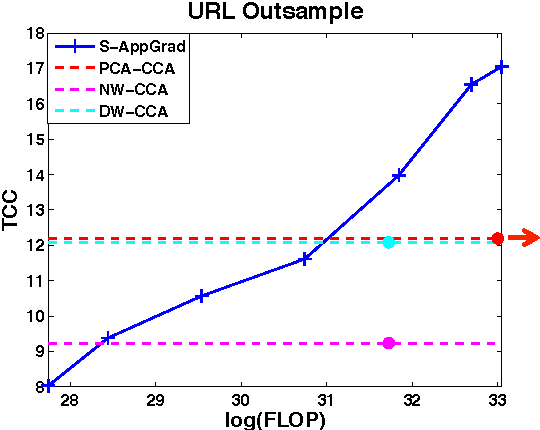
Canonical Correlation Analysis (CCA) is a widely used spectral technique for finding correlation structures in multi-view datasets. In this paper, we tackle the problem of large scale CCA, where classical algorithms, usually requiring computing the product of two huge matrices and huge matrix decomposition, are computationally and storage expensive. We recast CCA from a novel perspective and propose a scalable and memory efficient Augmented Approximate Gradient (AppGrad) scheme for finding top $k$ dimensional canonical subspace which only involves large matrix multiplying a thin matrix of width $k$ and small matrix decomposition of dimension $k\times k$. Further, AppGrad achieves optimal storage complexity $O(k(p_1+p_2))$, compared with classical algorithms which usually require $O(p_1^2+p_2^2)$ space to store two dense whitening matrices. The proposed scheme naturally generalizes to stochastic optimization regime, especially efficient for huge datasets where batch algorithms are prohibitive. The online property of stochastic AppGrad is also well suited to the streaming scenario, where data comes sequentially. To the best of our knowledge, it is the first stochastic algorithm for CCA. Experiments on four real data sets are provided to show the effectiveness of the proposed methods.